Downloaded 118 times


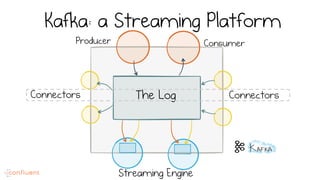
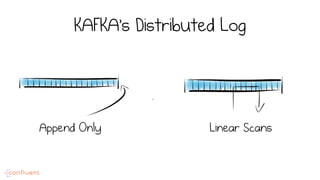



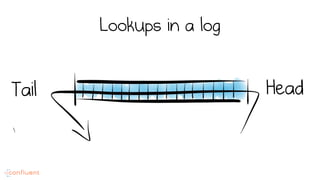
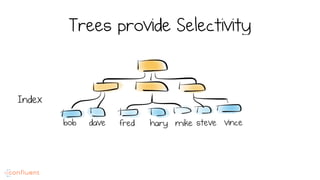
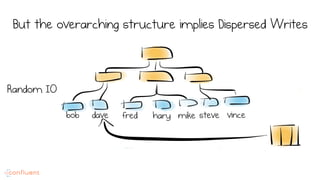



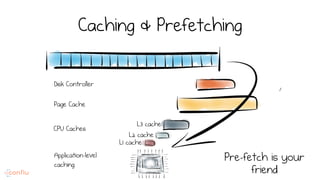
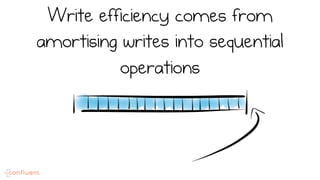


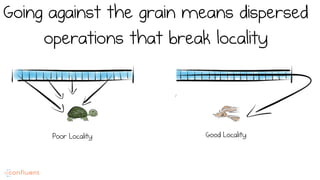
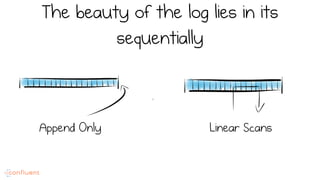

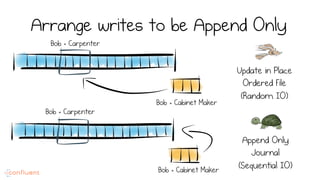
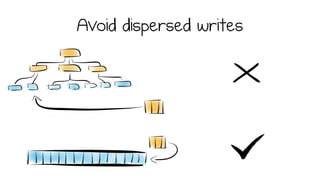


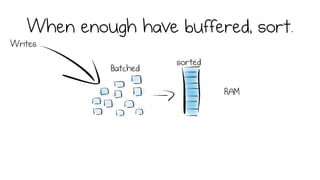
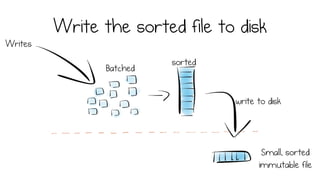
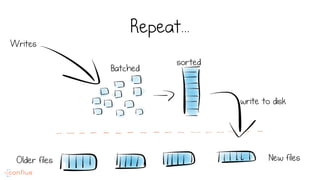
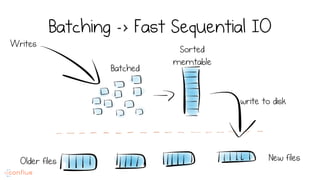


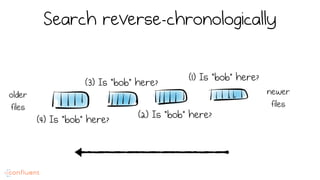




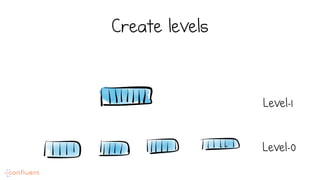
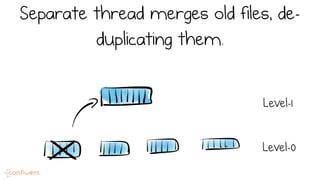


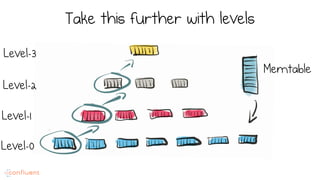
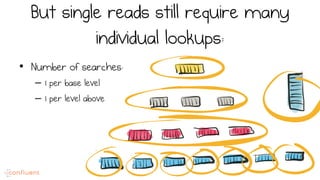


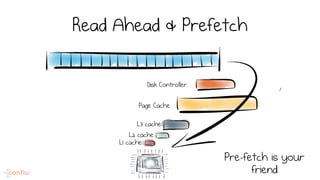


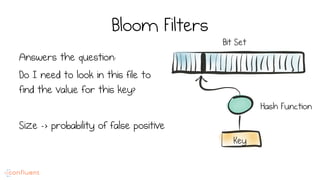

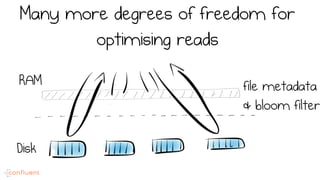


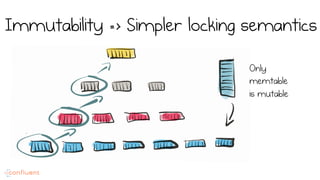

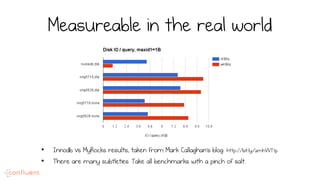



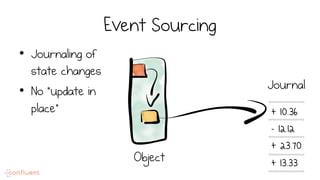
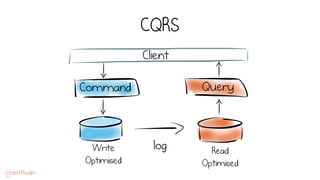

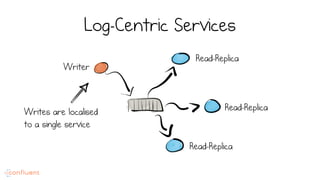
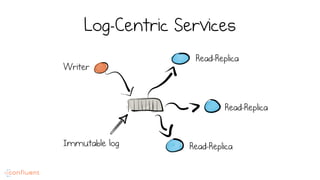
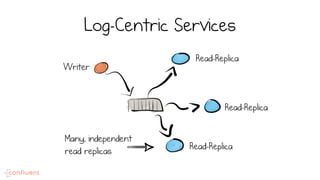







LSM trees provide an efficient way to structure databases by organizing data sequentially in logs. They optimize for write performance by batching writes together sequentially on disk. To optimize reads, data is organized into levels and bloom filters and caching are used to avoid searching every file. This log-structured approach works well for many systems by aligning with how hardware is optimized for sequential access. The immutability of appended data also simplifies concurrency. This log-centric approach can be applied beyond databases to distributed systems as well.


















































![[db tech showcase Tokyo 2017] C23: Lessons from SQLite4 by SQLite.org - Richa...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-sqlite4-20170906-170911071410-thumbnail.jpg?width=640&height=640&fit=bounds)
























































