Download to read offline



























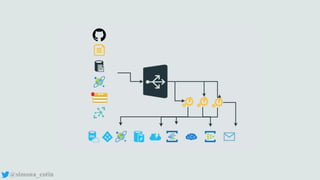




























The document discusses concepts related to automated deployments and infrastructure management using technologies like Terraform, Helm, and Azure Resource Manager. It highlights the importance of containers in packaging applications and mentions Kubernetes for managing containerized applications. Additionally, it addresses topics such as scaling, observability, and load balancing in software development.























![[WSO2Con Asia 2018] Architecting for Container-native Environments](https://cdn.slidesharecdn.com/ss_thumbnails/v2-wso2con2018-architectingforcontainernativeenvironments-180810085834-thumbnail.jpg?width=640&height=640&fit=bounds)










































