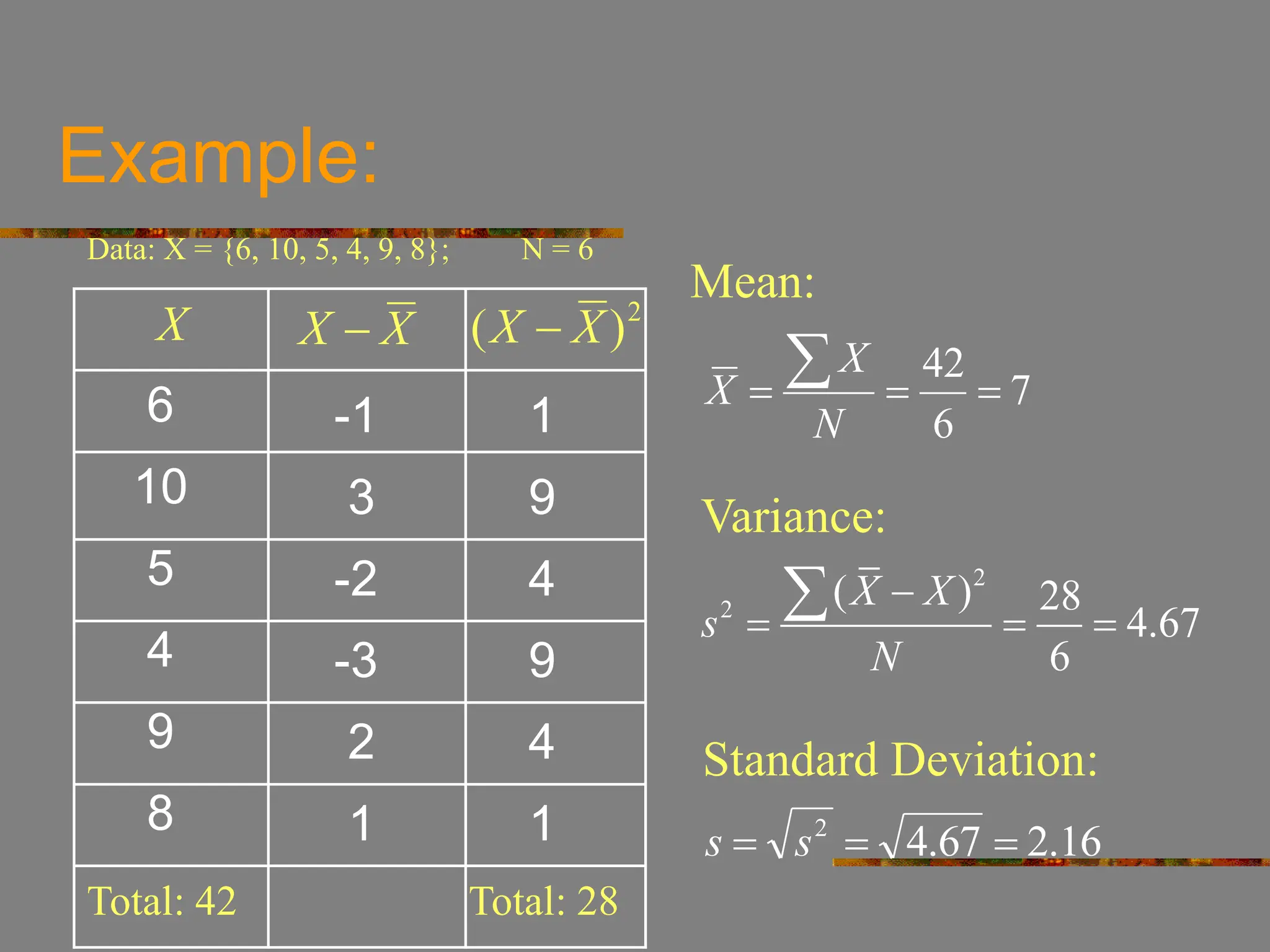
- The document discusses key concepts in descriptive statistics including types of distributions, measures of central tendency, and measures of dispersion.
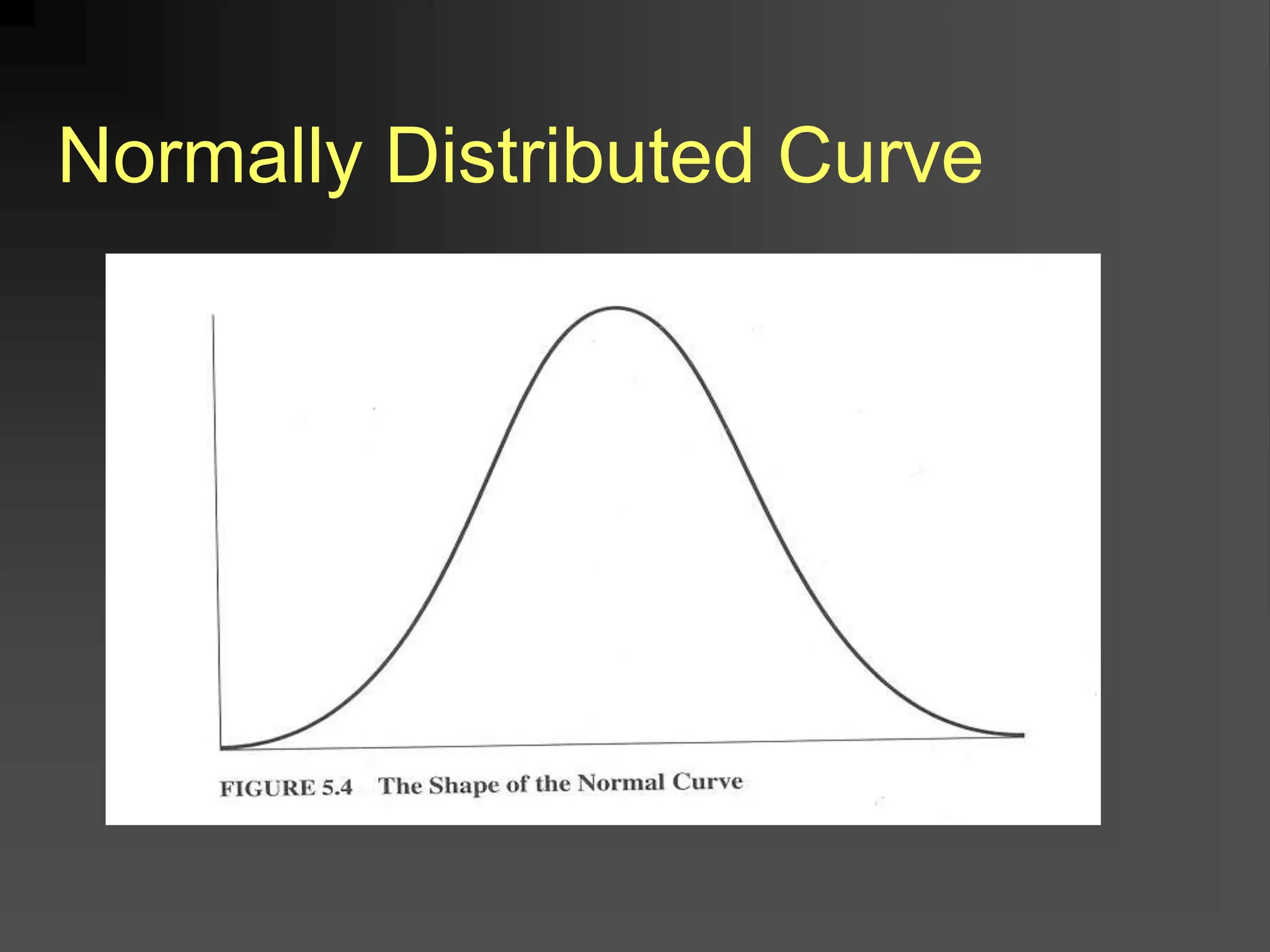
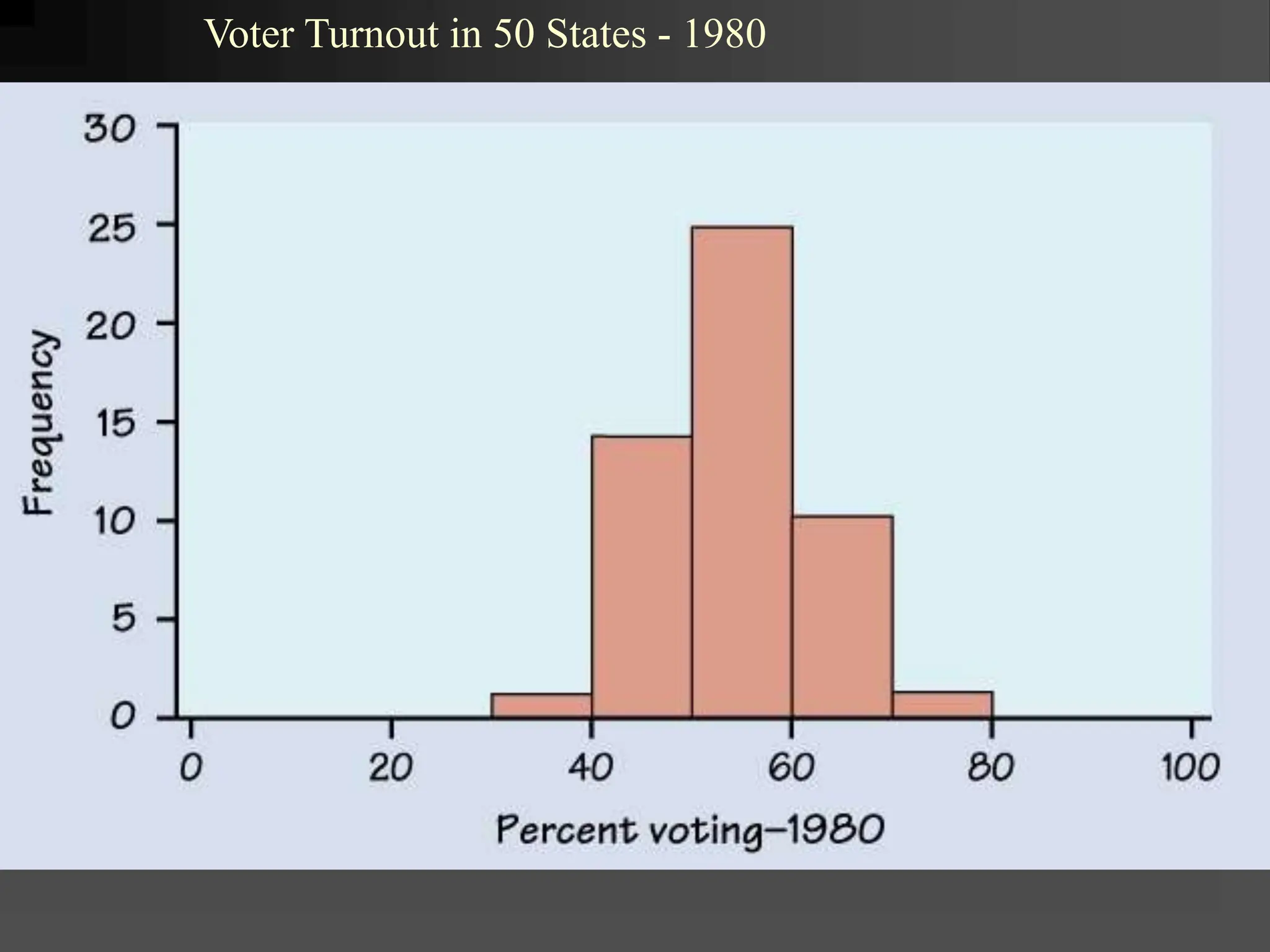
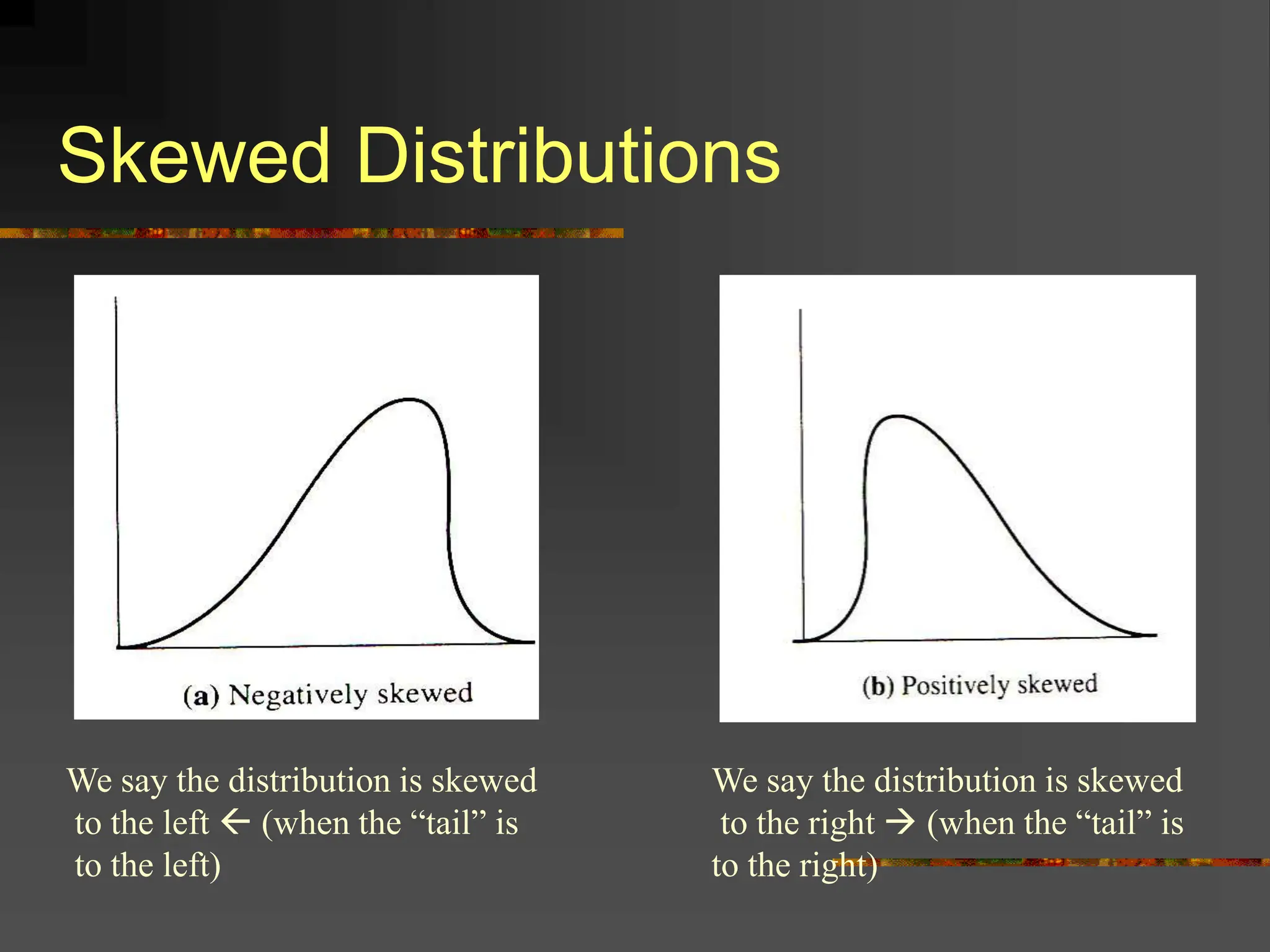
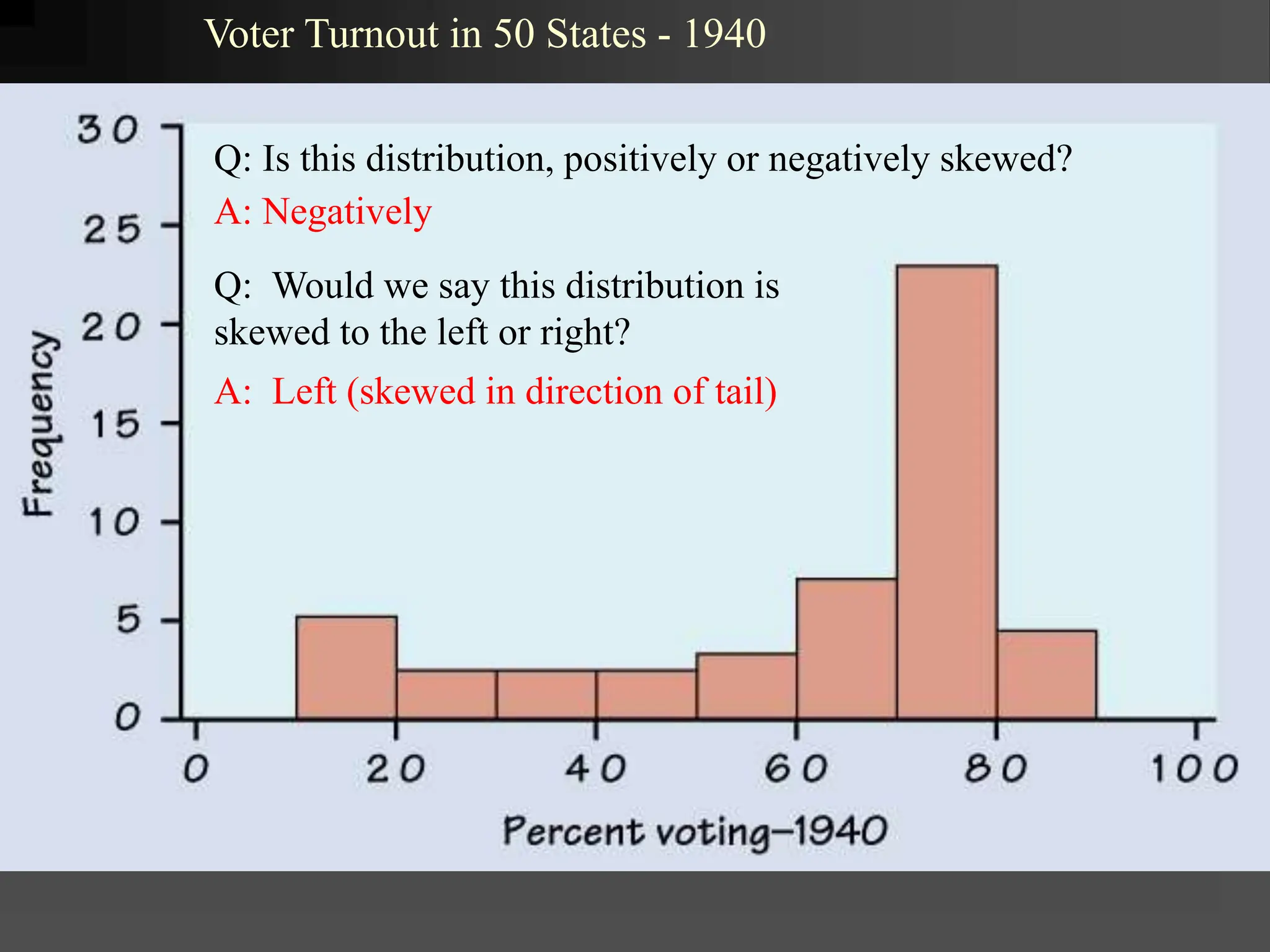
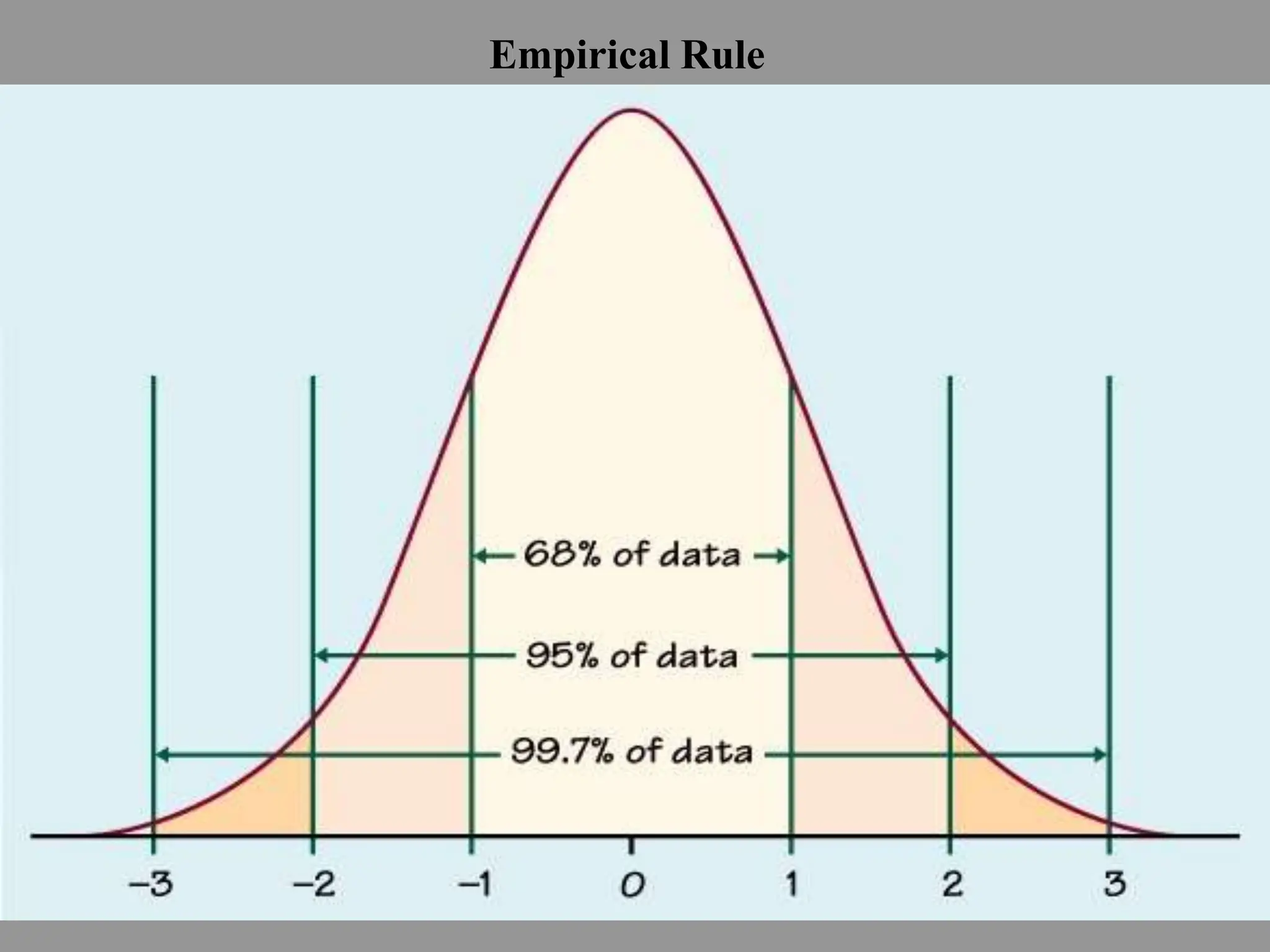
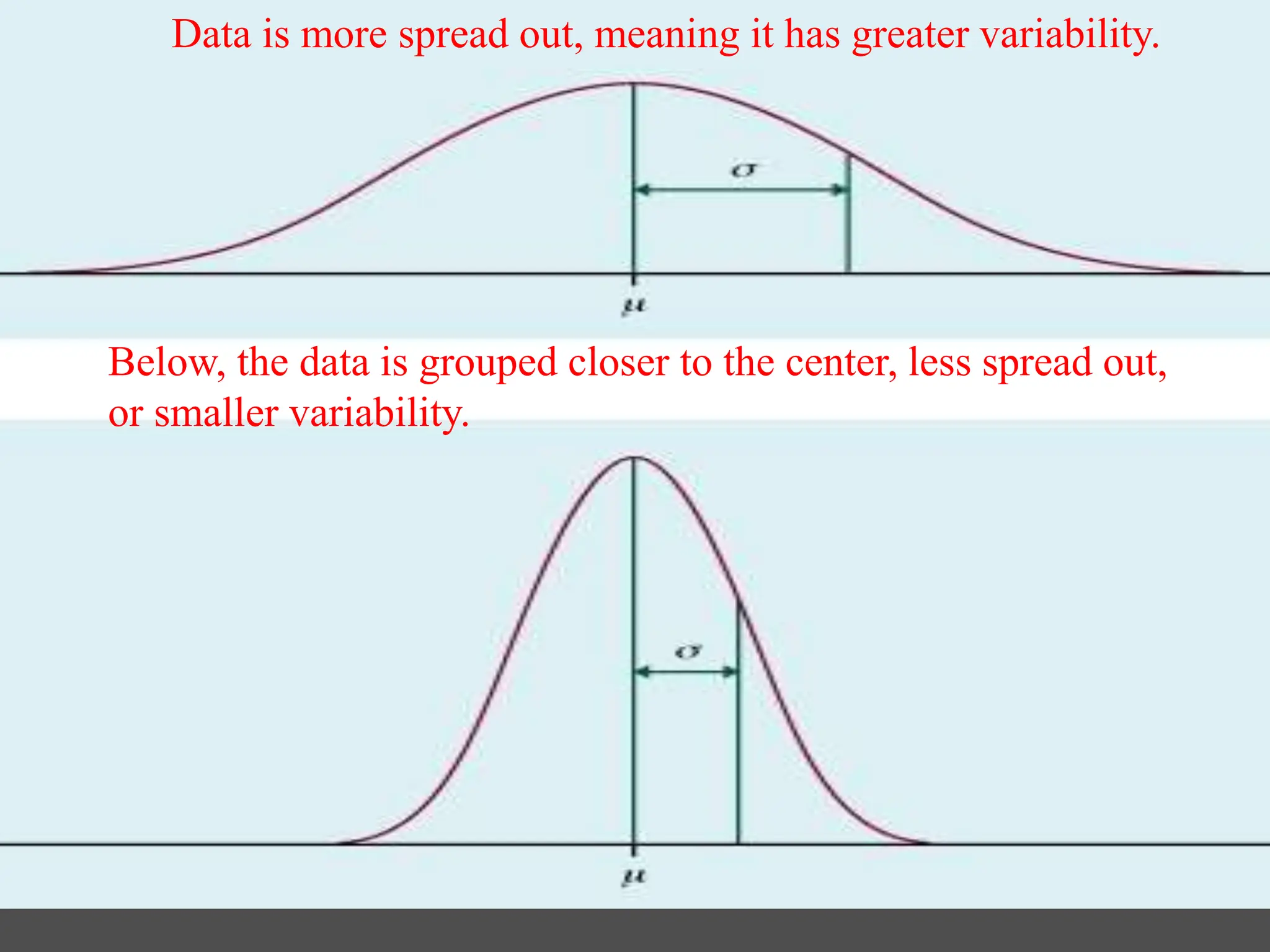
- It covers normal, skewed, and other types of distributions. Measures of central tendency discussed are mean, median, and mode. Measures of dispersion covered are variance and standard deviation.
- The document uses examples and explanations to illustrate how to calculate and interpret these important statistical measures.

![DESCRIPTIVE STATISTICS
are concerned with describing the
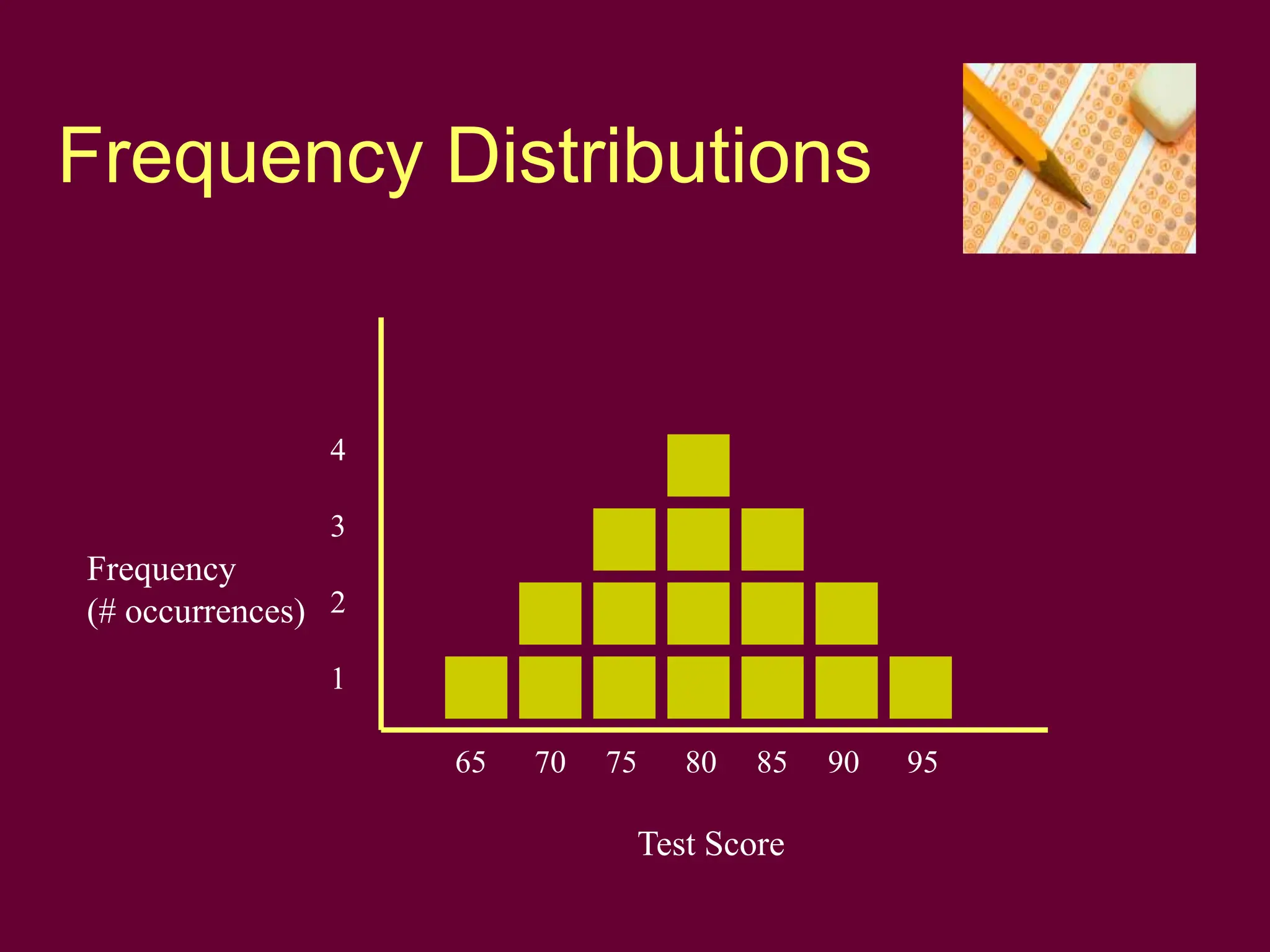
characteristics of frequency distributions
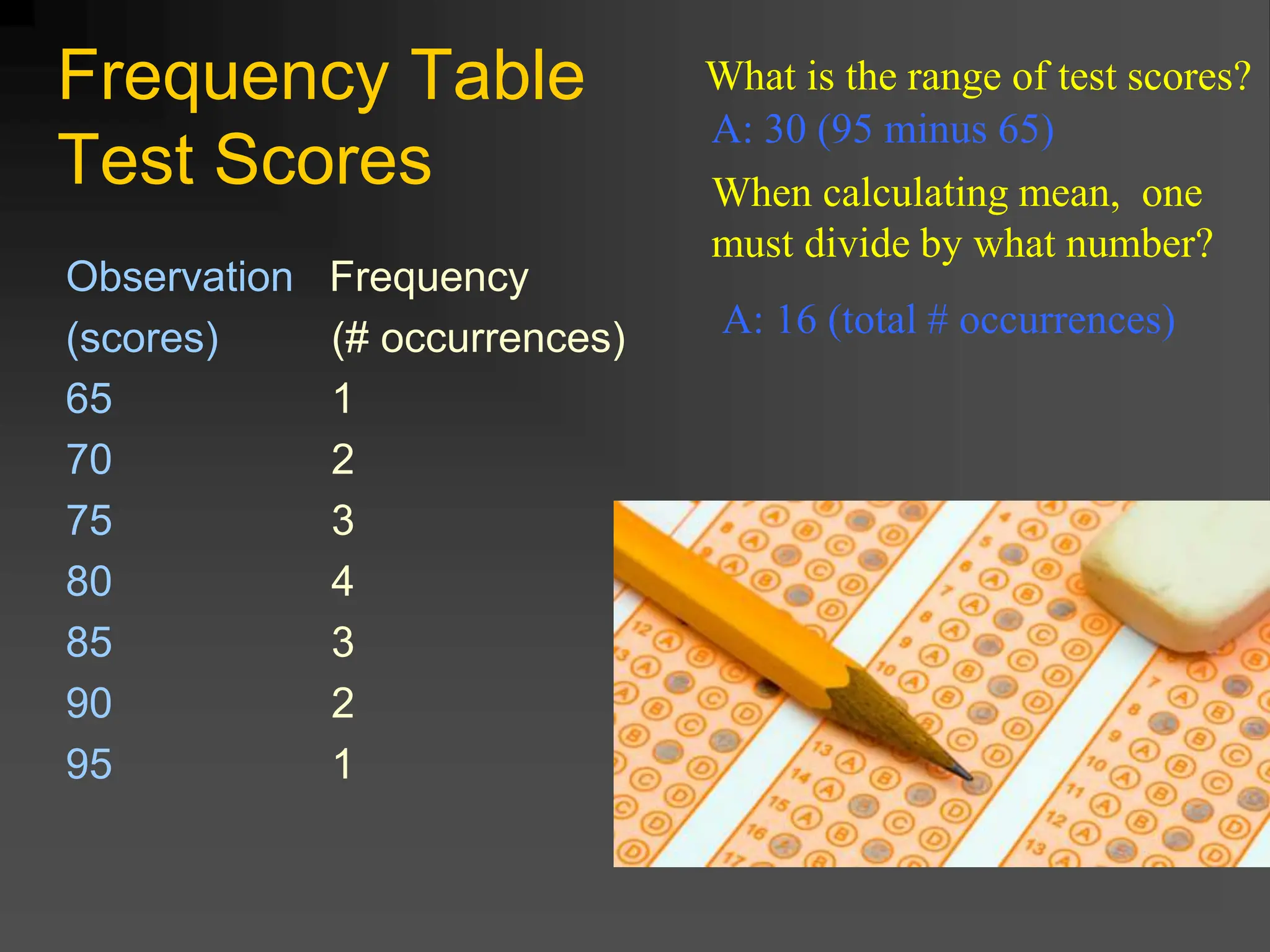
Where is the center?
What is the range?
What is the shape [of the
distribution]?](https://image.slidesharecdn.com/statical-data-1-240314025940-ca8e8391/75/statical-data-1-to-know-how-to-measure-ppt-2-2048.jpg)