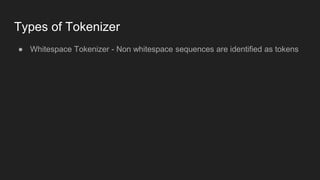
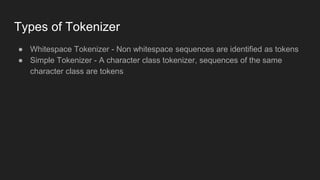
The document discusses tokenization in Natural Language Processing (NLP), highlighting its function of segmenting input character sequences into tokens, including words, numbers, and punctuation. It describes various types of tokenizers such as whitespace tokenizers, simple tokenizers, and learnable tokenizers. Each tokenizer has distinct methods for identifying tokens based on specific criteria.