Stream Analytics features
・Pythonstreaming(Beta)
Author streaming jobs in Python through Apache Beam.
・Dataflow Streaming Engine
Enable separation of compute and storage for more responsive autoscaling on fewer resources.
・Dataflow Shuffle(batch)
Improve underlying capabilities of Dataflow. Yielding faster and analytics and transformations.
・Better, Faster Pub/Sub
High perf client libraries in 7 languages, GRPC streaming APIs.
・Confluent Kafka Service
Managed Kafka service on GCP from Confluent.
Dataproc and Composerfeatures
・Cloud Composer GA
Managed Airflow service Cloud Composer now Available in GA.
・Dataproc enhancements release 1.3
Spark 2.3, Hadoop 2.9, Defaults include Tez, YARN timeline server, HCatalog.
・Customer managed Encryption Keys
CMEK support for BQ(GA). GCE(Beta) and GCS(Beta).
・Autoscaling & custom packages(Alpha)
Autoscaling Hadoop and Spark clusters & selection of Apache projects.
・Hortonworks support for GCP
Run HDP and HDF on GCP with GCS as data lake.


















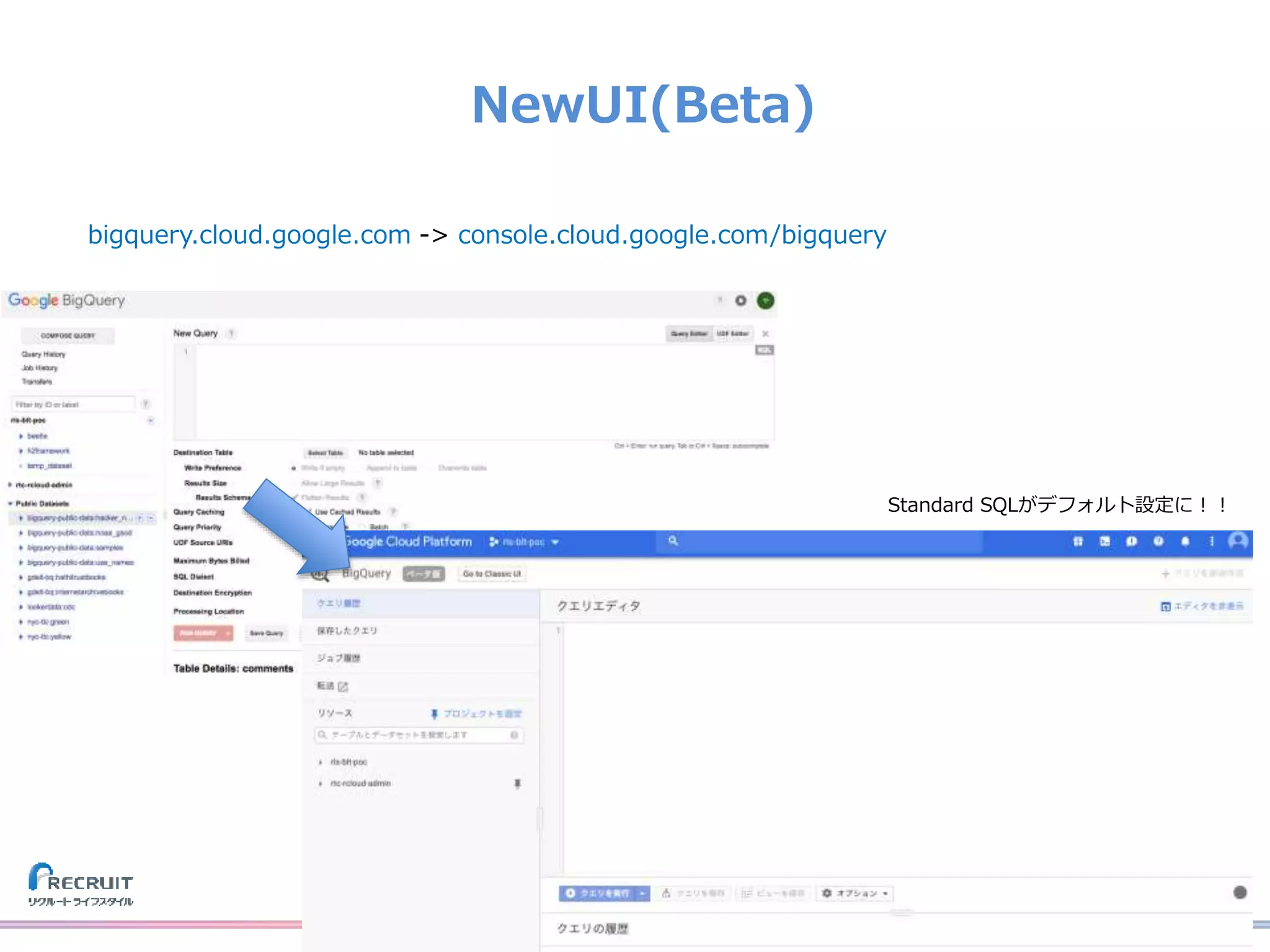



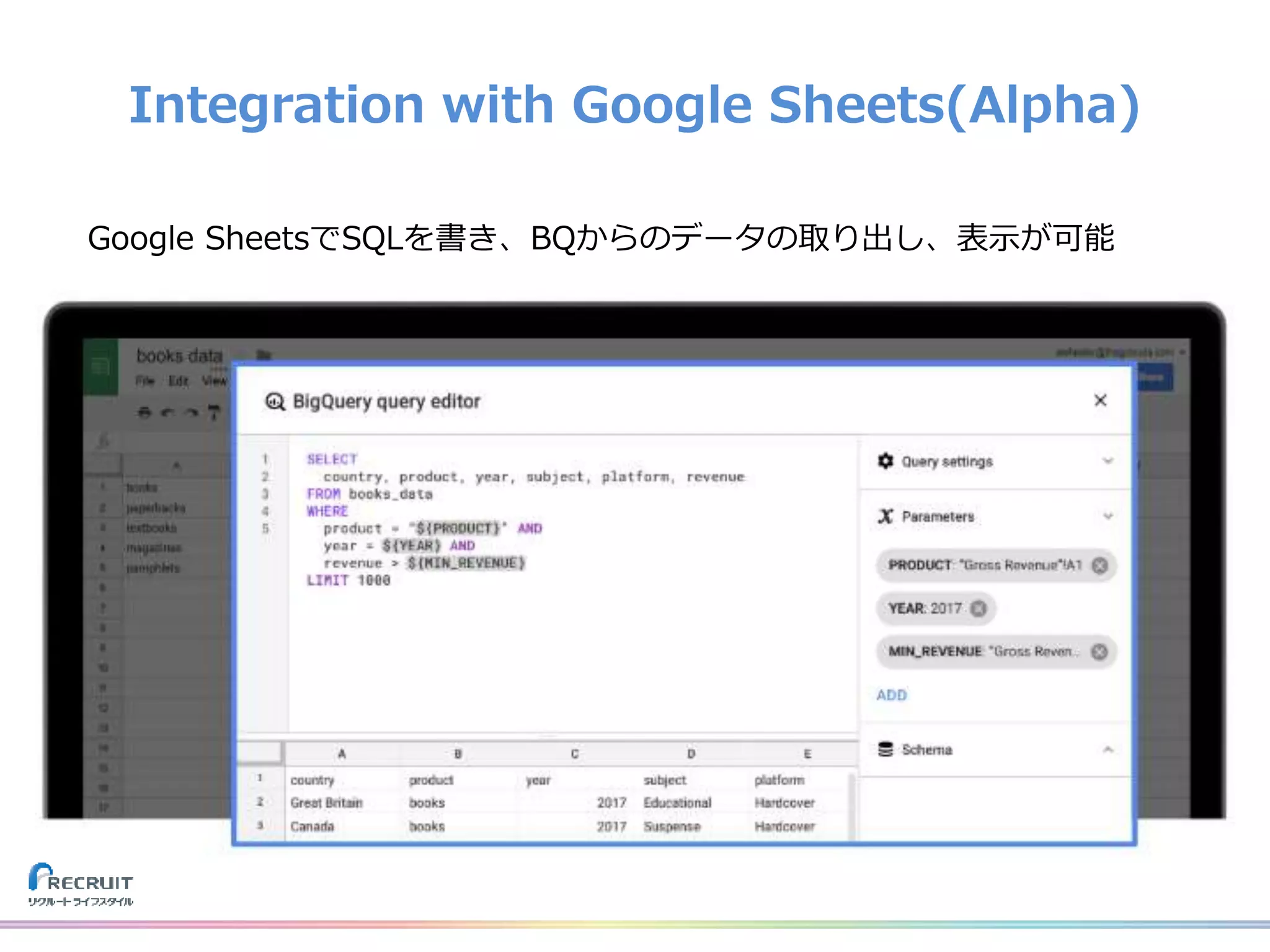

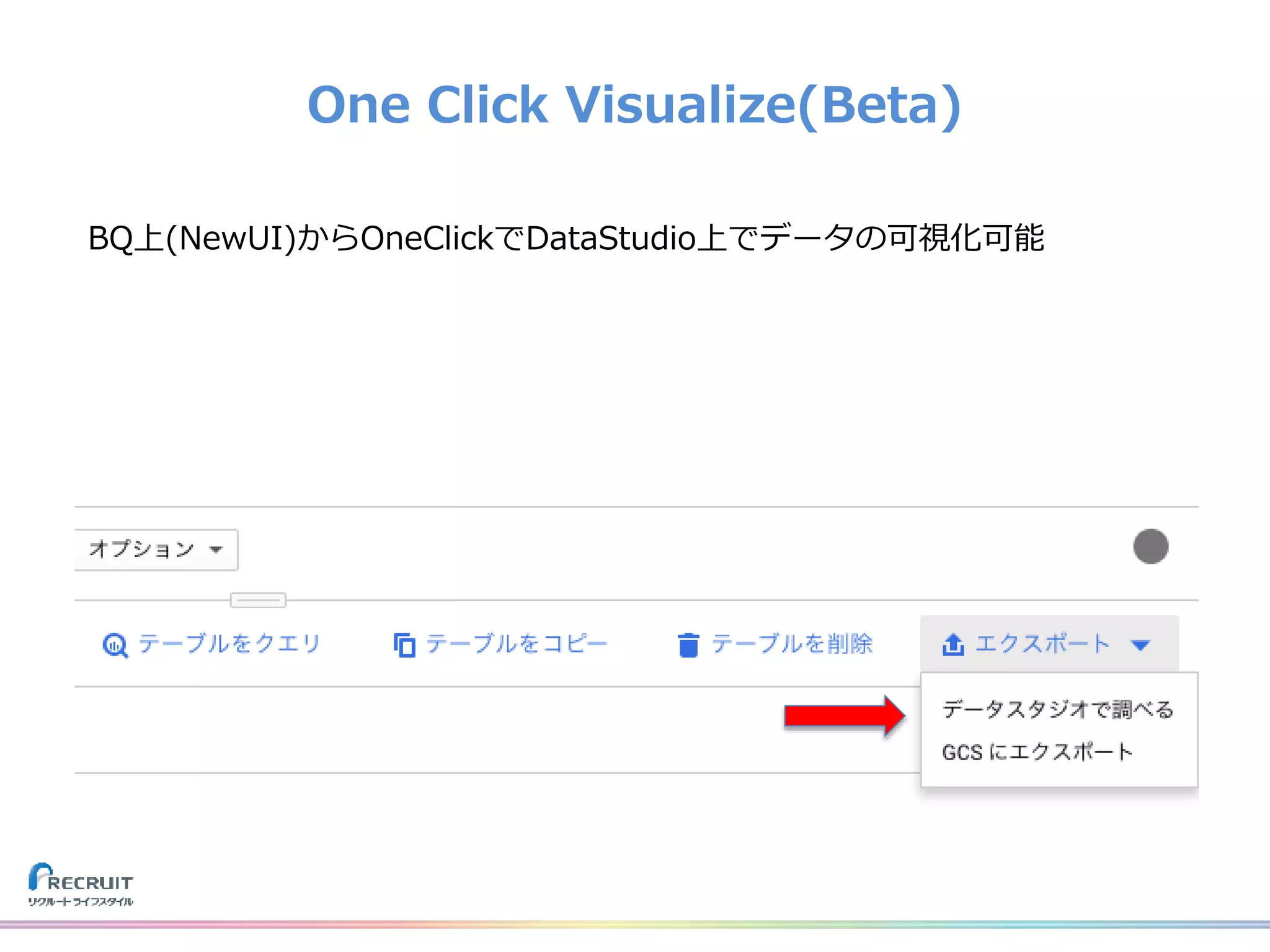







































![[Cloud OnAir] 最新アップデート Google Cloud データ関連ソリューション 2020年5月14日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0514-200514080330-thumbnail.jpg?width=640&height=640&fit=bounds)











