Download to read offline









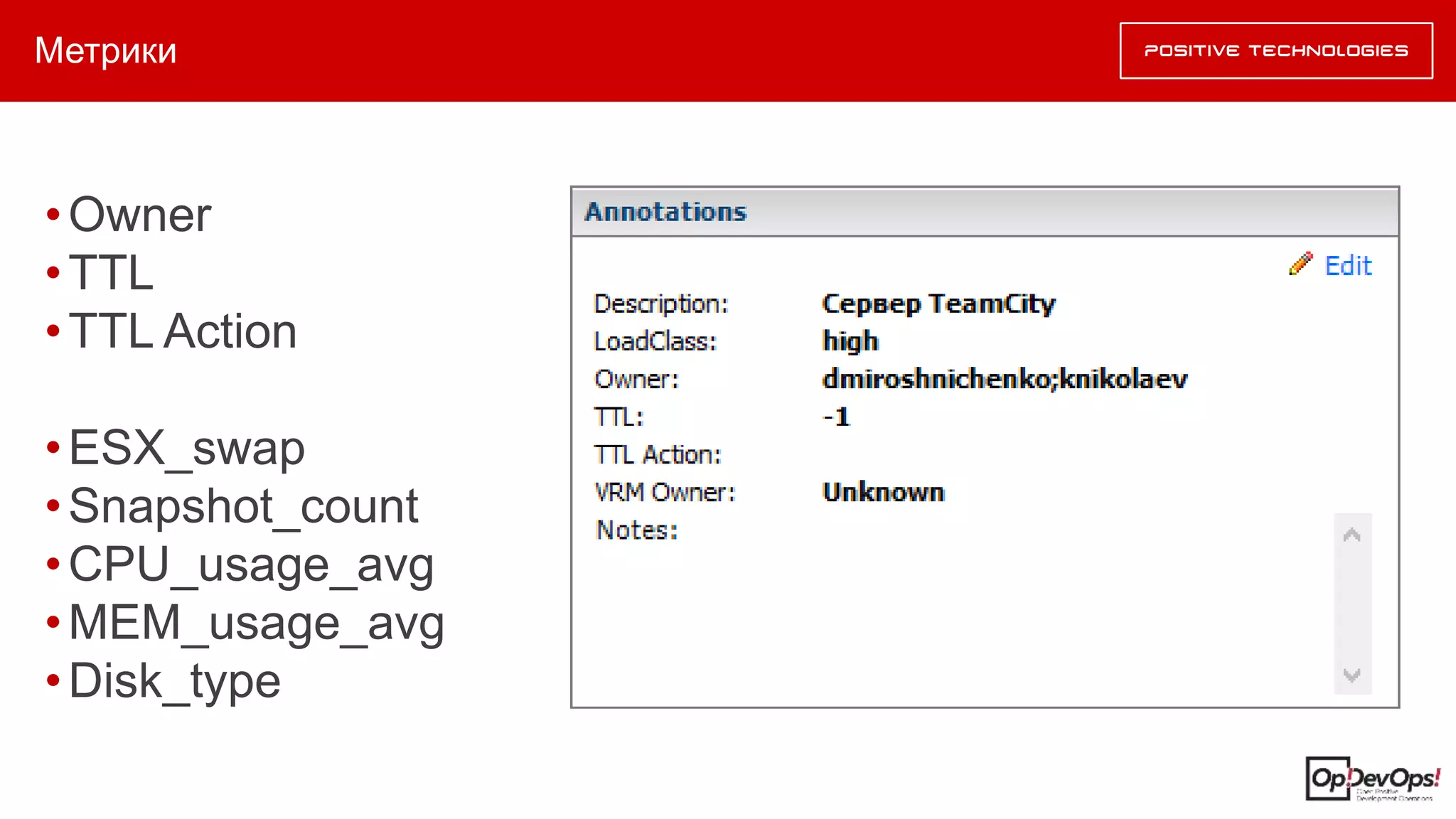




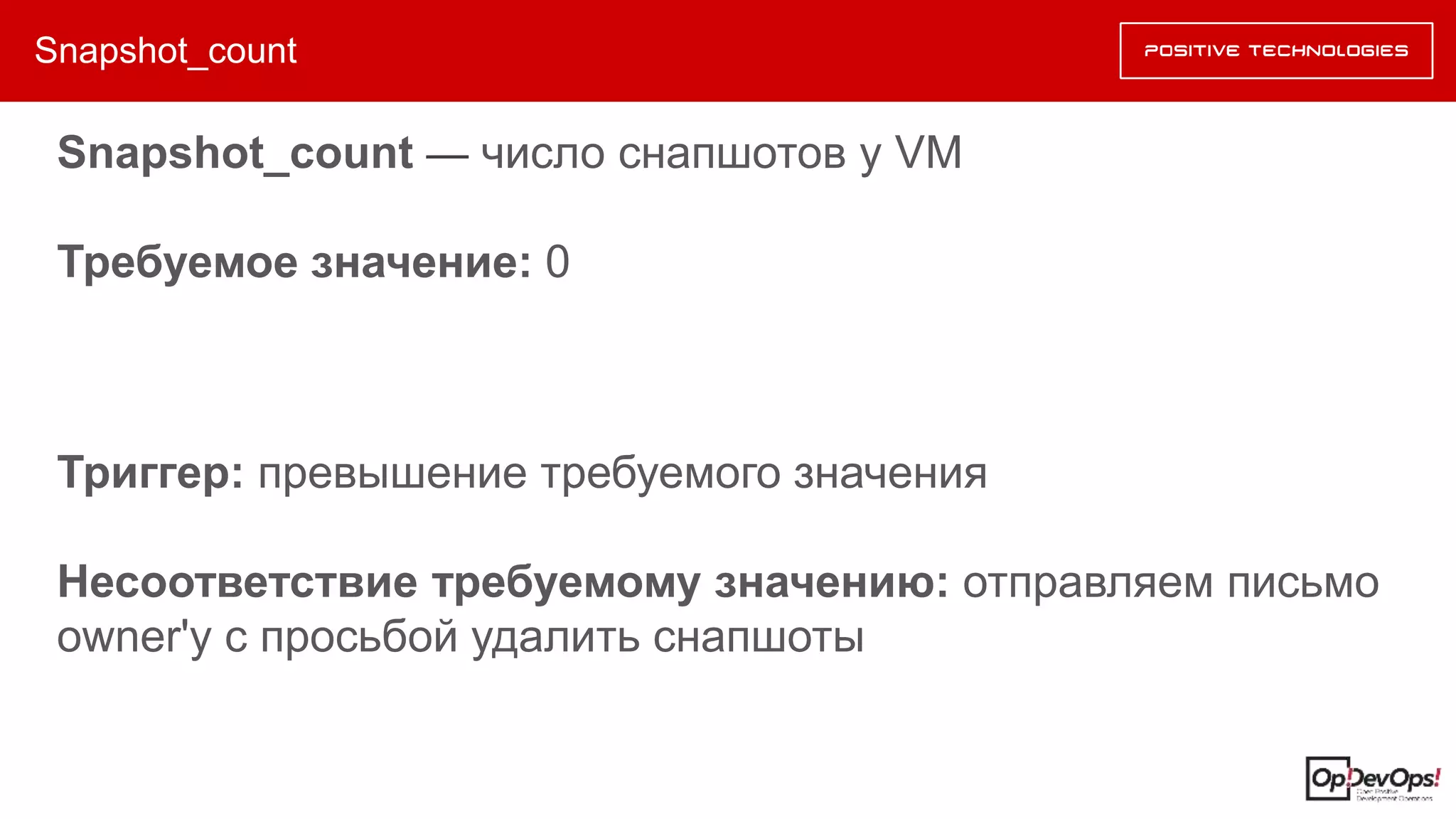




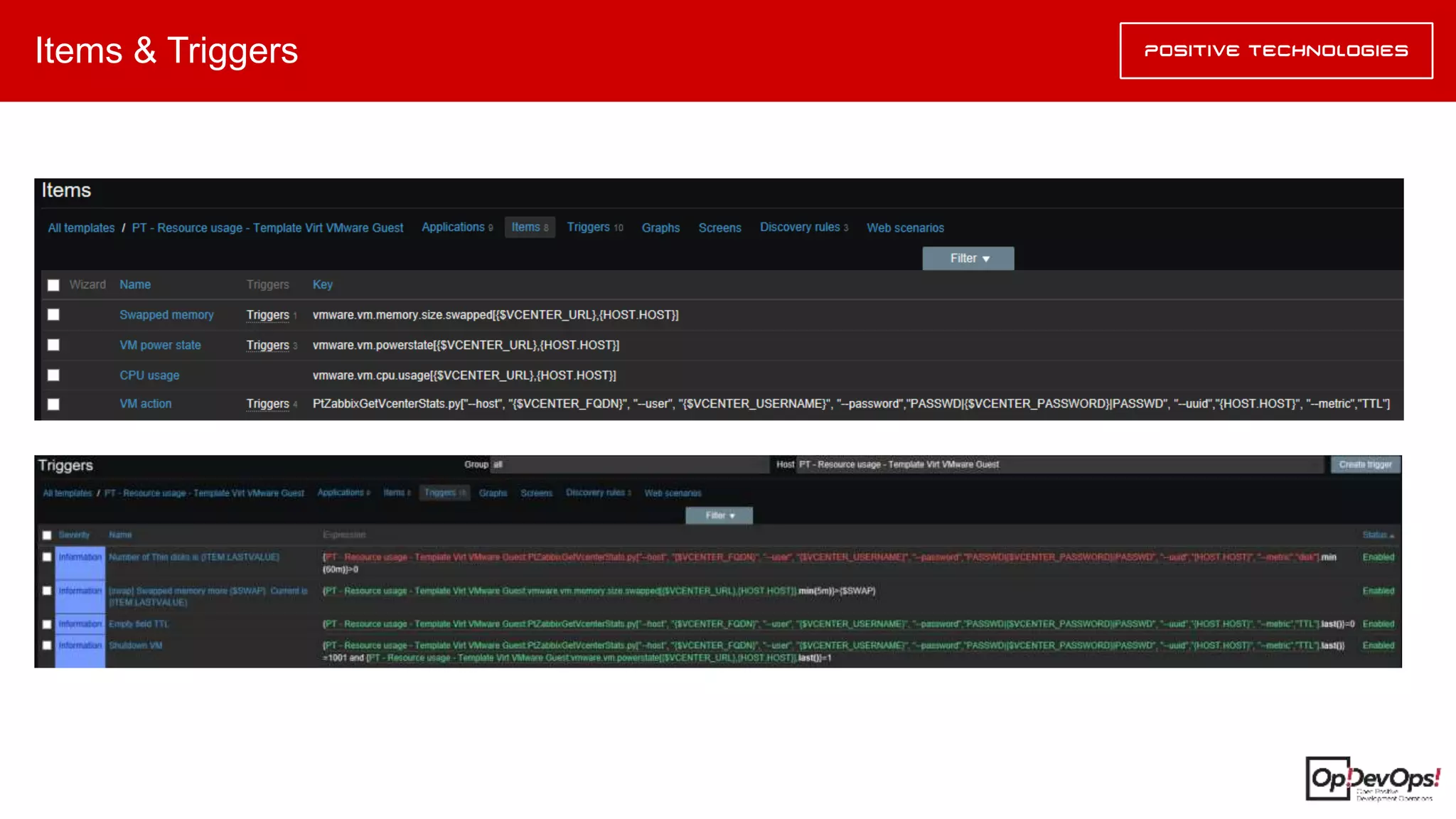











Документ описывает методику оптимизации использования ресурсов в инфраструктуре R&D, разработанную Дмитрием Мирошниченко. Главной целью является минимизация нехватки ресурсов через их оптимизацию, а не путем наращивания машинных мощностей. Методика включает автоматизированные оценки неоптимального использования ресурсов и рекомендации по их адекватному управлению.



















![Web performance 101 [GDG nsk webdev meetup #3]](https://cdn.slidesharecdn.com/ss_thumbnails/gdg-web-pref-170821085937-thumbnail.jpg?width=640&height=640&fit=bounds)

























