Paper Reading : Learning from simulated and unsupervised images through adversarial training
1.
Learning from Simulated
andUnsupervised Images
through Adversarial
Training
Ashish Shrivastava, Tomas Pfister, Oncel
Tuzel, Josh Susskind, Wenda Wang, Russ
Webb
@Mikibear_ 논문 정리 161227
2.
애플이 arXiv에 논문을
애플이arXiv에 논문을
애플이 arXiv에 논문을
애플이 arXiv에 논문을
애플이 arXiv에 논문을
애플이 arXiv에 논문을
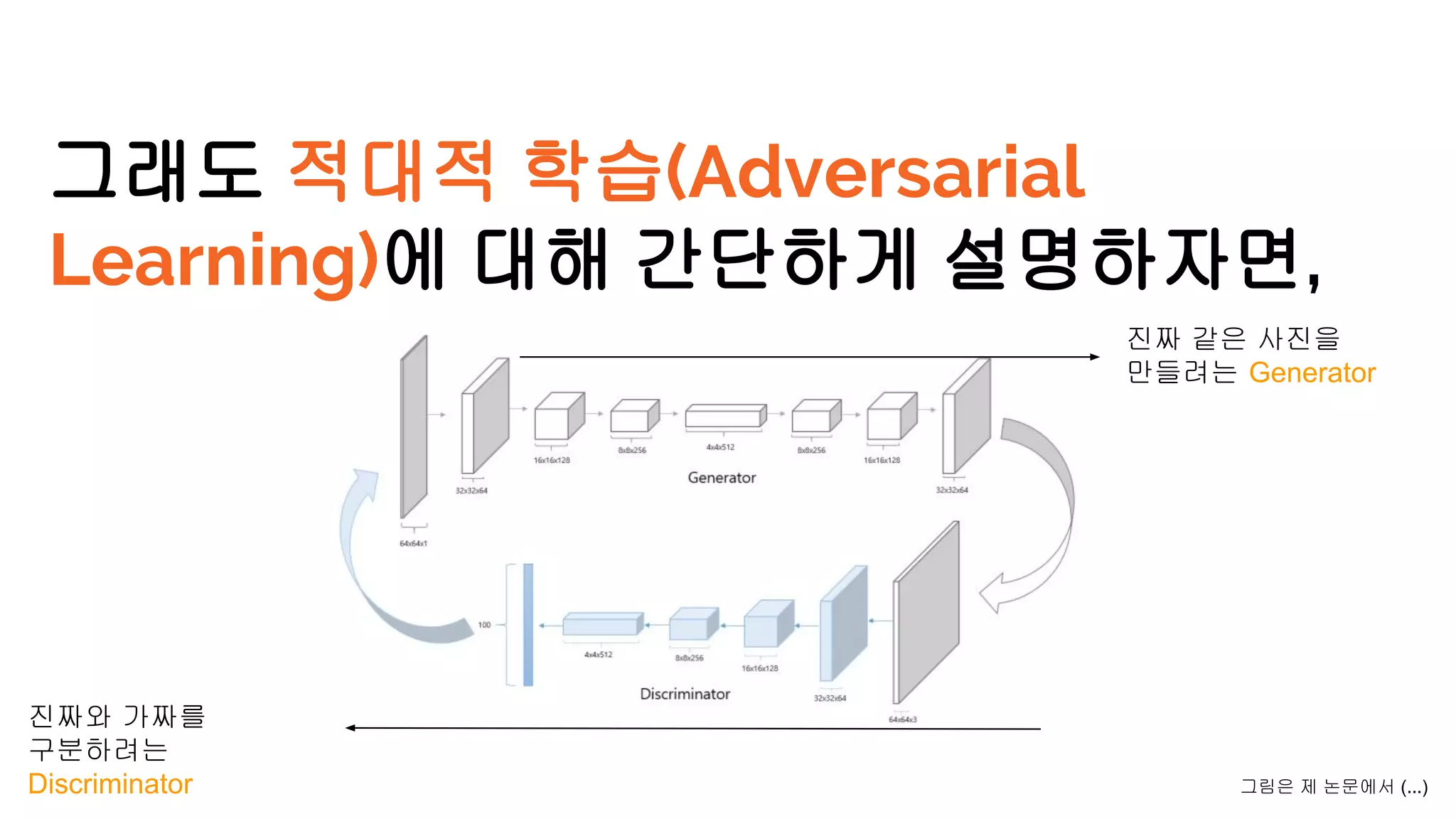
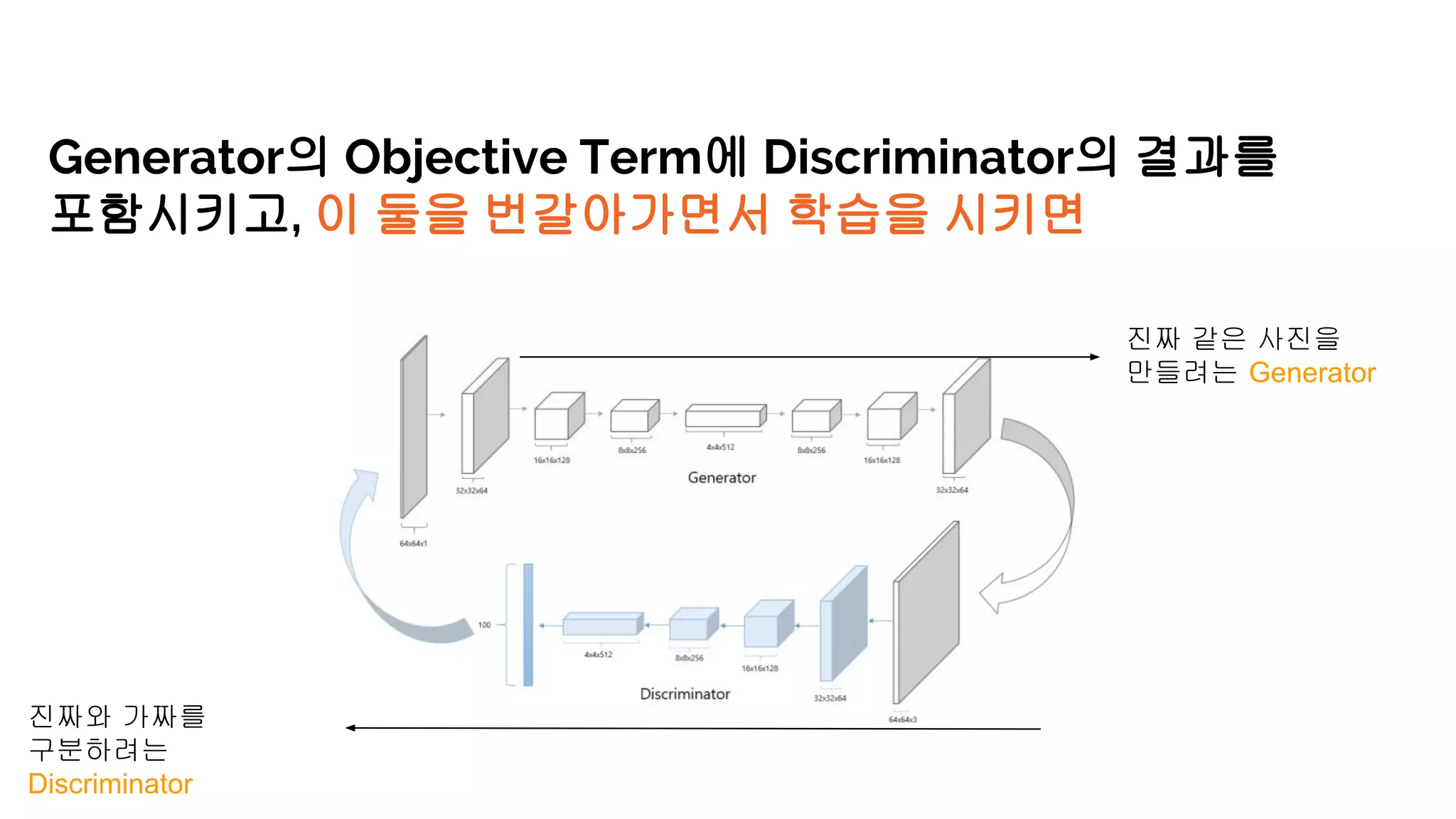
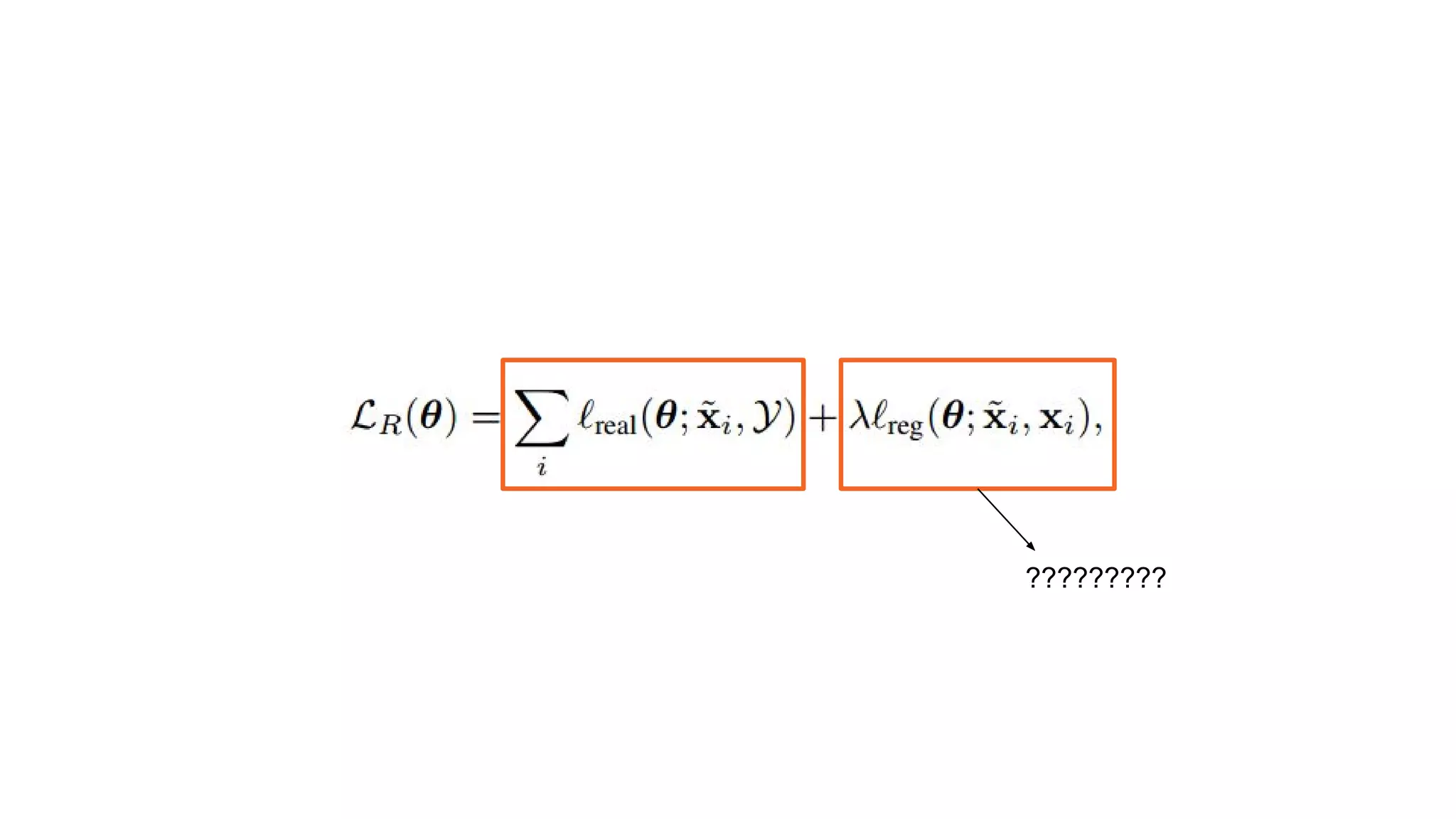
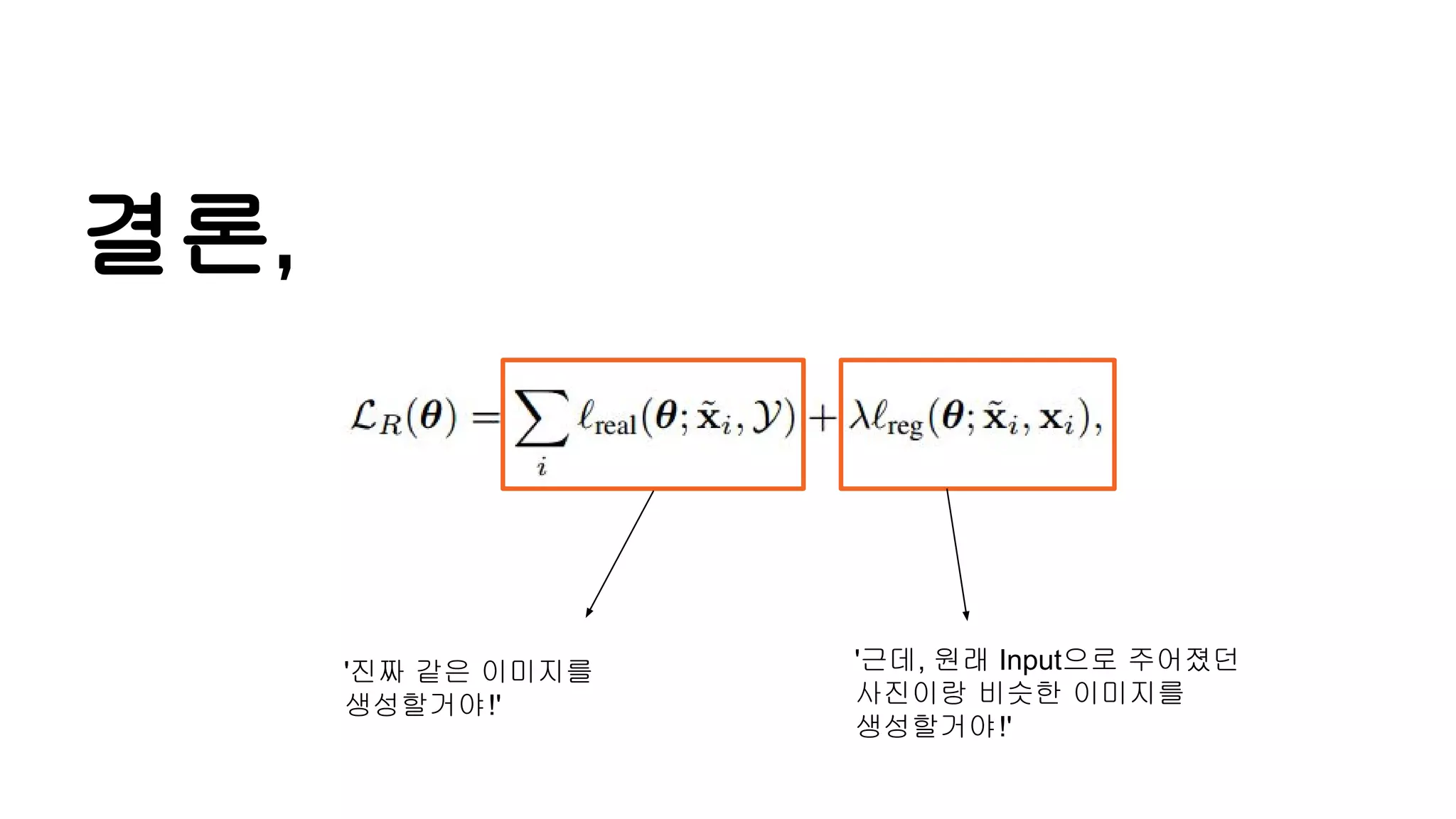
We develop amethod for S+U learning that uses an adversarial network
similar to Generative Adversarial Networks (GANs), but with synthetic images
as inputs instead of random vectors.
끝!...이라고 하면 욕먹겠죠
Generator Model의 Input으로 random vector
대신에 synthetic image를 사용함.
5.
사실 이 논문은Goodfellow의
GAN(2014)와 A Radford의
DCGAN(2016)에 대해 알고
있으면, 이와 크게 다르지
않습니다.
6.
GAN? DCGAN?
이에 대한설명은 데브시스터즈의 김태훈 씨의 한국 PyCON 2016에서의 멋진
발표가 있었으니, 링크로 대체합니다.
김태훈: 지적 대화를 위한 깊고 넓은 딥러닝 (Feat. TensorFlow)
https://www.youtube.com/watch?v=soJ-wDOSCf4&t=1s
좀 더 관심이 가시는 분은 이 두 논문을 참고하길 바랍니다.
GAN https://arxiv.org/abs/1406.2661
DCGAN https://arxiv.org/abs/1511.06434
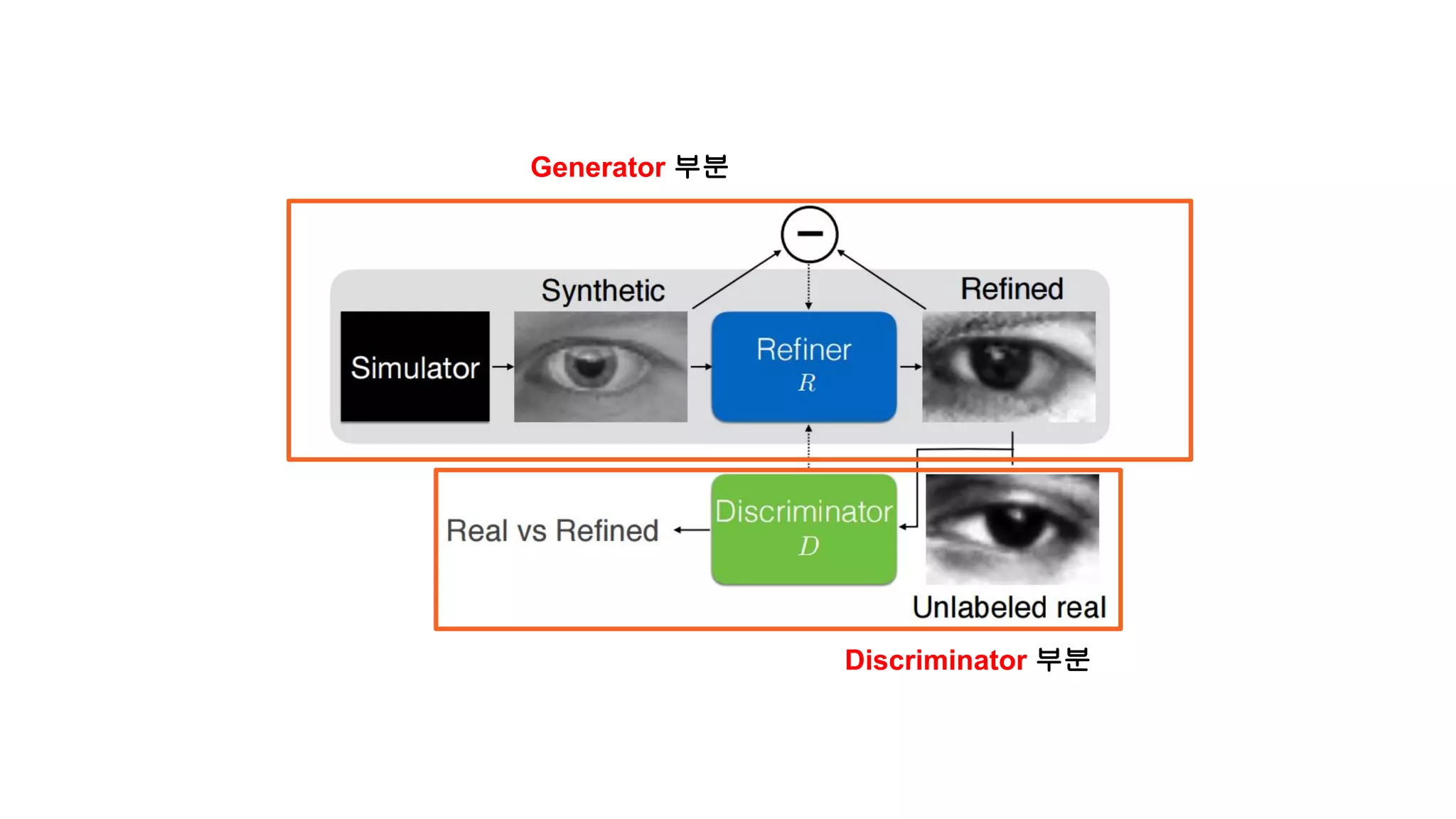
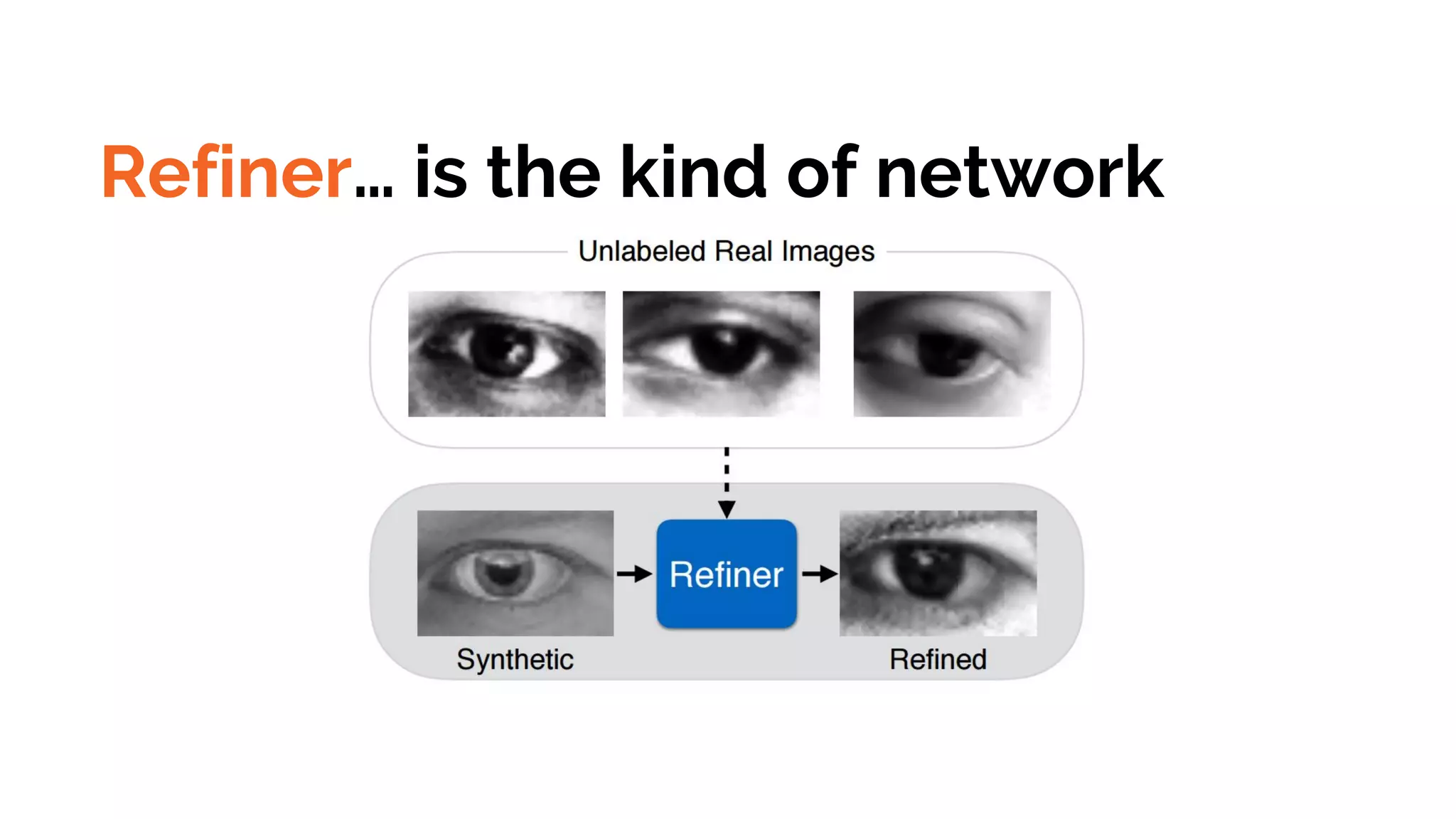
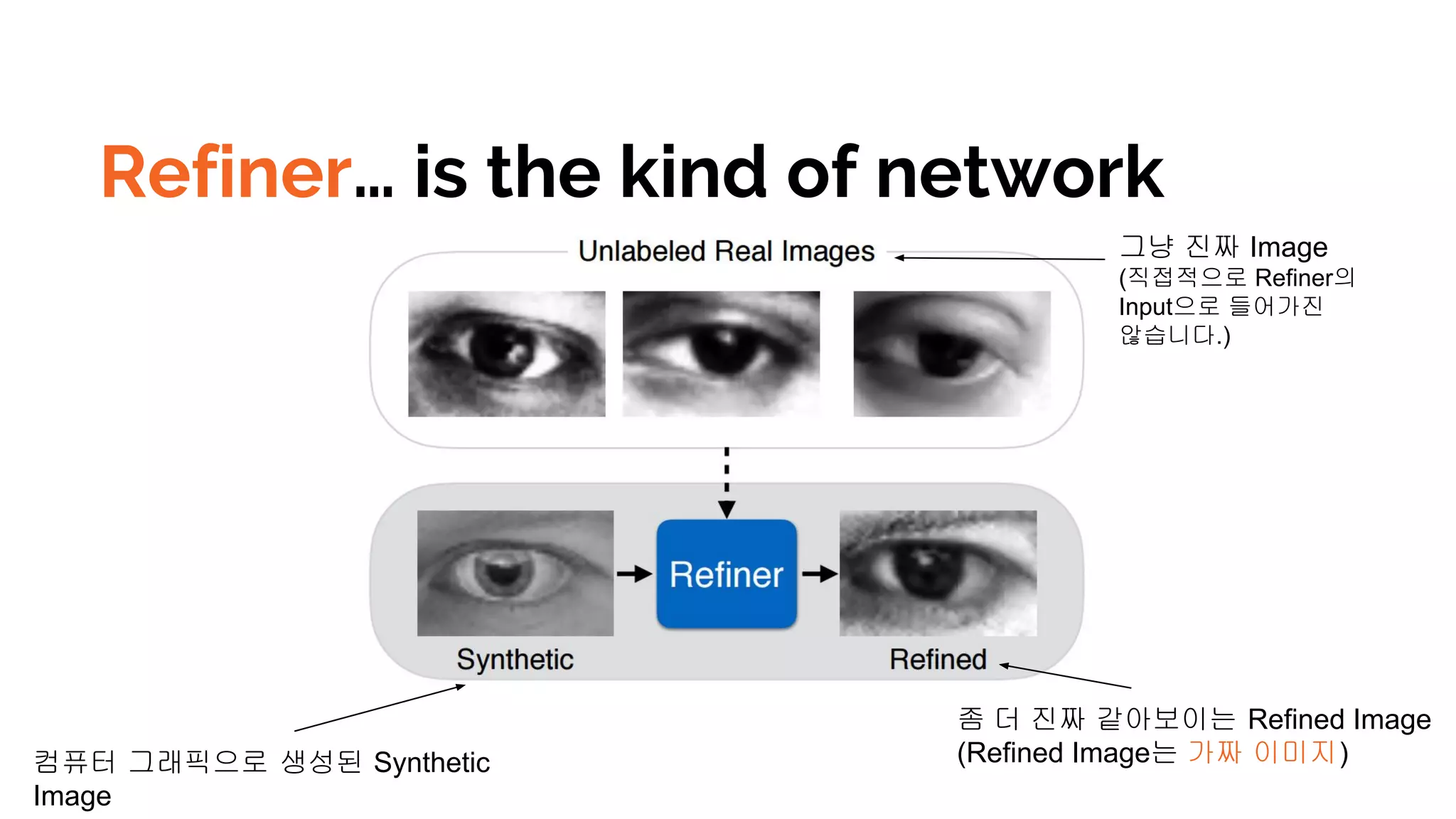
Refiner… is thekind of network
컴퓨터 그래픽으로 생성된 Synthetic
Image
그냥 진짜 Image
(직접적으로 Refiner의
Input으로 들어가진
않습니다.)
좀 더 진짜 같아보이는 Refined Image
(Refined Image는 가짜 이미지)
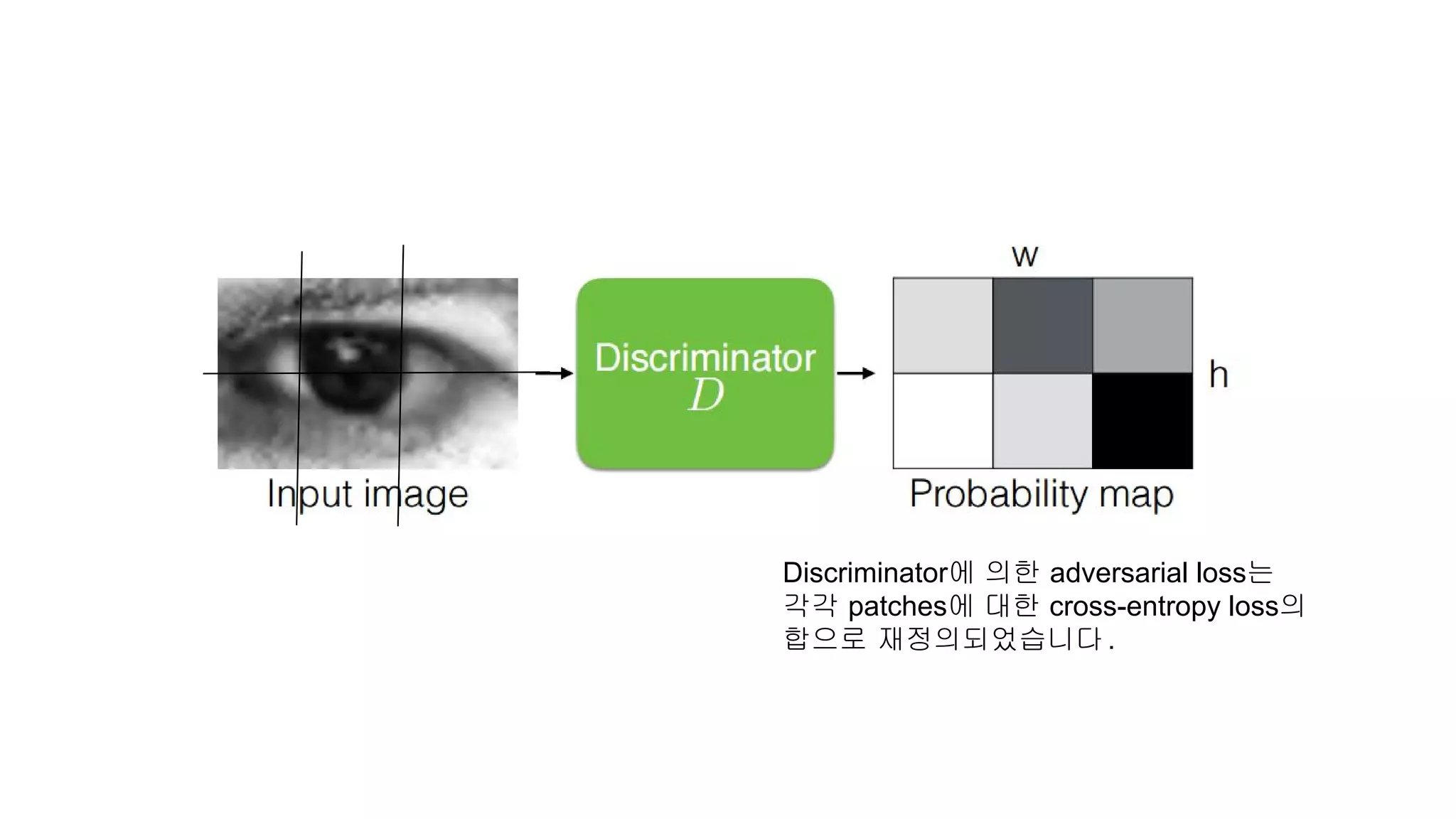
"When we traina single strong discriminator network, the refiner network tends to over-emphasize certain
image features to fool the current discriminator network, leading to drifting and producing artifacts."
:= Refiner를 뼈빠지게 학습시켜놓으니까 얘가
Discriminator가 헛짓해서 너무 학습을
못했네요
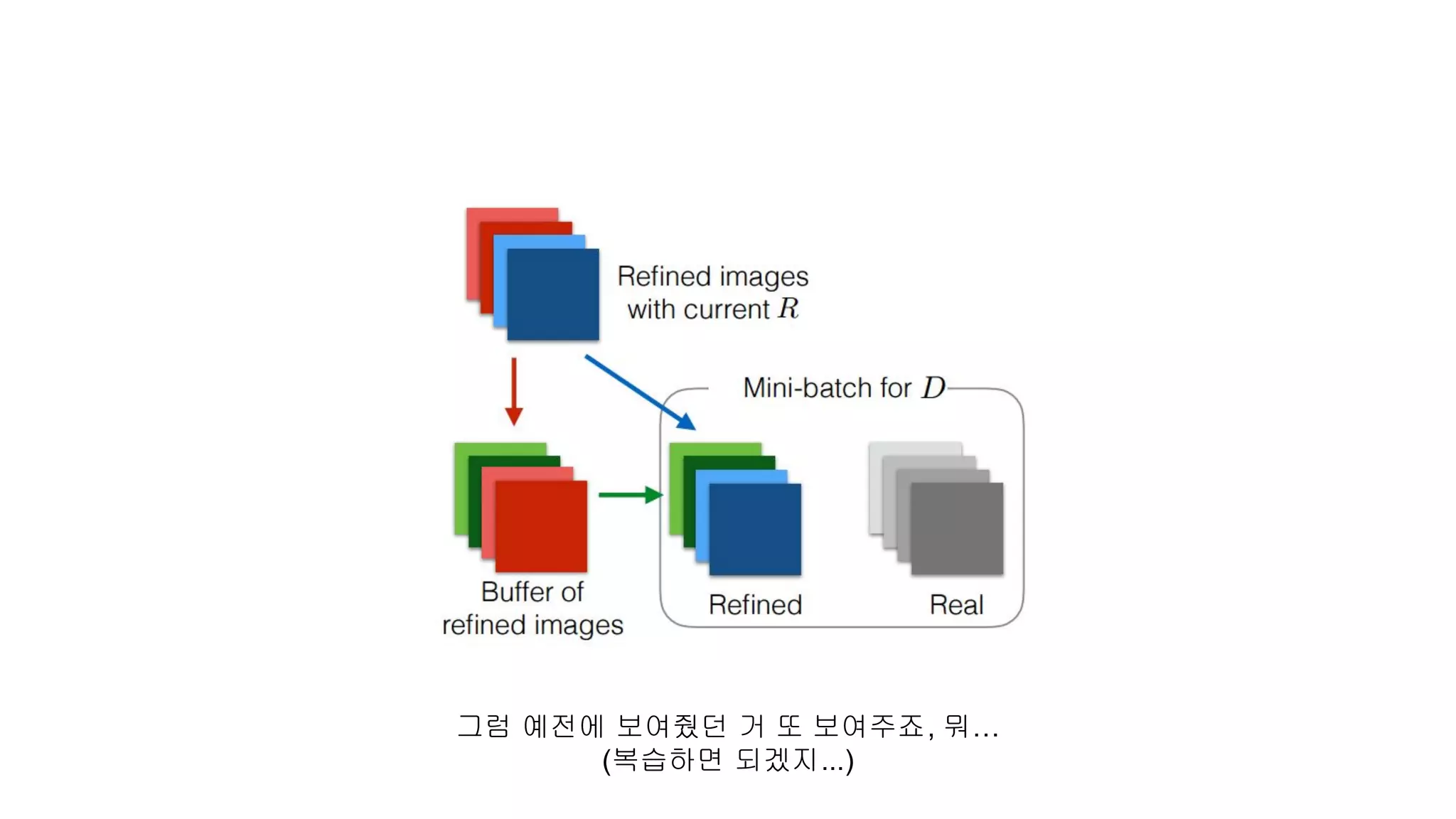
"Another problem ofadversarial training is
that the discriminator network only focuses on the latest refined images."
:= Discriminator가 멍청해서 예전에 학습했던
걸 까먹어요...
















































![[Paper Review] Image captioning with semantic attention](https://cdn.slidesharecdn.com/ss_thumbnails/imagecaptioningwithsemanticattention-180709045819-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[F2]자연어처리를 위한 기계학습 소개](https://cdn.slidesharecdn.com/ss_thumbnails/f2-120919022113-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























![[Pix2 pix] image to-image translation with conditional adversarial network re...](https://cdn.slidesharecdn.com/ss_thumbnails/pix2piximage-to-imagetranslationwithconditionaladversarialnetworkreview-200803044831-thumbnail.jpg?width=640&height=640&fit=bounds)





