Downloaded 11 times







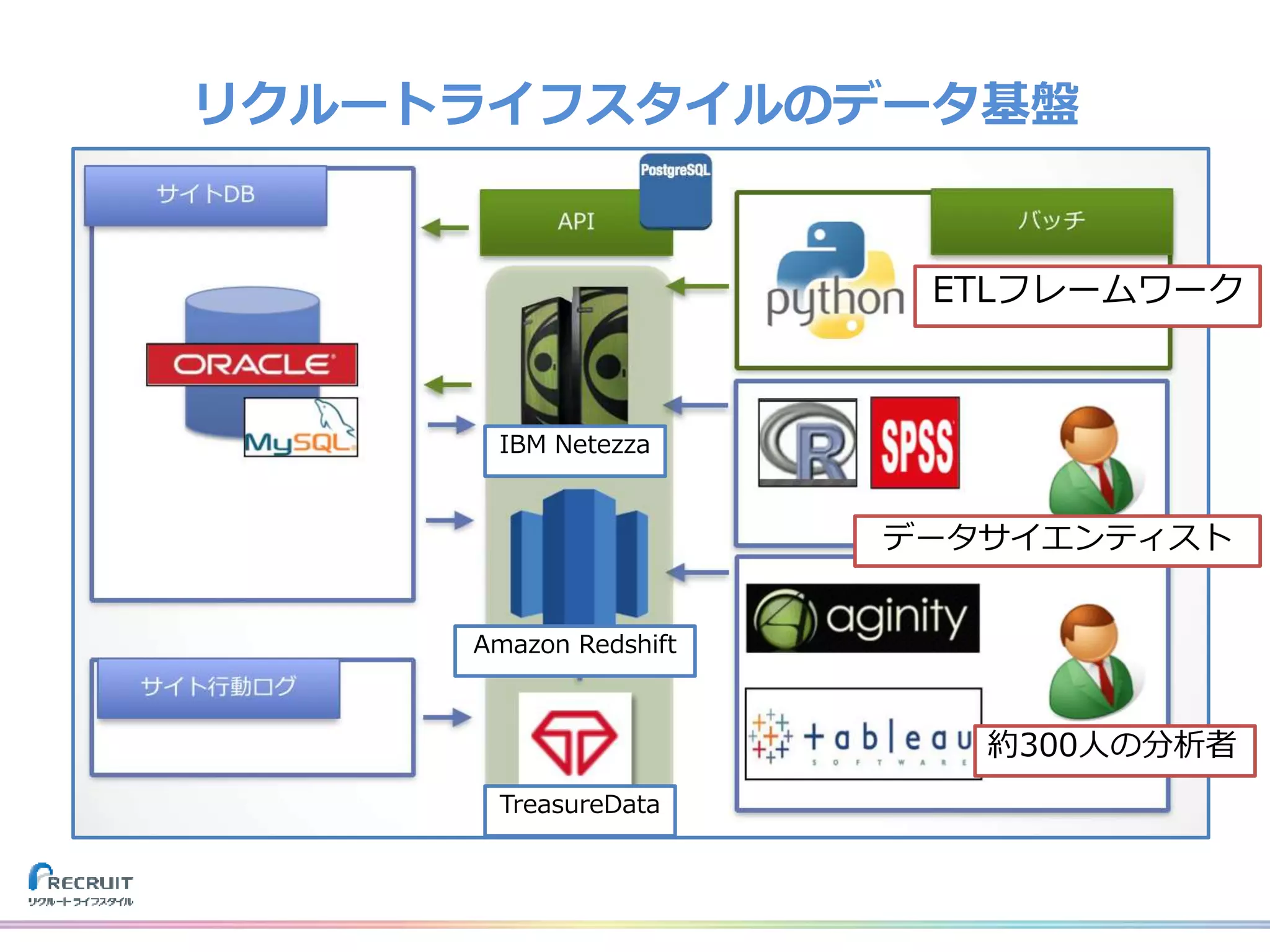







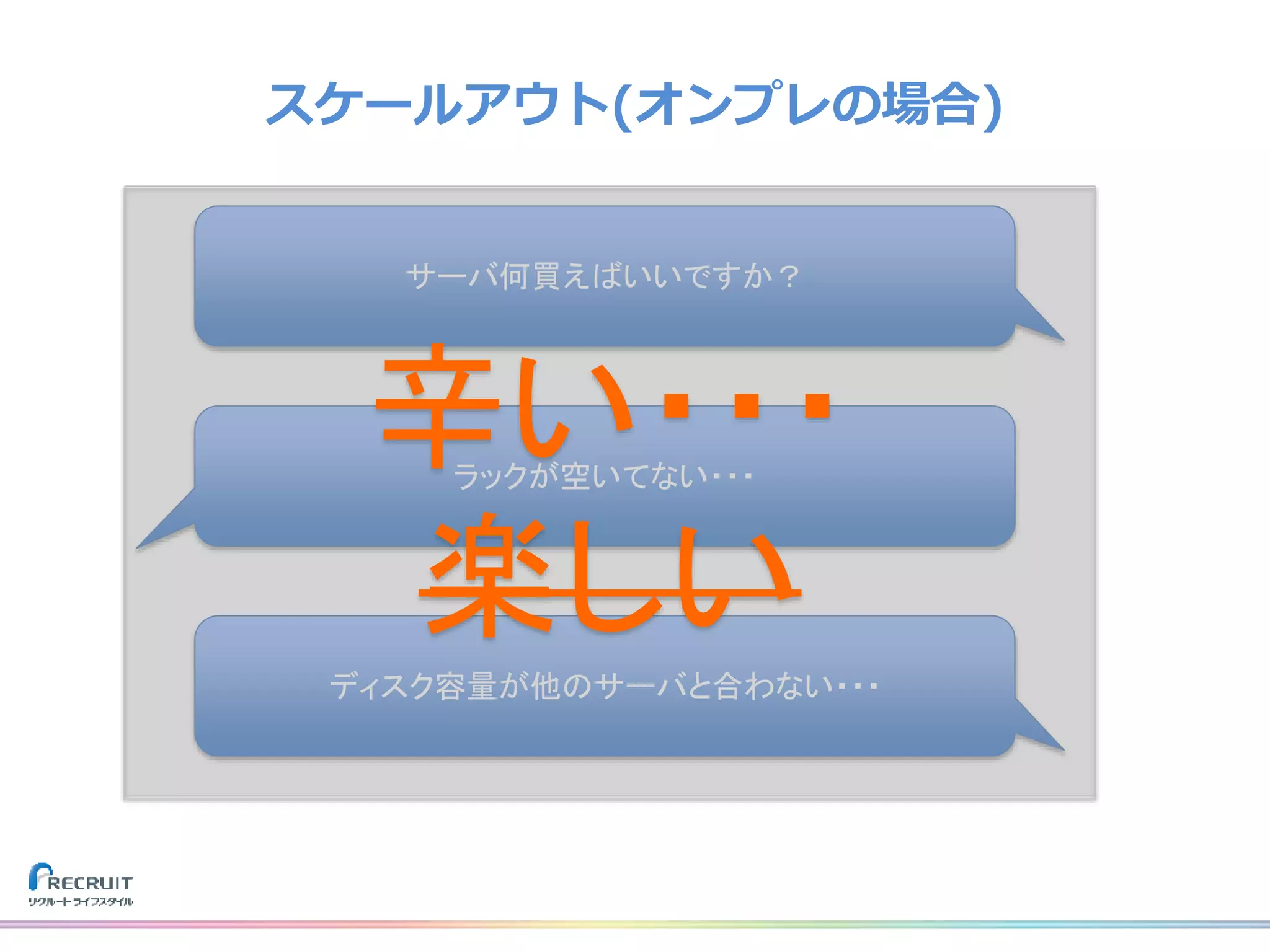


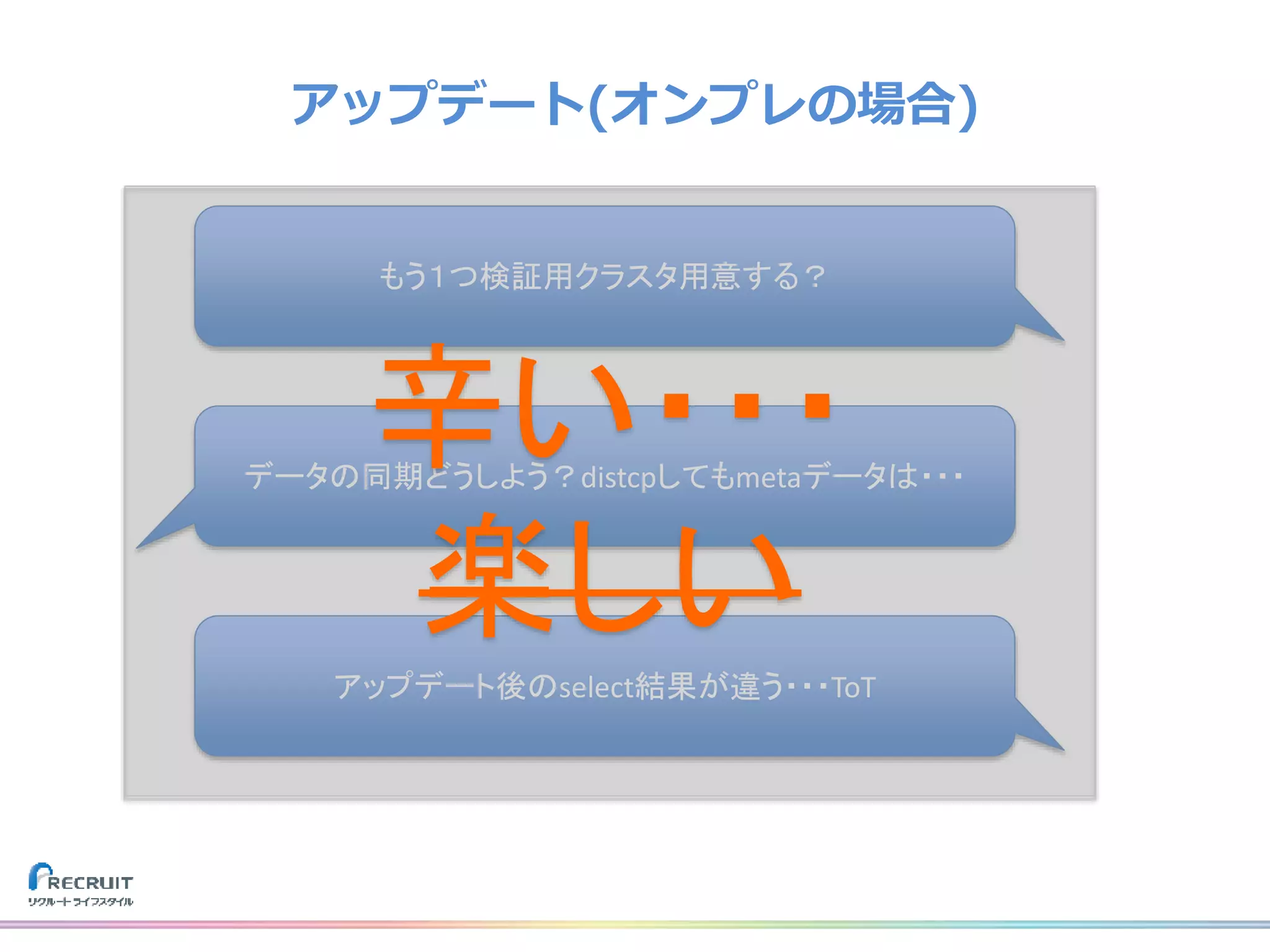

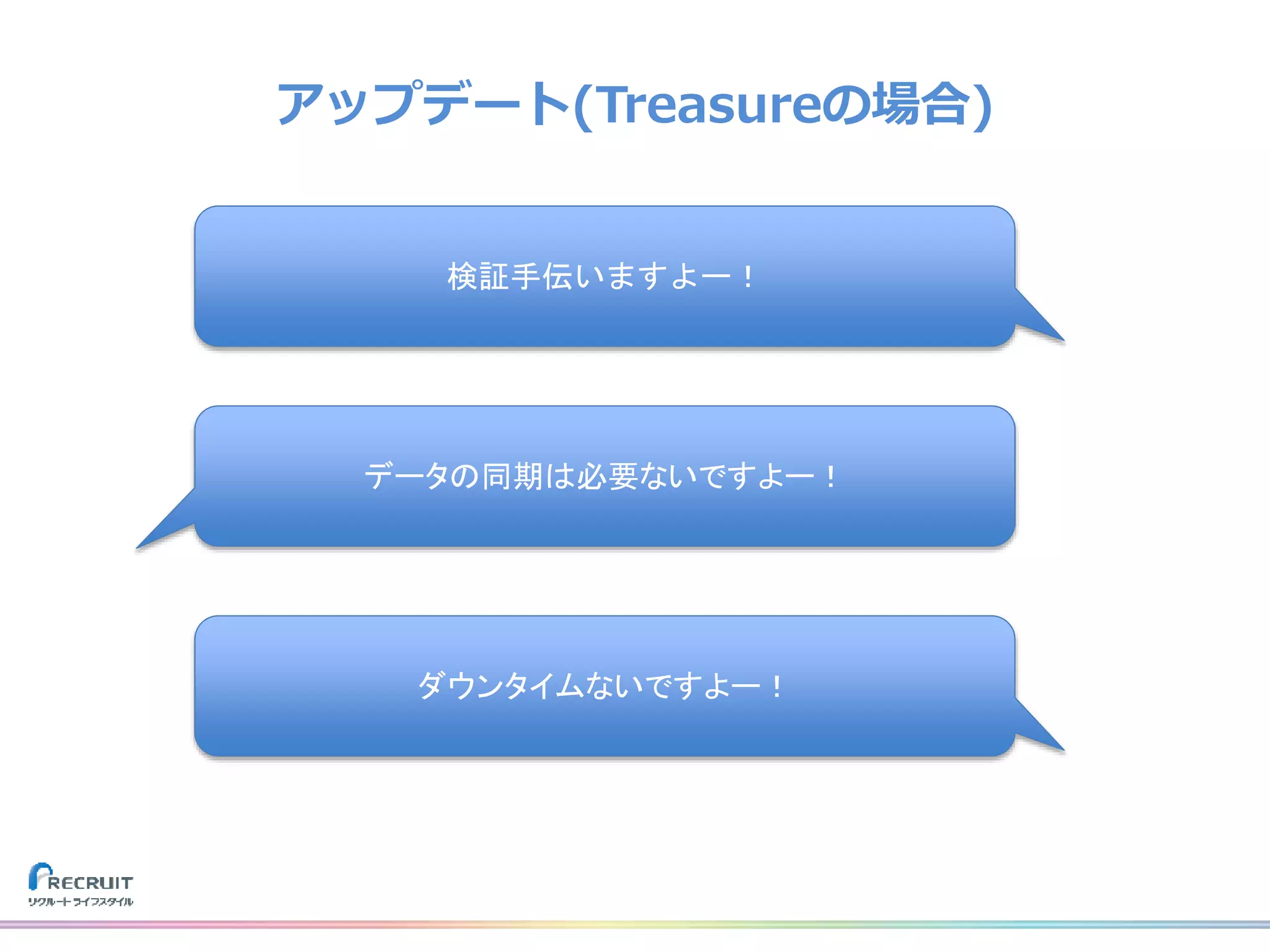










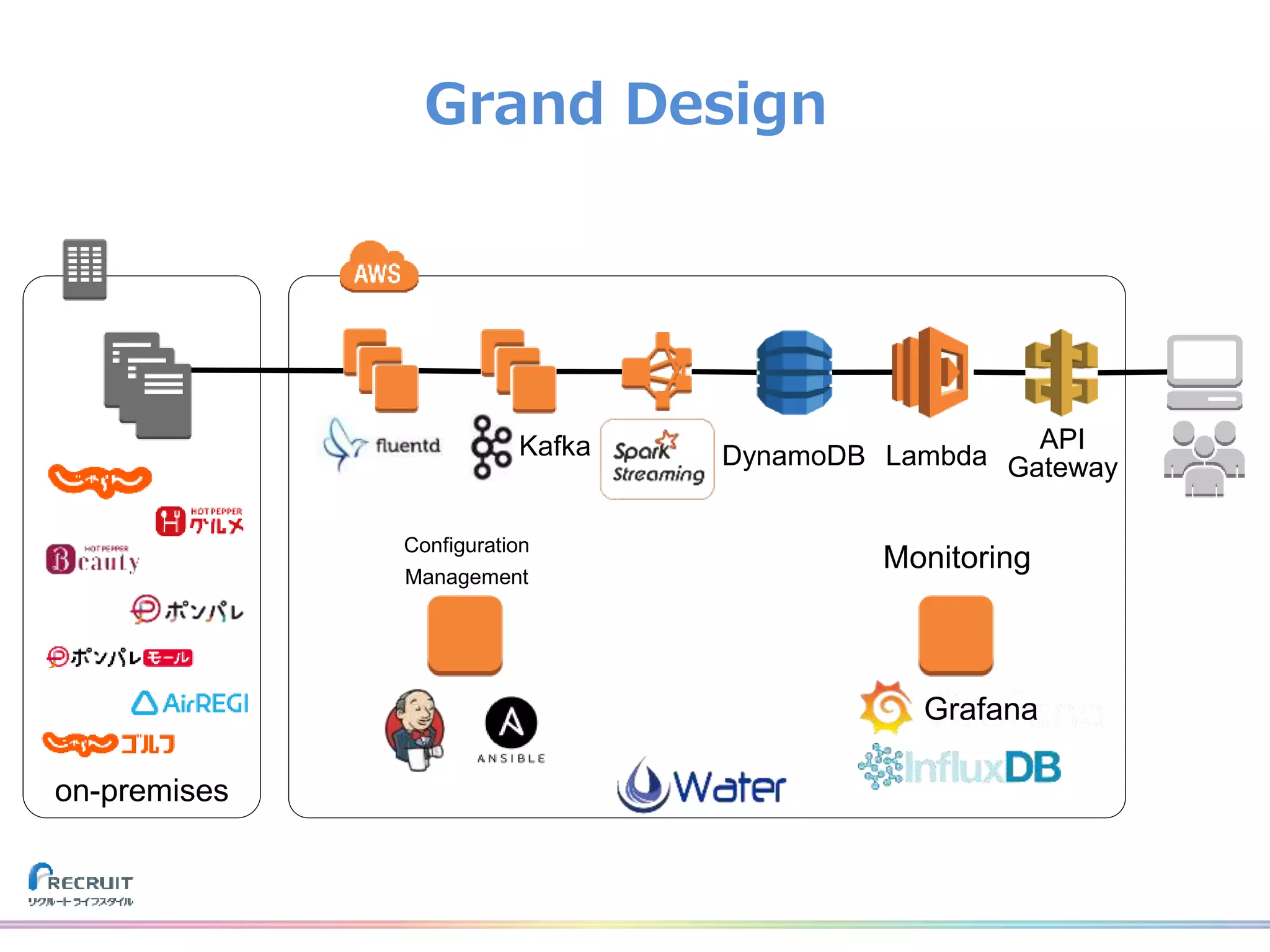

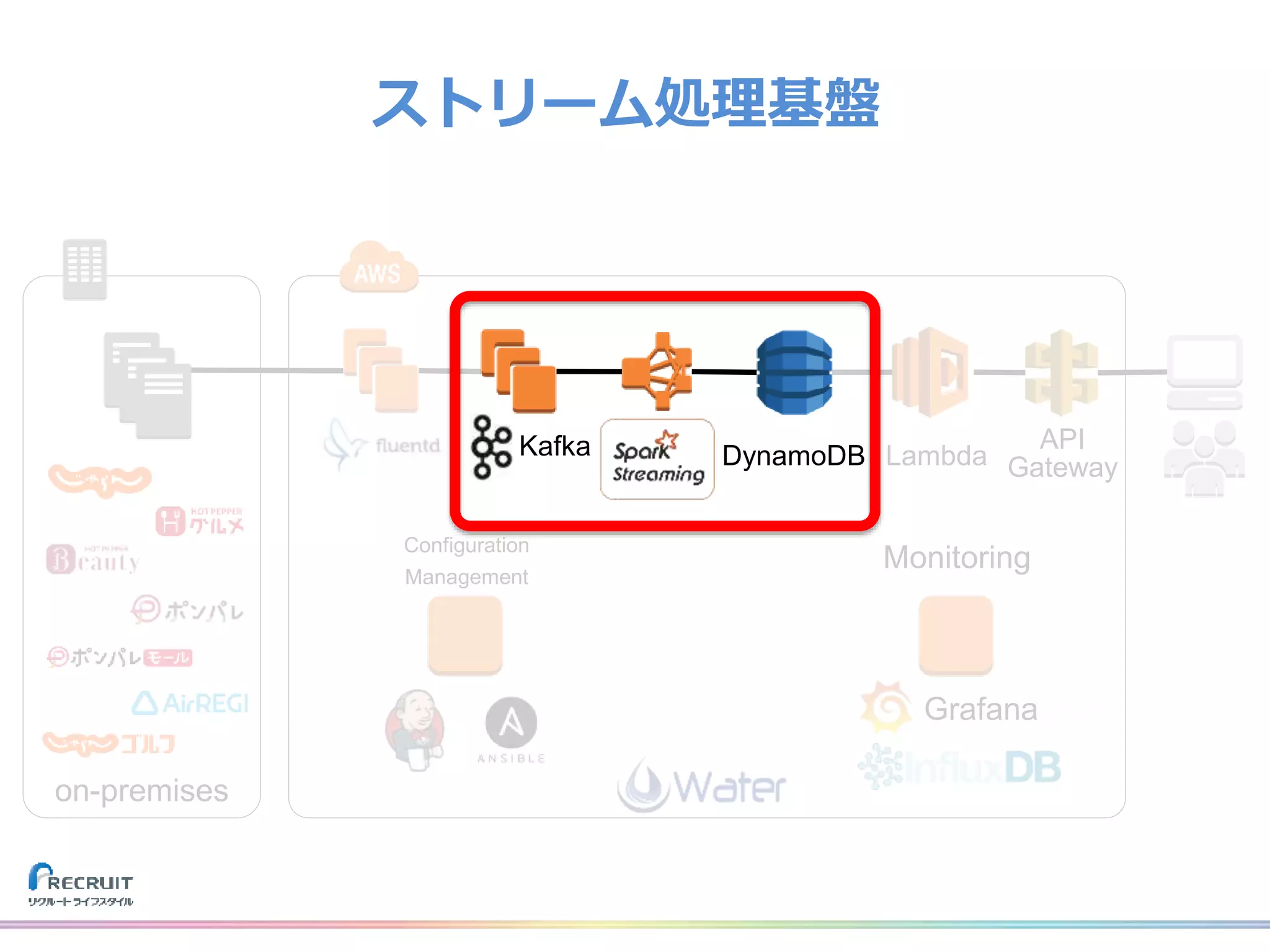
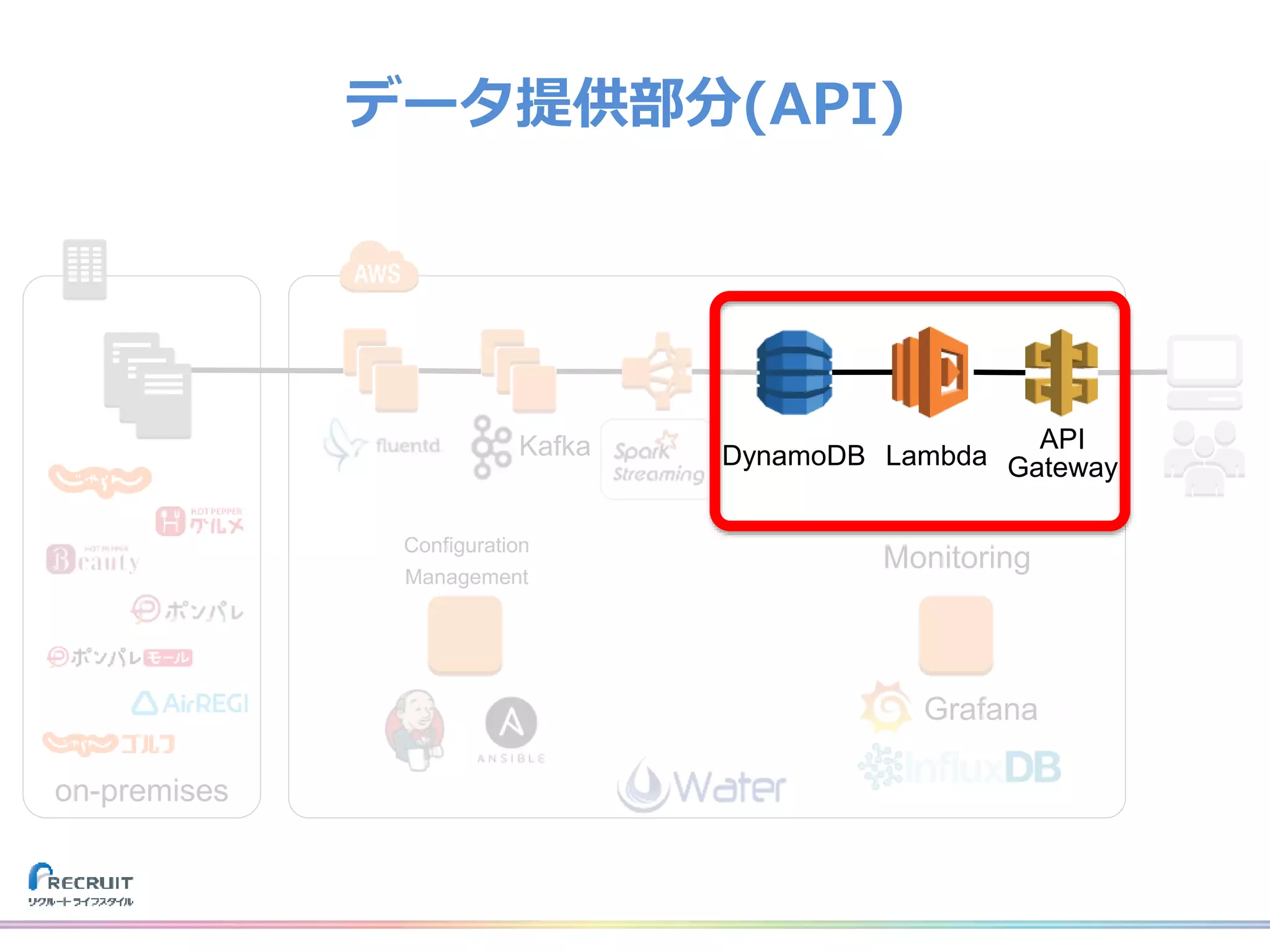









リクルートライフスタイルでは、飲食店や美容室の予約、旅行の予約や観光情報、ECなどみなさまの日常に密接した情報を提供し、それらから生まれる様々なデータを活用し、よりよいサービスを提供しています。 それらのデータを収集する基盤をTreasureDataなどのクラウドサービスを使用して構築しました。なぜこれらのプロダクトを選び、どのようにデータを収集しているのか、社内では収集したデータをどのように活用しているのか紹介致します。 また、現在取り組んでいるリアルタイムデータ集計処理基盤とこれからについてもお話させて頂けたらと思います。 山田 雄(株式会社リクルートライフスタイル)






































![[よくわかるクラウドデータベース] リクルートにおけるRedshift導入・活用事例](https://cdn.slidesharecdn.com/ss_thumbnails/20140117aws-140128175458-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


































