Downloaded 10 times






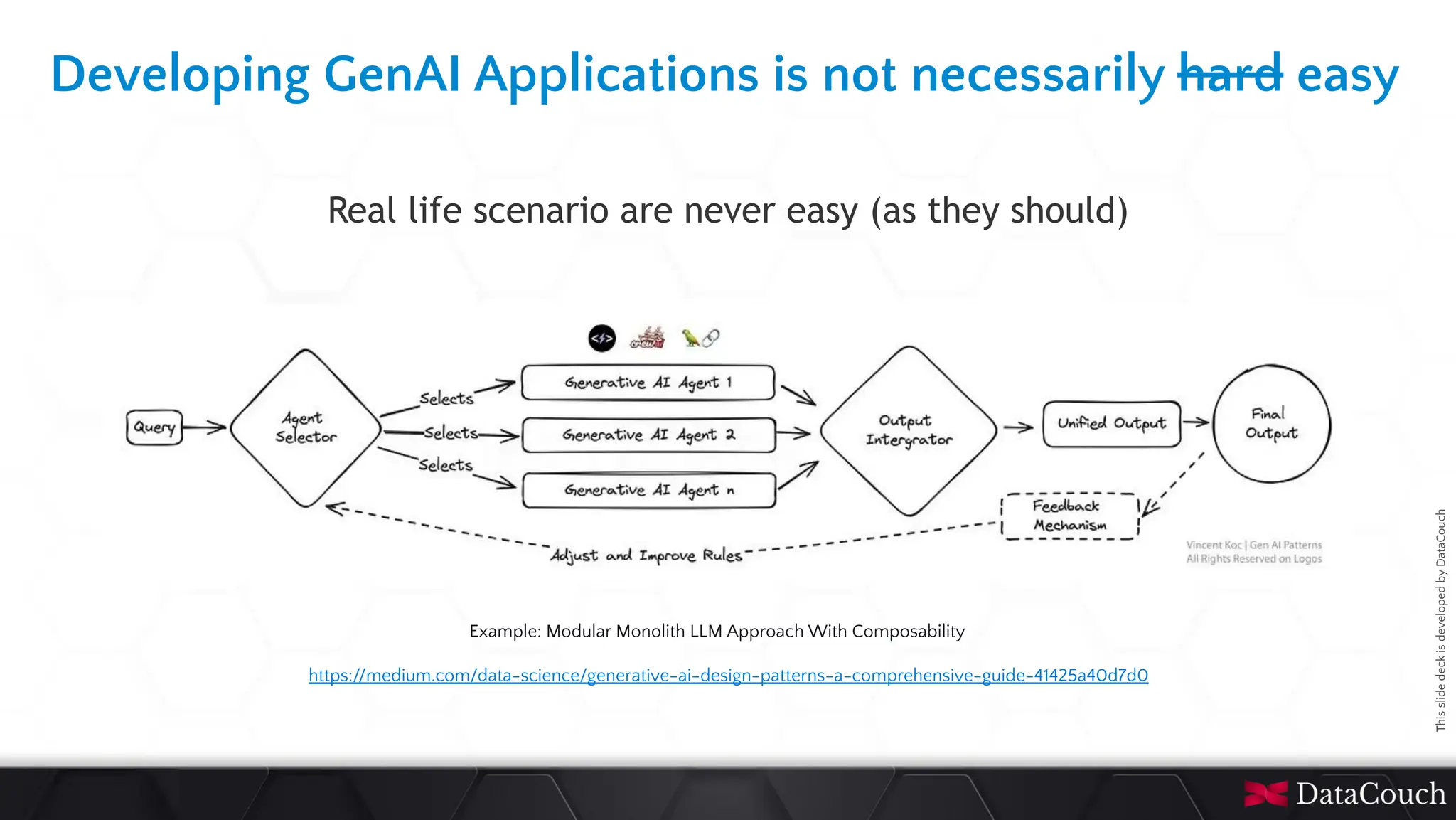
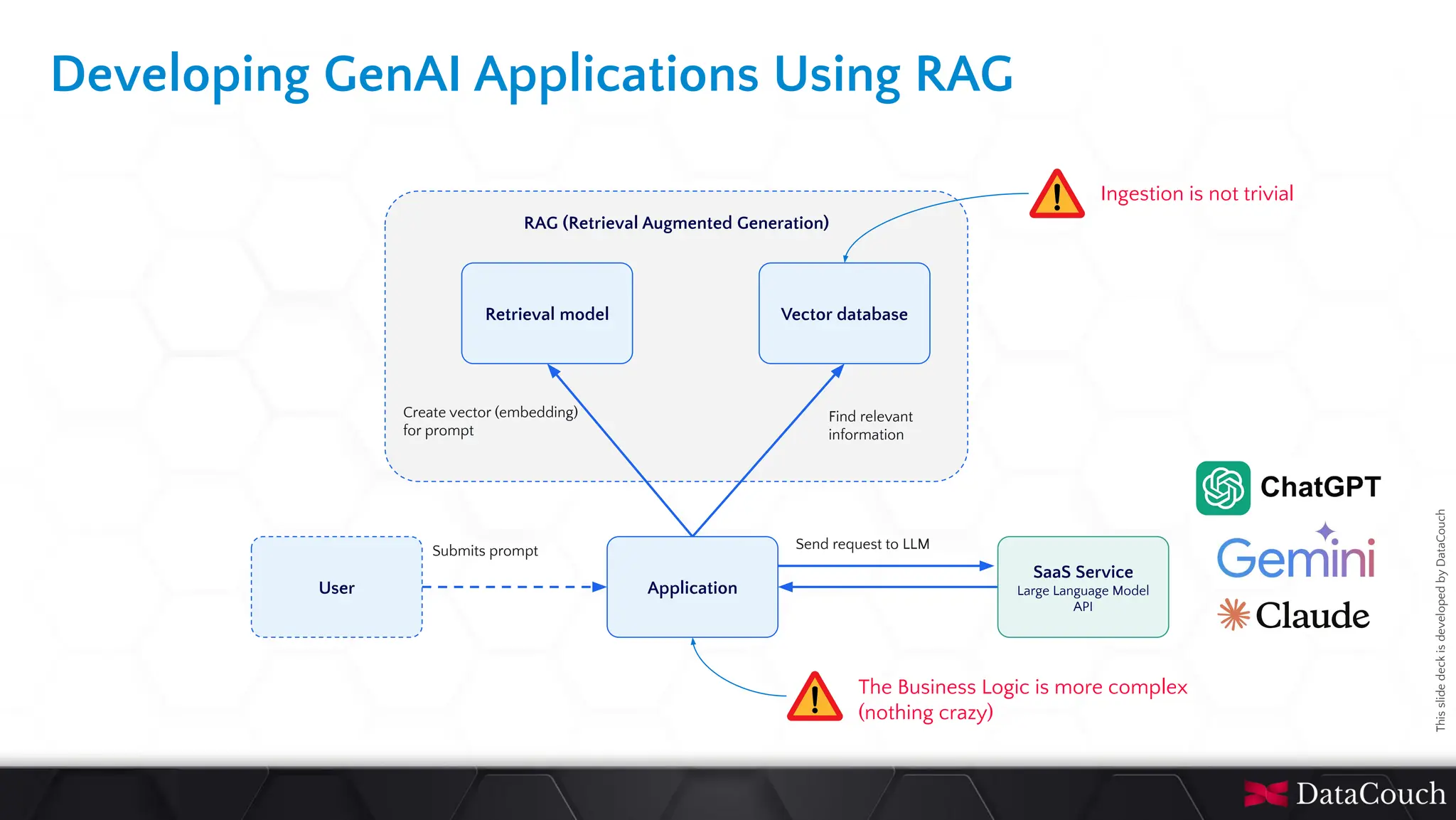
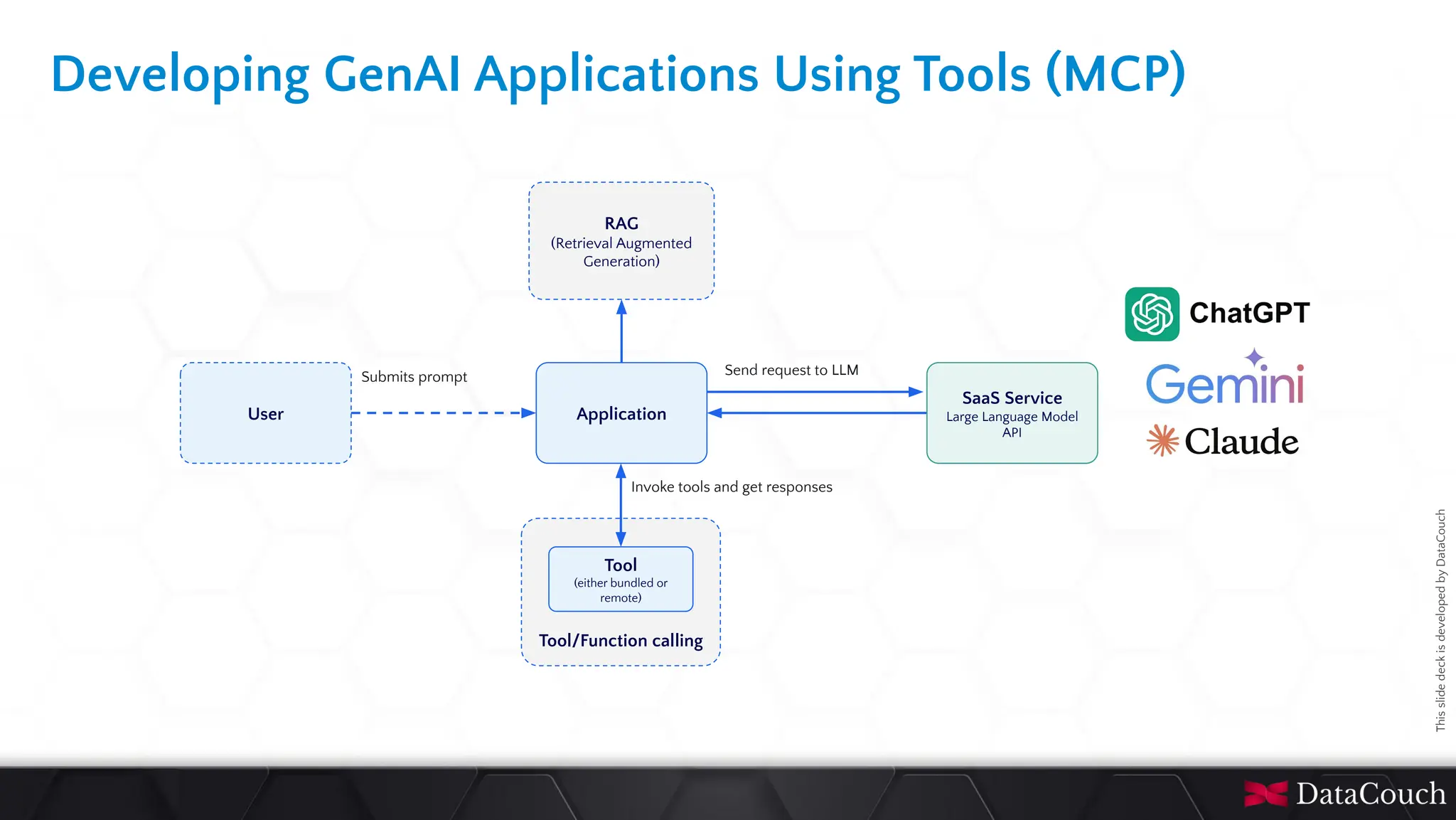
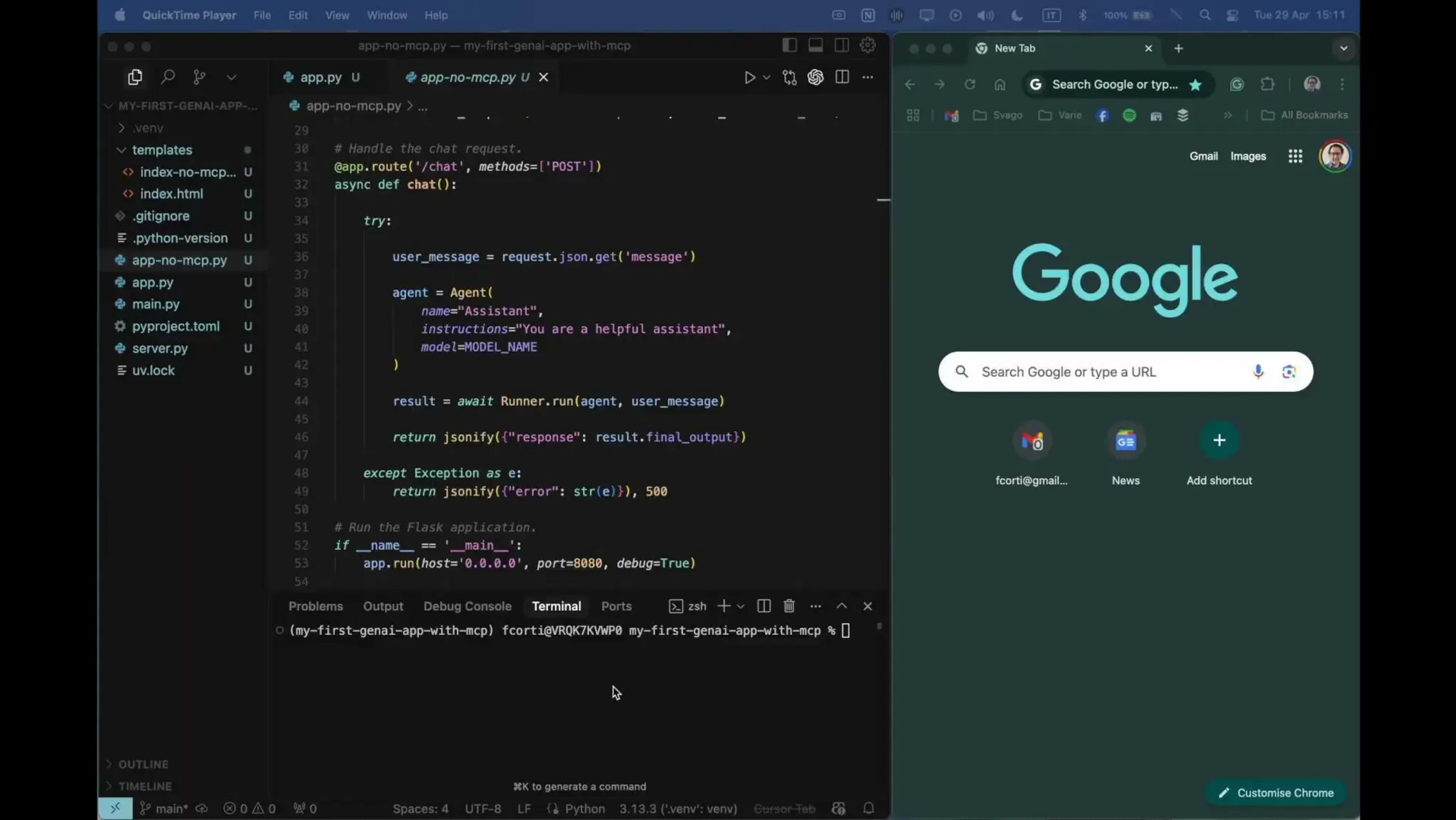
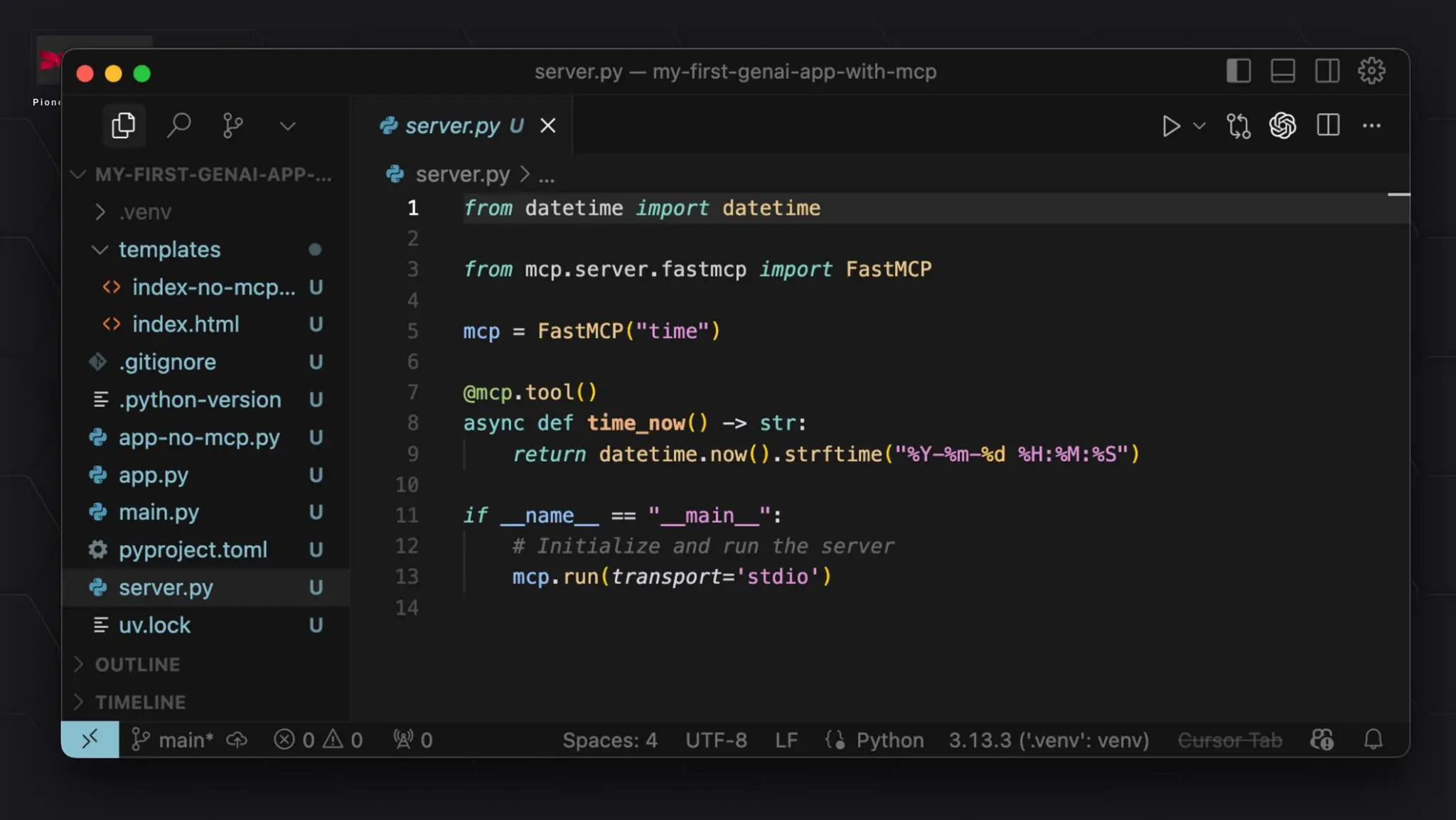
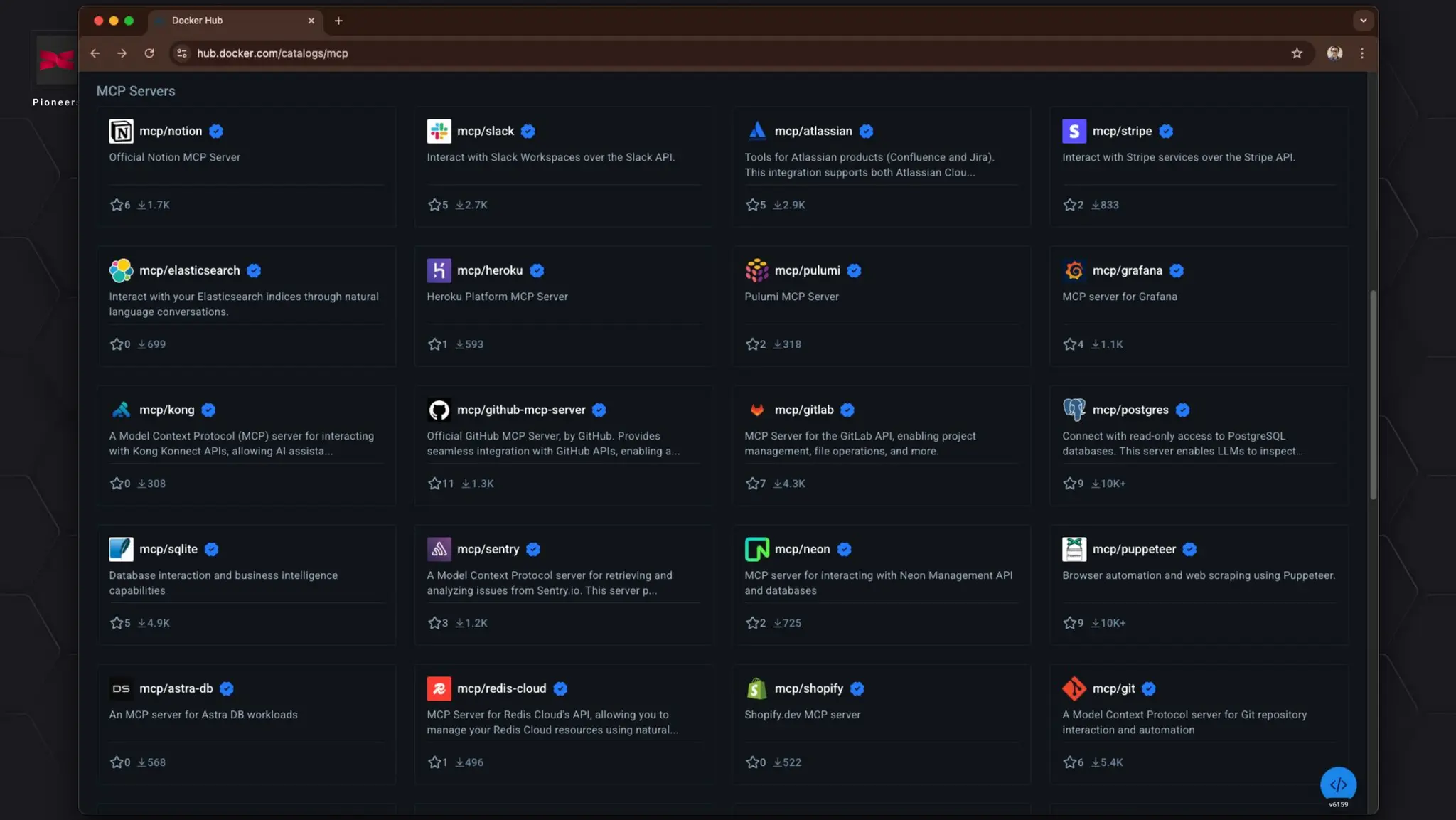
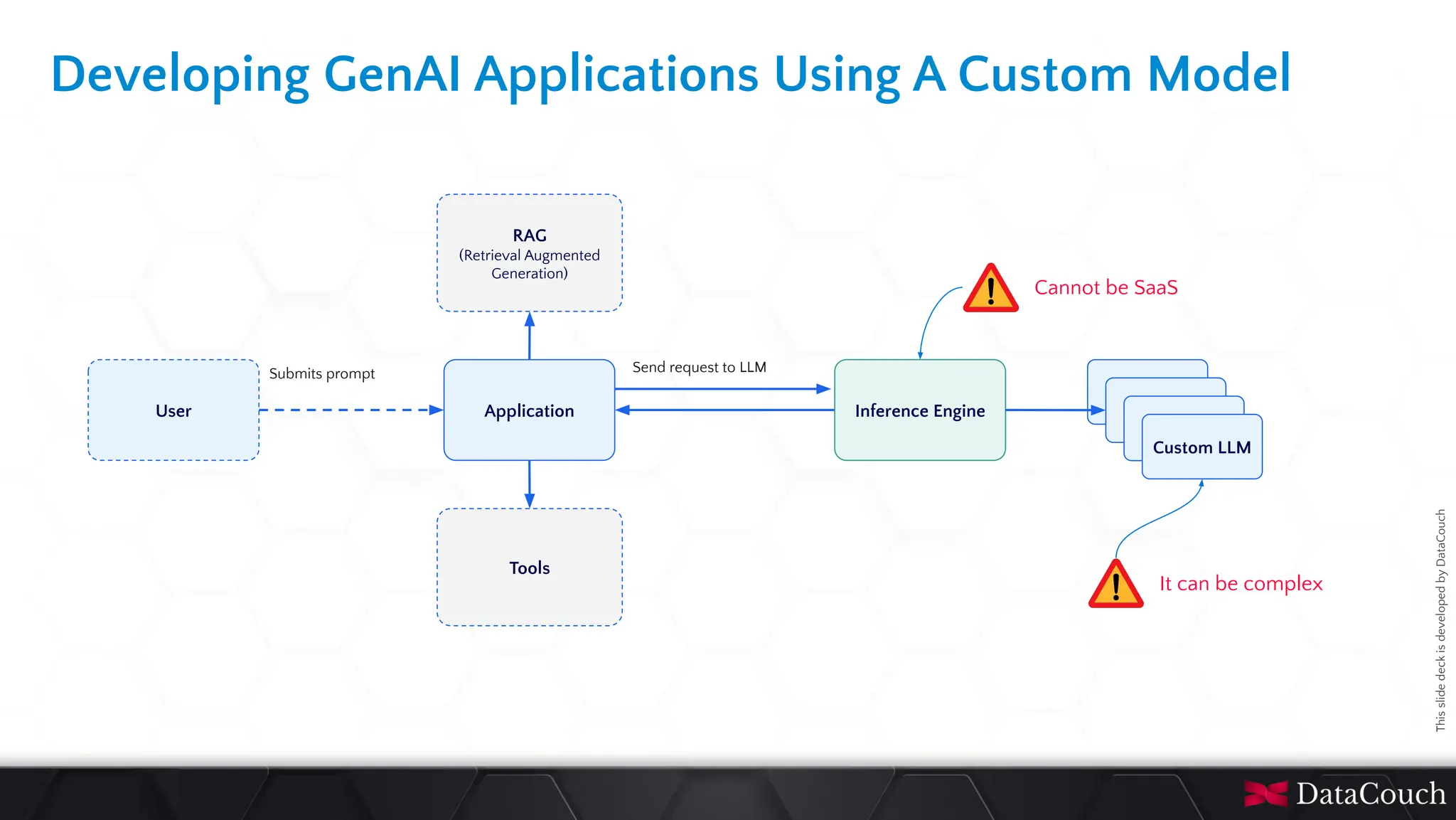
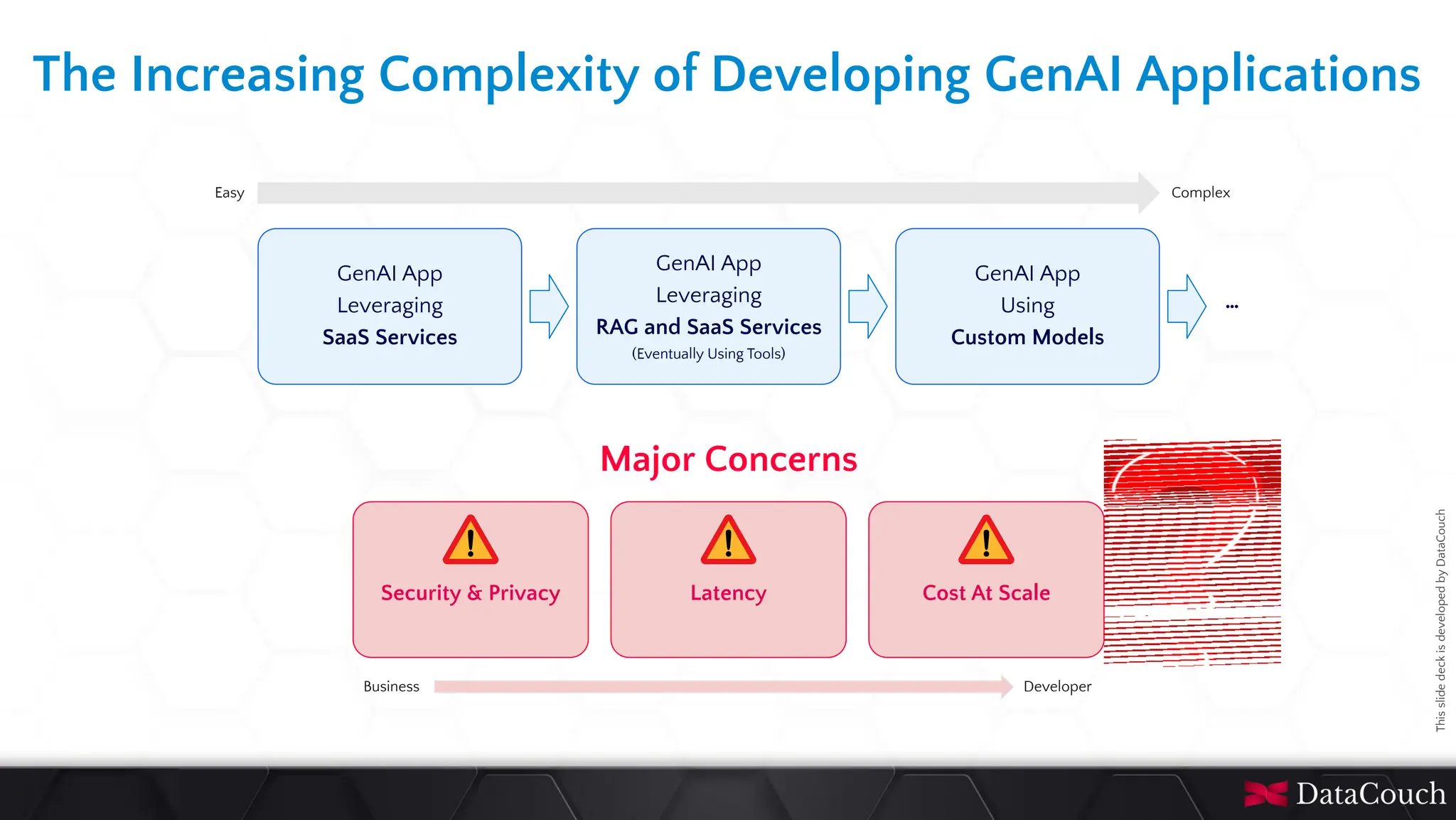
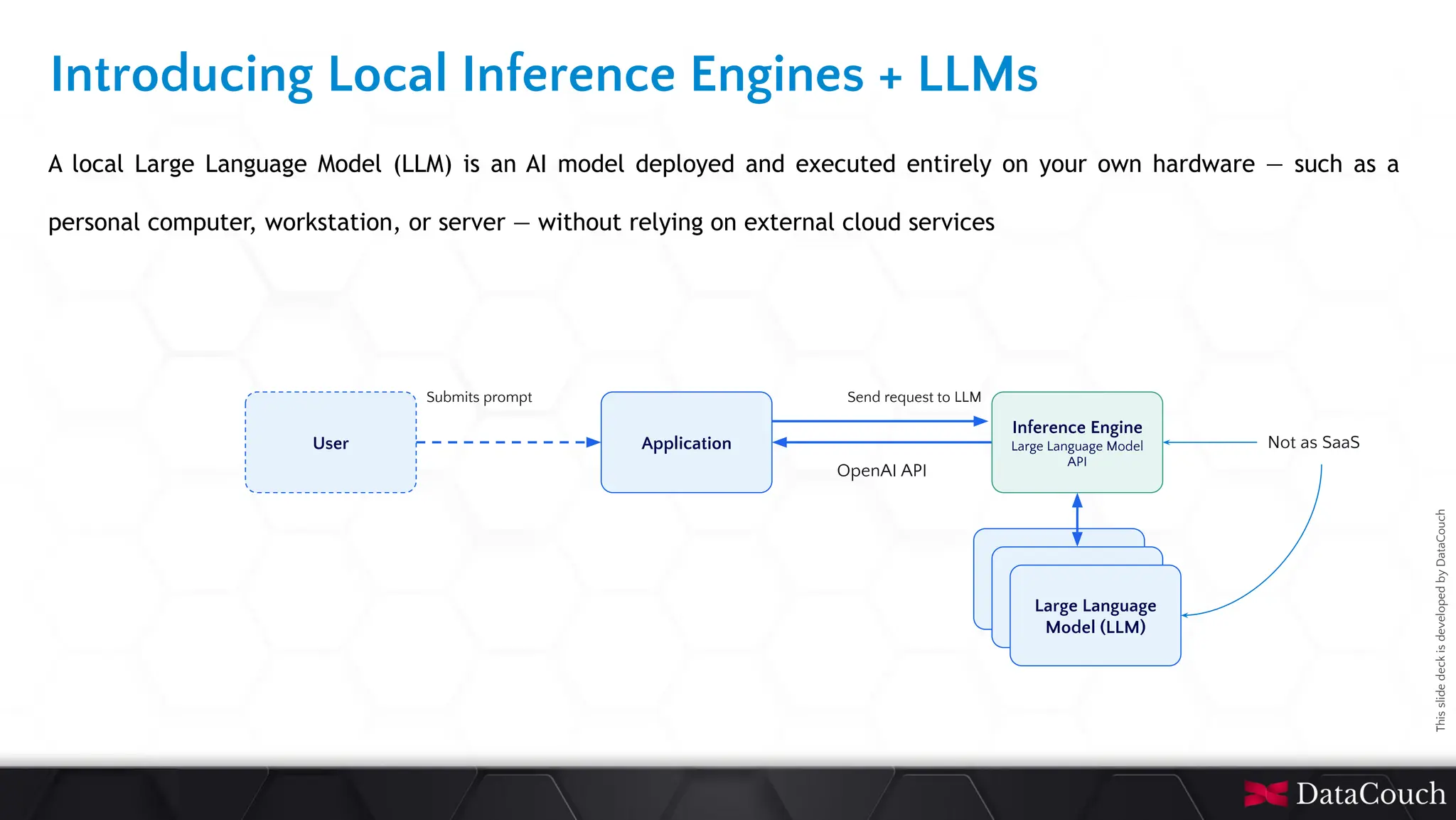

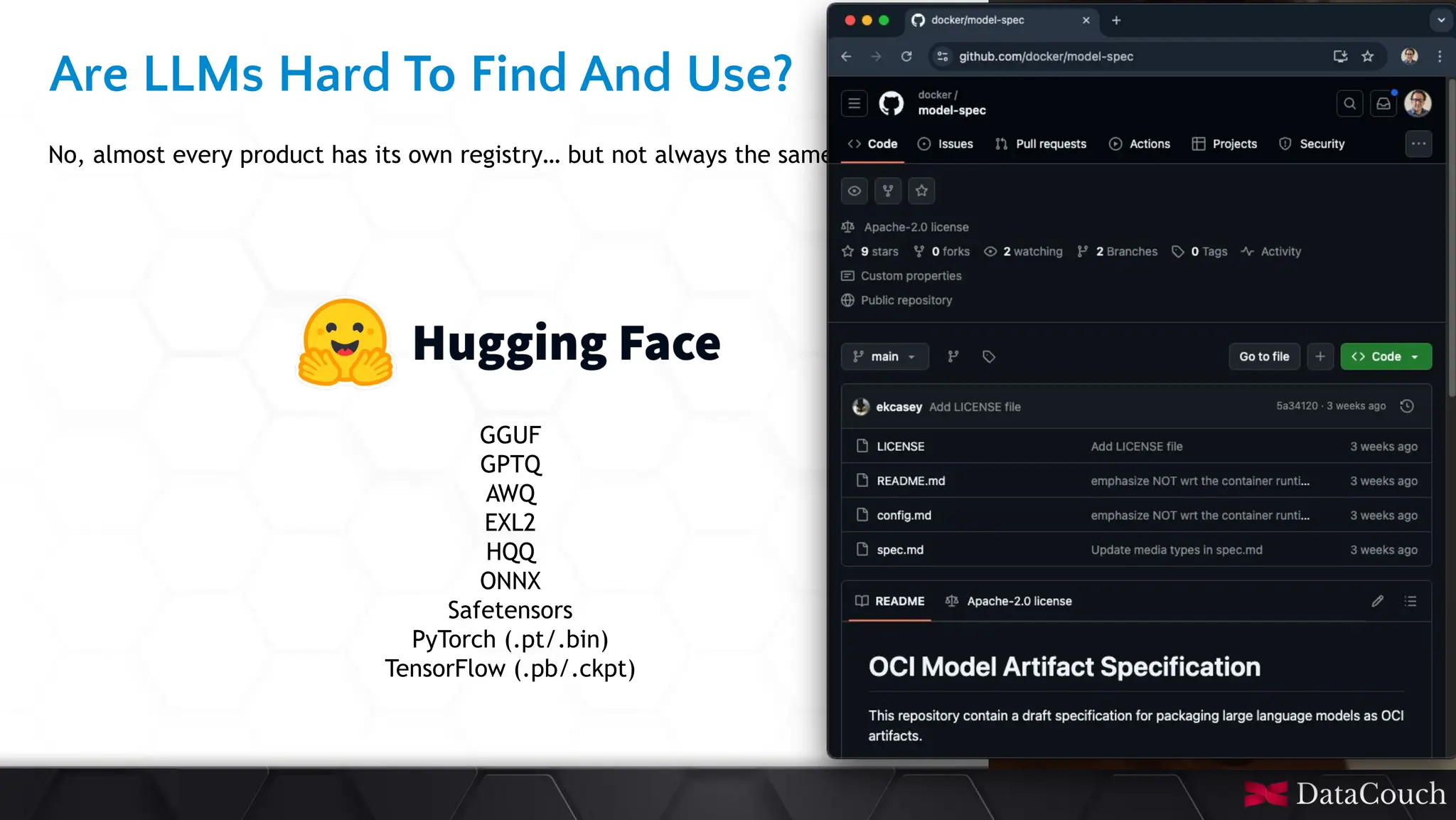




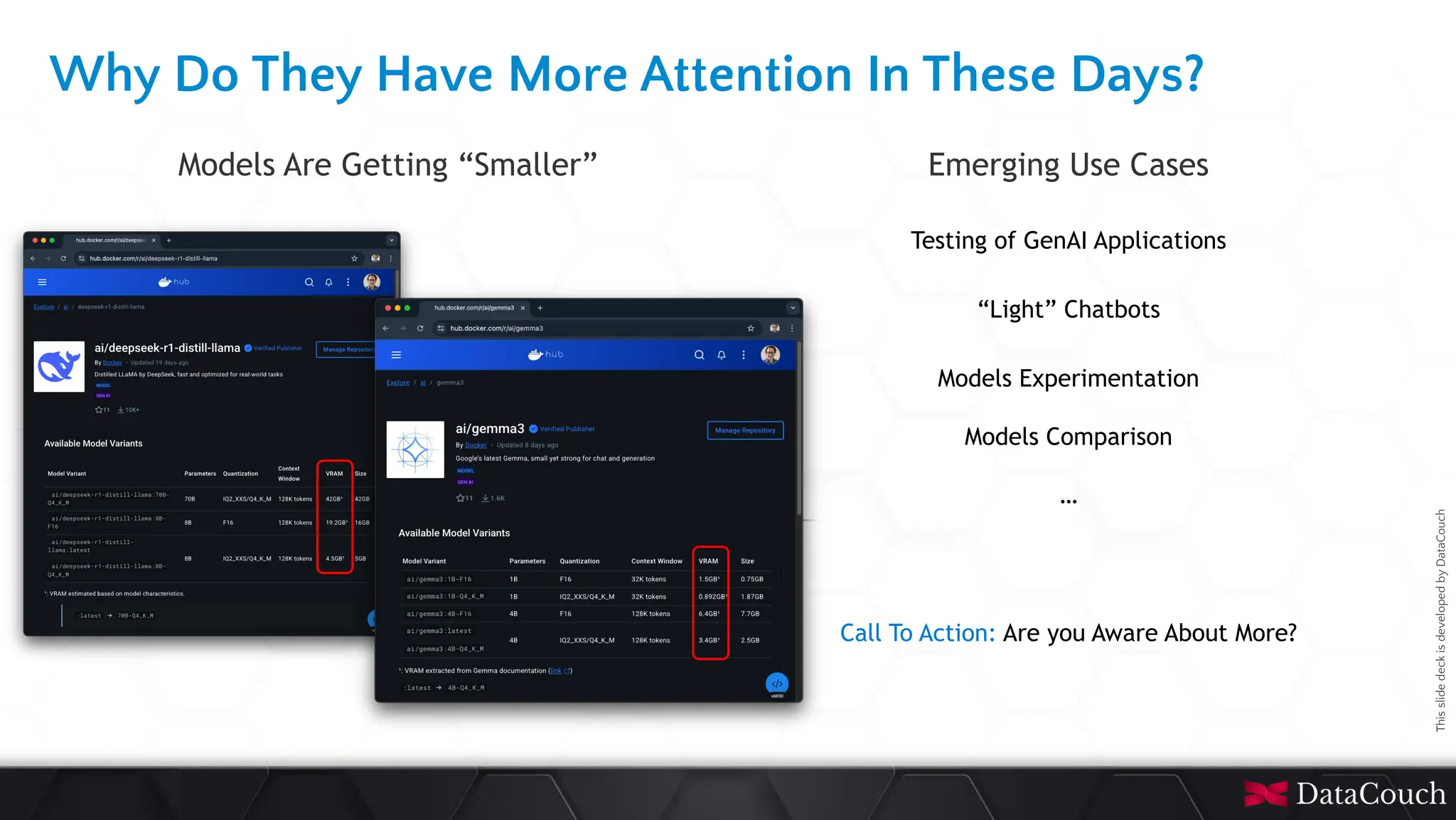



In today's AI development landscape, developers face significant challenges when building applications that leverage powerful large language models (LLMs) through SaaS platforms like ChatGPT, Gemini, and others. While these services offer impressive capabilities, they come with substantial costs that can quickly escalate especially during the development lifecycle. Additionally, the inherent latency of web-based APIs creates frustrating bottlenecks during the critical testing and iteration phases of development, slowing down innovation and frustrating developers. This talk will introduce the transformative approach of integrating local LLMs directly into their development environments. By bringing these models closer to where the code lives, developers can dramatically accelerate development lifecycles while maintaining complete control over model selection and configuration. This methodology effectively reduces costs to zero by eliminating dependency on pay-per-use SaaS services, while opening new possibilities for comprehensive integration testing, rapid prototyping, and specialized use cases.

















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















