Download to read offline












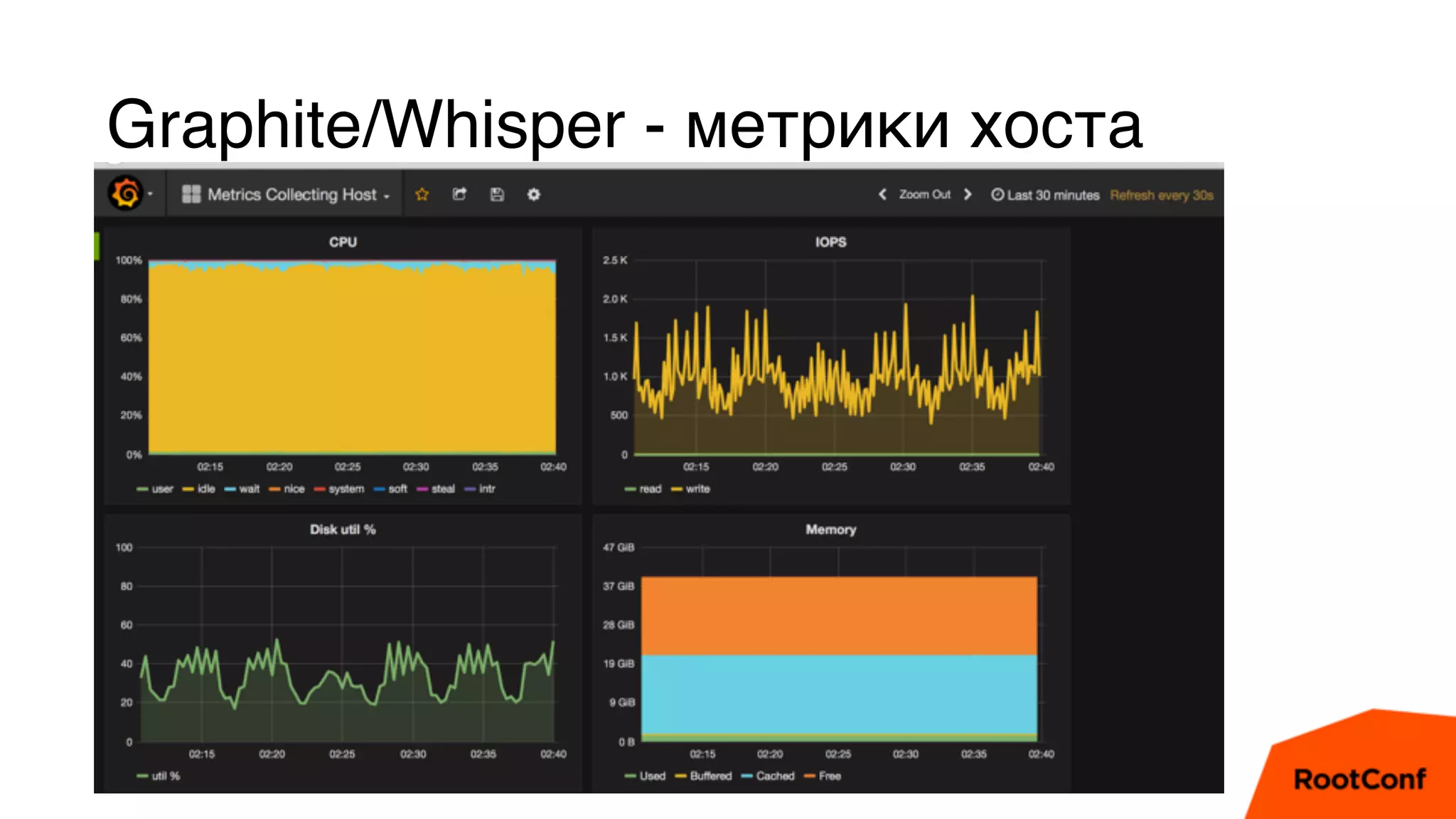
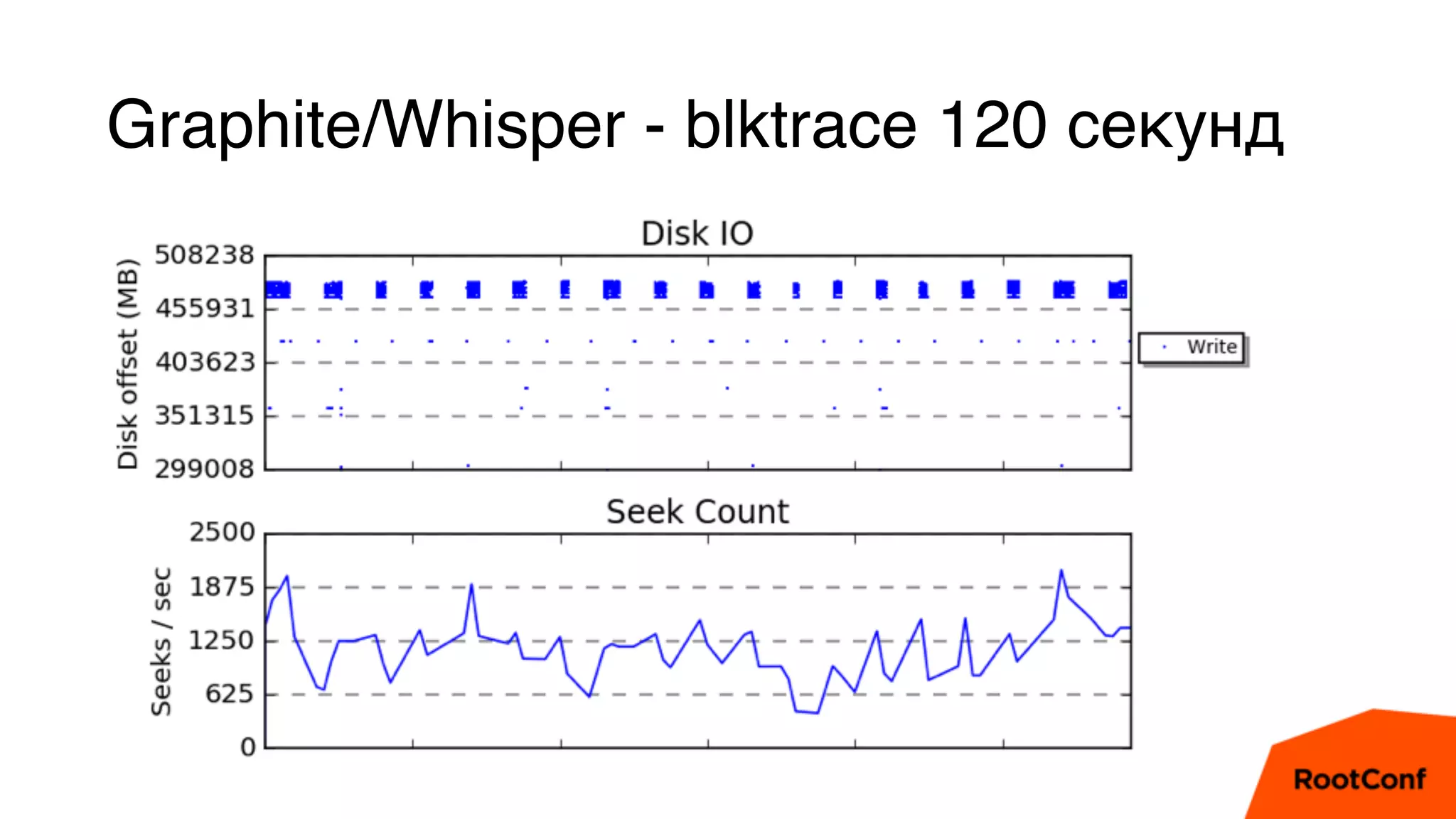
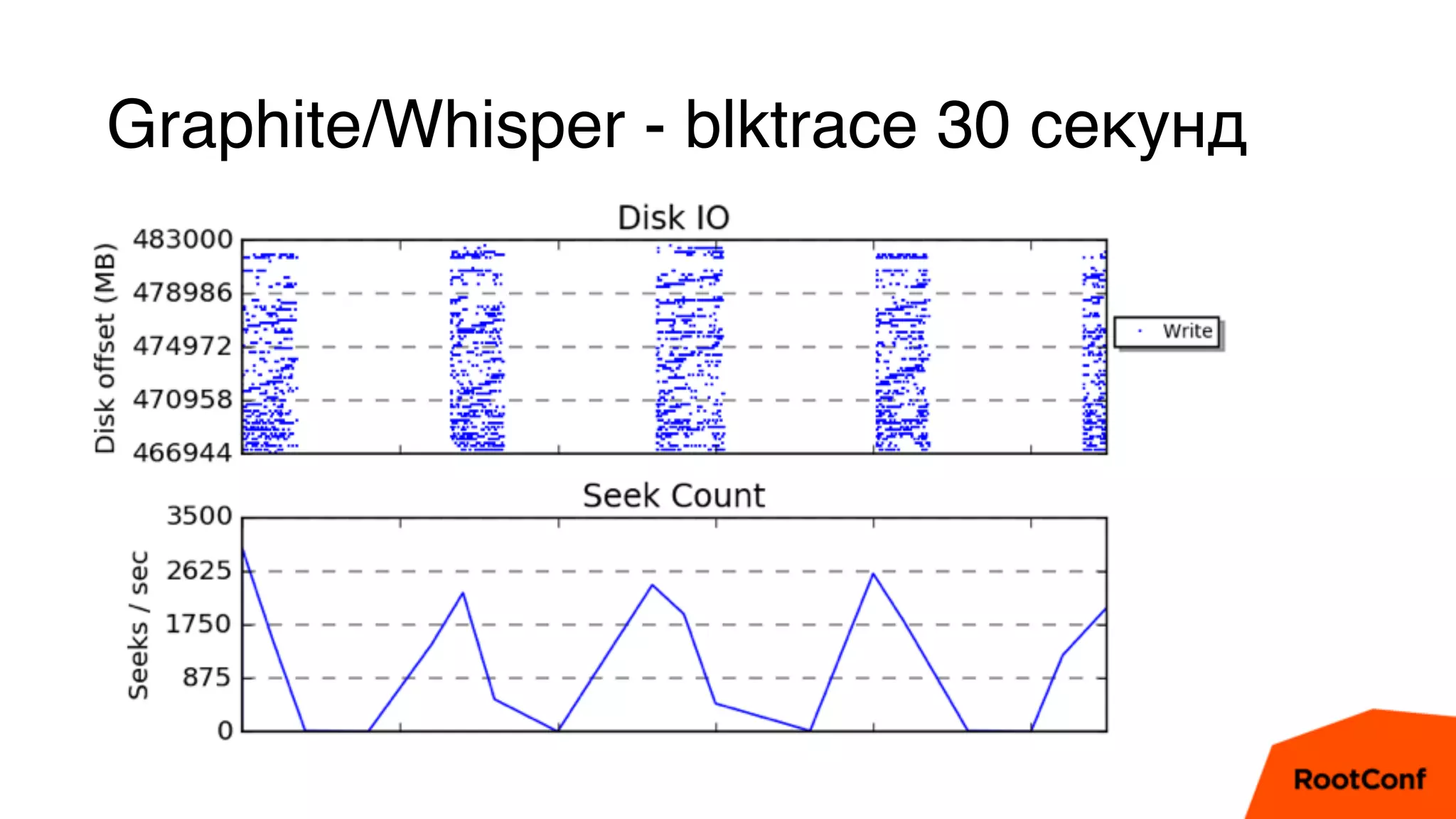










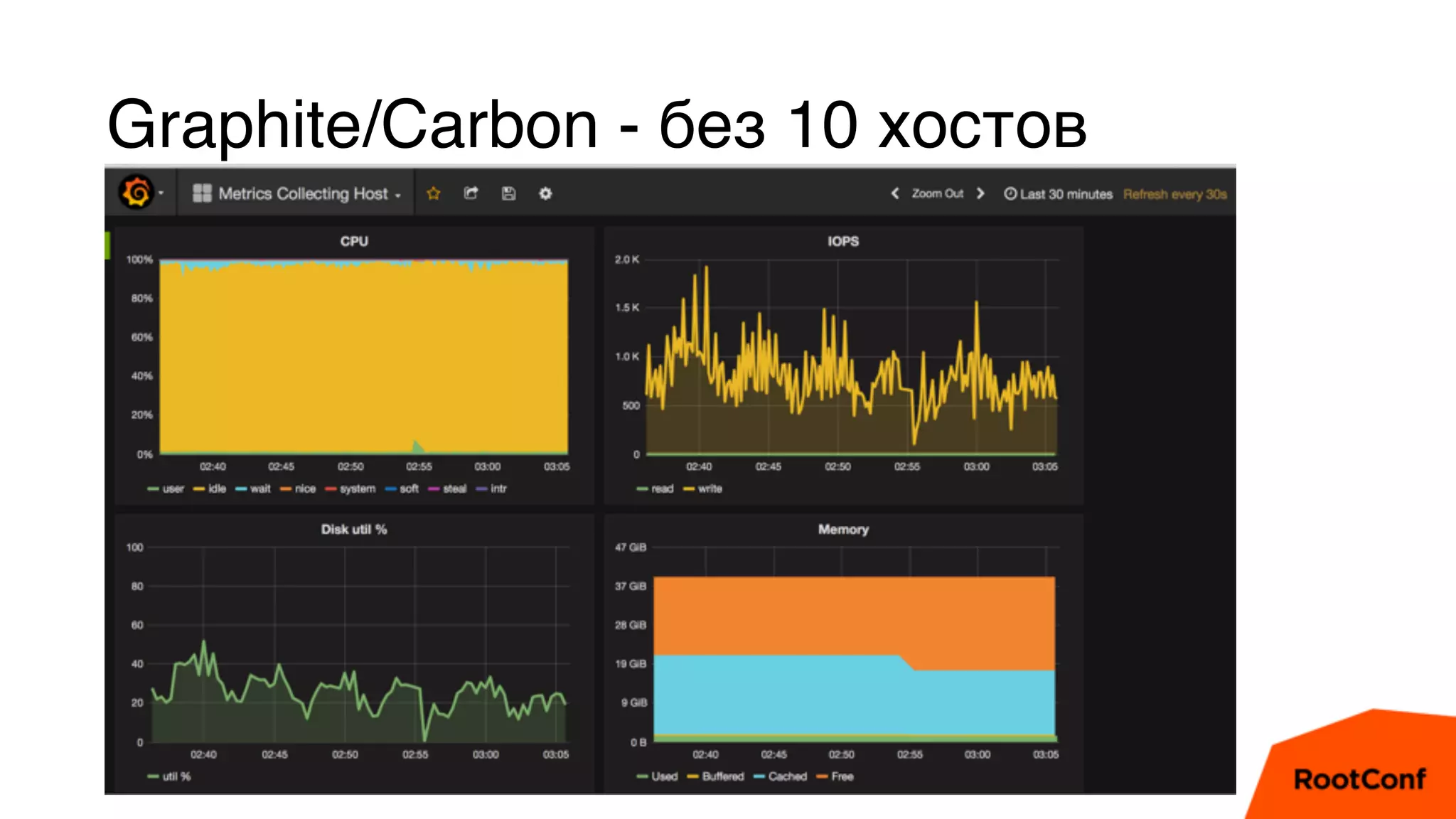


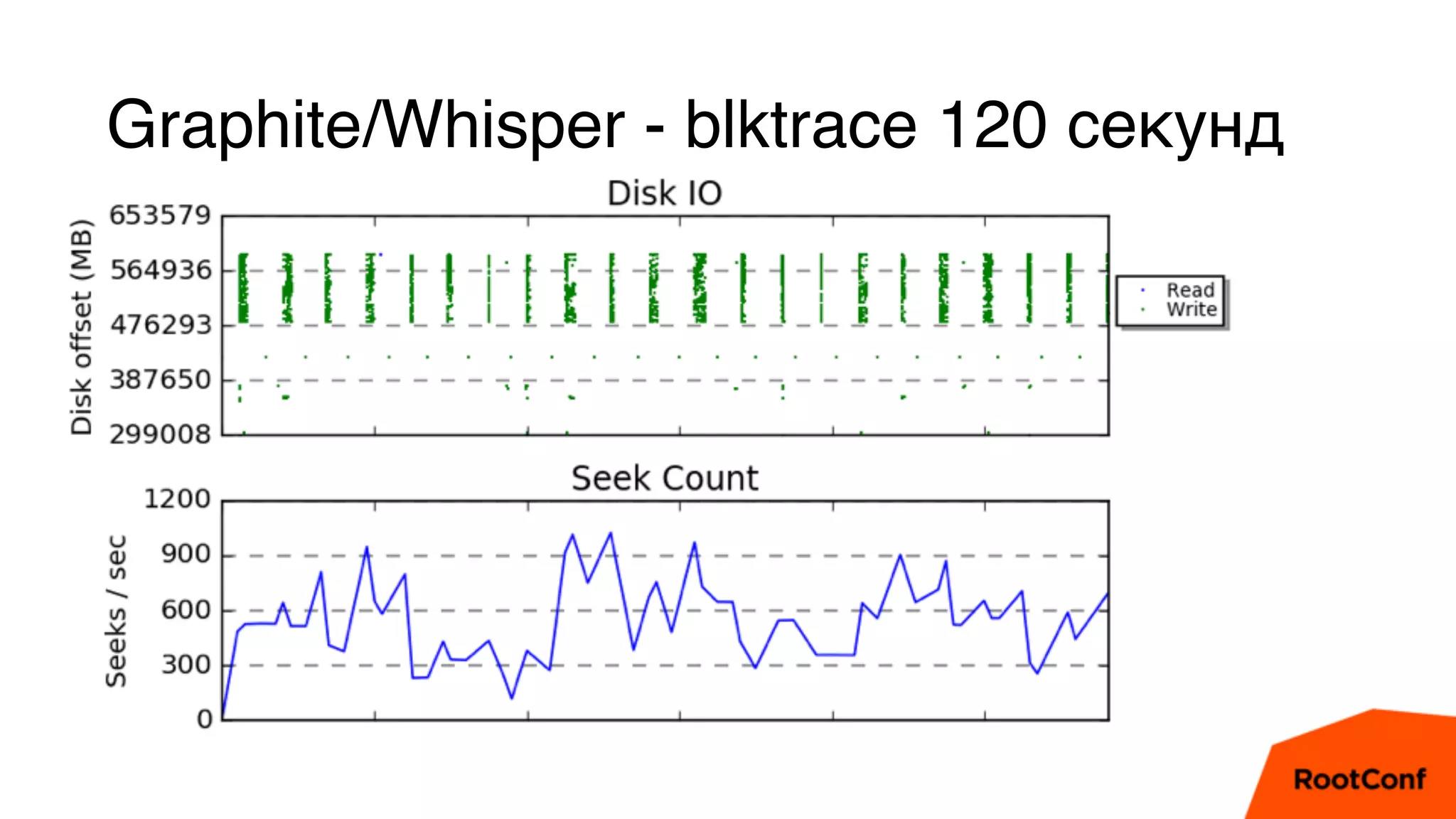
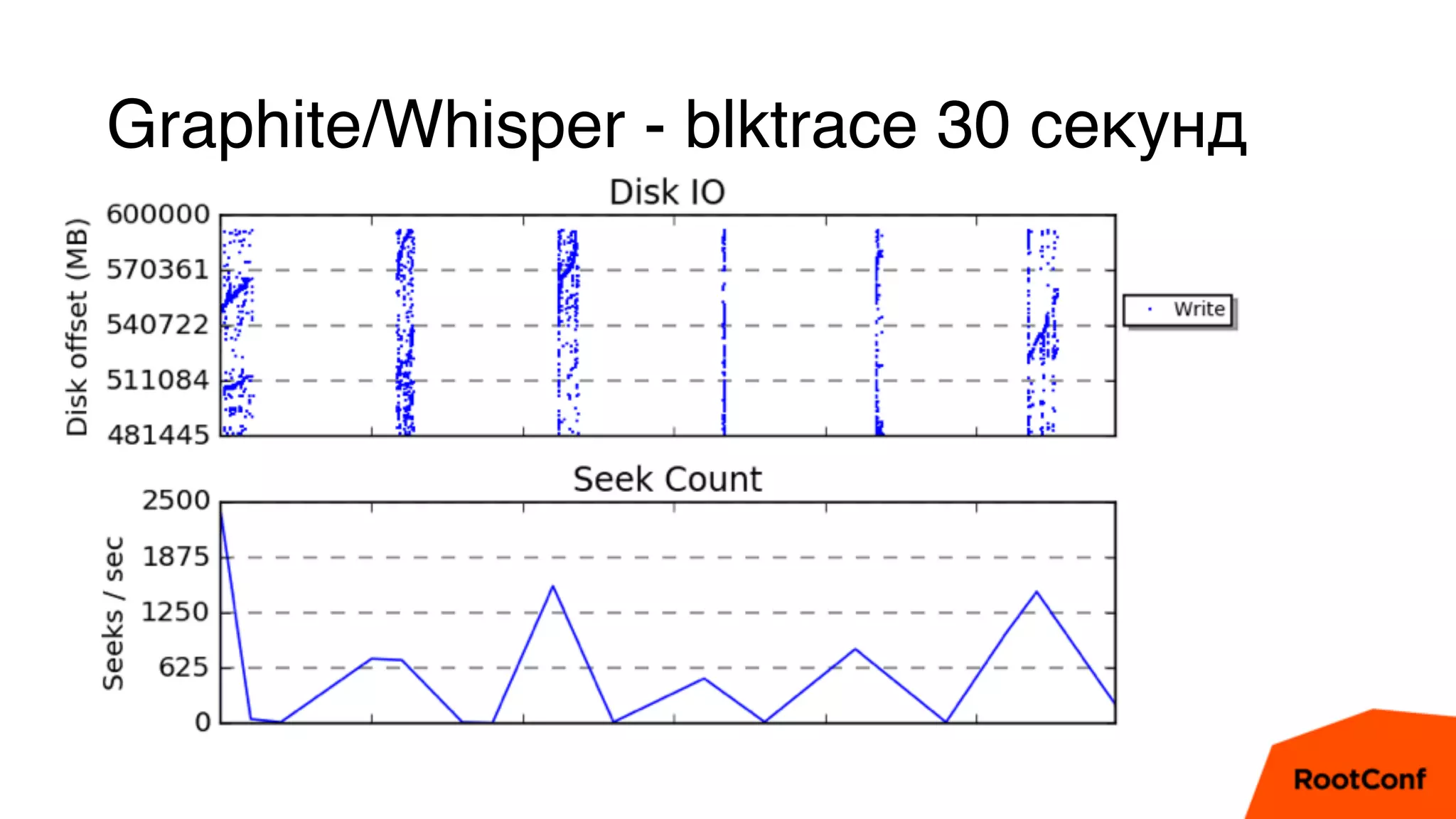
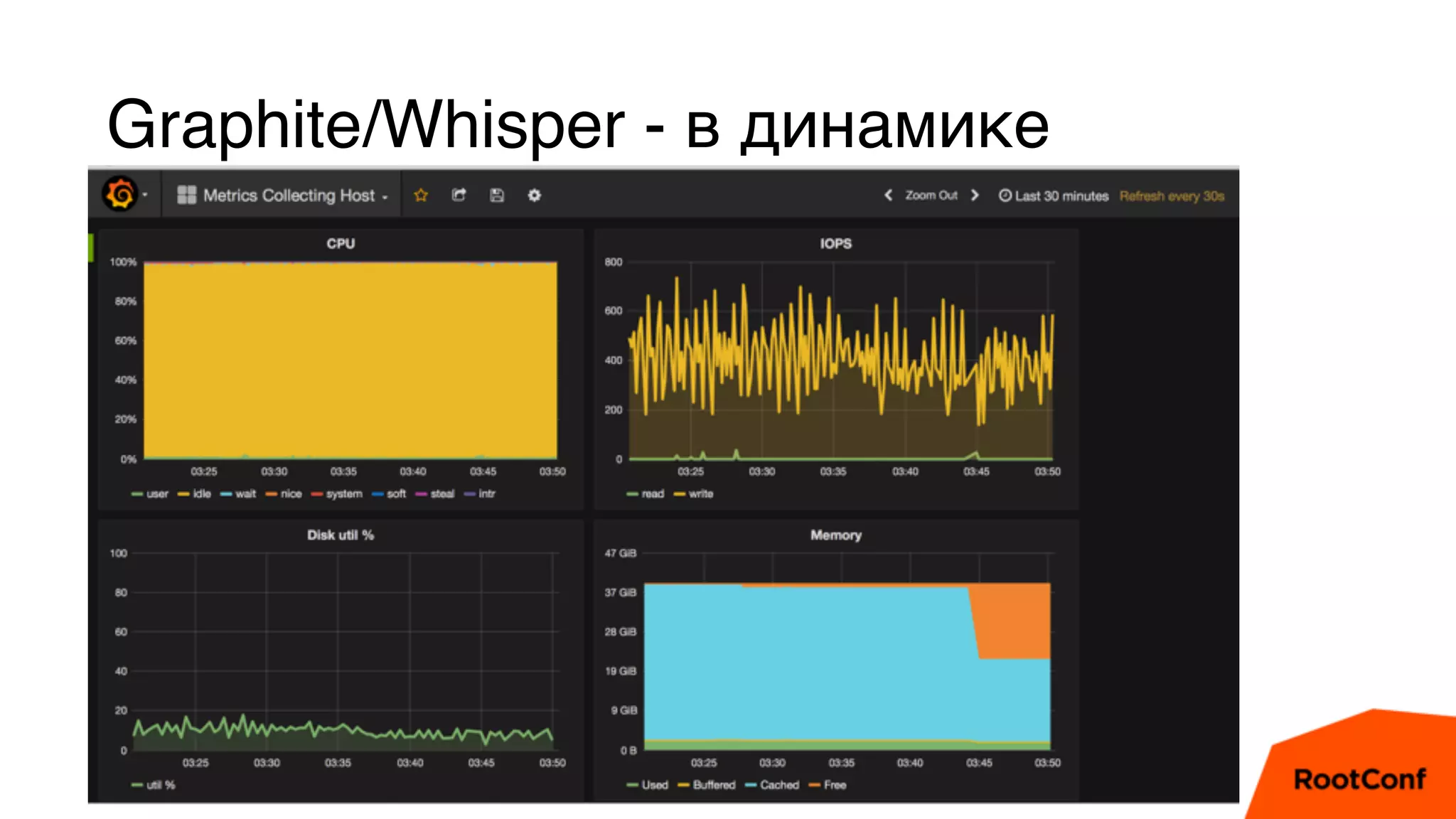



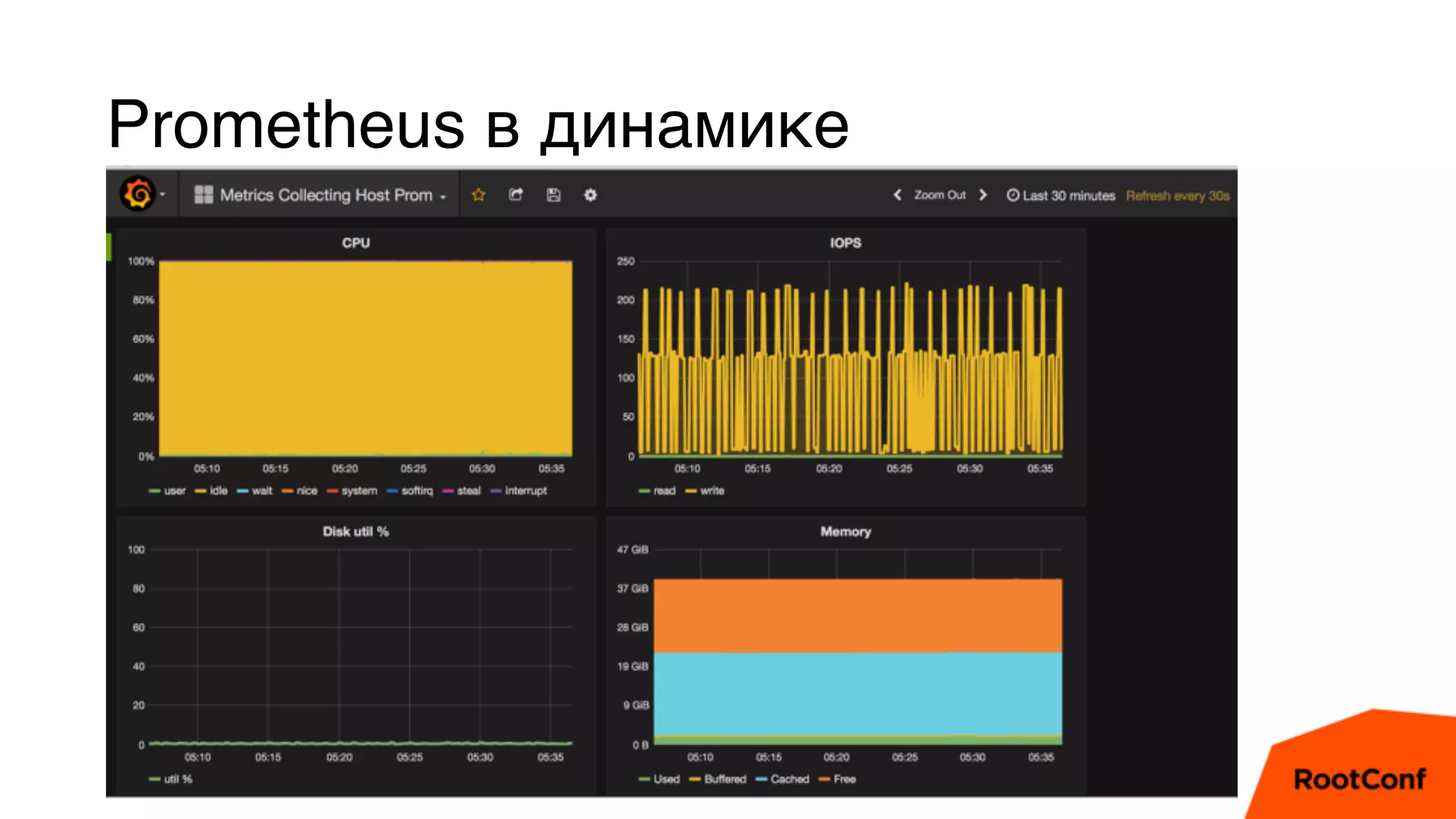
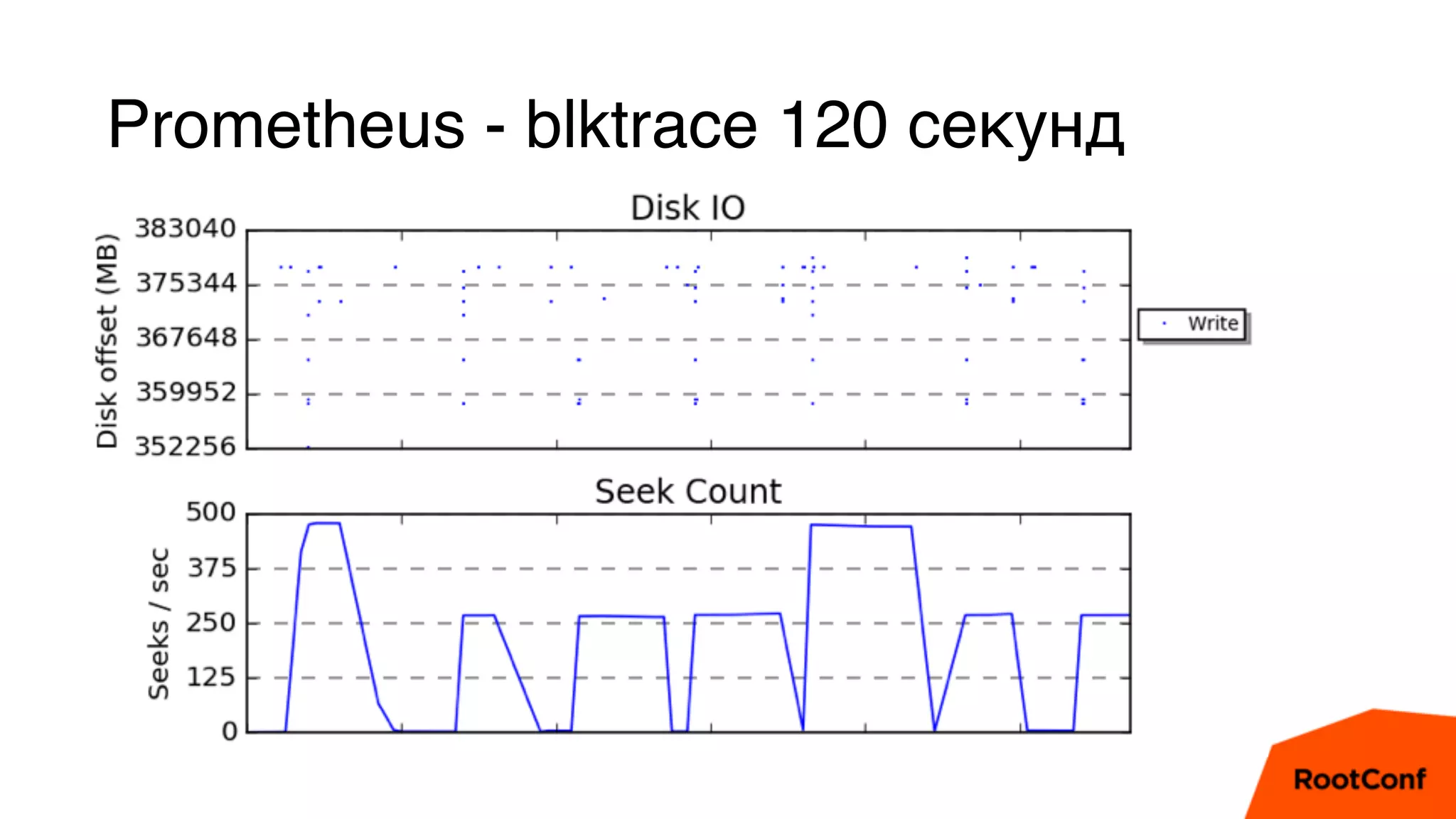
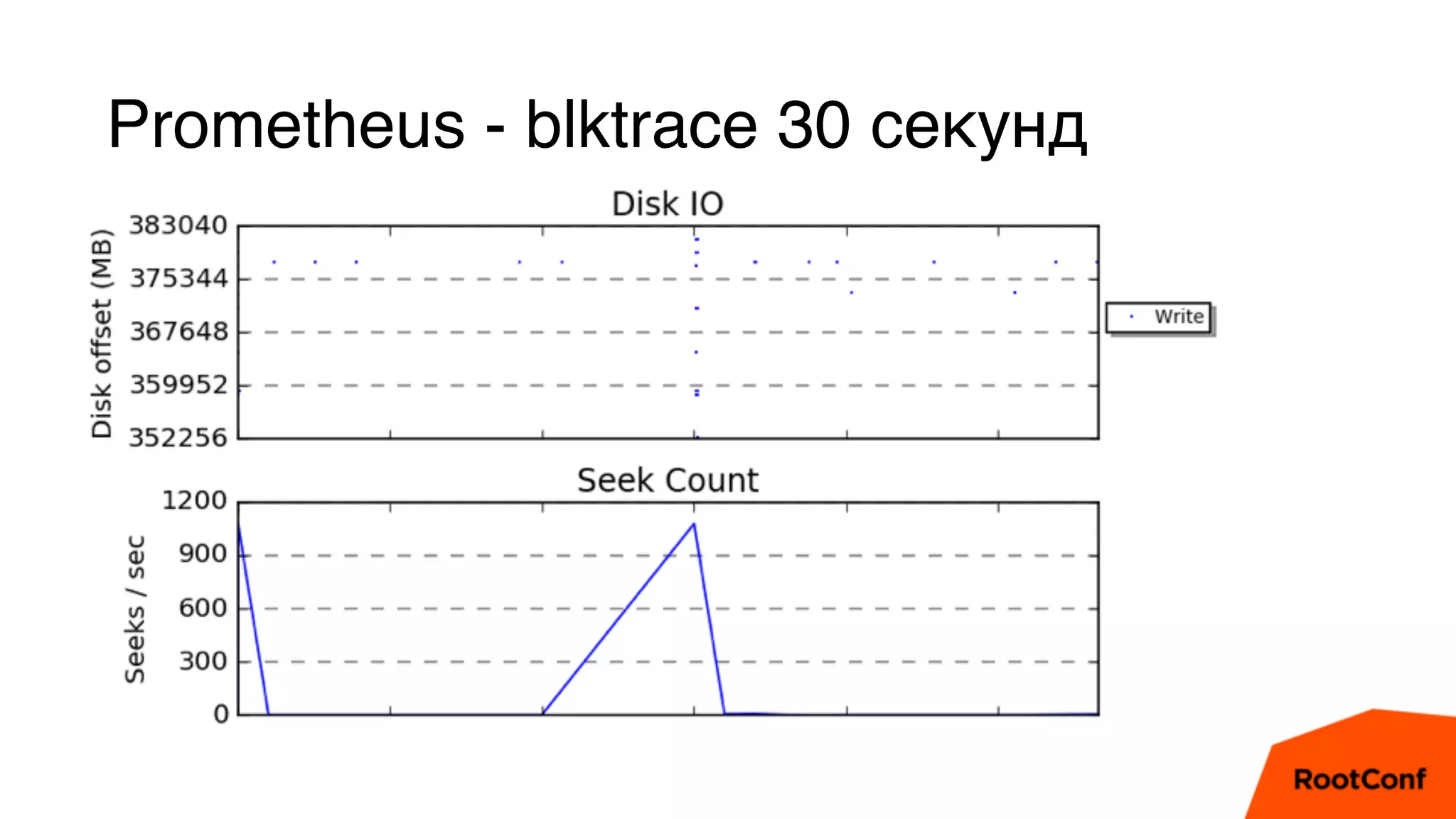



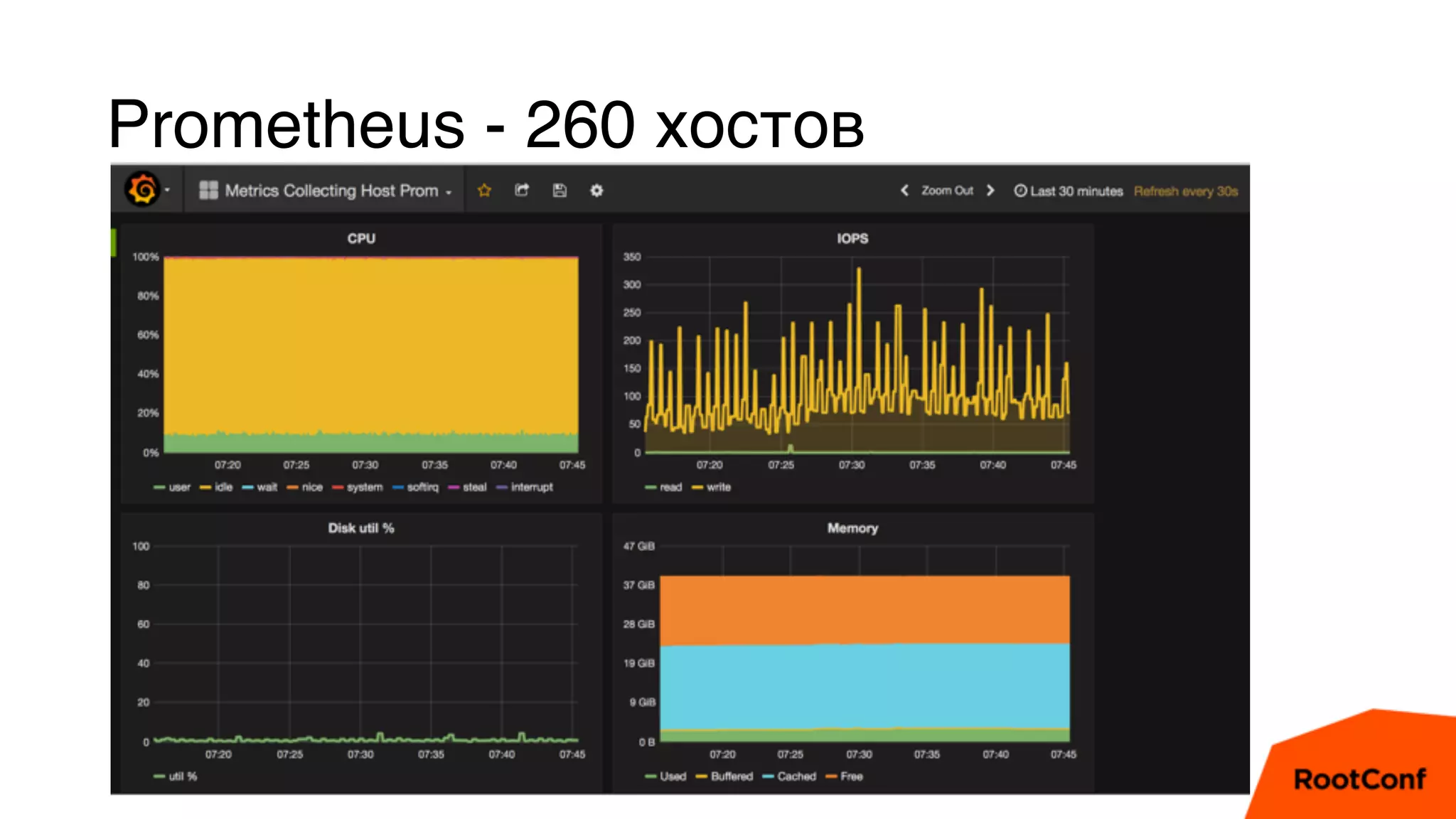
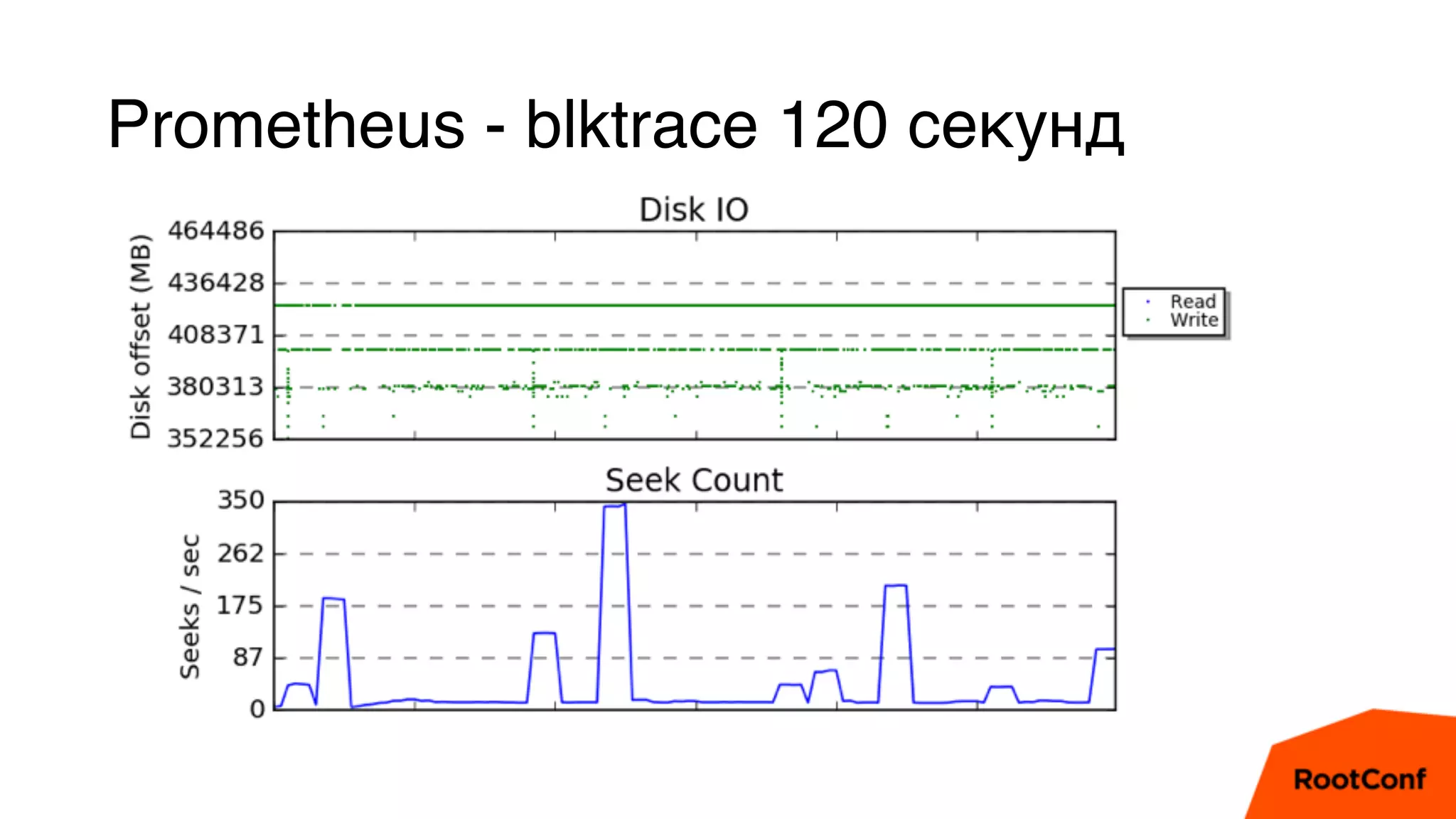










Документ является техноблогом о системах мониторинга, проведенном Александром Чистяковым, который делится своим опытом использования различных инструментов, таких как Zabbix, Prometheus и Graphite/Whisper. Сравнивая производительность этих систем, автор акцентирует внимание на преимуществах Prometheus и недостатках Zabbix, а также делится выводами о хранении метрик и их управлении. Основная цель — продемонстрировать эффективность современных систем мониторинга и их влияние на обработку метрик.













































































