1
CHAPTER 4
Deep Learning
•Concept of Deep Learning
• Introduction to Neural Networks.
• Types of Deep Learning models.
• Deep leaning applications.
Fundamental Of AI (unit 3: Basics of Machine Learning)
2.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
2
Concept of Deep Learning
• Deep Learning is transforming the way machines
understand, learn, and interact with complex data.
• Deep learning mimics neural networks of the
human brain, it enables computers to
autonomously uncover patterns and make
informed decisions from vast amounts of
unstructured data.
3.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
3
The Neuron
• Artificial neural system are inspired by biological
neural system.
• The elementary building block of biological neural
system is neuron.
• The brain is a collection of about 10 billion
interconnected neurons. Each neuron is a cell that
uses biochemical reaction to receive , process and
transmit information.
4.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
4
• Figure shows biological neural systems.
Soma
5.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
5
• Dendrites- Receive input
• Soma / Cell body – Process
• Axon - pass the Data to another neuron.
• Synapse-Small Space between the axon of one
neural & the dendrite of another.
• Terminal Axon- Next dendrite connect
• Afferent dendrites- conduct data towards the
soma
• Efferent axon- conduct data from the soma
6.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
6
Neural Network
• The word neural network referred to a network of
biological neurons in the nervous system that
process and transmits information.
• An artificial neural network is an information
processing paradigm that is inspired by the way
biological nervous system process information: ” a
large number of highly interconnected simple
processing elements working together to solve
specific problems.”
7.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
7
artificial neuron
8.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
8
• Neural networks are capable of learning and identifying
patterns directly from data without pre-defined rules.
These networks are built from several key components:
– Neurons: The basic units that receive inputs, each neuron is
governed by a threshold and an activation function.
– Connections: Links between neurons that carry information,
regulated by weights and biases.
– Weights and Biases: These parameters determine the
strength and influence of connections.
– Propagation Functions: Mechanisms that help process and
transfer data across layers of neurons.
– Learning Rule: The method that adjusts weights and biases
over time to improve accuracy.
9.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
9
• Perceptron is a type of neural network that
performs binary classification that maps input
features to an output decision, usually classifying
data into one of two categories, such as 0 or 1.
• Perceptron consists of a single layer of input nodes
that are fully connected to a layer of output
nodes. It is particularly good at learning linearly
separable patterns.
• It utilizes a variation of artificial neurons
called Threshold Logic Units (TLU)
Linear Perceptron as a neuron
10.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
10
• Basic Components of Perceptron
• A Perceptron is composed of key components that work together to process
information and make predictions.
– Input Features: The perceptron takes multiple input features, each
representing a characteristic of the input data.
– Weights: Each input feature is assigned a weight that determines its
influence on the output. These weights are adjusted during training to find
the optimal values.
– Summation Function: The perceptron calculates the weighted sum of its
inputs, combining them with their respective weights along with bias value.
– Activation Function: The weighted sum is passed through the Heaviside step
function, comparing it to a threshold to produce a binary output (0 or 1).
– Output: The final output is determined by the activation function, often used
for binary classification tasks.
– Bias: The bias term helps the perceptron make adjustments independent of
the input, improving its flexibility in learning.
– Learning Algorithm: The perceptron adjusts its weights and bias using a
learning algorithm, such as the Perceptron Learning Rule, to minimize
prediction errors.
11.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
11
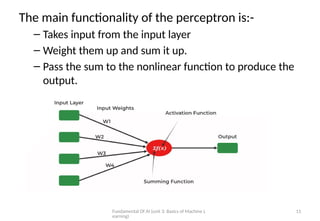
The main functionality of the perceptron is:-
– Takes input from the input layer
– Weight them up and sum it up.
– Pass the sum to the nonlinear function to produce the
output.
12.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
12
• How does it work?
– In the first stage, the linear combination of inputs is
calculated. Each value of input array is associated with
its weight value which is normally between 0 and 1.
Also the summation function often takes an extra input
value Theta with weight value of 1 to represent
threshold or bias of a neuron.
– In the simplest case the network has only two input
and a single output. The output of neuron is
Y = f (
Suppose that the activation function is a threshold then
f = 1 if s>0
-1 if s<=0
13.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
13
• Perceptron can represent most of primitive Boolean functions: AND ,
OR, NAND and NOR but cannot represent XOR.
• The single layer perceptron does not have a priori knowledge, so the
initial weights are assigned randomly. It sums all the weighted inputs
and if the sum is above the threshold (some predetermined value),
SLP is said to be activated (output=1).
• The input values are presented to the perceptron, and if the
predicted output is the same as the desired output, then the
performance is considered satisfactory and no changes to the weights
are made. However, if the output does not match the desired output,
then the weights need to be changed to reduce the error.
14.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
14
• The weight adjustment is does as follows:
• If output of perceptron is correct then we do not take any action. If
the output is incorrect then the weight vector is w w + ∆w
• The process of weight adjustment is called Learning.
15.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
15
• Perceptron learning algorithm
1. Select random sample from training set as input
2. If Classification is correct, do nothing
3. If Classification is incorrect, modify the weight vector
w using
= +η d (n) (n)
Repeat this procedure until the entire training set is
classified correctly.
a. The term is referred to as active or excitatory if its value is
1.
b. If the value is 0 then it is inactive.
c. If the value is -1 then it is inhibitory.
16.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
16
• Activation function of perceptron is typically either
a signum function sgn(x) or step function step(x):
sgn(x) = 1 if x>0
-1 otherwise
step(x) = 1 if x>0
0 otherwise
17.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
17
Feed Forward Neural Network
• A Feed forward Neural Network (FNN) is a type of
artificial neural network where information moves
only in one direction, from the input layer through
any hidden layers and finally to the output layer.
• There are no cycles or loops in the network.
• There are two key development
– MLP(multi- layer Perceptron)
– Back propagation algorithm
18.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
18
Multilayer Perceptron
• In multi layer feed forward neural networks, the sigmoid
activation function defined by
g(x) =
• A Multilayer Perceptron (MLP) consists of an input layer, one
or more hidden layers, and an output layer.
• Multi layer perceptron are able to cope with non – linearly
separable problems.
• Each neuron in one layer has direct connections to all the
neuron of subsequent layer.
• MLP can implement non linear discriminants(for classification)
and non linear regression function (for regression.)
• There were no known learning algorithms for training MLP.
19.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
19
Backpropagation:
• The procedure for finding a gradient vector in the network
structure is generally referred to as back propagation.
• Procedure of back propagation:
– The output values are compared with the target to compute the
value of some predefined error function.
– The error is then feedback through the network
– Using this information , the algorithm adjust the weights of each
connection in order to reduce the value of the error function.
• Generally the back propogation network has two stages ,
training and testing. During the training phase the network
is shown simple input and the correct classifications.
20.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
20
• Three most commonly used activation functions in back
propagation MLPs are:
– Logistic function
f(x) =
– Hyperbolic tangent function:
f(x) = tan h
(x/2)=
– Identify function
f(x) = x
21.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
21
• Both the hyperbolic tangent function and logistic function
approximate the signum and step function respectively.
Sometimes these two function are referred to as squashing
functions since the input to these function are squashed to the
range [0,1] or [-1,1].
• These function are also called sigmoidal functions because their
s shaped curves exhibits smoothness and asymptotic properties.
• A learning process is organized through a learning algorithm,
which is a process of updating the weights in such a way that a
machine learning tool implements a given input/output
mapping with no errors or with some minimal acceptable error.
• Any learning algorithm is based on a certain learning rule, which
determines how the weights shall be updated if the error
occurs.
22.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
22
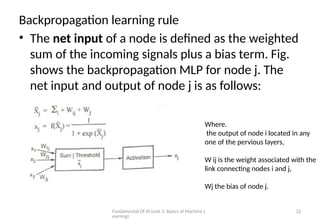
Backpropagation learning rule
• The net input of a node is defined as the weighted
sum of the incoming signals plus a bias term. Fig.
shows the backpropagation MLP for node j. The
net input and output of node j is as follows:
Where.
the output of node i located in any
one of the pervious layers,
W ij is the weight associated with the
link connecting nodes i and j,
Wj the bias of node j.
23.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
23
• Internal parameters associated with each node j is
the weight Wij. So changing the weights of the
node will change the behaviour of the whole
backpropagation MLP.
• Fig. shows two layer backpropagation MLP. Also
refer 3-4-3 network
24.
24
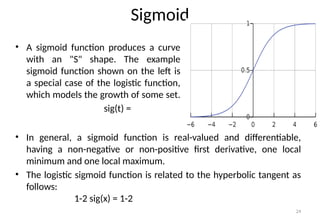
Sigmoid
• A sigmoidfunction produces a curve
with an "S" shape. The example
sigmoid function shown on the left is
a special case of the logistic function,
which models the growth of some set.
sig(t) =
• In general, a sigmoid function is real-valued and differentiable,
having a non-negative or non-positive first derivative, one local
minimum and one local maximum.
• The logistic sigmoid function is related to the hyperbolic tangent as
follows:
1-2 sig(x) = 1-2
25.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
25
• Sigmoid functions are often used in artificial neural
networks to introduce nonlinearity in the model.
• A neural network element computes a linear combination
of its input signals and applies a sigmoid function to the
result.
• A reason for its popularity in neural networks is because
the sigmoid function satisfies a property between the
derivative and itself such that it is computationally easy to
perform.
sig(t) = sig(t)(1-sig(t))
• Derivatives of the sigmoid function are usually employed
in learning algorithms
26.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
26
Zero-Centering
• Feature normalization is often required to neutralize the effect
of different quantitative features being measured on different
scales. If the features are approximately normally distributed,
we can convert them into z-scores by centring on the mean and
dividing by the standard deviation. If we don't want to assume
normality we can centre on the median and divide by the
interquartile range.
• Sometimes feature normalization is understood in the stricter
sense of expressing the feature on a [0,1] scale. If we know the
feature's highest and lowest values h and I, then we can simply
apply the linear scaling.
27.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
27
• Feature calibration is understood as a supervised feature transformation
adding a meaningful scale carrying class information to arbitrary features.
This has a number of important advantages. For instance, it allows models
that require scale, such as linear classifiers, to handle categorical and
ordinal features. It also allows the learning algorithm to choose whether
to treat a feature as categorical, ordinal or quantitative.
• The goal of both types of normalization is to make it easier for your
learning algorithm to learn. In feature normalization, there are two
standard things to do:
• 1. Centering: Moving the entire data set so that it is centered around the
origin.
• 2. Scaling: Rescaling each feature so that one of the following holds:
– a) Each feature has variance I across the training data.
– b) Each feature has maximum absolute value 1 across the training
data.
• The goal of centering is to make sure that no features are arbitrarily large.
28.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
28
Tanh and ReLU Neuron
• Tanh is also like logistic sigmoid but
better. The range of the tanh function is
from (-1 to 1). Tanh is also sigmoidal (s -
shaped).
• Fig. shows tanh v/s Logistic sigmoid.
• Tanh neuron is simply a scaled sigmoid
neuron.
• Problems resolved by Tanh
1. The output is not zero centered
2. Small gradientof sigmoid function
• ReLU (Rectified Linear Unit) is the most
used activation function in the world
right now.Since, it is used in almost all
the convolution neural networks or deep
learning.
29.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
29
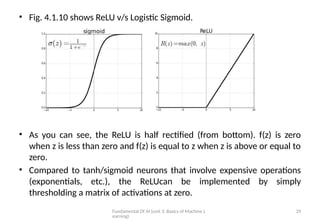
• Fig. 4.1.10 shows ReLU v/s Logistic Sigmoid.
• As you can see, the ReLU is half rectified (from bottom). f(z) is zero
when z is less than zero and f(z) is equal to z when z is above or equal to
zero.
• Compared to tanh/sigmoid neurons that involve expensive operations
(exponentials, etc.), the ReLUcan be implemented by simply
thresholding a matrix of activations at zero.
30.
Fundamental Of AI(unit 3: Basics of Machine L
earning)
30
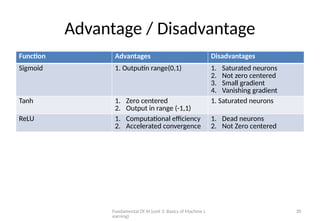
Advantage / Disadvantage
Function Advantages Disadvantages
Sigmoid 1. Outputin range(0,1) 1. Saturated neurons
2. Not zero centered
3. Small gradient
4. Vanishing gradient
Tanh 1. Zero centered
2. Output in range (-1,1)
1. Saturated neurons
ReLU 1. Computational efficiency
2. Accelerated convergence
1. Dead neurons
2. Not Zero centered

















![Fundamental Of AI (unit 3: Basics of Machine L
earning)
21
• Both the hyperbolic tangent function and logistic function
approximate the signum and step function respectively.
Sometimes these two function are referred to as squashing
functions since the input to these function are squashed to the
range [0,1] or [-1,1].
• These function are also called sigmoidal functions because their
s shaped curves exhibits smoothness and asymptotic properties.
• A learning process is organized through a learning algorithm,
which is a process of updating the weights in such a way that a
machine learning tool implements a given input/output
mapping with no errors or with some minimal acceptable error.
• Any learning algorithm is based on a certain learning rule, which
determines how the weights shall be updated if the error
occurs.](https://image.slidesharecdn.com/unit4-250626065812-9f847124/85/Unit-4-deep-learning-lecture-notes-presentation-21-320.jpg)


![Fundamental Of AI (unit 3: Basics of Machine L
earning)
26
Zero-Centering
• Feature normalization is often required to neutralize the effect
of different quantitative features being measured on different
scales. If the features are approximately normally distributed,
we can convert them into z-scores by centring on the mean and
dividing by the standard deviation. If we don't want to assume
normality we can centre on the median and divide by the
interquartile range.
• Sometimes feature normalization is understood in the stricter
sense of expressing the feature on a [0,1] scale. If we know the
feature's highest and lowest values h and I, then we can simply
apply the linear scaling.](https://image.slidesharecdn.com/unit4-250626065812-9f847124/85/Unit-4-deep-learning-lecture-notes-presentation-26-320.jpg)