Downloaded 34 times


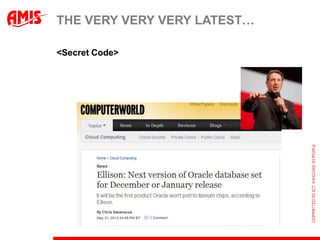


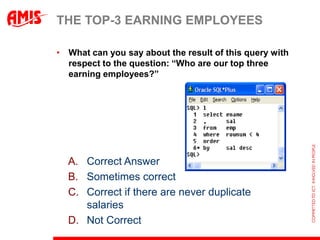
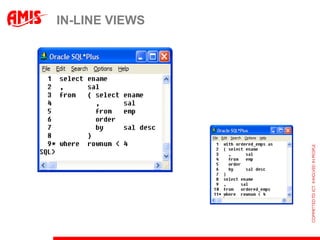


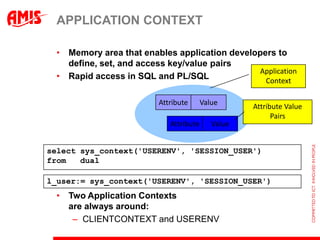











![GET THIS WEEK‟S GROCERIES
getGroceries Item[] ( String[] shoppingList) {
Item[] items = new Item[ shoppingList.length];
for (int i=0; i < shoppingList.length; i++) {
items[i] = shopForItem (shoppingList[i]);
}
return items;
}](https://image.slidesharecdn.com/oow2012theveryverylatestindatabasedevelopment-120929085029-phpapp01/85/The-Very-Very-Latest-in-Database-Development-Oracle-Open-World-2012-35-320.jpg)

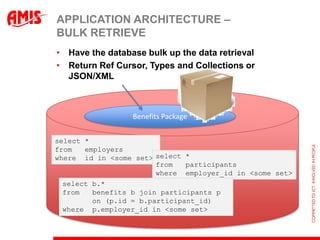
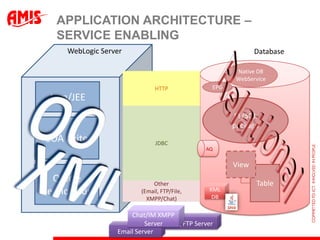
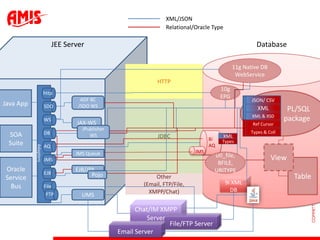
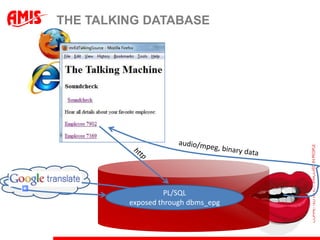


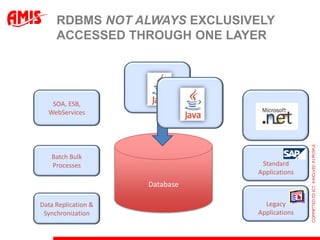


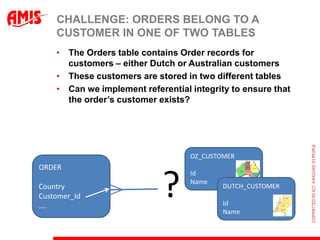
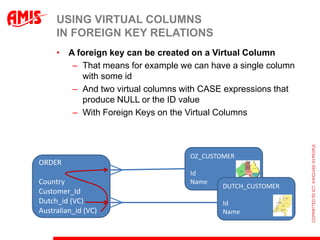
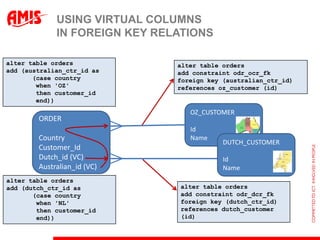

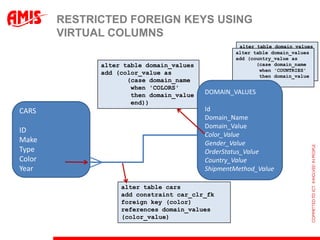


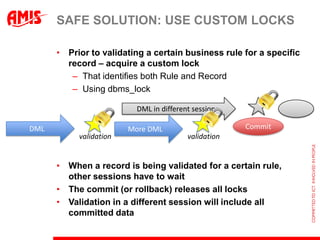


The document discusses using virtual columns in Oracle databases to implement business rules and uniqueness constraints across tables in a declarative way. Virtual columns allow expressing attributes as SQL expressions of real columns, enabling indexing and foreign key constraints that check rules involving multiple tables or columns. Business rules that were previously only possible through procedural logic can now be enforced at the database level through virtual columns.



































































