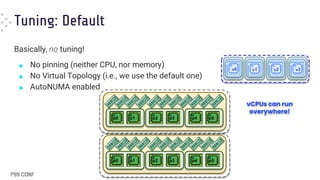
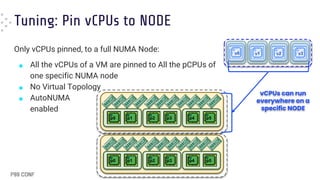
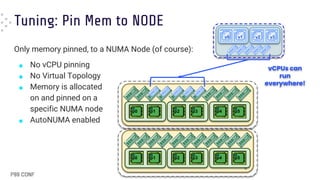
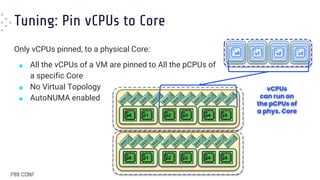
Download to read offline












![Cyclictest +
KernelBench (noise)
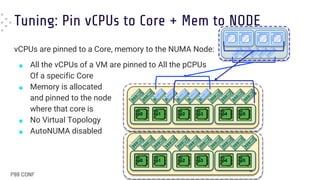
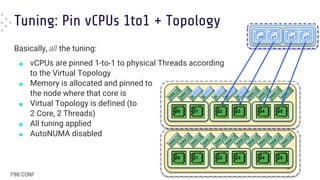
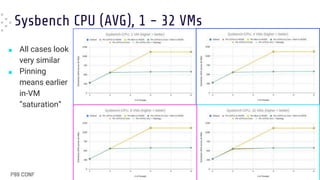
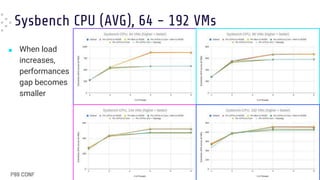
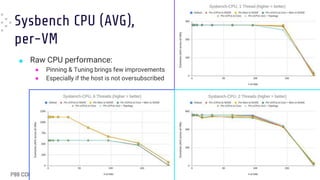
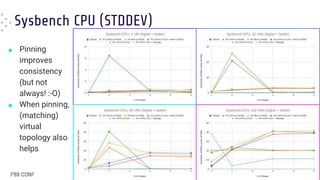
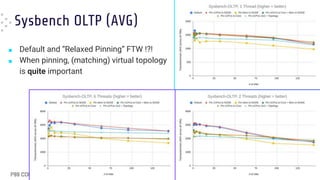
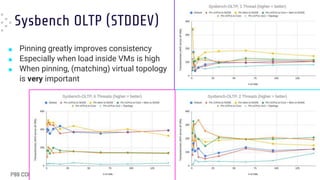
■ When in [over]load pinning results in
worse average latency
● “Default” (BLUE) FTW !!
■ Pinning still gives the best worst-case
latencies
● Especially with matching topology
● “Default” (BLUE) and “Relaxed Pinning”
(RED), in this case, are both worse
(although not that far from GREEN and
ORANGE)](https://image.slidesharecdn.com/dariofaggiolip99conf2023-240625212448-af635a6a/85/VM-Performance-The-Differences-Between-Static-Partitioning-or-Automatic-Tuning-24-320.jpg)


This document discusses the complexities of tuning virtual machines (VMs) for optimal performance, emphasizing techniques such as static partitioning, CPU and memory pinning, and managing virtual topologies. Experimental results indicate that while pinning can enhance performance consistency, its effectiveness varies based on workload and VM configuration. Tuning decisions should be informed by benchmarking and an understanding of the specific hardware setup.



































































