Download to read offline




![My Next Processors
4000
3000
Cache Size [kB]
2000
1000
0
66 200 1000 2250 1600 2400 2400
MHz MHz MHz MHz MHz MHz MHz
Apr-94
Apr-98
Nov-01
May-04
Jul-06
Jul-08
Mar-11
5/4/11 4](https://image.slidesharecdn.com/multicore-mem-110404222315-phpapp01/85/CSTalks-The-Multicore-Midlife-Crisis-30-Mar-4-320.jpg)
![My Next Processors
4000
3000
Cache Size [kB]
2000
1000
0
66 200 1000 2250 1600 2400 2400
MHz MHz MHz MHz MHz MHz MHz
Apr-94
Apr-98
Nov-01
May-04
Jul-06
Jul-08
Mar-11
5/4/11 5](https://image.slidesharecdn.com/multicore-mem-110404222315-phpapp01/85/CSTalks-The-Multicore-Midlife-Crisis-30-Mar-5-320.jpg)

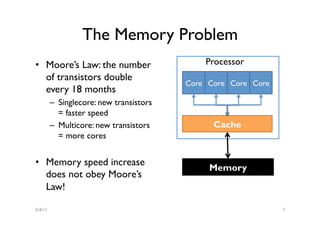
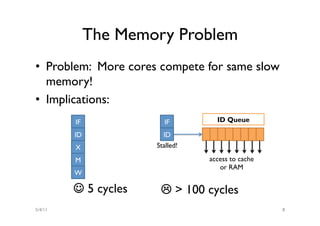

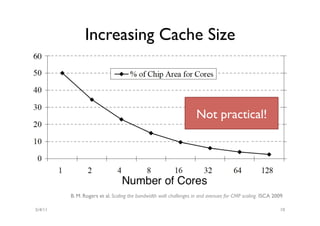


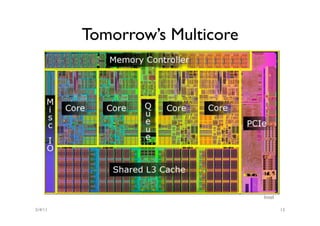








The document discusses the multicore midlife crisis as processors move to multiple cores to cope with Moore's Law. As core counts increase, the memory bandwidth does not scale accordingly, creating a memory wall problem. Solutions proposed include increasing cache sizes, improving memory speeds, and better caching techniques. Future multicore designs may focus more on heterogeneous cores tailored for different workloads rather than increasing core counts uniformly. Research challenges include coping with heterogeneity, improving data locality given slow memory speeds, and software techniques to help address issues like cache coherence.









































