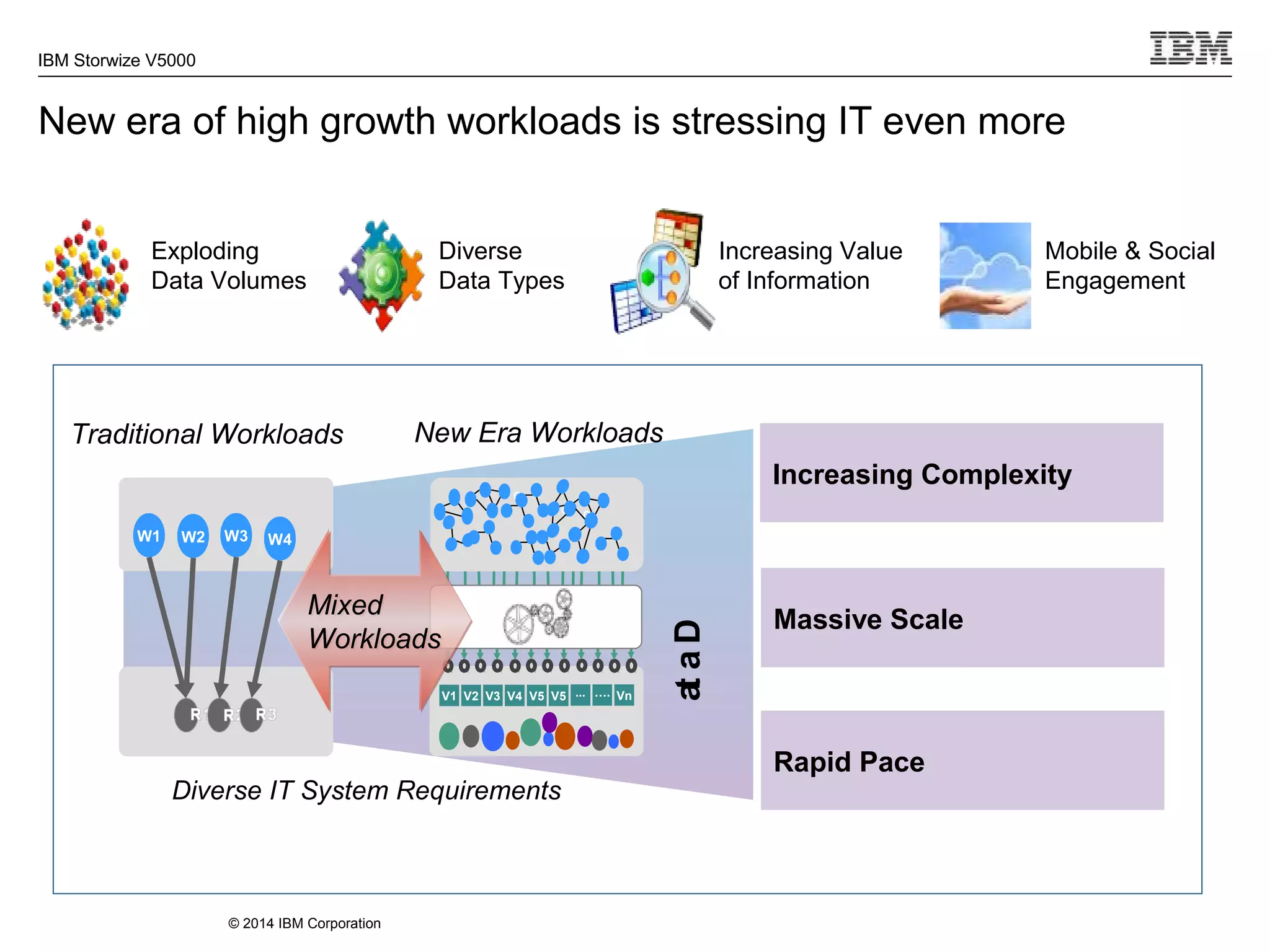
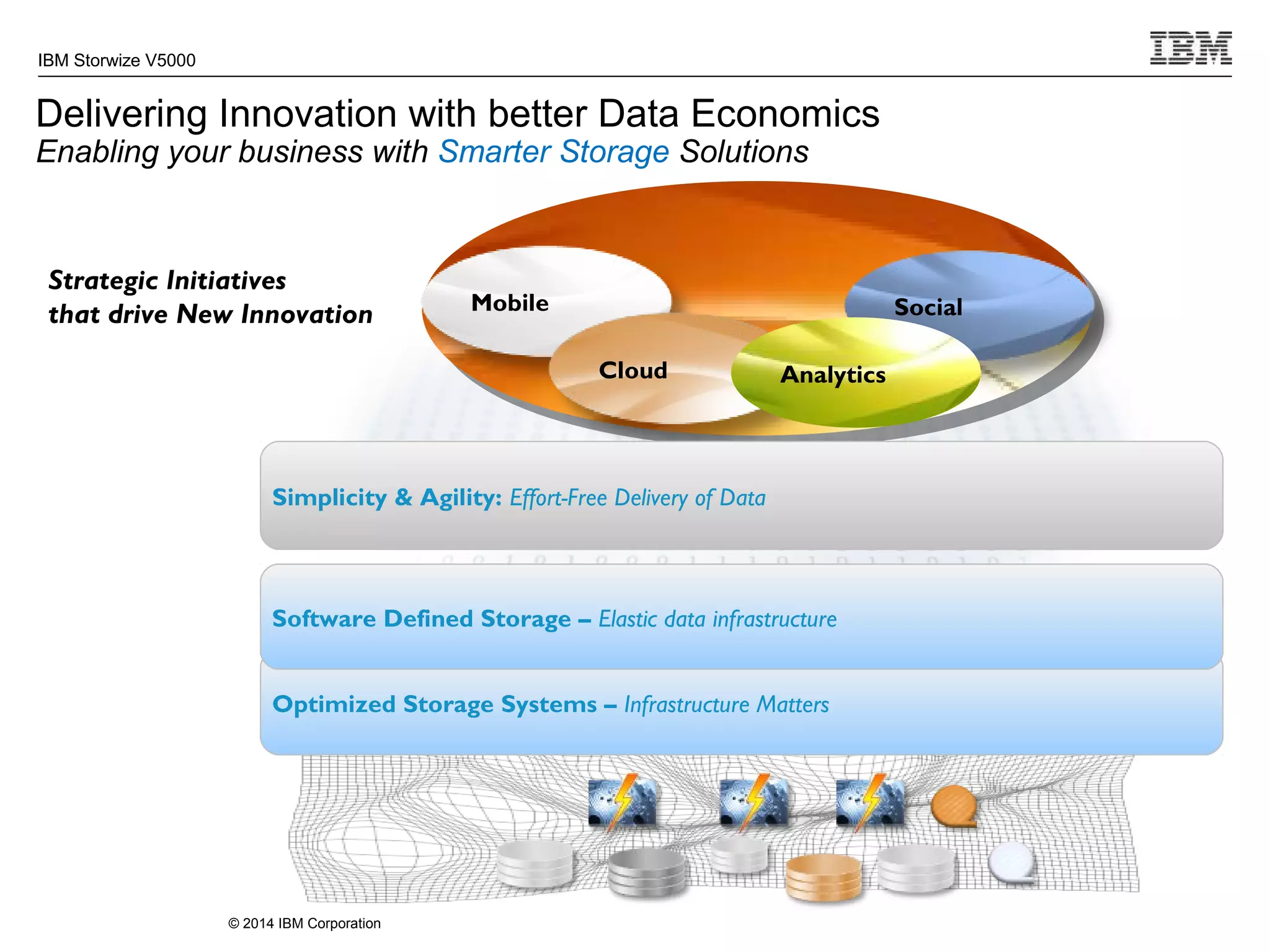
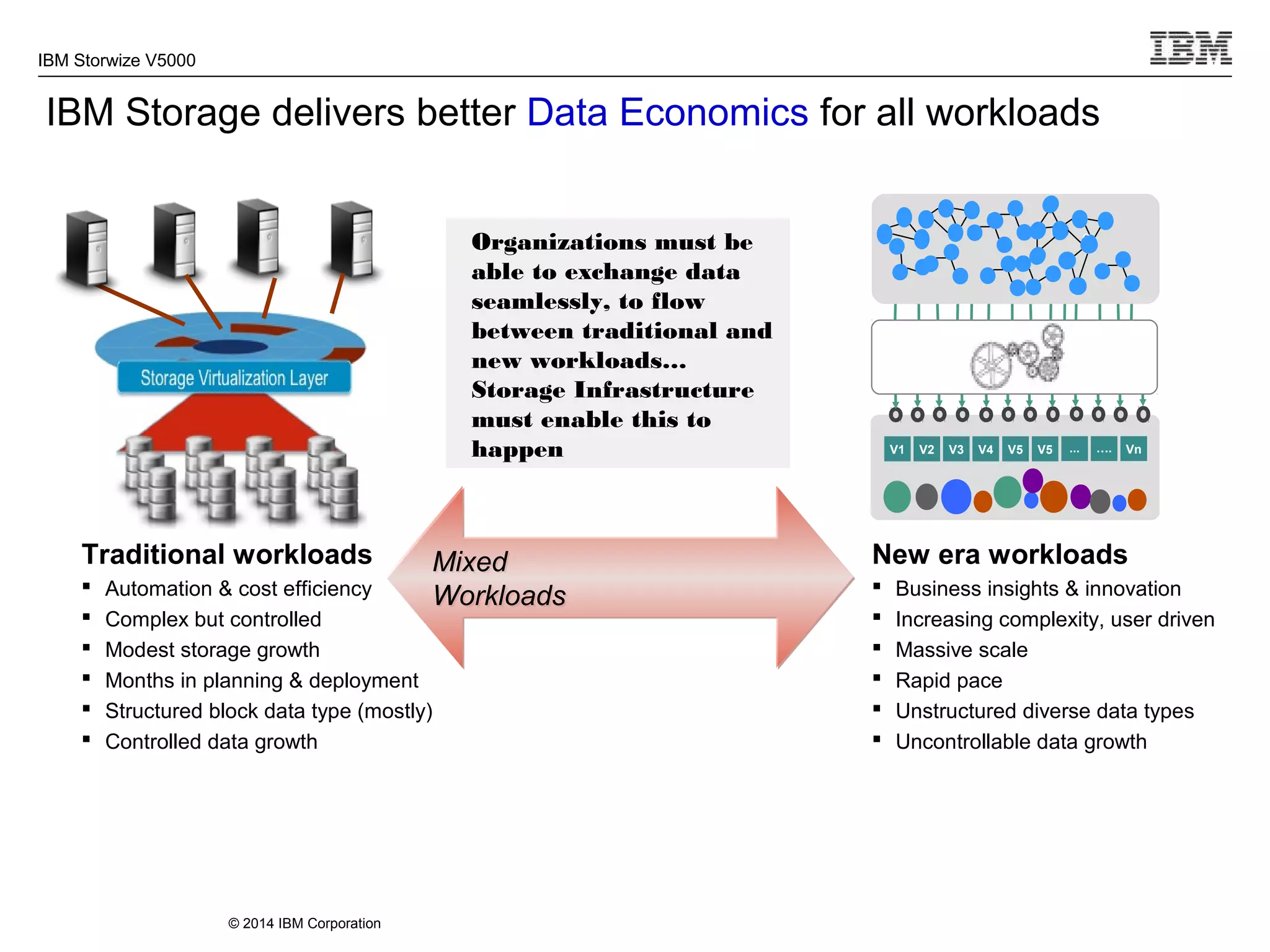
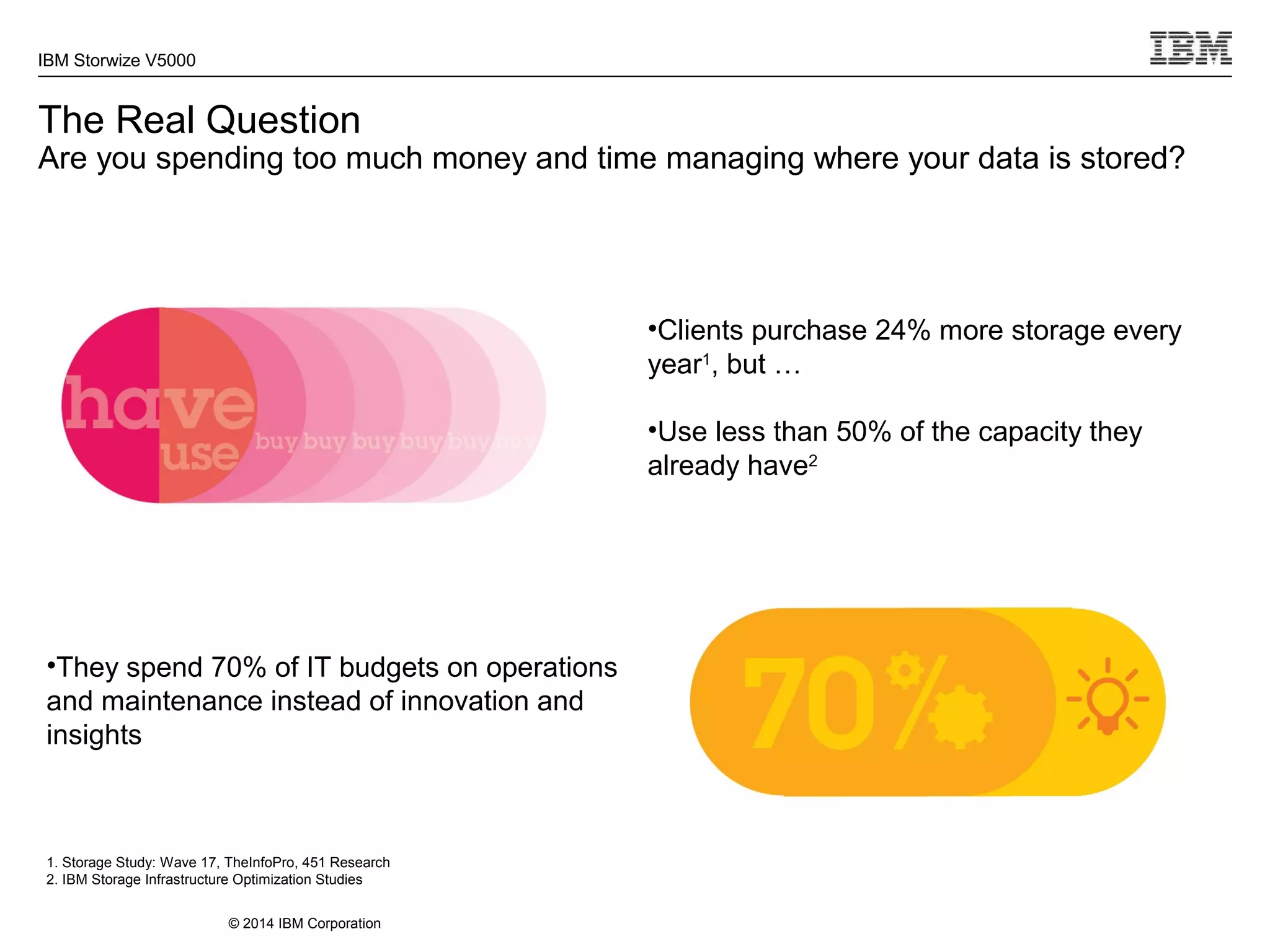
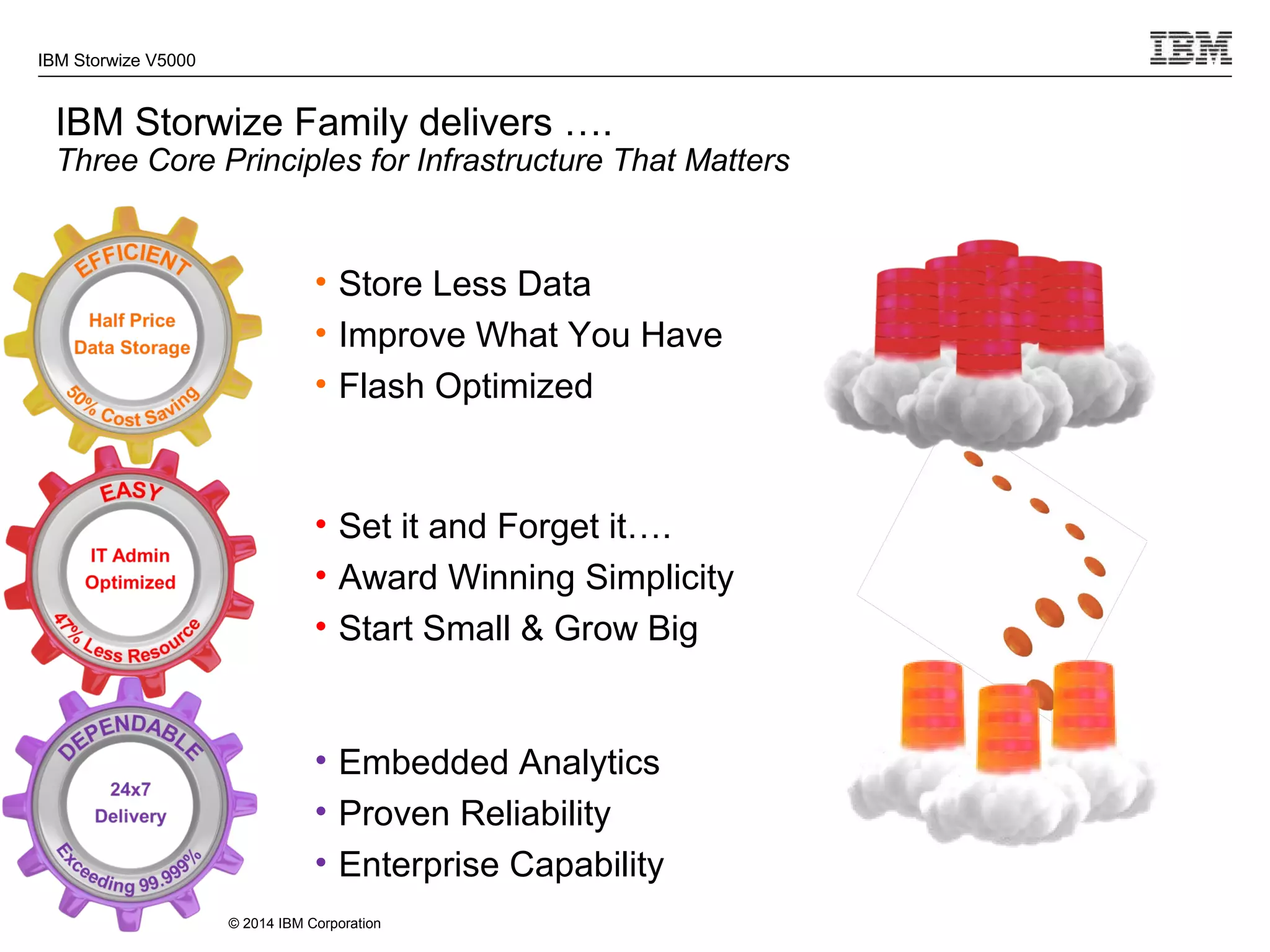
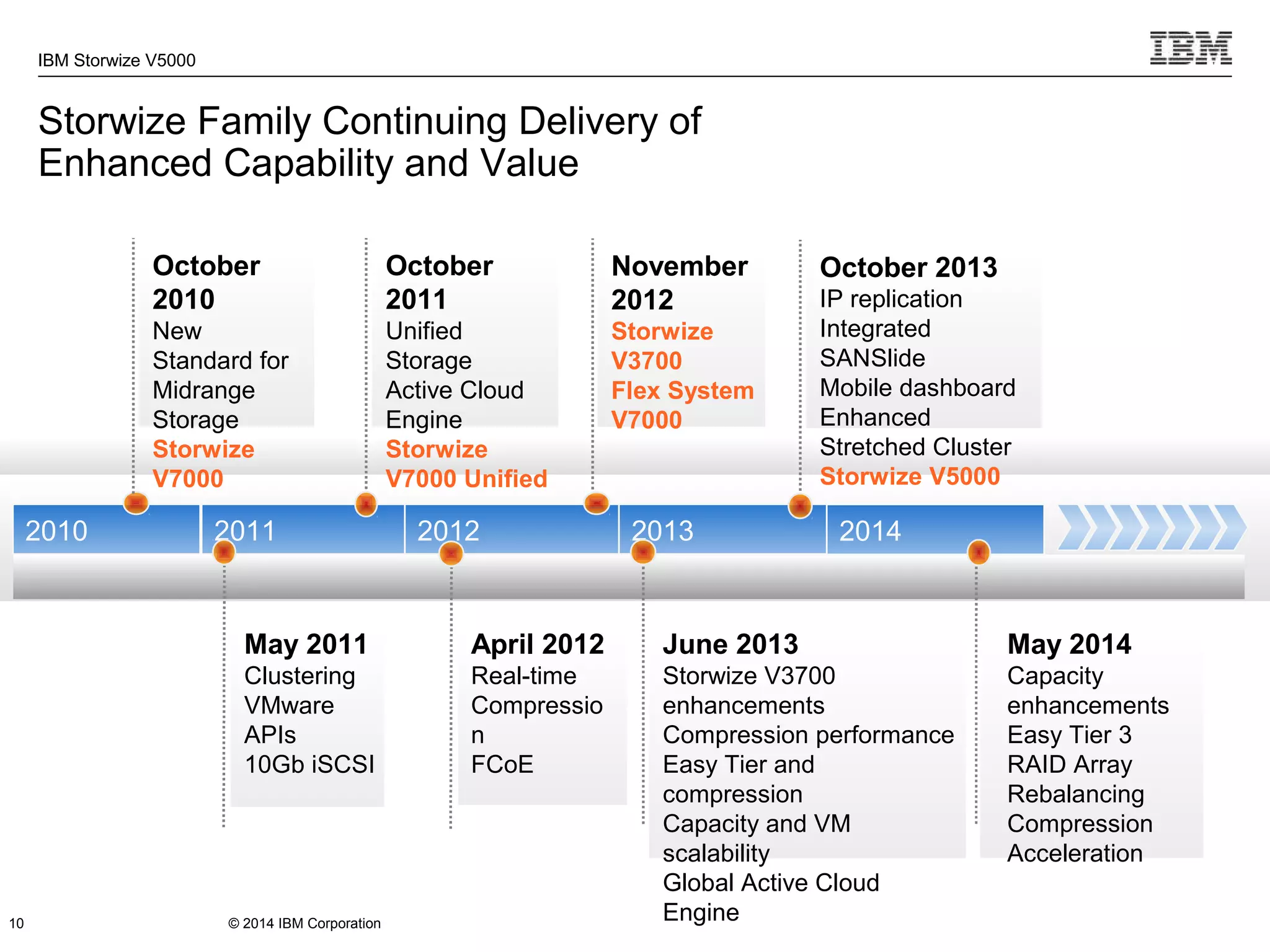
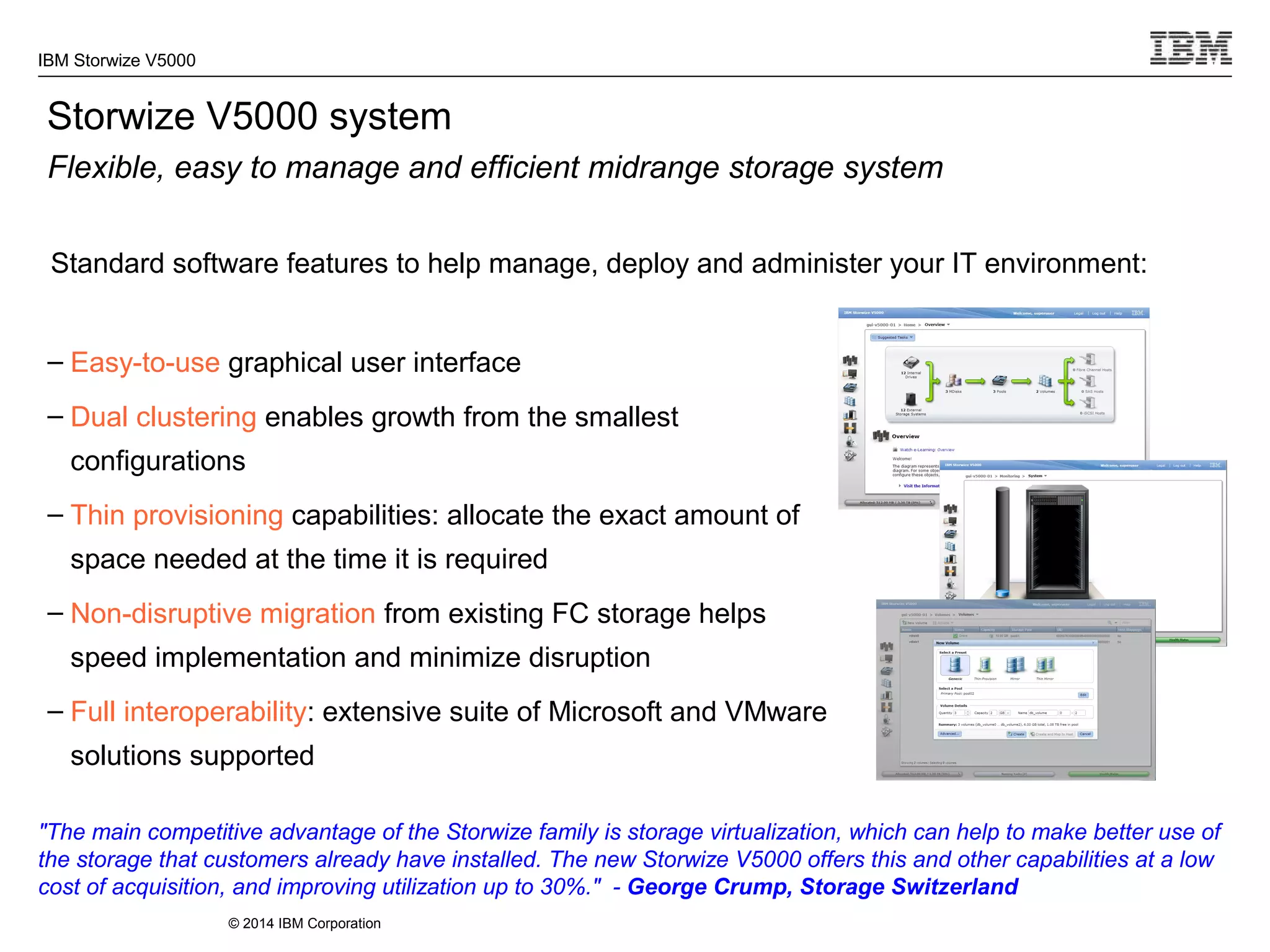
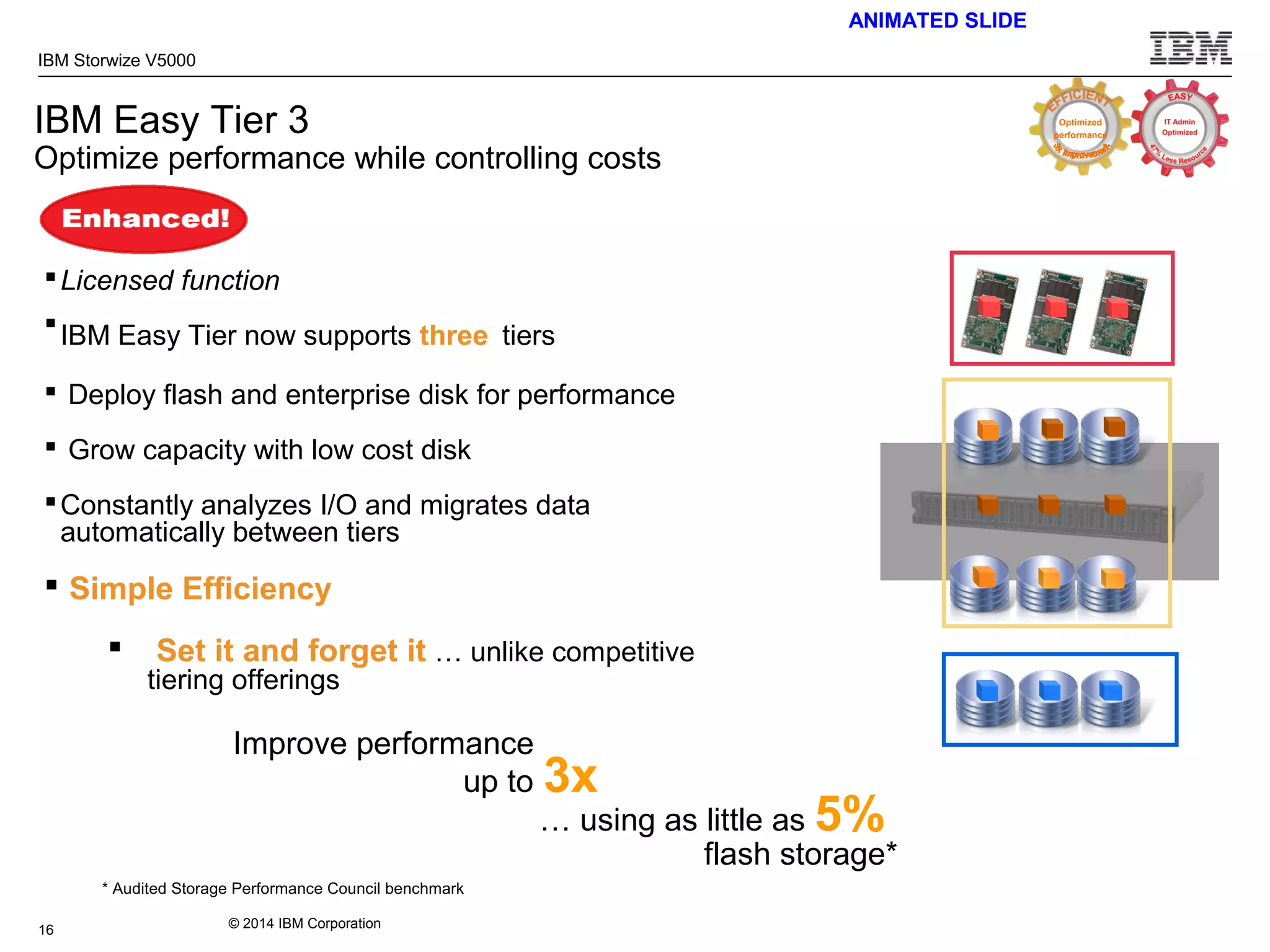
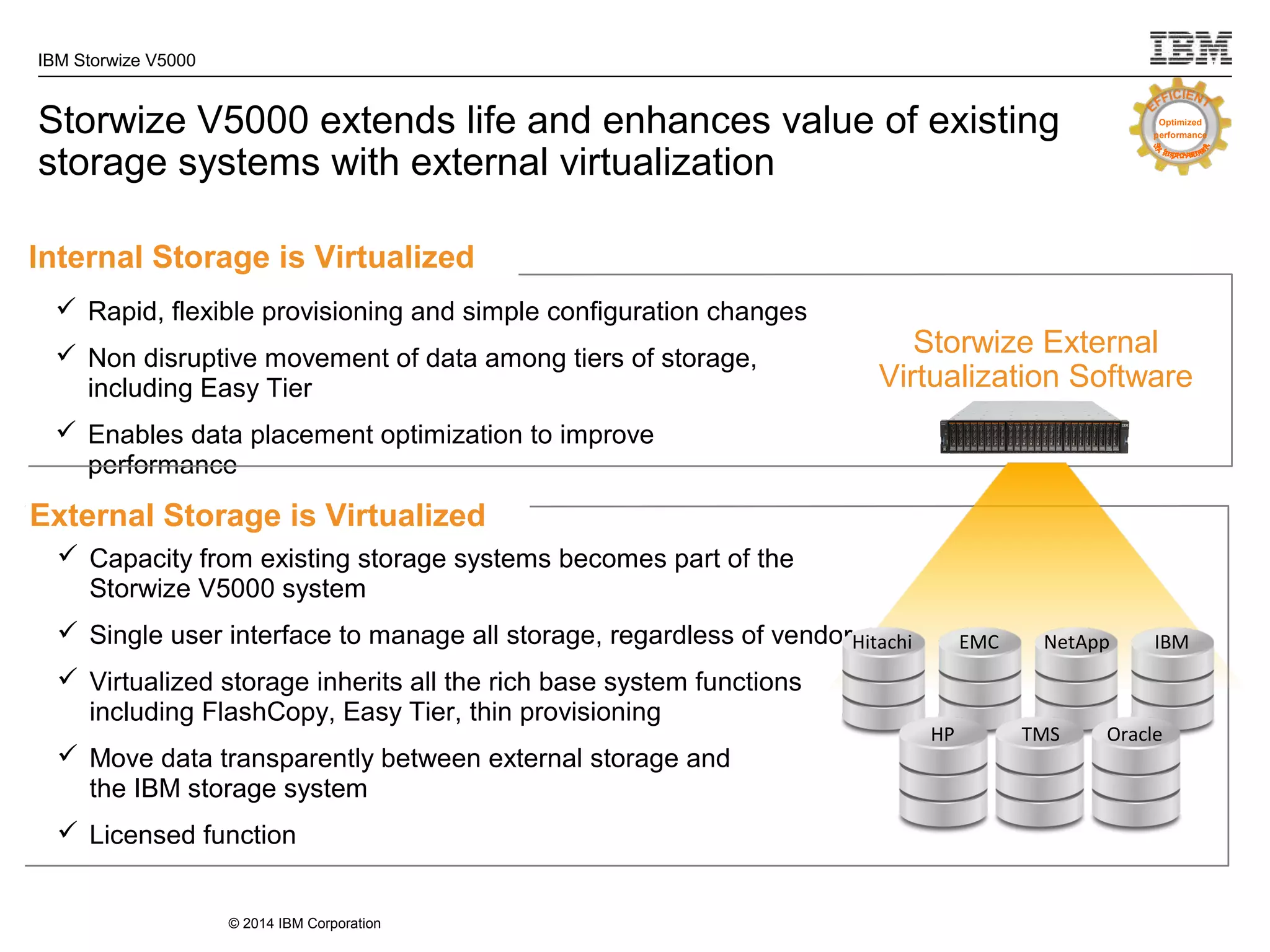
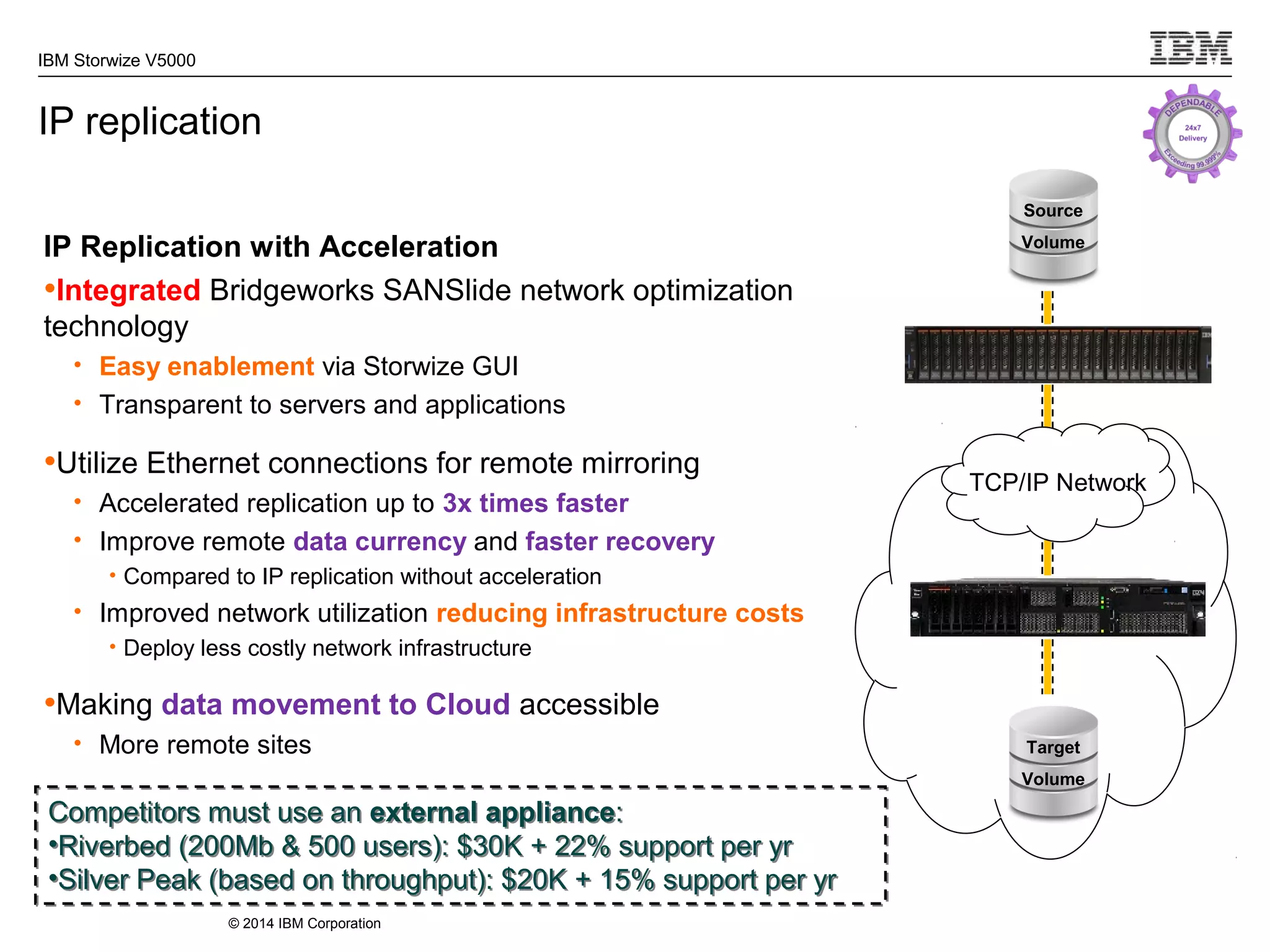
The document provides information about the IBM Storwize V5000 storage system. It highlights key benefits such as simplified management, flexible customization options, and boosted performance through optional Easy Tier technology. The Storwize V5000 offers flexible scaling from small to large configurations and standard software features to help manage storage environments.







![© 2014 IBM Corporation
IBM Storwize V5000
“ ”
“… managing an IBM Storwize [family] system with its
management interface is 47 percent less time-consuming
and 31 percent less complex than managing an EMC VNX
system using the Unisphere software interface.”
Source: Edison Group, Competitive Management Cost Study:
IBM Storwize V7000 vs. EMC VNX5500 Storage Systems
Industry-leading user interface
Graphical User Interface
Adopted from the easy-to-use Storwize family and XIV GUI
Common GUI across IBM Storage reduces training costs
Enhance IT productivity with point-and-click system
management capabilities
YouTube:YouTube:
IBM Storwize family Ease of Use GUI
YouTube:YouTube:
IBM Storwize family Ease of Use GUI](https://image.slidesharecdn.com/s1ppoacys5smefoxpxna-signature-924a00b5c474e906b46a6bc926f7b1dd1c97286288d95d3a810feab38cb41d78-poli-150514113257-lva1-app6892/75/Storwize-v5000-15-2048.jpg)










































![Resume2011[1]](https://cdn.slidesharecdn.com/ss_thumbnails/resume20111-13262888897551-phpapp01-120111073606-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












