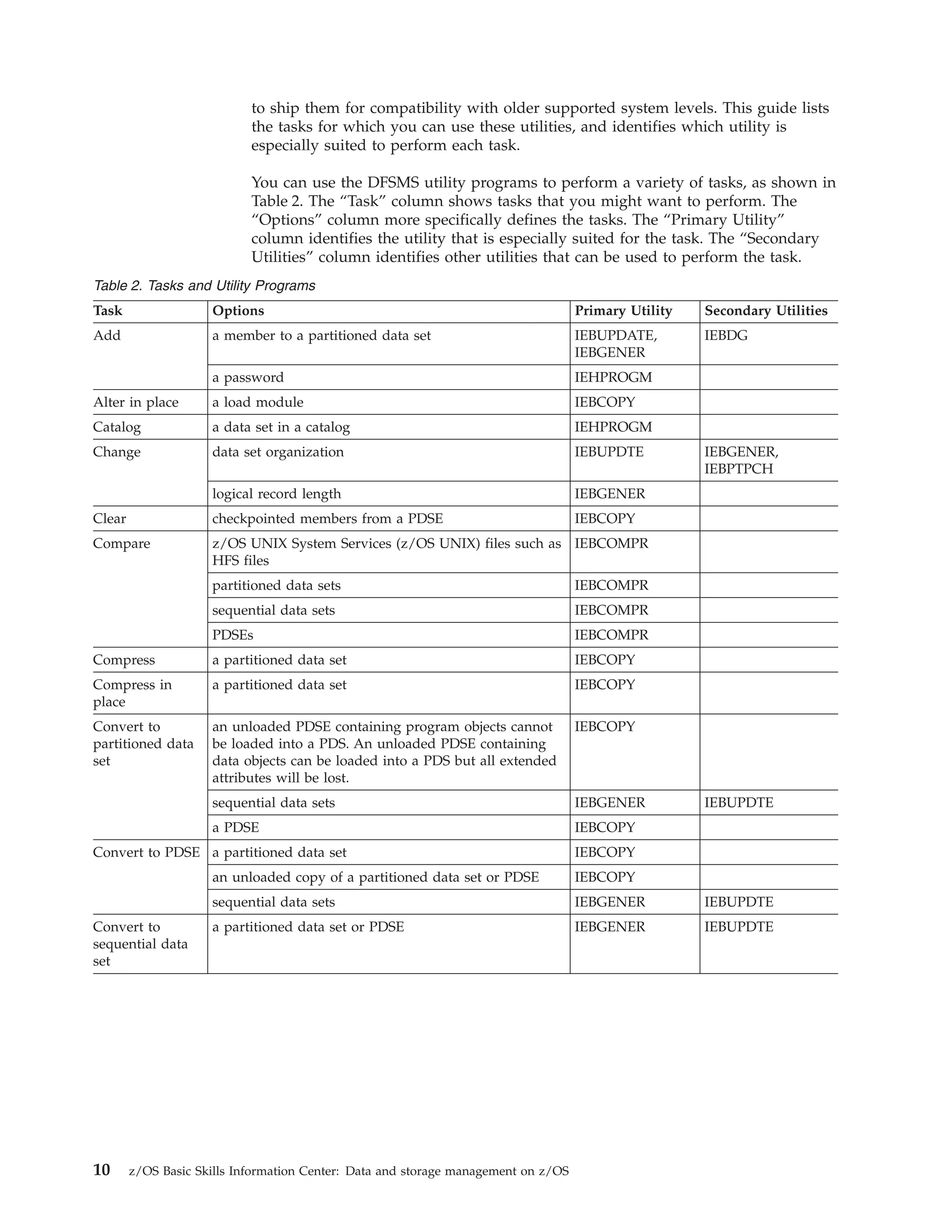
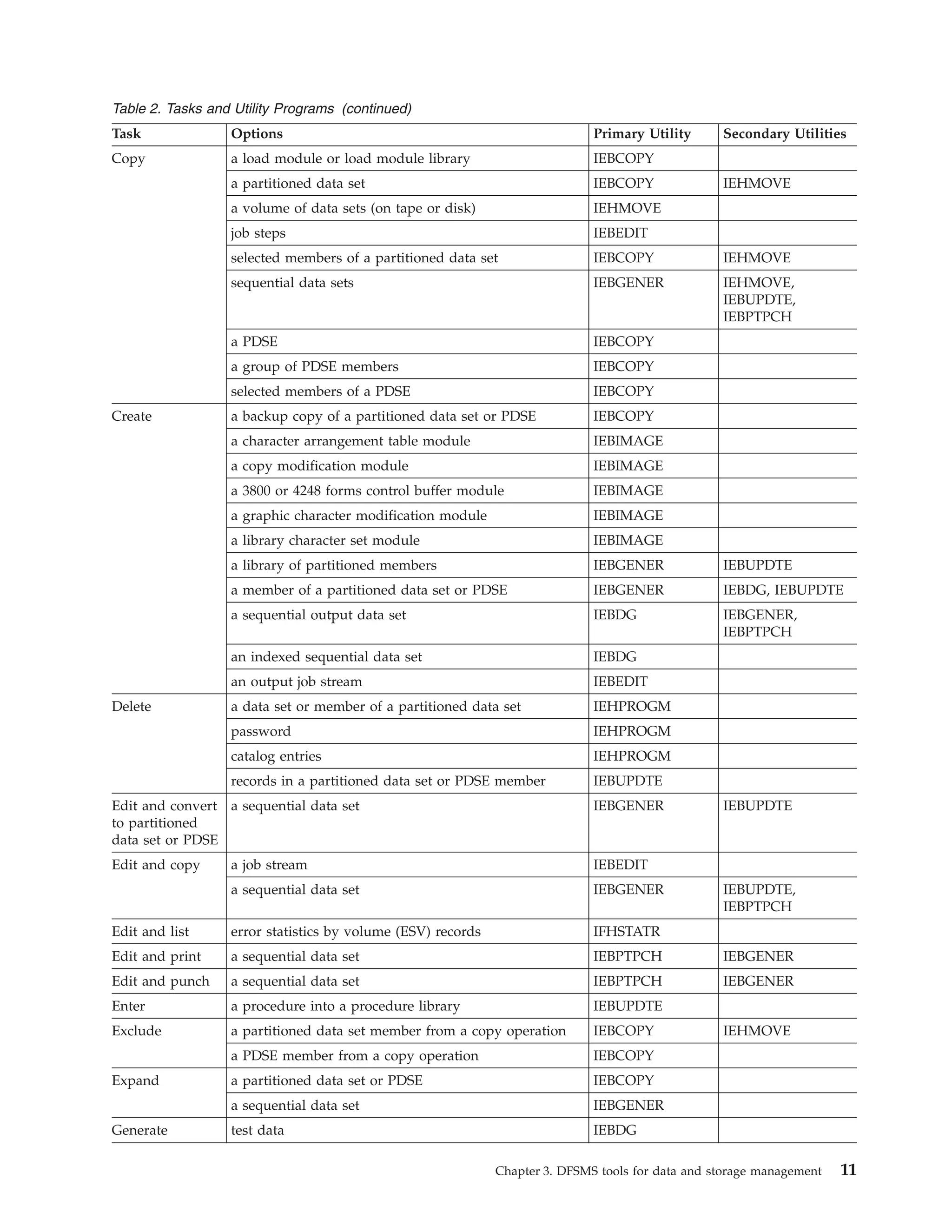
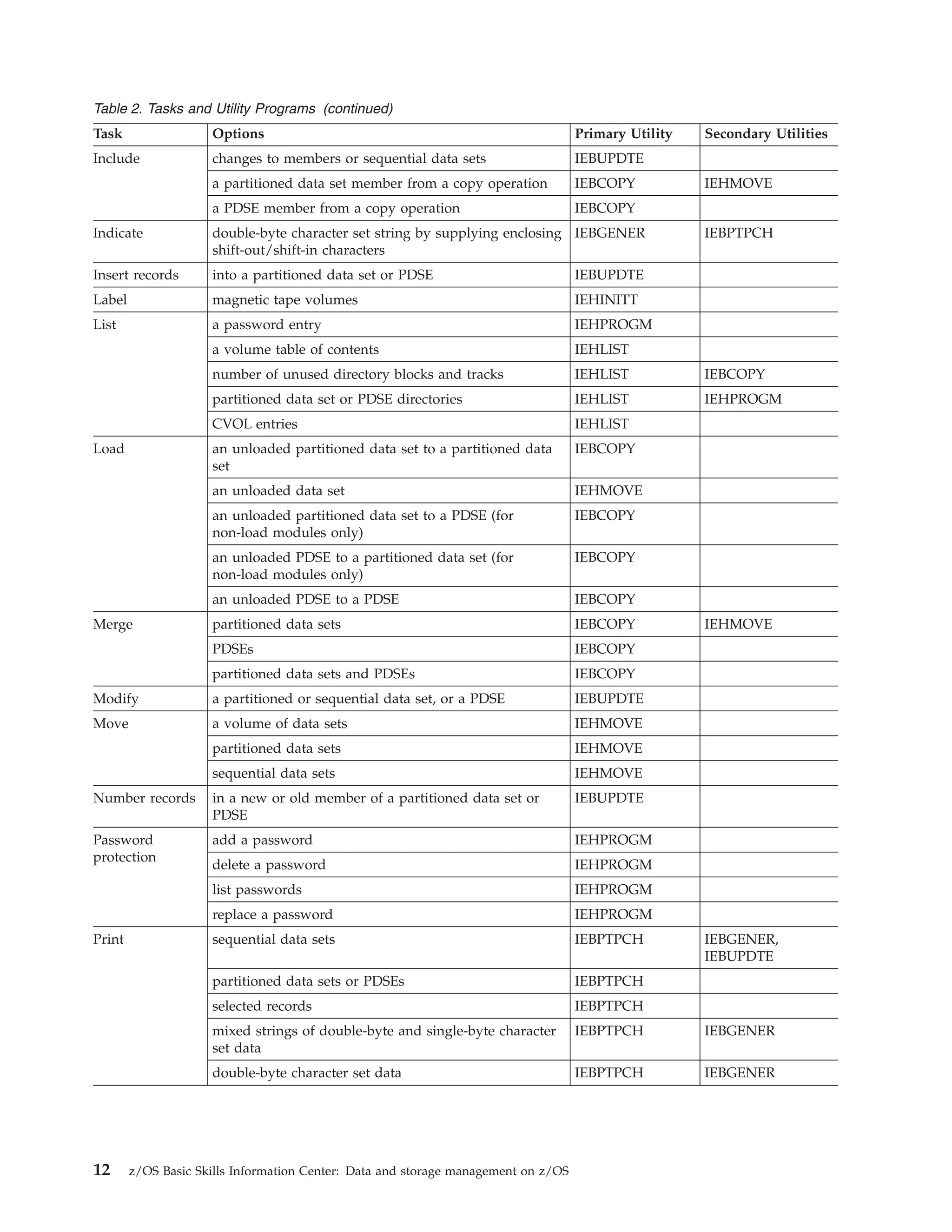
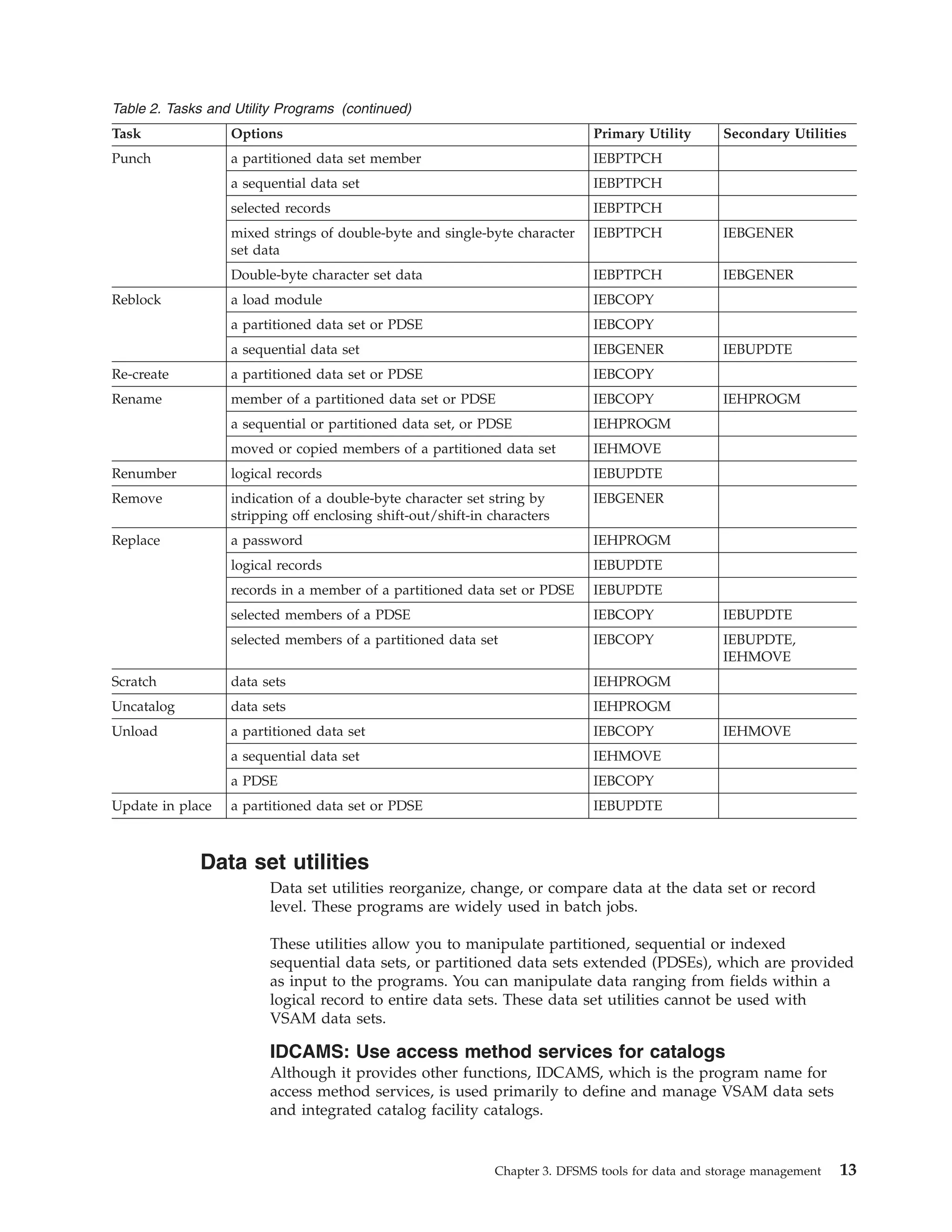
The document provides an overview of data and storage management tools available in DFSMSdfp:
1) DFSMSdfp provides several access methods for organizing and processing data, including BPAM, BSAM, QSAM, VSAM, and OAM. It also supports older access methods like BDAM.
2) Access Method Services commands can be used to define, manipulate, and maintain data sets, volumes, and catalogs.
3) Utilities like IDCAMS and IEBCOPY can copy, move, dump, and restore data.
4) Callable services allow writing advanced application programs to manage storage.
5) Installation exits can customize DFSMS functions.






























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)









