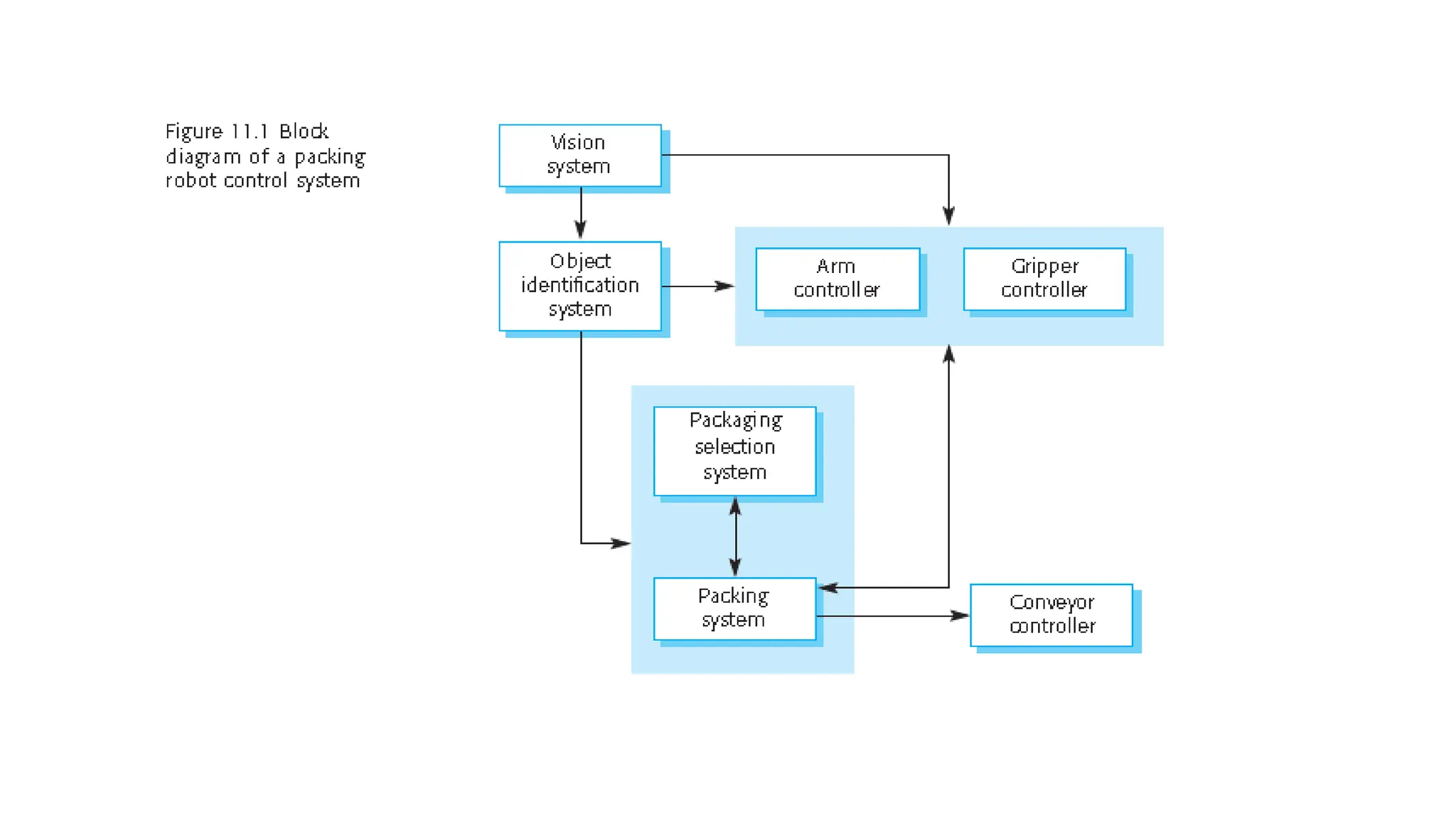
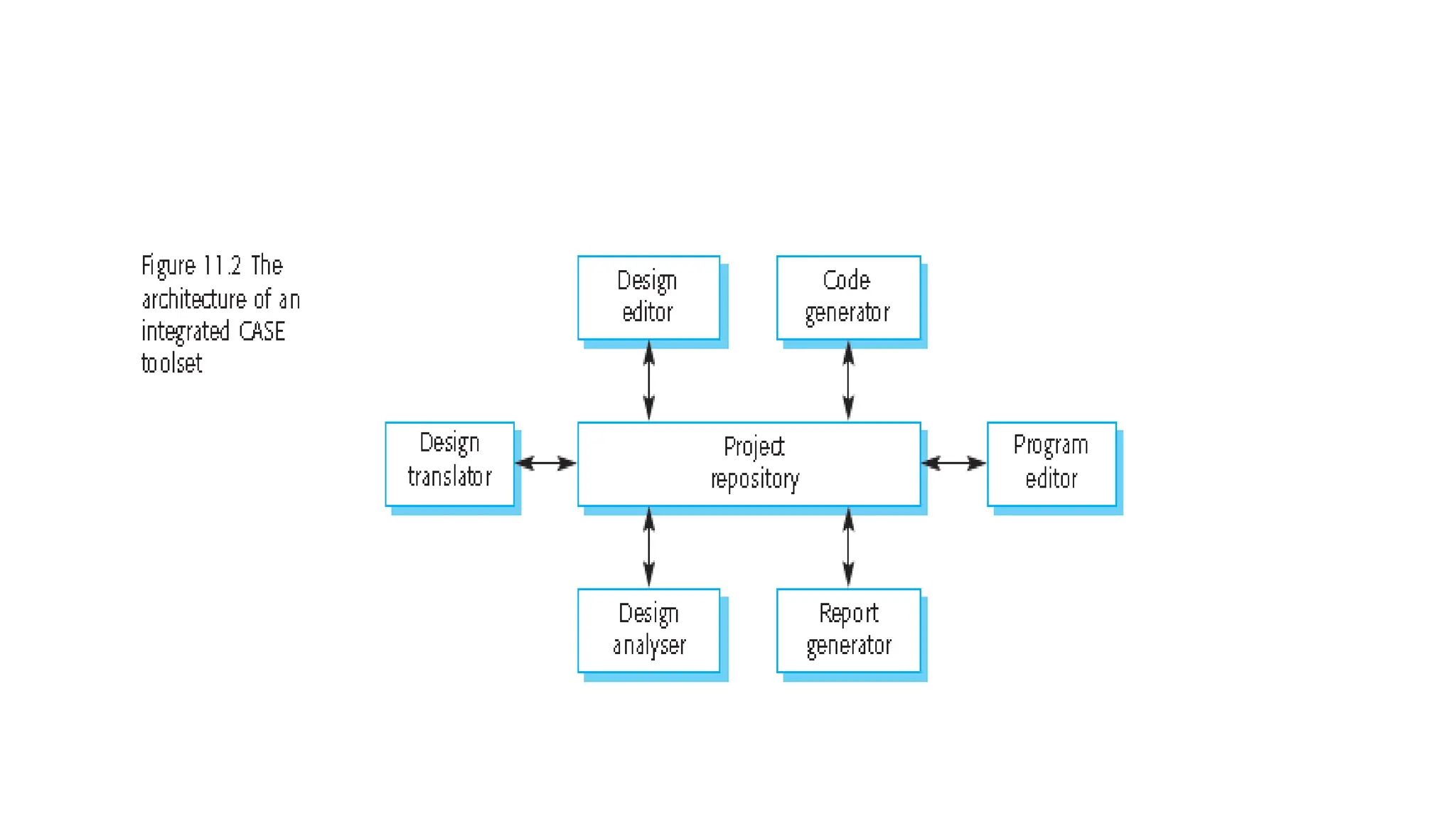
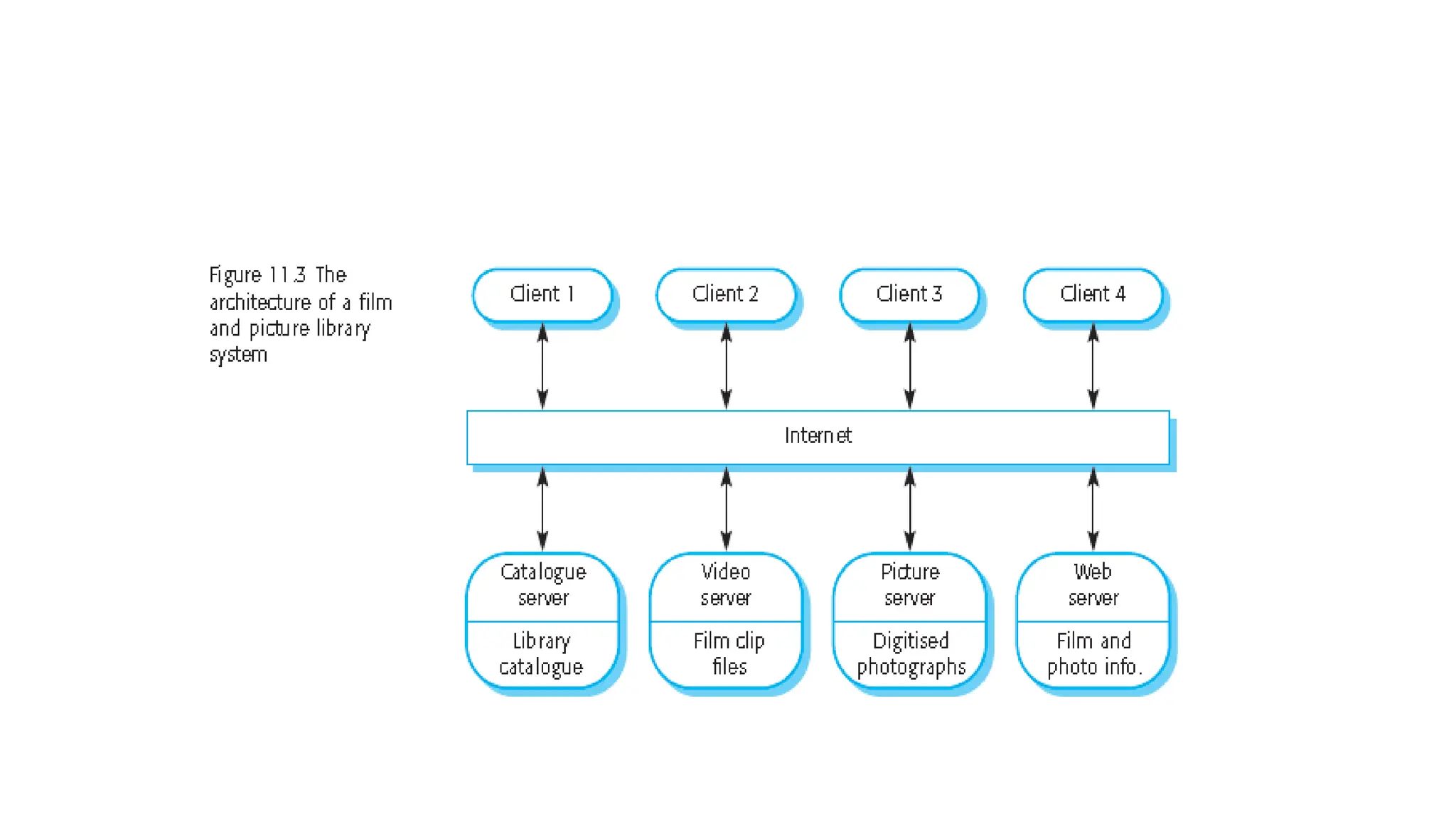
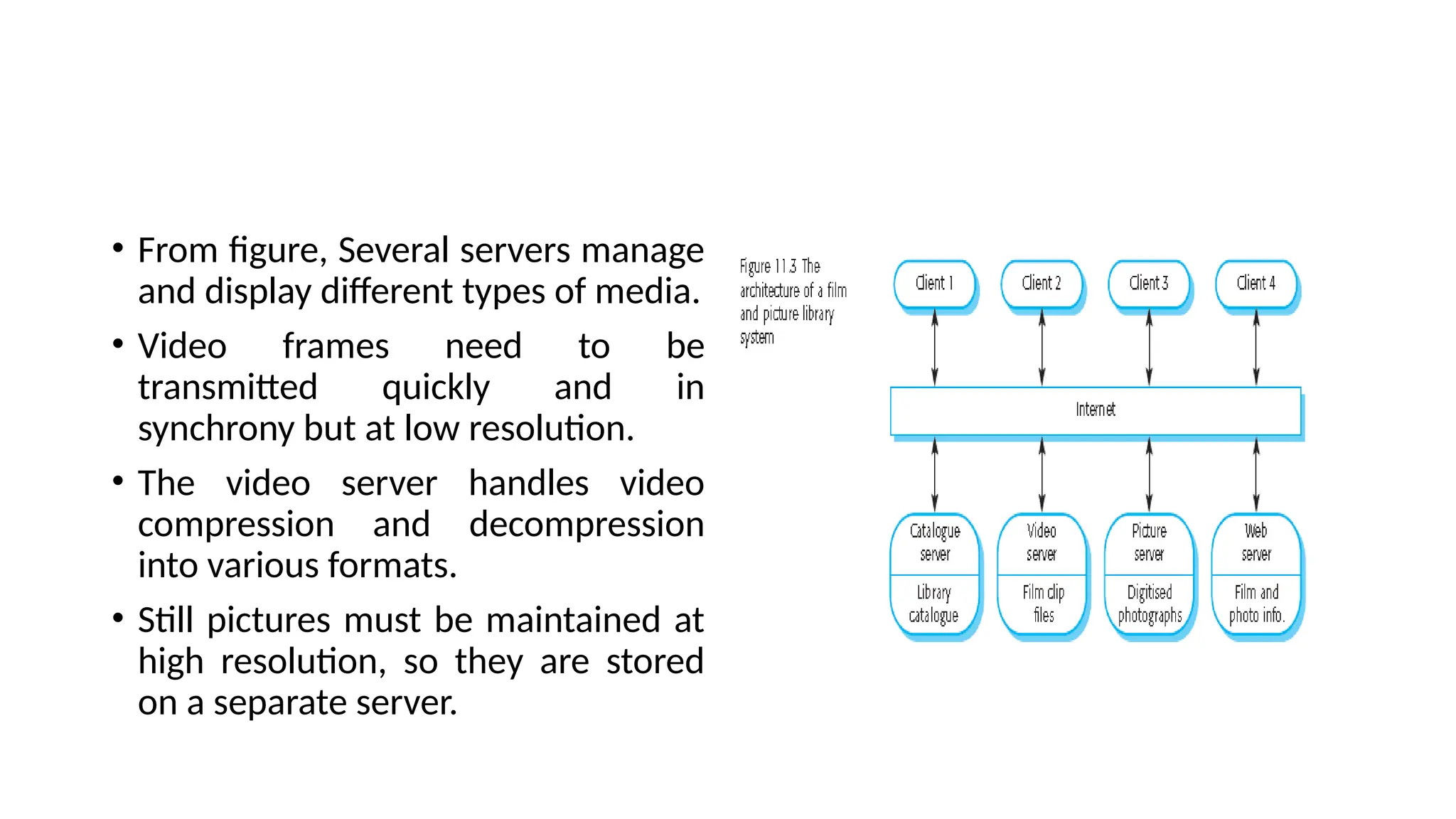
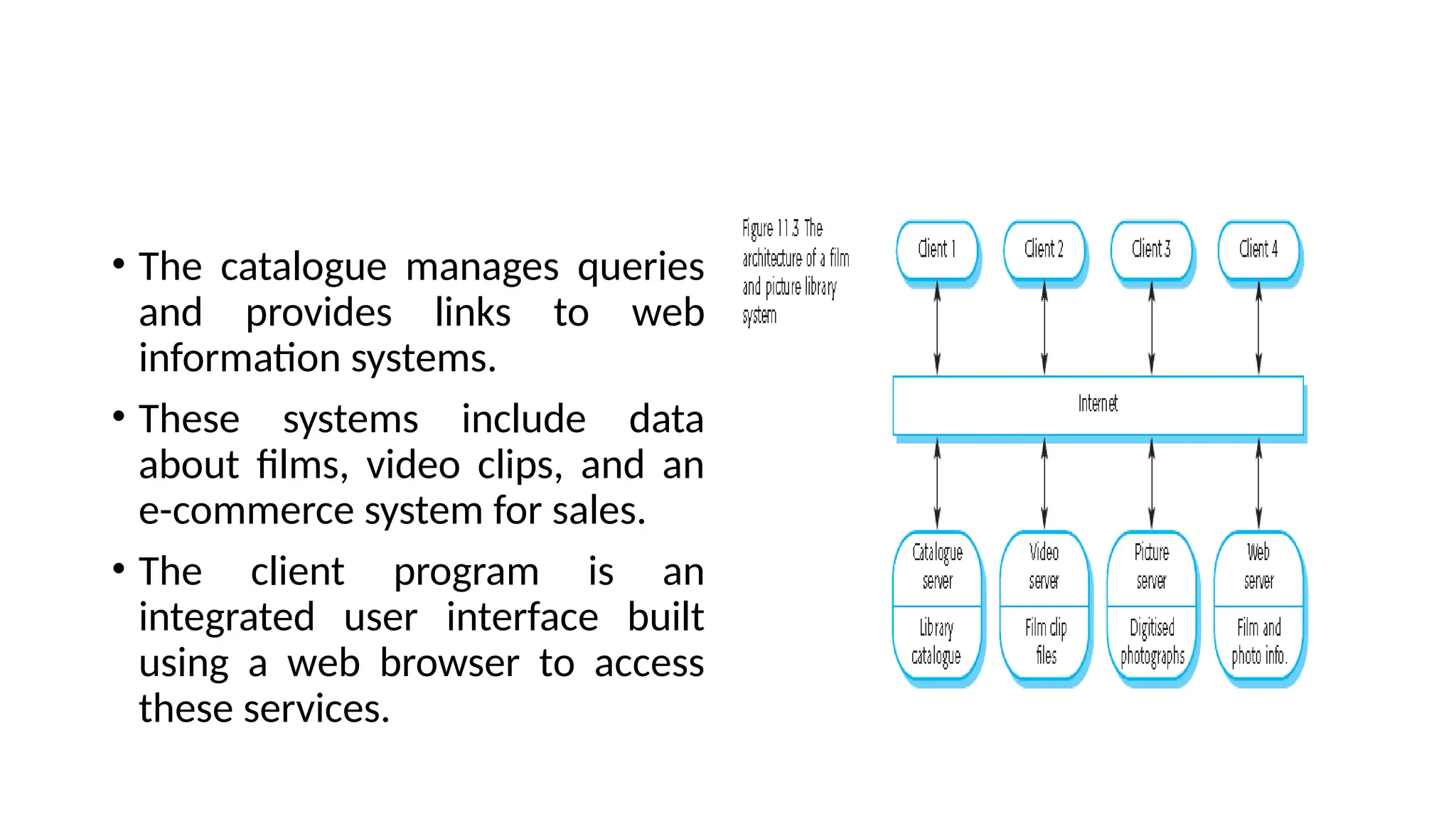
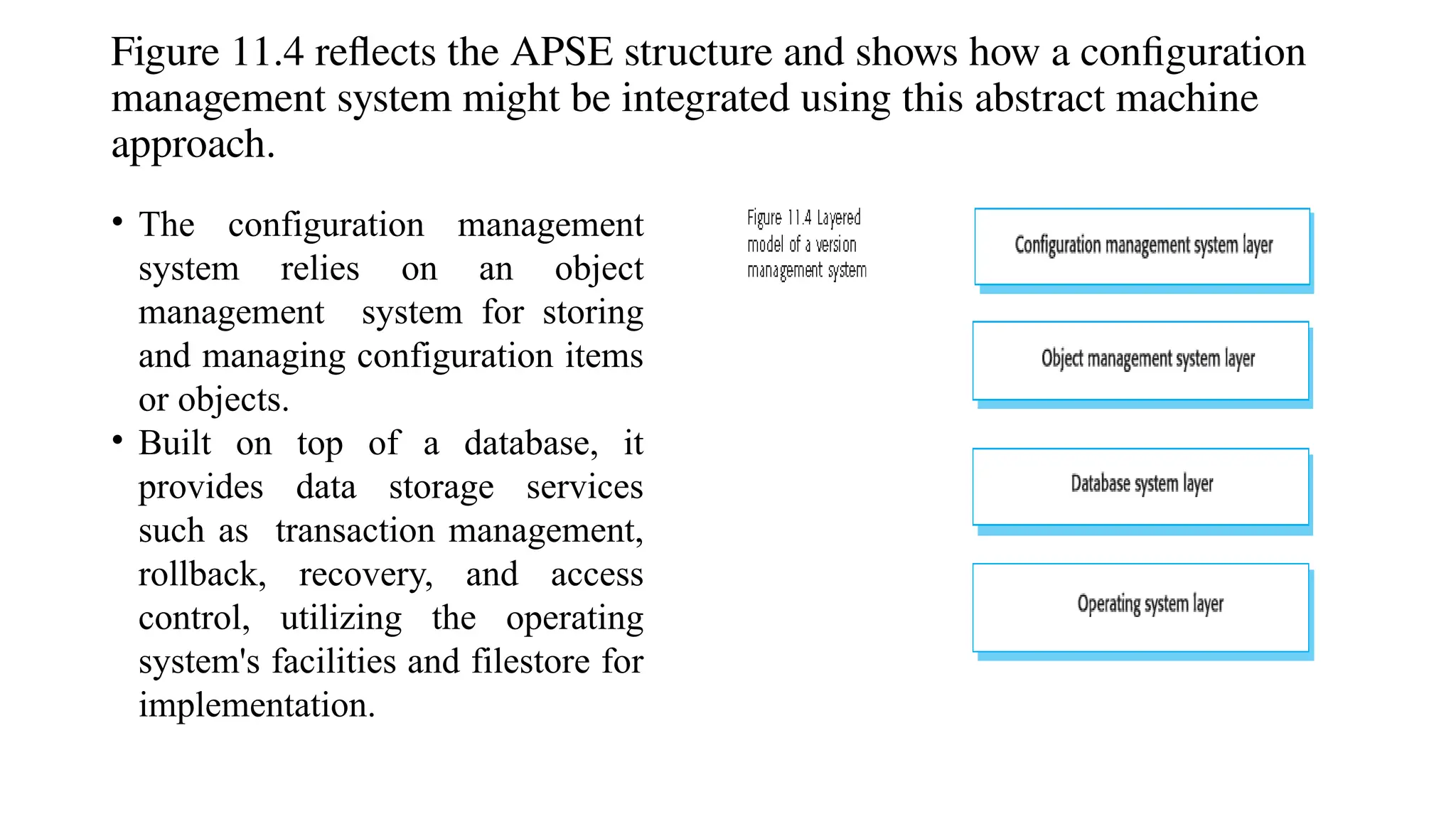
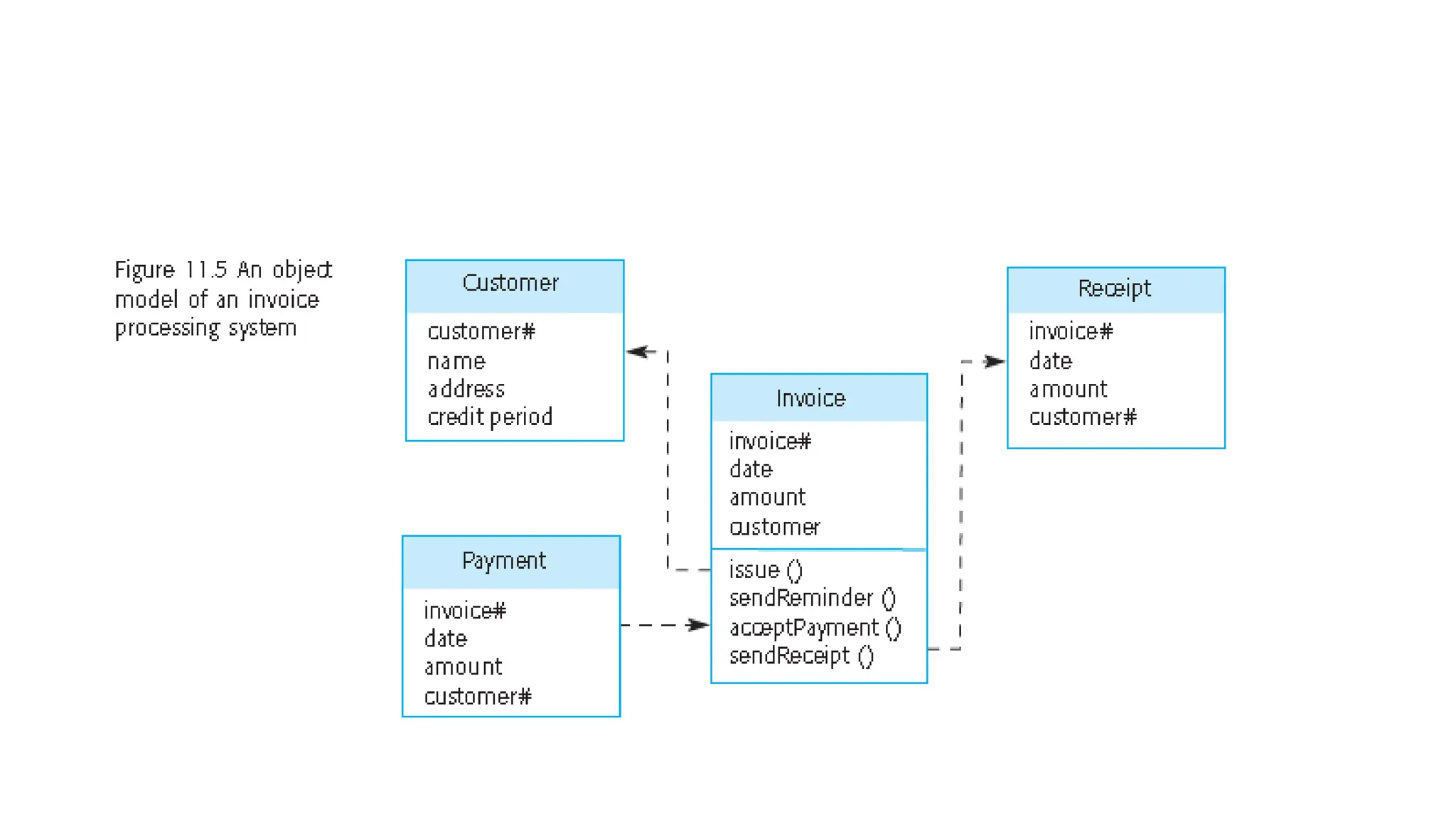
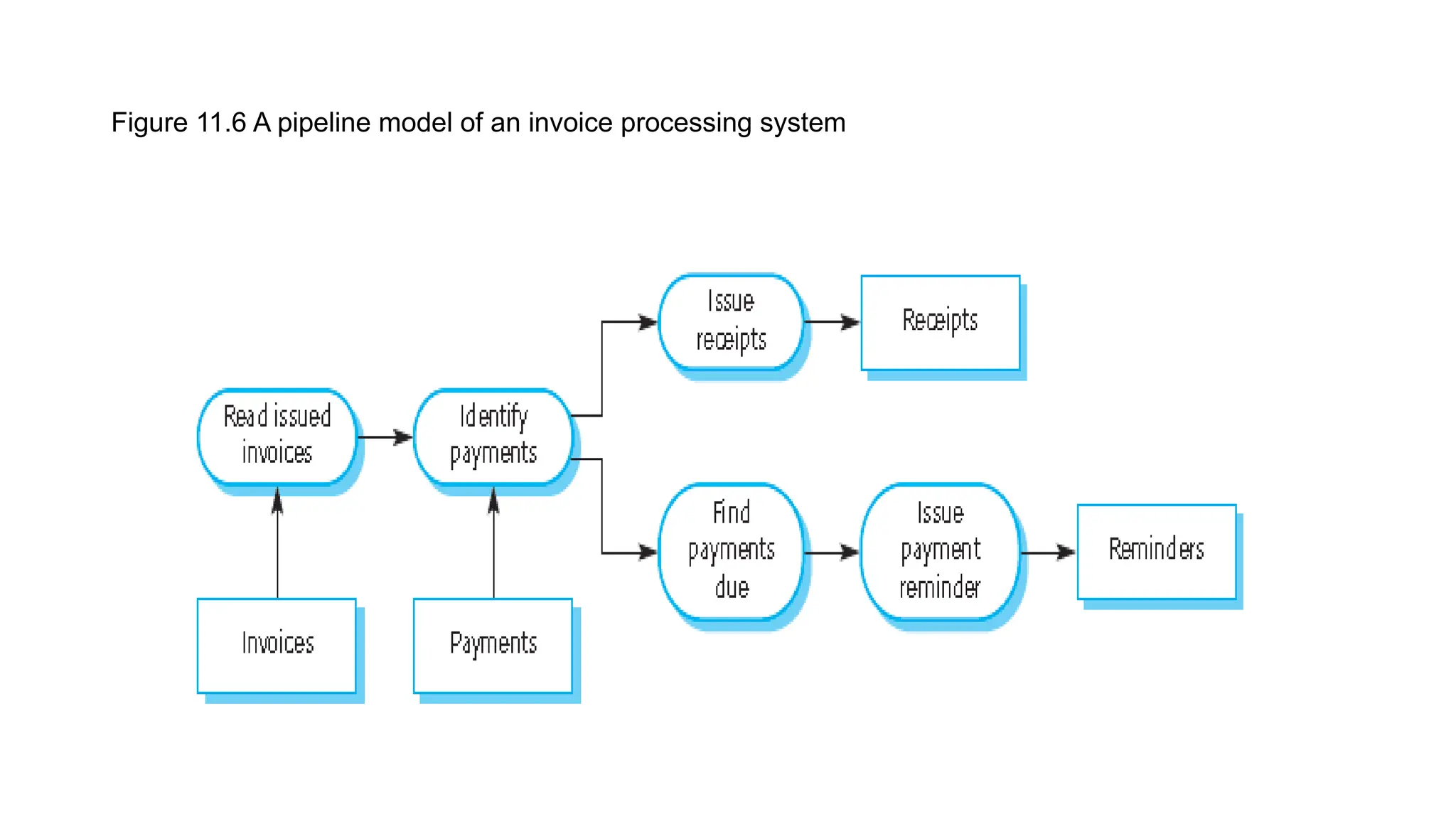
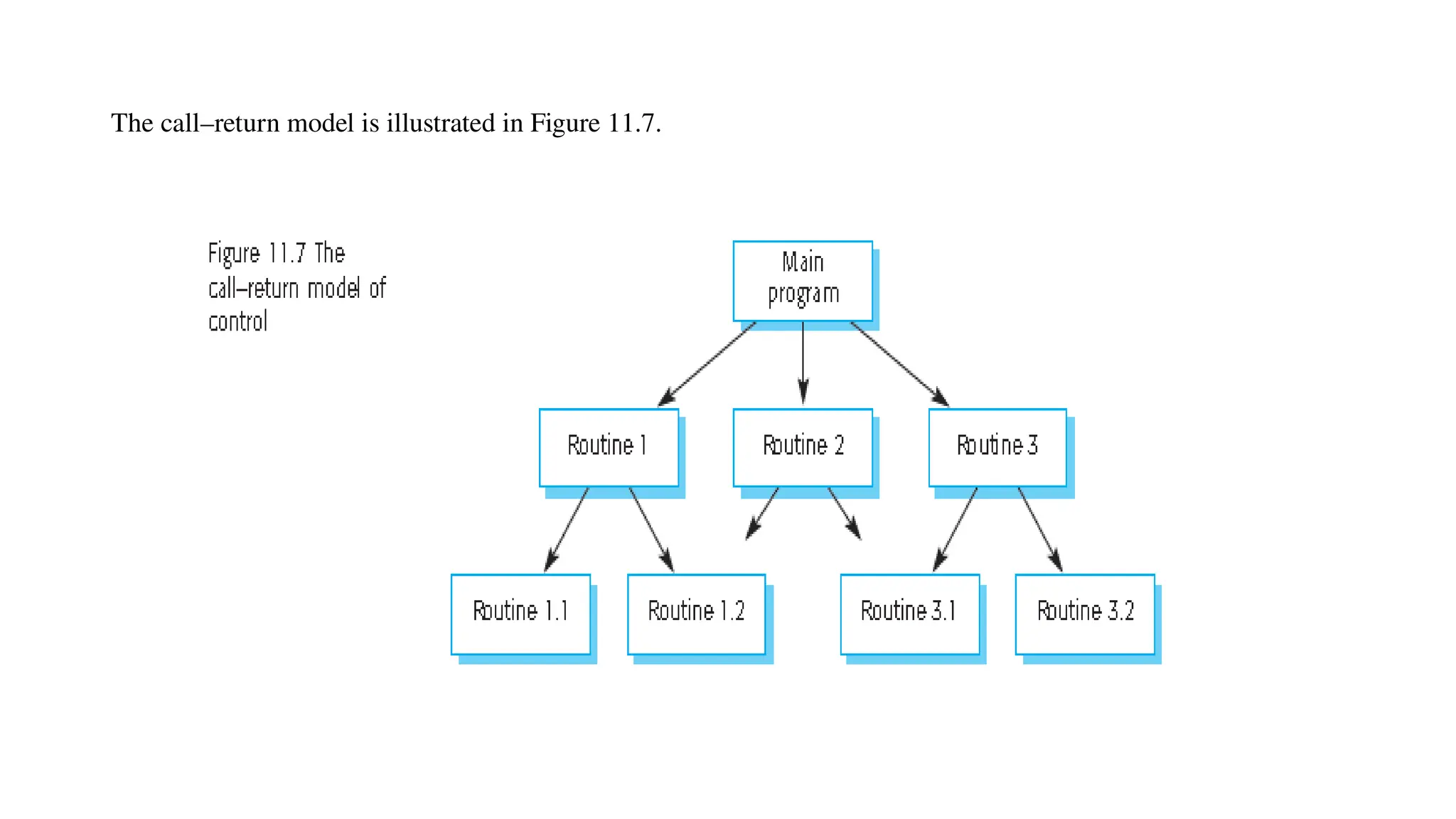
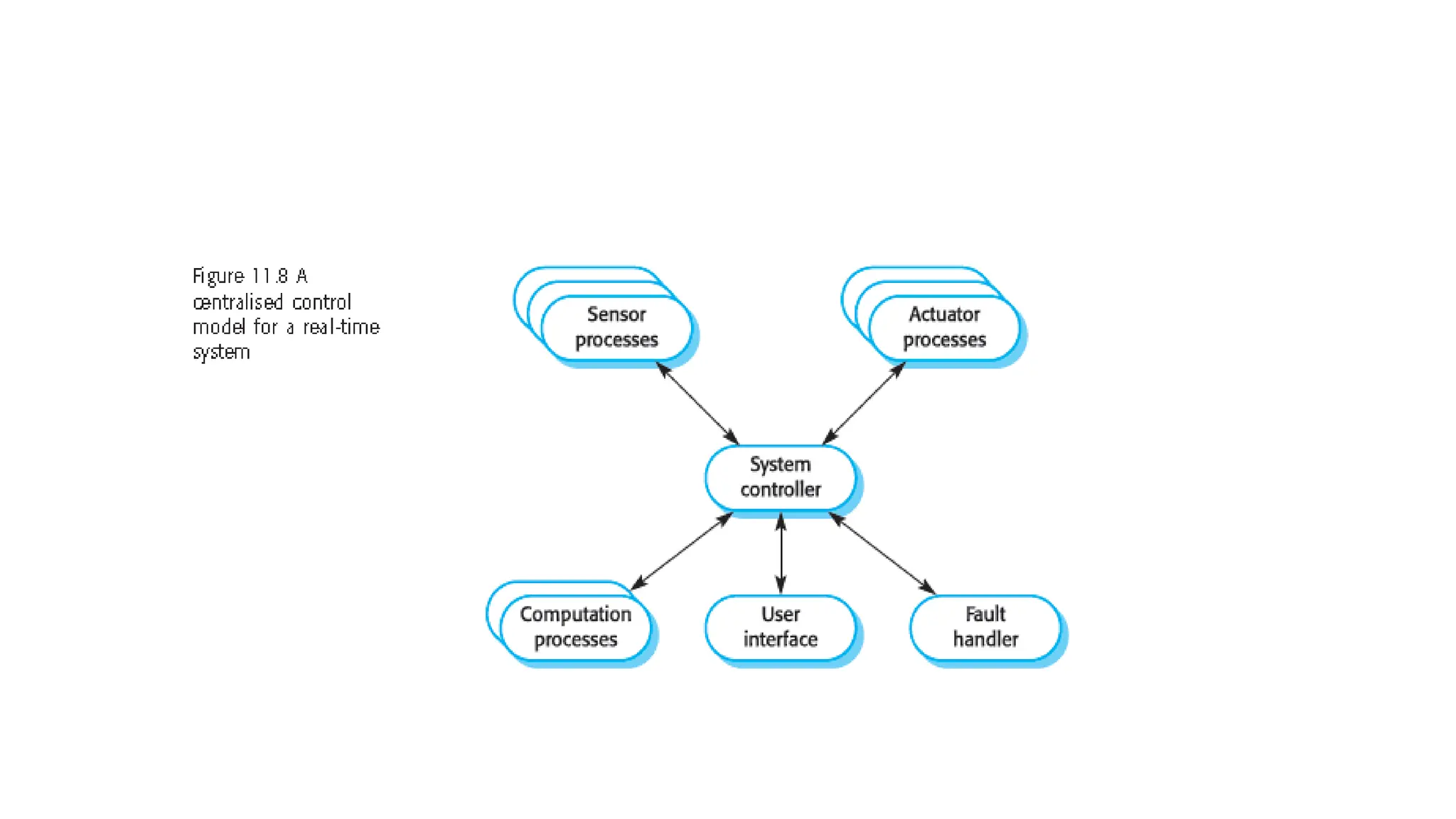
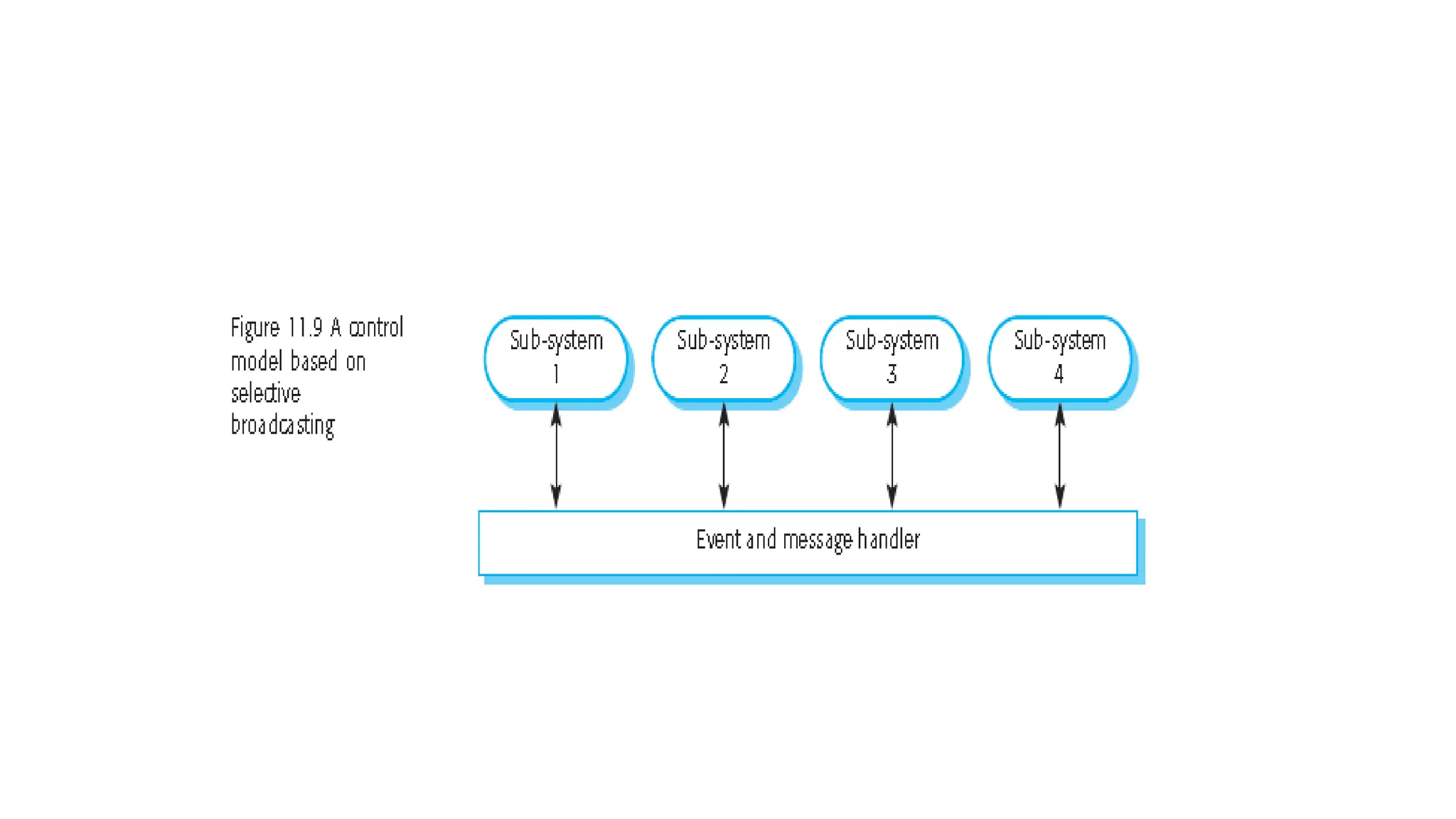
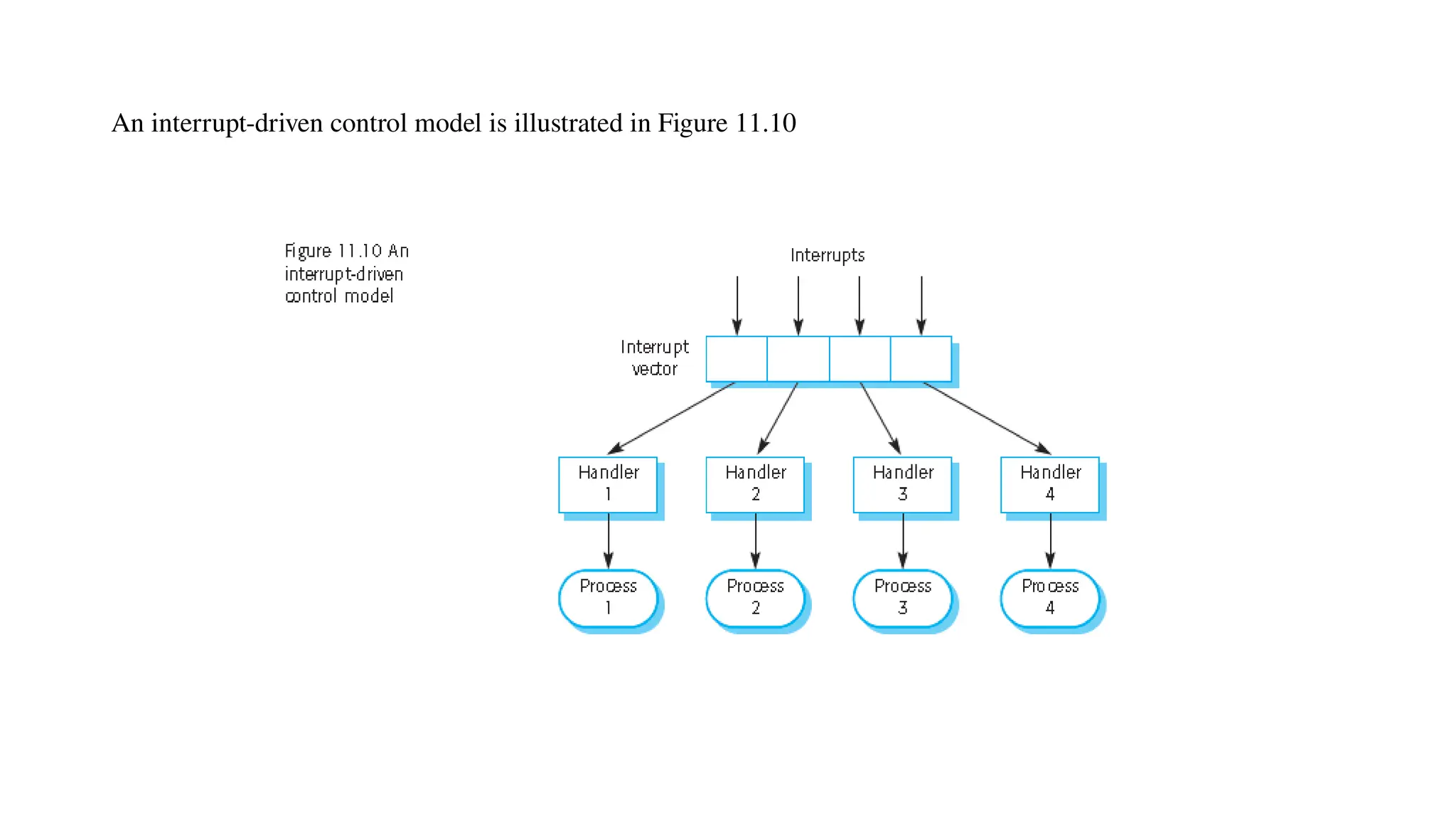
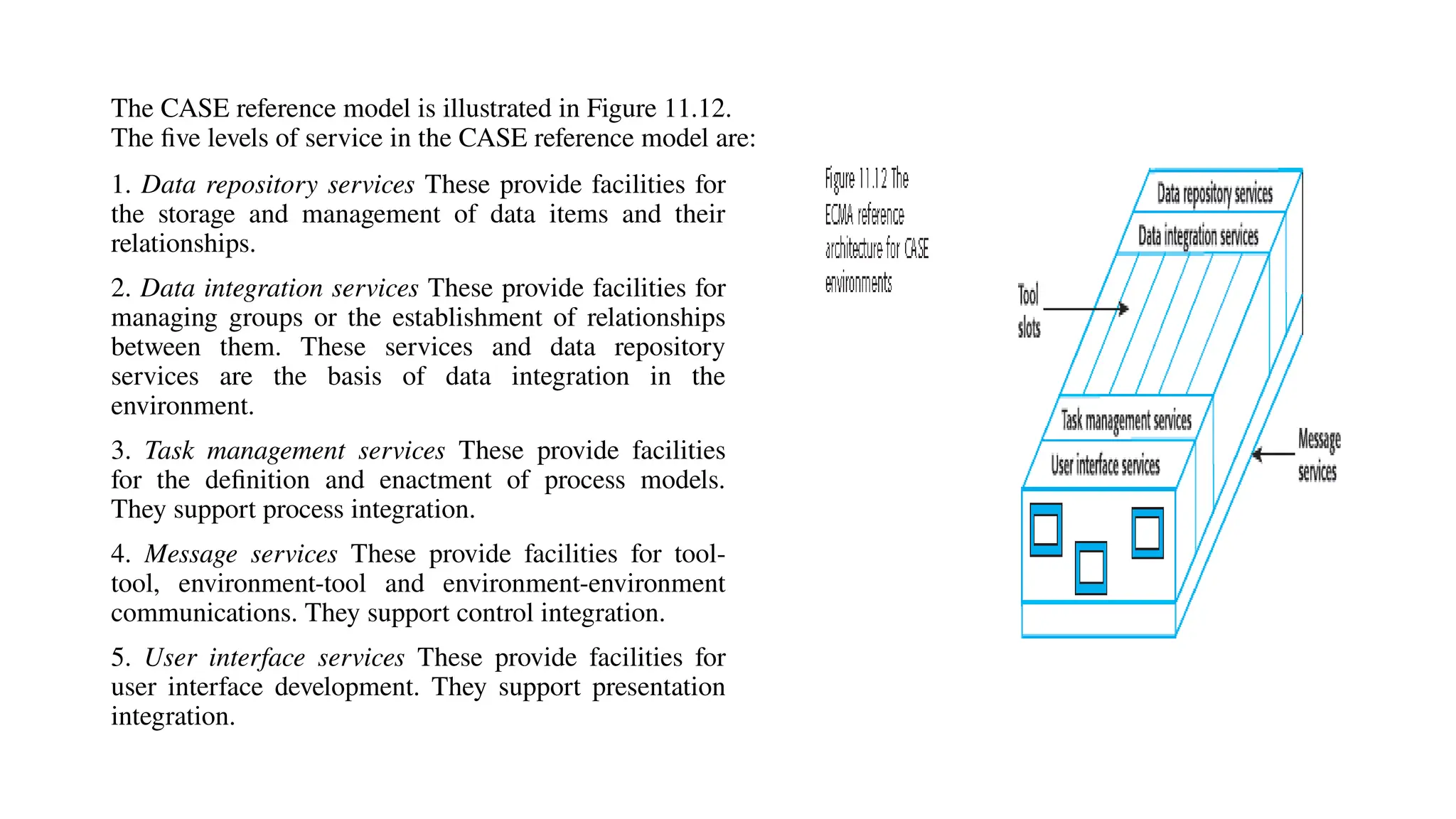
Architectural design involves the initial process of organizing a system into subsystems to meet both functional and non-functional requirements, culminating in a software architecture description. Key advantages of this design include enhanced stakeholder communication, critical system analysis, and the potential for large-scale reuse across similar systems. Various architecture styles such as shared data repositories, client-server models, and layered architectures address specific system requirements including performance, security, maintainability, and availability.