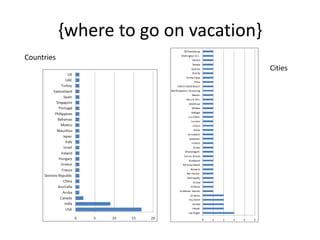
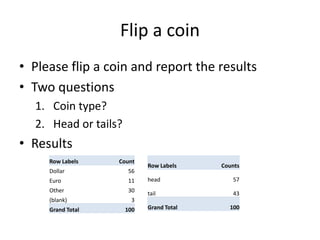
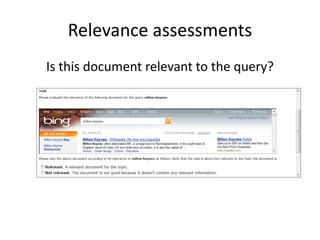
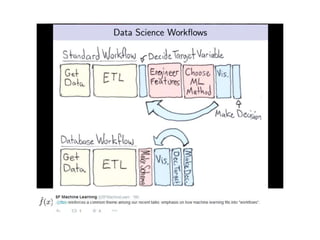
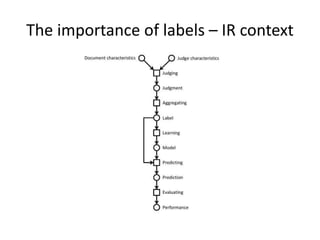
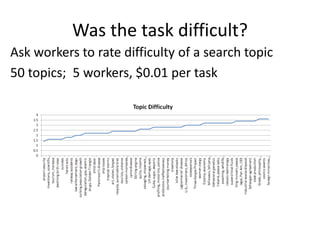
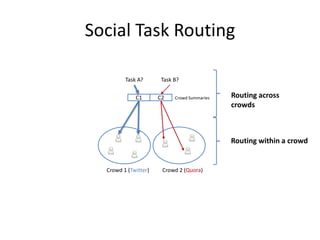
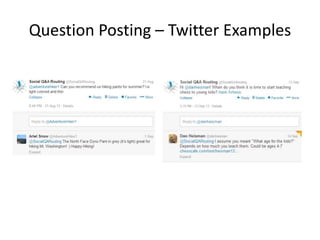
This document summarizes a talk on human computation and crowdsourcing from an industrial perspective. It discusses how crowdsourcing can provide large amounts of cheap labeled data through platforms like Mechanical Turk but that ensuring high quality labels requires careful task design, payments, quality control methods and addressing issues like worker experience and content. Current trends include algorithms for optimizing human-machine workflows and routing tasks between crowds based on their expertise.