Download as PDF, PPTX




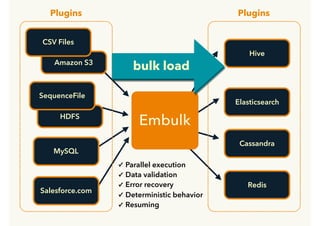




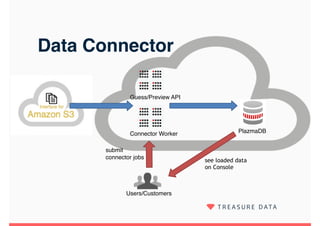
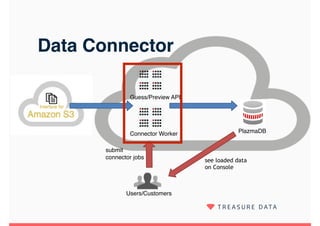
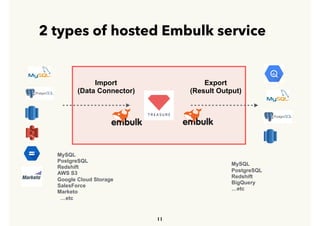
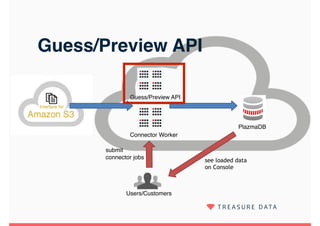

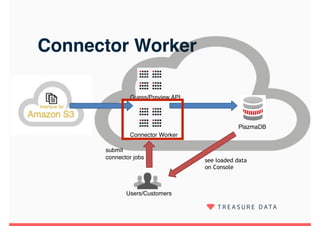

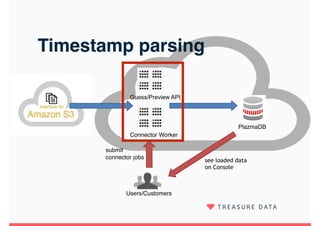



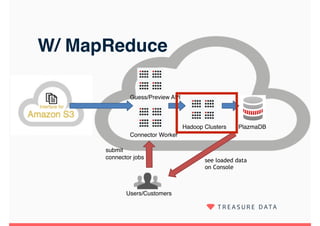
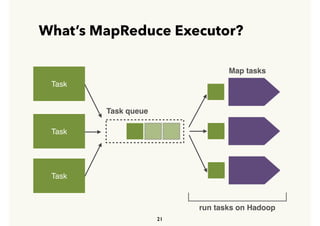
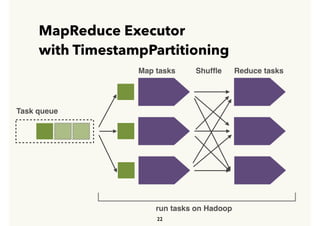

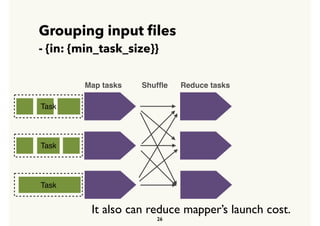
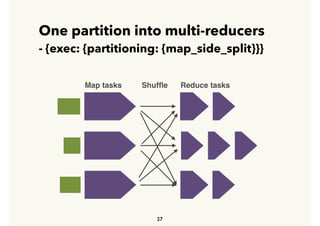



Embulk is an open-source tool for bulk loading data between various data sources. It provides parallel execution, data validation, error recovery, and other features. Customers use Embulk to upload various file formats and data sources to Treasure Data. The architecture includes a data connector that submits Embulk jobs to connector workers, which generate Embulk configurations and load data directly into Treasure Data using a private output plugin. To scale to large data loads, an optional MapReduce executor can run Embulk tasks on Hadoop clusters in parallel.













![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)












































