UNIT-V
• Hashing Techniquesand Indexing Structures for Files and Physical
Database Design: Types of Single-Level Ordered Indexes, Multilevel
Indexes, Dynamic Multilevel Indexes Using B-Trees and B+-Trees
2.
Hashing Techniques
• Hashing:
•Hashing is an effective technique to calculate the direct location
of a data record on the disk without using index structure.
Hash Organization:
• Bucket: Hash file stores data in bucket format.
• Buckets are the memory locations where the records are stored.
It is also known as Unit Of Storage.
• Hash Function − A hash function, h, is a mapping function that
maps all the set of search keys K to the address where actual
records are placed. It is a function from search keys to bucket
addresses.
3.
• A commonformula for hash function is
h(k)= k mod(%) M
Where ‘k’ is the primary key value and ‘M’ is the size of the hash table.
• The range of bucket starts from 0.
• Example: Let’s say we have a table with 6 buckets(indexes 0,1,2,3,4,5)
using mod(6) Hash function.
1. Key 3: 3 mod 6=3. so, data
associated with key 3 would be stored in bucket 3
if it is empty.
2. Key 6: 6 mod 6=0. so, key 6 would be stored
In bucket 0.
4.
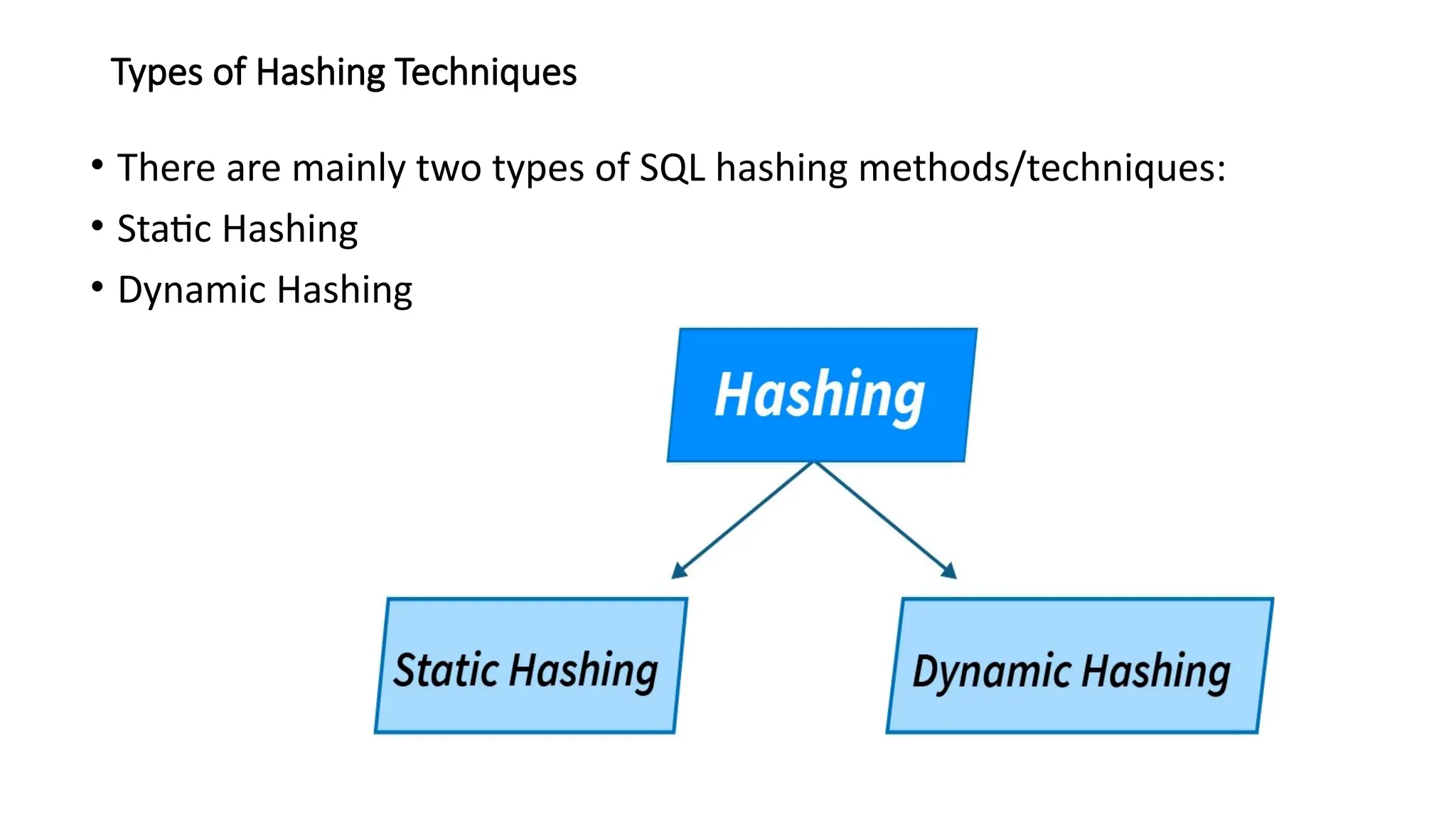
Types of HashingTechniques
• There are mainly two types of SQL hashing methods/techniques:
• Static Hashing
• Dynamic Hashing
5.
1. Static Hashing
•In static hashing, the resultant data bucket address will
always be the same.
• That means if we generate an address for EMP_ID =98 using
the hash function mod (5) then it will always result in same
bucket address 3. Here, there will be no change in the bucket
address.
• Hence in this static hashing, the number of data buckets in
memory remains constant throughout.
6.
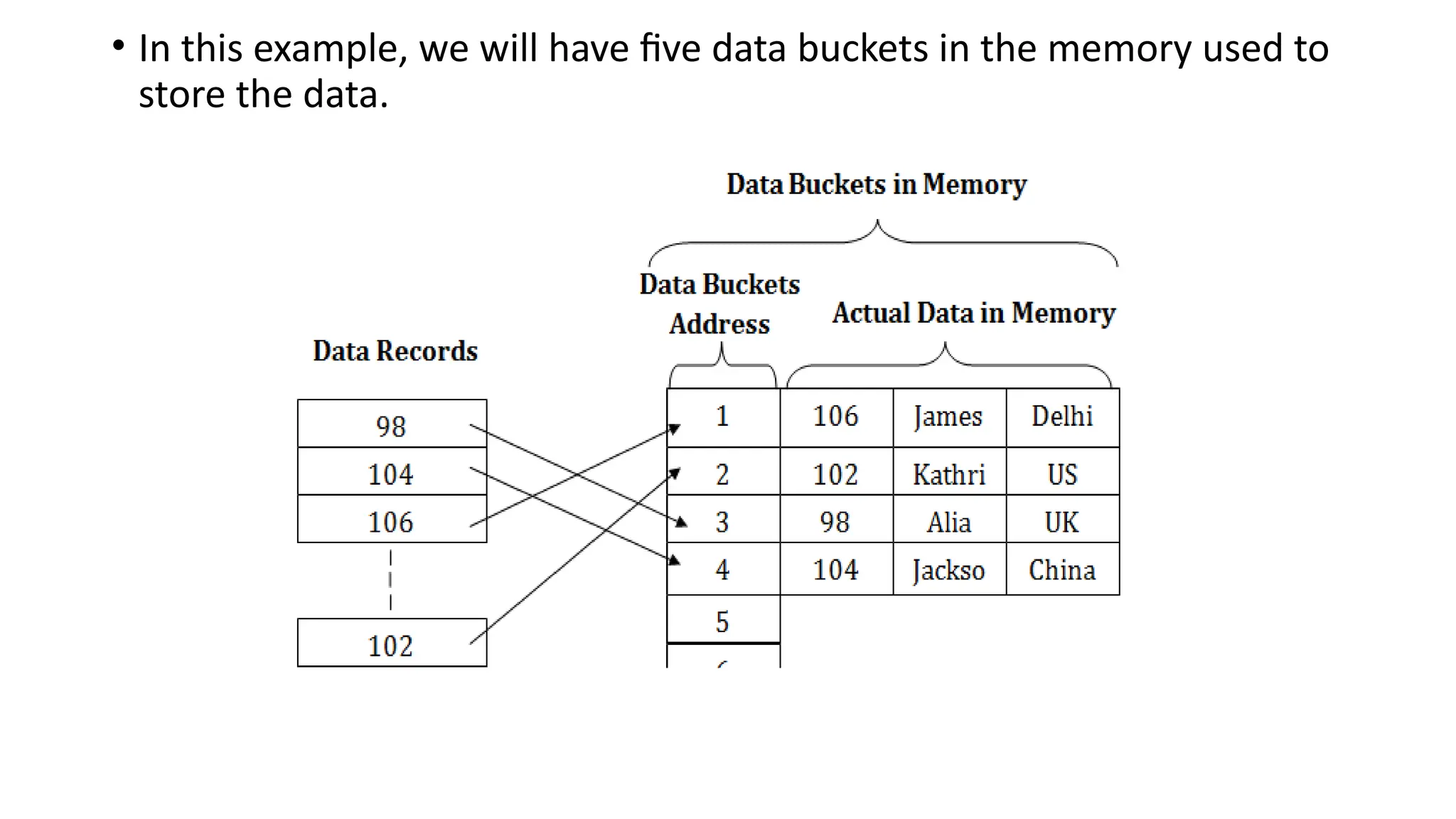
• In thisexample, we will have five data buckets in the memory used to
store the data.
7.
Operations in StaticHashing
• Searching a record:
• When a record needs to be searched, then the same hash function retrieves
the address of the bucket where the data is stored.
• Insert a Record:
• When a new record is inserted into the table, then we will generate an
address for a new record based on the hash key and record is stored in that
location.
• Delete a Record:
• To delete a record, we will first fetch the record which is supposed to be
deleted. Then we will delete the records for that address in memory.
• Update a Record:
• To update a record, we will first search it using a hash function, and then the
data record is updated.
8.
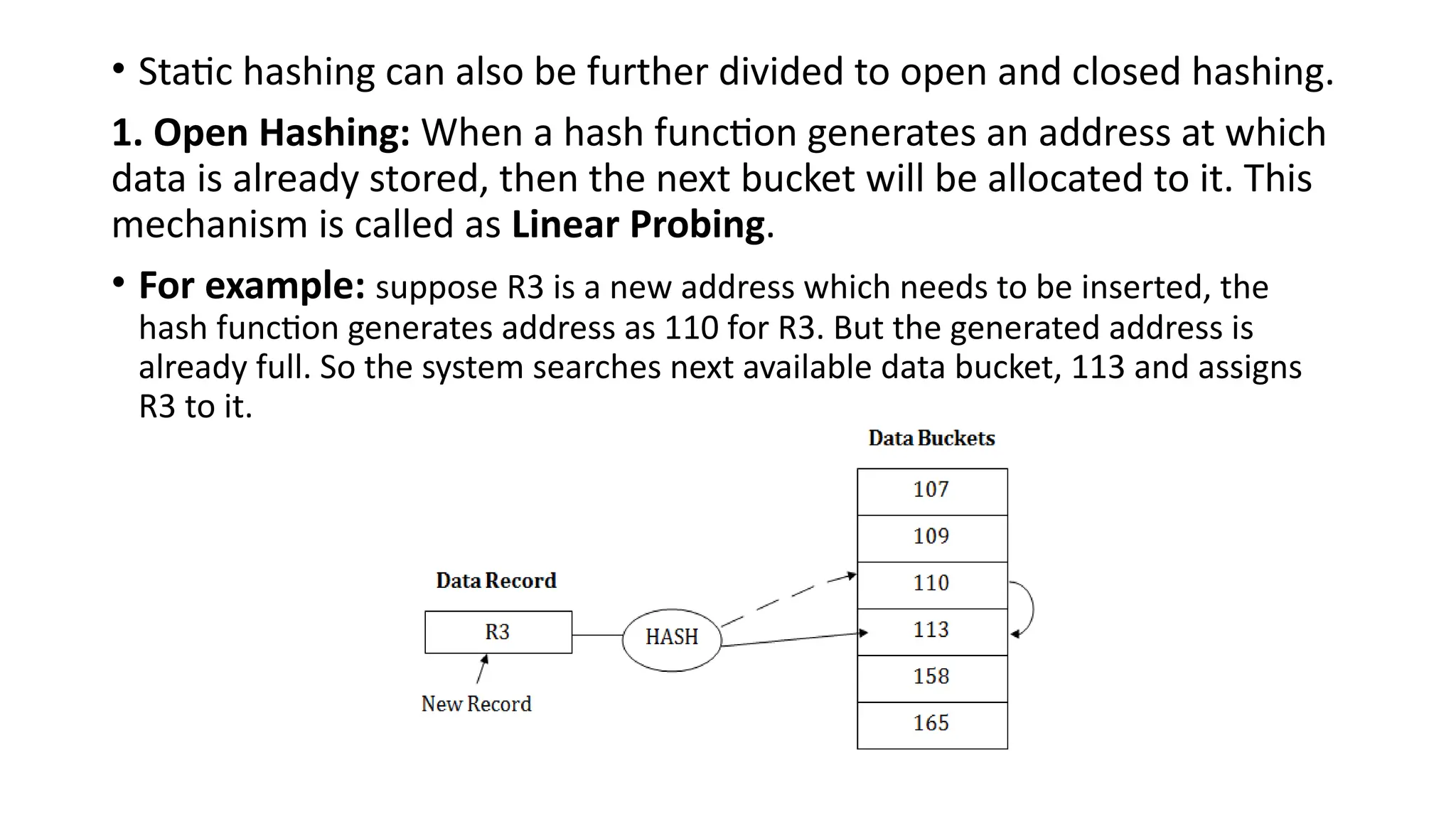
• Static hashingcan also be further divided to open and closed hashing.
1. Open Hashing: When a hash function generates an address at which
data is already stored, then the next bucket will be allocated to it. This
mechanism is called as Linear Probing.
• For example: suppose R3 is a new address which needs to be inserted, the
hash function generates address as 110 for R3. But the generated address is
already full. So the system searches next available data bucket, 113 and assigns
R3 to it.
9.
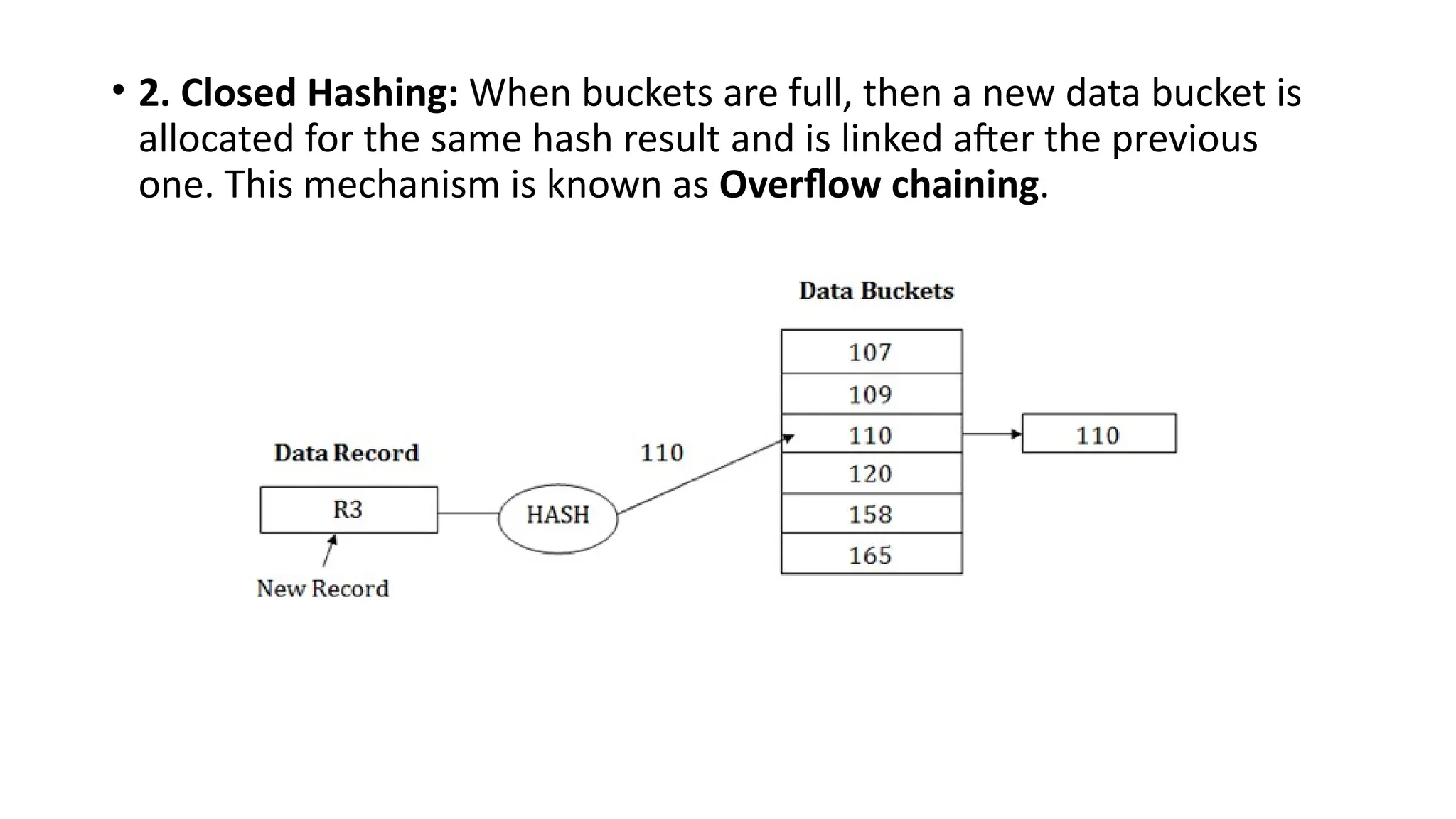
• 2. ClosedHashing: When buckets are full, then a new data bucket is
allocated for the same hash result and is linked after the previous
one. This mechanism is known as Overflow chaining.
10.
2. Dynamic Hashing
•The dynamic hashing method is used to overcome the problems of static
hashing like bucket overflow.
• In this method, data buckets grow or shrink as the records increases or
decreases. This method is also known as Extendable hashing method.
• This method makes hashing dynamic, i.e., it allows insertion or deletion
without resulting in poor performance.
Terminologies:
• Directories - These are the containers that store pointers to the buckets.
Each bucket has an "id" associated with them.
• Global depth - Global depth can be defined as the "number of bits in
directory id".
11.
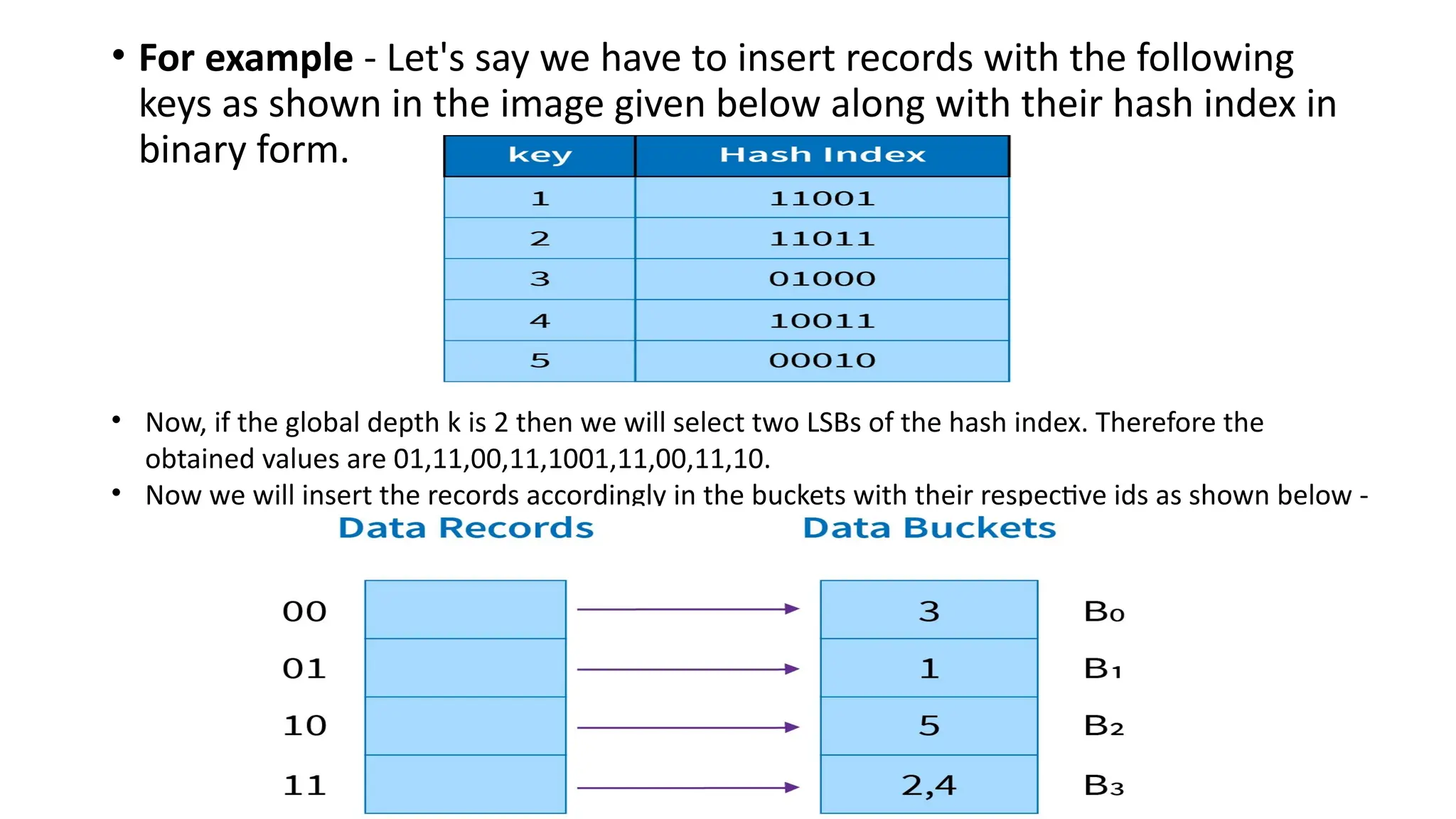
• For example- Let's say we have to insert records with the following
keys as shown in the image given below along with their hash index in
binary form.
• Now, if the global depth k is 2 then we will select two LSBs of the hash index. Therefore the
obtained values are 01,11,00,11,1001,11,00,11,10.
• Now we will insert the records accordingly in the buckets with their respective ids as shown below -
12.
Operations in DynamicHashing
• Searching a record:
• Calculate hash address of record based primary key of record.
• Convert hash address into binary form, for ex 13 is 1101.
• Select k LSBs from the binary form, where k=3, then select 101.
• Now navigate to the bucket with directory id 101.
• Inserting a record:
• Repeat the first 3 steps of searching procedure.
• Now, go to the bucket with the obtained address and insert the record there.
• Deleting a record:
• Again repeat the first 3 steps of the searching procedure.
• Now, delete the record from there.