근데 왜 발표함?
▪엔씨소프트, 핵심 IP 활용·인공지능 기술로 지속성장 - (헤럴드경제)
▪ 넷마블·엔씨·넥슨, AI기술 통해 재미·수명·편의성 높여 (매일경제)
▪ 블레이드&소울 '무한의 탑' 신규 콘텐츠에 인공지능 기능을 적용 (게임동아)
▪ 게임업계에도 인공지능 바람 – 엔씨, 넥슨, 넷마블 AI 적용 게임 출시 예고 (헤럴
드경제)
▪ 게임도 AI·빅데이터… '사용자 맞춤형' 나온다 – (Chosunbiz)
8.
왜 저러나 싶어찾아봤다 [활용사례]
▪ 인게임
- 밸런싱
- 특정 유저 탐지 -> 선택적/즉각적 피드백
▪ 마케팅
- 추천, 이벤트, 프로모션
- 또 특정 유저 탐지 -> 또 선택적/즉각적 피드백
- 과금전환
▪ 보안
9.
어찌보면 당연함
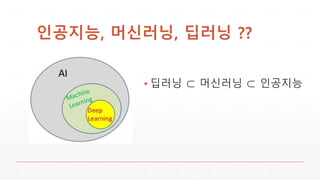
▪ 머신러닝의궁극적 목표
인간의 패턴인식능력을 데이터기반 흉내
즉, 추론가능 데이터있다면 많은것을 효율적 처리가능
▪ 게임 = 데이터 세계
10.
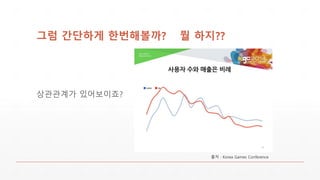
그럼 간단하게 한번해볼까?뭘 하지??
출처 : Korea Games Conference
상관관계가 있어보이죠?
11.
그럼 간단하게 한번해볼까?
▪돈좀 벌어보자! 일매출 = DAU * PU% * ARPPU
▪ DAU = SUM ( NRU * Retention )
▪ NRU는 광고 = 돈
▪ Retention = 무조건 재미
뭘 하지??
▪ 그래! “밸런싱” 너로 결정했어!! (뜬금포)
왜?? 거의 고정
변수 : 승부다!!
최종변수 : 최종승부다!!
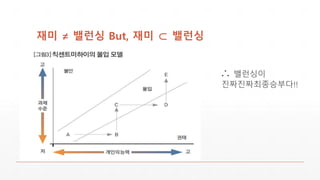
밸런싱실패에 따른 재미하락Cycle
밸런싱실패
OP챔 출현
벤시스템
OP챔 차단/선택만
중요
챔프/전략
다양성 회손
▪ 성공사례 - [도타2 디 인터내셔널6]
110명 영웅 중 105명 활용 (95.45%)
▪ 실패사례 – [롤드컵 시즌6]
131명 챔피언 중 57명 활용(43.51%)
- 롤드컵 시즌4 : 120명 중 61명 등장 (50.83%)
- 롤드컵 시즌5 : 126명 중 74명 등장 (58.73%)
14.
ML 따위 필요없다.완벽한 수기 저울질
(feat. 내 손은 금손 / chorus. MS The 엑셀)
16.
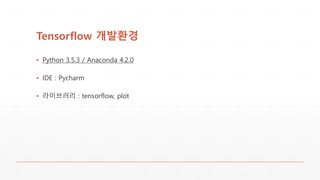
Tensorflow 소개
▪ 구글횽이만든 대표 머신러닝 라이브러리
▪ Python / C++ 지원
▪ CPU / GPU 연산지원
▪ 통계에 사용되는 각종 수학함수 제공
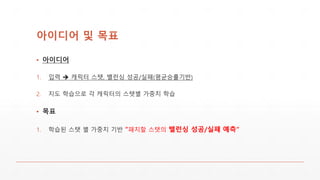
아이디어 및 목표
▪아이디어
1. 입력 캐릭터 스탯, 밸런싱 성공/실패(평균승률기반)
2. 지도 학습으로 각 캐릭터의 스탯별 가중치 학습
▪ 목표
1. 학습된 스탯 별 가중치 기반 “패치할 스탯의 밸런싱 성공/실패 예측“
19.
학습데이터 준비
▪ 밸런싱성공/실패 조건
각 캐릭터 스탯 * 가중치 = 승점
모든캐릭터의 승점 표준편차 < 2.5 성공
아니면 실패
▪ 캐릭터 스탯 종류
기본, 스킬, 아이템 (캐릭터 별 각각 가중치 존재 – unknown)
▪ 라이브러리 : tensorflow, plot
20.
Tensorflow 소스
# Lab4 Multi-variable linear regression
import tensorflow as tf
import numpy as np
tf.set_random_seed(378) # for reproducibility
xy = np.loadtxt('databalancing.csv', delimiter=',', dtype=np.float32)
#xy = np.loadtxt('databalancing_YTV.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
#x_data = (xy[:, 0:-1] - xy[:, 0:-1].mean()) / xy[:, 0:-1].std()
y_data = xy[:, [-1]]
# Make sure the shape and data are OK
#print(x_data.shape, x_data, len(x_data))
#print(y_data.shape, y_data)
# placeholders for a tensor that will be always fed.
X = tf.placeholder(tf.float32, shape=[None, 9])
Y = tf.placeholder(tf.float32, shape=[None, 1])
#정규분포
W = tf.Variable(tf.random_normal([9, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
#균등분포
#W = tf.Variable(tf.random_uniform([9, 1], minval=0.3, maxval=0.5), name='weight')
#b = tf.Variable(tf.random_normal([1]), name='bias')
# Hypothesis using sigmoid: tf.div(1., 1. + tf.exp(tf.matmul(X, W)))
hypothesis = tf.sigmoid(tf.matmul(X, W) + b)
# cost/loss function
cost = -tf.reduce_mean(Y * tf.log(tf.clip_by_value(hypothesis, 1e-8, 1.)) +
(1 - Y) * tf.log(tf.clip_by_value(1 - hypothesis, 1e-8, 1.)))
#cost = -tf.reduce_mean(Y * tf.log(hypothesis) +
# (1 - Y) * tf.log(1 - hypothesis))
# Accuracy computation
# True if hypothesis>0.5 else False
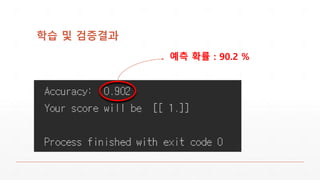
한계 및 개선방법
▪학습 데이터의 현실반영 정도 불확실 실제 게임로그 활용
▪ 스탯 입력값 범위가 넓을 경우 예측확률 떨어짐 : 90% 75%
CNN, RNN, Reinforce Learning 등 학습기법 변경 및 learning rate, 예측 기
준 최적화





![왜 저러나 싶어 찾아봤다 [활용사례]
▪ 인게임
- 밸런싱
- 특정 유저 탐지 -> 선택적/즉각적 피드백
▪ 마케팅
- 추천, 이벤트, 프로모션
- 또 특정 유저 탐지 -> 또 선택적/즉각적 피드백
- 과금전환
▪ 보안](https://image.slidesharecdn.com/random-170425072127/85/Tensorflow-8-320.jpg)


![밸런싱실패에 따른 재미하락 Cycle
밸런싱실패
OP챔 출현
벤시스템
OP챔 차단/선택만
중요
챔프/전략
다양성 회손
▪ 성공사례 - [도타2 디 인터내셔널6]
110명 영웅 중 105명 활용 (95.45%)
▪ 실패사례 – [롤드컵 시즌6]
131명 챔피언 중 57명 활용(43.51%)
- 롤드컵 시즌4 : 120명 중 61명 등장 (50.83%)
- 롤드컵 시즌5 : 126명 중 74명 등장 (58.73%)](https://image.slidesharecdn.com/random-170425072127/85/Tensorflow-13-320.jpg)




![Tensorflow 소스
# Lab 4 Multi-variable linear regression
import tensorflow as tf
import numpy as np
tf.set_random_seed(378) # for reproducibility
xy = np.loadtxt('databalancing.csv', delimiter=',', dtype=np.float32)
#xy = np.loadtxt('databalancing_YTV.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
#x_data = (xy[:, 0:-1] - xy[:, 0:-1].mean()) / xy[:, 0:-1].std()
y_data = xy[:, [-1]]
# Make sure the shape and data are OK
#print(x_data.shape, x_data, len(x_data))
#print(y_data.shape, y_data)
# placeholders for a tensor that will be always fed.
X = tf.placeholder(tf.float32, shape=[None, 9])
Y = tf.placeholder(tf.float32, shape=[None, 1])
#정규분포
W = tf.Variable(tf.random_normal([9, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
#균등분포
#W = tf.Variable(tf.random_uniform([9, 1], minval=0.3, maxval=0.5), name='weight')
#b = tf.Variable(tf.random_normal([1]), name='bias')
# Hypothesis using sigmoid: tf.div(1., 1. + tf.exp(tf.matmul(X, W)))
hypothesis = tf.sigmoid(tf.matmul(X, W) + b)
# cost/loss function
cost = -tf.reduce_mean(Y * tf.log(tf.clip_by_value(hypothesis, 1e-8, 1.)) +
(1 - Y) * tf.log(tf.clip_by_value(1 - hypothesis, 1e-8, 1.)))
#cost = -tf.reduce_mean(Y * tf.log(hypothesis) +
# (1 - Y) * tf.log(1 - hypothesis))
# Accuracy computation
# True if hypothesis>0.5 else False](https://image.slidesharecdn.com/random-170425072127/85/Tensorflow-20-320.jpg)









![NDC 2015 이광영 [야생의 땅: 듀랑고] 전투 시스템 개발 일지](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2015-kwangyoung-150522112340-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[IGC 2017] 넥슨코리아 오현근 - 평생 게임 기획자 하기](https://cdn.slidesharecdn.com/ss_thumbnails/igc2017in-170905063633-thumbnail.jpg?width=640&height=640&fit=bounds)




![[NDC 2010] 그럴듯한 랜덤 생성 컨텐츠 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/hsf4fdvtjgcprbeczm9r-signature-8b01151cfddd883a338efa8a6603d585034336564338d911ab6e95aca4592fa0-poli-150122014503-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[IGC 2017] 넥슨코리아 심재근 - 시스템 기획자에 대한 기본 지식과 준비과정](https://cdn.slidesharecdn.com/ss_thumbnails/igc-170905073804-thumbnail.jpg?width=640&height=640&fit=bounds)


![NDC 2015. 한 그루 한 그루 심지 않아도 돼요. 생태학에 기반한 [야생의 땅: 듀랑고]의 절차적 생성 생태계](https://cdn.slidesharecdn.com/ss_thumbnails/zxw42orfsbyogfutmcuz-signature-336dceb59671a895fbf4d561f6799d39719d30f09e04cae133a46c0a8f86264a-poli-150519075553-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)










![[NDC2016] 신경망은컨텐츠자동생성의꿈을꾸는가](https://cdn.slidesharecdn.com/ss_thumbnails/random-160427135746-thumbnail.jpg?width=640&height=640&fit=bounds)



![[125] 머신러닝으로 쏟아지는 유저 cs 답변하기](https://cdn.slidesharecdn.com/ss_thumbnails/25cs-171016061055-thumbnail.jpg?width=640&height=640&fit=bounds)









