Downloaded 21 times






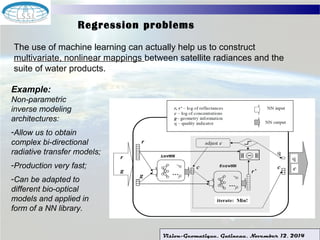
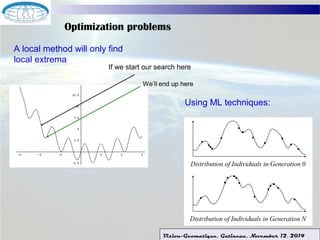



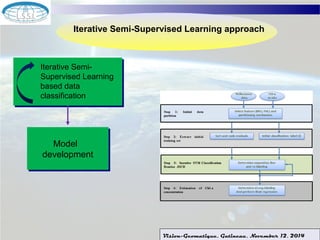
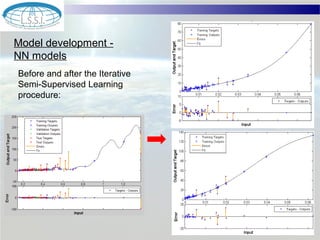

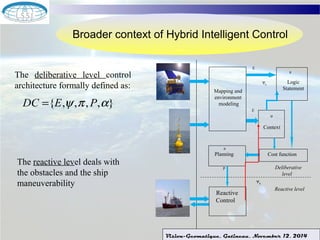

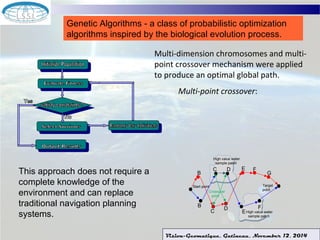





The document discusses using machine learning techniques for satellite-guided water quality monitoring. It covers using machine learning algorithms to automatically develop empirical models from multimodal satellite and field data sets. Machine learning can help construct nonlinear mappings between satellite measurements and water quality products and optimize in-situ data collection through mission planning. Experimental results are shown applying these techniques to map water quality metrics like chlorophyll-a and total suspended solids using MODIS satellite images of Lake Winnipeg.























































































