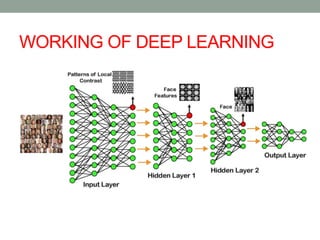
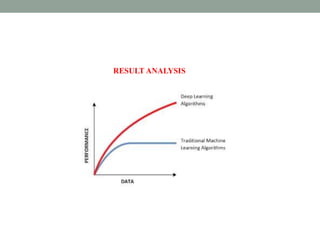
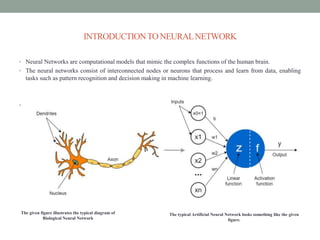
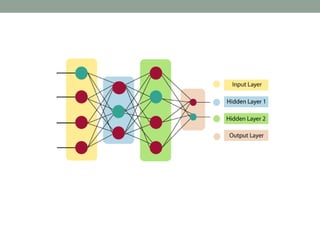
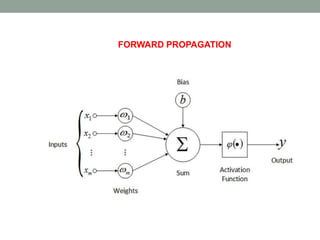
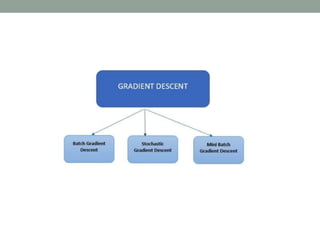
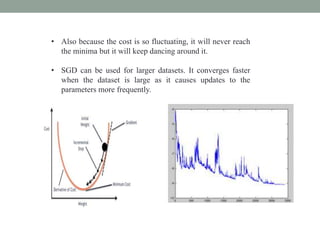
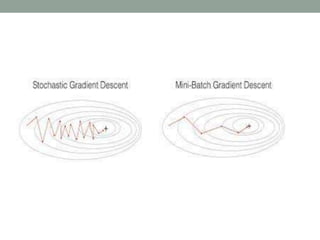
Deep learning involves using neural networks with multiple layers to automatically learn patterns from large amounts of data. The document discusses the working of deep learning networks, which take raw input data and pass it through successive hidden layers to determine higher-level features until reaching the output layer. It also covers applications of deep learning like image recognition and Amazon Alexa, as well as advantages such as automatic feature learning and ability to handle complex datasets.