This document provides an overview of using Stata software to perform time series analysis. It describes opening a dataset containing economic variables over time, declaring the data as a time series, using commands like lag and lead to generate past and future values, exploring autocorrelation and cross-correlation between variables, and testing for a unit root in the data. Learning outcomes include autocorrelation analysis, cross-correlation analysis, unit root testing, and using basic time series commands in Stata.







![pac unemp, lags(10)
xcorr gdp unemp
-1.00-0.50
0.000.501.00
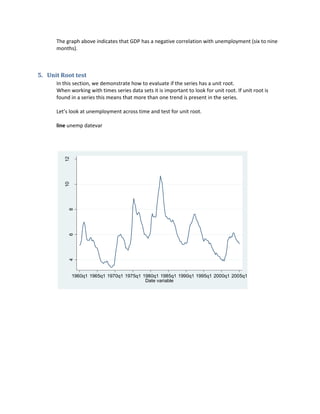
0 2 4 6 8 10
Lag
95% Confidence bands [se = 1/sqrt(n)]
-1.00-0.500.000.501.00
-1.00-0.50
0.000.501.00
-20 -10 0 10 20
Lag
Cross-correlogram](https://image.slidesharecdn.com/stata-time-series-fall-2011-160312093508/85/Stata-time-series-fall-2011-8-320.jpg)






![ARIMA Models - [Lab 3]](https://cdn.slidesharecdn.com/ss_thumbnails/ydqcxn5vtqizjoun2as1-signature-e1de5ad681d661531c2467ca0d3e475440809ccfdbcb78c5369a1bb749945888-poli-141230090527-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)















































