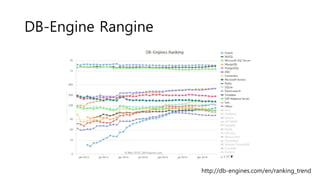
UnQLite is an embeddable, serverless, zero-configuration NoSQL database that uses a single database file with no external dependencies. It provides ACID transactions with key-value and document storage and supports efficient O(1) lookups. The database can be accessed from C code using a simple API to open and close the database, store, retrieve, append, and delete key-value pairs, and iterate over records with a cursor. It also supports loading and storing files and scripting functionality through Jx9 scripts.










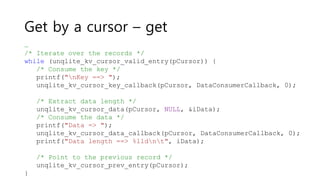


![Make random string
char zKey[12]; //Random generated key
char zData[34] = "DATA!!"; //Dummy DATA
unqlite_util_random_string(pDb, zKey, sizeof(zKey));
// Perform the insertion
rc = unqlite_kv_store(pDb, zKey, sizeof(zKey), zData,
sizeof(zData));
if (rc != UNQLITE_OK) {
break;
}](https://image.slidesharecdn.com/unqlite-160529110641/85/Unqlite-16-320.jpg)


![Jx9 script
/* Create the collection 'users' */
if( !db_exists('users') ){
/* Try to create it */
$rc = db_create('users');
}
//The following is the JSON objects to be stored shortly in our 'users' collection
$zRec = [{
name : 'james',
age : 27,
mail : 'dude@example.com'
}];
//Store our records
$rc = db_store('users',$zRec);
//One more record
$rc = db_store('users',{ name : 'alex', age : 19, mail : 'alex@example.com' });
print "Total number of stored records: ",db_total_records('users'),JX9_EOL;
//Fetch data using db_fetch_all(), db_fetch_by_id() and db_fetch().](https://image.slidesharecdn.com/unqlite-160529110641/85/Unqlite-20-320.jpg)













































































