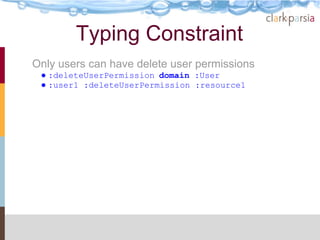
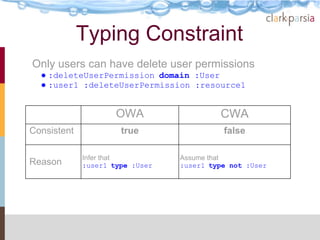
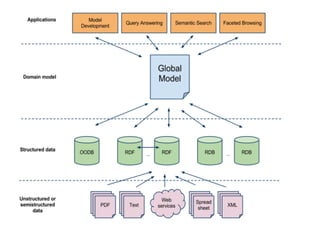
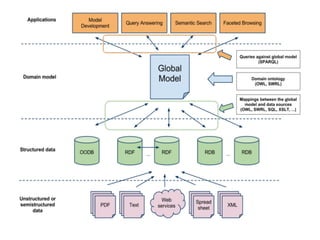
The document describes the Stardog Linked Data Catalog (SLDC), a metadata management tool developed by Clark & Parsia, which integrates various types of data sources using semantic technologies. It emphasizes features such as security through role-based permissions, data validation, and querying capabilities across diverse data repositories. The SLDC aims to enhance data discoverability and manageability in large organizations with disparate data systems.