Download to read offline









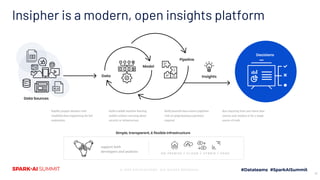
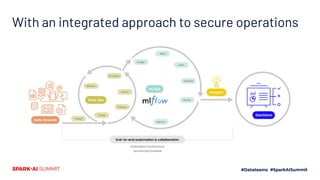
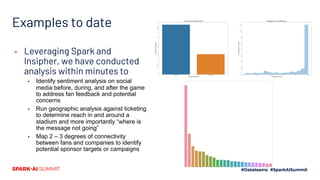




The document discusses the integration of machine learning and sports analytics to enhance fan engagement, maximize sponsorship opportunities, and improve game and player analysis within sports organizations. Key contributors David Cunningham and Young Bang highlight the interconnectedness of data sources to drive success, increase stadium attendance, and optimize business operations. The insights platform Insipher supports these efforts by simplifying data engineering and enabling scalable analytics to address fan feedback and identify profitability opportunities.

















































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Harshvardhan Jain - From Pre-Trained to Purpose-Built: Fine-T...](https://cdn.slidesharecdn.com/ss_thumbnails/zru4zmiseku5tgvu2dgw-harshvardhan-jain-from-pre-trained-to-purpose-built-fine-tuning-llms-for-high-i-260119101520-8335585f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)

