목차
문자셋과 문자인코딩의 정의
ASCII란 ?
ISO/IEC 2022 (EUC 인코딩 ,CCS)
한글 인코딩
일본어 인코딩
중국어 인코딩
유니코드
파일시스템과 문자 인코딩
3.
문자셋과 문자인코딩의 정의
문자셋( Charset )
정보를 표현하기 위한 글자들의 집합
집합 안의 문자들에 음수가 아닌 정수들을 배정한 것을 부
호화된 문자 집합 (coded character set, CCS )
문자 집합은 ASCII 와 같이 더 이상의 문자가 추가될 수 없기도
하고 , 유니코드와 같이 문자가 계속 추가될 수 있기도 하다 .
문자인코딩 ( Character Encoding )
문자들의 집합을 컴퓨터에서 저장하거나 통신에 사용할 목적으로
부호화하는 방법
특정한 문자 집합 안의 문자들을 컴퓨터 시스템에서 사용할 목적
으로 일정한 범위 안의 정수 ( 코드값 ) 들로 변환하는 방법이다 .
4.
ASCII 란 ?
정의
미국정보 교환 표준 부호 (American Standard Code for Information
Interchange) – Coded Character Set
1967 년에 표준으로 제정되어 1986 년에 마지막으로 개정
국제표준
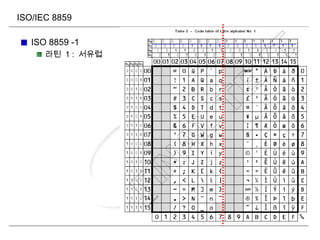
ISO 646 (7bit Encoding)
ASCII 를 따르며 영어 숫자의 위치는 동일하게 하고 각 국가별로 조금씩 특수
기호들을 변환
한국 : KSC5636(KS x 1003) “” -> “” (ISO646-KR)
ISO 8859 (8bit Encoding)
MSB bit0 = 표준 ASCII 코드와 동일
MSB bit1 = 각 나라별 필요코드 첨가
다양한 버전 (16 개 ) 이 존재
ex) ISO-8859 Part16(Latin10)- 동유럽국가
ISO/IEC 2022
ISO/IEC 2022규격 – 7bit, 8bit 두 종류로 구성
7bit 규격은 7~80 년대 Usenet, E-mail 교환을 위한 규격이다 . ( 자세한
설명 생략 )
관련 문자셋 (CJK 8bit, 2byte)
한국 : KSC-5601 ( 완성형 ), CP949 (CCS)
일본 : JIS x 0208, JIS x 0213 (CCS)
중국 : GB2312, GBK(CP939) (CCS)
관련 인코딩
한국 : EUC-KR (⊃ KSC5601, KSC5636[ASCII] )
일본 : EUC-JP
중국 : EUC-CN
7.
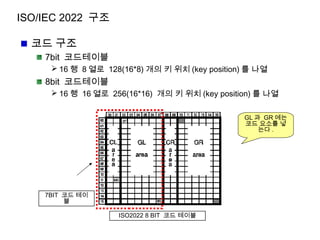
ISO/IEC 2022 구조
코드구조
7bit 코드테이블
16 행 8 열로 128(16*8) 개의 키 위치 (key position) 를 나열
8bit 코드테이블
16 행 16 열로 256(16*16) 개의 키 위치 (key position) 를 나열
7BIT 코드 테이
블
ISO2022 8 BIT 코드 테이블
GL 과 GR 에는
코드 요소를 넣
는다 .
8.
ISO/IEC 2022 구조
표기법
테이블위치 표시법 : xx/yy (xx = 열 , yy = 행 )
2 진법에서 xx 는 상위 4bit(8bit 기준 ), yy 는 하위 4bit
영역설명
테이블 위치와 비트조합
00, 01 열의 CL 영역 (Control Left) - 0x00-0x1f
02-07 열까지의 GL 영역 (Graphic Left) - 0x20-0x7f
08-09 열의 CR 영역 (Control Right) - 0x80-0x9f
10-15 열까지의 GR 영역 (Graphic Right) - 0xA0-0xff
특수문자 (7bit 와 8bit 에 모두 적용 )
01/11( 열 / 행 ) 에 ESCAPE ( 간단히 ESC 라고 표시 )
02/00 에 SPACE ( 간단히 SP 라고 표시 )
07/15 에 DELETE ( 간단히 DEL 이라고 표시 )
CL,CR 은 제어기능을 위한 영역
으로 Locking Shift( 한 / 영 키 )
와 같이 자판의 형태를 상호간에
맞추는 용도와 구조를 나타내는
데도 사용되어 진다 .
1Byte GL 영역 0x21 ~ 0x7E 영
역은 반드시 ASCII 코드가 고정
되어 있어야 함
2byte 의 경우는 자유
9.
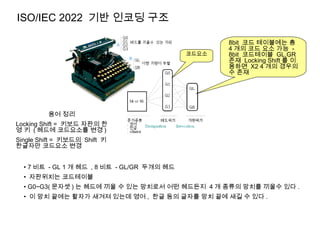
ISO/IEC 2022 기반인코딩 구조
용어 정리
Locking Shift = 키보드 자판의 한
영 키 ( 헤드에 코드요소를 변경 )
Single Shift = 키보드의 Shift 키
한글자만 코드요소 변경
8bit 코드 테이블에는 총
4 개의 코드 요소 가능 -
8bit 코드테이블 GL,GR
존재 Locking Shift 를 이
용하면 X2 4 개의 경우의
수 존재
코드요소
• 7 비트 - GL 1 개 헤드 , 8 비트 - GL/GR 두개의 헤드
• 자판위치는 코드테이블
• G0~G3( 문자셋 ) 는 헤드에 끼울 수 있는 망치로서 어떤 헤드든지 4 개 종류의 망치를 끼울수 있다 .
• 이 망치 끝에는 활자가 새겨져 있는데 영어 , 한글 등의 글자를 망치 끝에 새길 수 있다 .
10.
ISO/IEC 2022 기반인코딩 구조
Control Function
C0, C1 코드요소 (code elements) : CL(control left), CR(contron
right) 영역에 호출 (invocation)
7 비트의 경우
CL 영역만 존재 : C1 코드 요소 (code elements) 는 escape
sequence 를 통해 7 비트 코드로 표시
8 비트 코드의 경우
CASE 1: C0 는 CL ,C1 는 CR COC1 은 항상 CR 영역에 호출된
다 .
CASE 2: C1 코드 요소 (code elements) 는 escape sequence 를 통
해 7 비트 코드로 표시
기능
Gn 코드 요소를 호출하기 위한 locking shifts
전체 코드요소를 호출하지 않고 개별문자만 선택할 수 있는 single
shifts
코드구조 (code structure) 공표 (announcement) : C1 이 esc 에 의
해 코드화 되었는지 .
11.
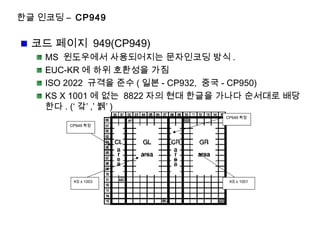
한글 인코딩 –문자셋 표준화 역사
연도 규격 번호 내용
1974 년 KSC 5601-1974 한글 자모 51 자에 코드 부여
1977 년 KSC 5714-1977 한자 7,200 자에 코드 부여
1982 년 KSC 5601-1982
KSC 5619-1982
2 바이트 조합형
완성형 ( 한글 1,316 자 , 한자 1,692 자 )
1987 년 KSC 5601-1987 완성형 ( 한글 2,350 자 , 한자 4,888 자 ), ISO 2022 규
격에 준함 )
1991 년 KSC 5601-1991 완성형 확장 글자 ( 한글 1,930 자 , 옛한글 1,673 자 ,
한자 2,865 자 )(KS C5601-1987 을 보충하기 위하여
추가로 수집한 글자들 )
1992 년 KSC 5601-1992 2 바이트 조합형을 완성형 한글과 함께 복수표준화
1995 년 KSC 5700-1995 완성형 한글 11,172 자 , 조합형 자모 334 자 및
23,274 자의 한자 ( 당시 유니코드 표준을 국가표준화한
것임 )
1998 년 ( 최종개정 ) 신규격번호 KS X 1001(KS C 5601-1987 완성형의 신
규격 )
2001 년 ( 최종개정 ) 신규격번호 KS X 1001(KS C 5657-1991 의 신규격 )
2002 년 ( 최종개정 ) KS X 1005-1 (KS C 5700-1995( 유니코드 )
의 신규격 )
• KSC 5601-1987, KSC 5601-1992 가 현재 공동 표준 , KS X 1005-1 은 ISO10646-1 에 등록된
유니코드 한글을 그대로 채용
12.
한글 인코딩 -KS x 1001 = KS C 5601-1987 (94x94 문자
셋 )
KSx1001 구조 (ISO2022 규격준수 )
ISO2022 8 비트 코드테이블의 GR 영역에 한
글 호출
2 Byte 구조 , 즉 코드 테이블이 2 개 (GR 영
역만으로 = 94X94 코드조합 가능 ( 총 8836
문자 지정 가능 )
고어나 방언은 제외 가나다 순으로 많이 쓰이
는 글자만 배열 ( 모든 한글 조합 불가 )
표현방식
First byte = 행 , Second byte = 열
First byte 는 왼쪽 GR 영역 , Second byte 는
오른쪽 GR 영역
Rows : 94 개의 Rows 가 존재 ,First byte 한
영역에 대해 94 개의 오른쪽 GR 영역을 통째
로 일컫는 말
A1 x 94 개의 오른쪽 GR 영역을 rows 1 이라
고 표현
94x94 문자셋 (GR 영역 )
Adobe Acrobat
Document
KSC 5601 Table
13.
한글 인코딩 -KS x 1001 = KS C 5601-1987 (94x94 문
자셋 )
각 행별 설명
Row 1: 94 개 symbols
Row 2: 69 개 abbreviations and symbols
Row 3: 94 full-width KS C 5636-1993 characters (ASCII)
……
Row 16-40: 2,350 완성형
Row 42-93: 4,888 한자
예제 )
첨부된 파일 KS C 5601 의 테이블에서 ‘가’를 보면
First Byte( 행 ) 0100001b
Second Byte( 열 ) 0110000b
KS C 5601 은 GRGR 조합의 8 비트 코드
GR 영역에 MSB = 1 -> First Byte= 10100001b Second Byte = 10110000b => 0xB0A1.
왜 테이블에는 7bit 로 표현되어 있는가 ?
ISO 2022 규격은 7bit 통신방식에서도 정의 되어있다 .
Escape Sequence, invocation….
현재로서는 많이 사용되지 않는다 . (E-mail, usenet)
자세한 사항은 문서 참조
14.
한글 인코딩 -KS x 1003 = KS C 5636 ( 문자셋 )
명칭
한국 산업규격 – 로마자 문자 집합
정식명칭 - 정보 교환용 부호 ( 로마 문자 )
ASCII 및 ISO/IEC 646 에 기반한 7 비트 문자 집합
ASCII 와의 차이점
역슬래쉬 (,0x5C) 자리에 원화 기호 (₩, U+20A9) 가 들어 있는
것 외에는 차이 없음 .
15.
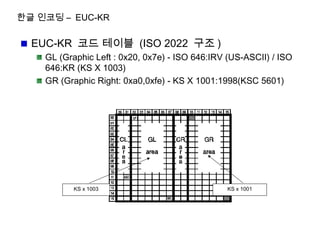
한글 인코딩 –EUC-KR
EUC-KR 코드 테이블 (ISO 2022 구조 )
GL (Graphic Left : 0x20, 0x7e) - ISO 646:IRV (US-ASCII) / ISO
646:KR (KS X 1003)
GR (Graphic Right: 0xa0,0xfe) - KS X 1001:1998(KSC 5601)
KS x 1003 KS x 1001
16.
KS x 1003KS x 1001
CP949 확장
CP949 확장
한글 인코딩 – CP949
코드 페이지 949(CP949)
MS 윈도우에서 사용되어지는 문자인코딩 방식 .
EUC-KR 에 하위 호환성을 가짐
ISO 2022 규격을 준수 ( 일본 - CP932, 중국 - CP950)
KS X 1001 에 없는 8822 자의 현대 한글을 가나다 순서대로 배당
한다 . (‘ 갘’ ,’ 뷁’ )
17.
일본어 인코딩
일본은 동아시아권나라 중 가장 먼저 자국 언어 정보처리
를 시작
대만 , 중국 , 한국 모두가 일본의 문자셋에 영향을 받음
부호의 배치 , 키릴 / 그리스 자모의 배치
일본 문자셋 표준 - JIS = Japanese Industrial Standard
18.
일본어 인코딩 -JIS X 0201
8bit 문자셋 (ISO 2022 문자셋 )
MSB 가 0 인 GL 영역 => ASCII
MSB 가 1 인 GR 영역 => 반각 카타가나
70 년대는 멀티바이트 문자셋 표준화가 되어있지 않음
GR 영역은 JIS x 0208 과 겹치므로 많이 사용되지 않음 .
SHIFT-JIS 와 같은 이상한 Encoding 을 만든 원인제공
19.
일본어 인코딩 -JISX 0208 (94x94 문자
셋 )
명칭
7 비트 및 8 비트의 2 바이트 정보 교환용 부호화 한자 집합 "( 일
본어 : 7 ビット及び 8 ビットの 2 バイト情報交換用符号化漢字集
合 )
옛명칭 : JIS C 6226
역사
1978 년 제정 -> 1997 년 개정
내용
히라가나 , 가타카나 , 한자 포함
일본에서 가장 널리 사용되는 문자셋
한중일 중 최초의 2 바이트 문자셋 -> 한 , 중에 많은 영향을 끼침
행 단위의 기호 , 특수문자 위치 동일
20.
일본어 인코딩 -JISX 0208 (94x94)
구조 (ISO 2022 8bit 규격 준수 )
ASCII 1 바이트 (GL = G0)
2 바이트 구조 , (GL 영역에 맵핑 [CCS] GL=G1) [Single shift]
GL 영역 각 행들 (= GL 영역의 첫째 바이트 x 94 문자 )
Row 1-8(0x21 ~ 0x28): 한자가 아닌 문자들 ( 문장 부호 , 그림 문
자 , 히라가나 , 가타카나 , 그리스 문자 , 키릴 문자 등 )
Row16-31(0x30 ~ 0x4F): 제 1 수준 한자 영역 ( 발음 순서대로 , 가
장 많이 사용되는 2965 자를 추림 )
Row32-68(0x50 ~ 0x74): 제 2 수준 한자 영역 ( 발음 순서대로 , 그
다음 많이 사용되는 3390 자를 추림 )
21.
일본어 인코딩 –JIS X 0212
JIS X 0212
94x94 문자셋 GL 영역
보조한자 5801 자를 할당
일반 PC 사용자는 사용 X
유닉스 유저 몇몇 학술 상용데이터 베이스에서 EUC-JP
를 통해 지원
22.
일본어 인코딩 –JIS X 0213 문자셋
JIS x 0208 의 확장판
정식명칭 : 정보교환을 위한 7bit,8bit 2 바이트 부호화 확장형 Kanji
문자셋 (Kanji = 일본에서 사용되는 한문 )
구조
2 Plane[2 개의 94x94 문자셋 ] (G0,G1 코드요소 ) – SHIFT LOCKING
필요
Plane 1 : JISx0208 (Kanji sets Level 1~3) 과 non-Kanji Character 총
8836 문자
Plane 2 : Kanji sets Level 4
총 문자수는 11,233 자
EUC-JIS-2004, ISO2022-2004, SHIFT-JIS-2004 에서 지원
23.
일본어 인코딩 –EUC-JP
인코딩 비트 : 8 bit
ISO/IEC 2022 규격 준수
구조
4 개의 문자셋 (Plane
G0,G1,G2,G3) 이용
CR 영역의 0x8e 와 0x8f 의
SS(Single-Shift) 코드 이용
1/2/3 바이트 가변폭 인코딩
화면 출력과 코드 너비가 다른
인코딩
CL(Control-Left): 0x00-0x1f
GL(Graphic-Left): 0x20-0x7f
CR(Control-Right): 0x80-0x9f
GR(Graphic-Right): 0xA0-0xff
문자셋 코드 설명
ASCII [0x20-0x7f] 아스키는 항상 GL 에 배치됩니다 .
JIS X 0201 0x8e [0xa1-0xdf] JIS X 0201 중 반각 카타카나 부분은 앞
에 0x8e 를 쓴 다음에 씁니다 .
(GR)
JIS X 0208 [0xa1-0xfe] [0xa1-0xfe] JIS X 0208 문자들은 각각 MSB 를 세
팅해서 그냥 씁니다 . (GR)
JIS X 0212 0x8f [0xa1-0xfe] [0xa1-0xfe] JIS X 02012 문자들은 0x8f 를 앞에 쓴
다음에 MSB 를 세팅해서 씁니다 .
(GR)
24.
일본어 인코딩 –SHIFT-JIS
탄생배경
1980 년대 JIS X 0201(GL ASCII GR 가타카나 할당 [CCS]).
한문 표시 하드웨어의 등장 . 그에 걸맞는 인코딩의 필요성 도래
인코딩 구조
ISO 2022 확장 방법으로는 하위호환성을 유지하면 JIS X 0208
을 지원 불가
JIS X 0201 에서 사용하고 있지 않던 영역 (0x81~0x9F[CR],
0xE0~0xEF[GR] ) 에 JIS X 0208 을 별도의 계산 과정으로 할당 .
(Seconde Byte 는 GL 영역도 사용 )
Shift_JIS 0xF0 ~ 0xFF(GR) 까지의 첫 바이트에는 아무 글자도 할
당되어 있지 않음 -> 추가를 통해 CP932 탄생
De Facto standard
25.
일본어 인코딩 –SHIFT-JIS
인코딩 방법
JIS x 0213 은 그대로 사용
JIS x 0208 의 경우
2Byte 의 JIS 문자코드 j1,j2 로부터 Shift_JIS byte s1s2 를 변환하
는 과정은 아래 식 과 같습니다 .
26.
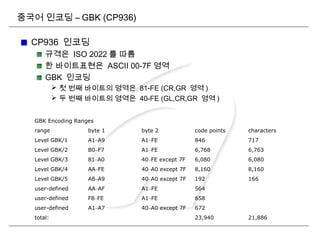
중국어 인코딩 –GB2312 (94x94 문자셋 )
Guojia Biaozhun 2312
1980 년 제정된 간체 국가표준 (ISO 2022 규격 )
GBK,GB18030 이 제정되었지만 현재도 널리 사용
6763 개의 한자와 기호 , 히라가나 , 카타카나 , Pinyin( 병음입력
- 알파벳 ) 등을 포함해서 모두 7445 글자로 구성
동일한 구조의 번체표준 GB/T12345 ([ 예 ] 코드포인트 39-7A
GB2312 => 囯 , GB/T12345 => 國 )
99.75% 의 실용한문의 입력을 커버
27.
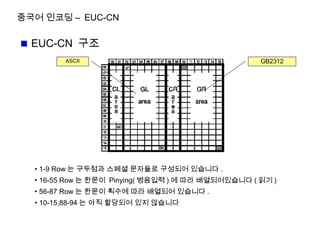
중국어 인코딩 –EUC-CN
EUC-CN 구조
GB2312ASCII
• 1-9 Row 는 구두점과 스페셜 문자들로 구성되어 있습니다 .
• 16-55 Row 는 한문이 Pinying( 병음입력 ) 에 따라 배열되어있습니다 ( 읽기 )
• 56-87 Row 는 한문이 획수에 따라 배열되어 있습니다 .
• 10-15,88-94 는 아직 할당되어 있지 않습니다
28.
중국어 인코딩 -기타문자셋
GB7589
보조문자셋 GB2 라고도 불림
모두 7237 자의 한자 포함
유니코드에 포함됨
번체 GB/T13131
GB7590
보조 문자셋 , GB4 라고도 불림
모두 7039 자의 한자가 포함
유니코드에 포함됨
GB/T13132 입니다 .
29.
중국어 인코딩 –GBK (CP936)
생성 유래
GB2312 의 확장판 . GBK 에 ‘ K’ 는 Extenstion 을 의미
Unicode 2.1 에 한중일 , 대만에서 사용되는 20,902 문자를 포함
하게 되었고 이에 따라 중국은 GB13000.1-93 를 제정하였다
( 유니코드의 중국어판과 동일 )
구조
GB13000.1-93 을 GB2312 에서 사용하지 않는 코드 포인트에 넣
음으로 GB2312 에 대한 상위호환성을 유지
국제표준은 아니나 Win95 에서 CP936 으로 널리 사용되면서
De facto Standard
30.
중국어 인코딩 –GBK (CP936)
CP936 인코딩
규격은 ISO 2022 를 따름
한 바이트표현은 ASCII 00-7F 영역
GBK 인코딩
첫 번째 바이트의 영역은 81-FE (CR,GR 영역 )
두 번째 바이트의 영역은 40-FE (GL,CR,GR 영역 )
GBK Encoding Ranges
range byte 1 byte 2 code points characters
Level GBK/1 A1–A9 A1–FE 846 717
Level GBK/2 B0–F7 A1–FE 6,768 6,763
Level GBK/3 81–A0 40–FE except 7F 6,080 6,080
Level GBK/4 AA–FE 40–A0 except 7F 8,160 8,160
Level GBK/5 A8–A9 40–A0 except 7F 192 166
user-defined AA–AF A1–FE 564
user-defined F8–FE A1–FE 658
user-defined A1–A7 40–A0 except 7F 672
total: 23,940 21,886
31.
중국어 인코딩 –GB18030
GB2312,GBK 를 대체하기 위한 중국의 공식 문자셋
강제적으로 표준으로 정함
중국 내 모든 OS 는 모두 지원
구성
GBK,GB2312 와의 완벽한 하위 호환성 유지 ,
가변길이 인코딩
GBK 에 추가적으로 유니코드를 순서대로 정렬 추가
110 만 개의 모든 유니코드 (0~16Plane) 에 대해 변환 가능
구조
Single-byte: 00-80 (*) (ASCII+ 유로기호 )
Two-byte: 81-fe | 40-7e, 80-fe (GBK)
Four-byte: 81-fe | 30-39 | 81-fe | 30-39 (GB13000.1)
4 바이트일 경우 1,587,600 (126*10*126*10) 개의 문자를 맵핑 가능 ( 유니코
드 1,112,046 자 )
32.
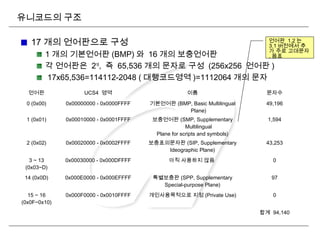
유니코드
목적
현존하는 문자 인코딩방법들을 모두 유니코드로 교체
기존의 인코딩들은 그 규모나 범위 면에서 한정 , 다국어 환경에서는 서로 호
환되지 않는 문제점
다양한 문자 집합들을 통합 운영체제 , 최신 소프웨어 기술에 다국어 환경에서
호환 가능하도록 한다 .
역사
유니코드 컨소시엄에서는 유니코드 표준과 ISO/IEC 10646 을 발전시키
기 위해 ISO 와 공동 작업
ISO/IEC 10646-1:1993 ≈ Unicode 1.1
ISO/IEC 10646-1:2000 ≈ Unicode 3.0
ISO/IEC 10646-2:2001 ≈ Unicode 3.2
ISO/IEC 10646-3:2003 ≈ Unicode 4.0
ISO 10646 과 Unicode 의 대응관계
33.
ISO10646 구조 (≈유니코드 )
기본언어판 , BMP
BMP 는 Basic Mulitilingual Plane 의 약자입니다 . 유니코드의 첫
65,536 개의 코드를 의미합니다 .
언어판 , Plane
256x256 즉 65,536 개씩의 코드 묶음을 이릅니다 . 유니코드에서는 현
재 17 개의 언어판을 사용할 수 있습니다 . 모두 그룹 00 에 포함됩니다
.
언어판 그룹 , Group
1 언어판 그룹 256 Plane
유니코드의 17 개 언어판은 Group 00 포함
유니코드는 17 개의 언어판에 한정
ISO 10646 표준 (UCS-4) 에서는 모두 128 개의 언어판 그룹이 정의
1 Plane = 65,536 code points
1 Group = 256 planes = 256x65,536 = 16,777,216 code points
UCS-4 = 128 groups = 128x16,777,216 = 2,147,483,648 code points
34.
유니코드의 구조
17 개의언어판으로 구성
1 개의 기본언어판 (BMP) 와 16 개의 보충언어판
각 언어판은 216
, 즉 65,536 개의 문자로 구성 (256x256 언어판 )
17x65,536=114112-2048 ( 대행코드영역 )=1112064 개의 문자
언어판 UCS4 영역 이름 문자수
0 (0x00) 0x00000000 - 0x0000FFFF 기본언어판 (BMP, Basic Multilingual
Plane)
49,196
1 (0x01) 0x00010000 - 0x0001FFFF 보충언어판 (SMP, Supplementary
Multilingual
Plane for scripts and symbols)
1,594
2 (0x02) 0x00020000 - 0x0002FFFF 보충표의문자판 (SIP, Supplementary
Ideographic Plane)
43,253
3 ~ 13
(0x03~D)
0x00030000 - 0x000DFFFF 아직 사용하지 않음 0
14 (0x0D) 0x000E0000 - 0x000EFFFF 특별보충판 (SPP, Supplementary
Special-purpose Plane)
97
15 ~ 16
(0x0F~0x10)
0x000F0000 - 0x0010FFFF 개인사용목적으로 지정 (Private Use) 0
합계 94,140
언어판 1,2 는
3.1 버전에서 추
가 주로 고대문자
, 음표
35.
ISO10646 (≈ 유니코드) 인코딩
UCS-2: Universal Character Set 2
Universal Multipe-Octet Coded Character Set 2
ISO10646 의 규격
오직 BMP 의 65,536 코드만을 정의 , 2 바이트로 표현
유니코드를 순서대로 표현 . 2byte=[65536]
UCS-4: Universal Character Set 4
Universal Multipe-Octet Coded Character Set 4
ISO10646 의 규격
128 개의 언어판 그룹 ( 언어판 그룹 =256 언어판 )
128*(256 언어판 ) = 32,768 언어판을 정의
대략 231
= 2,147,483,648 문자 표현
유니코드 전체를 포괄 .
36.
ISO10646 (≈ 유니코드) 인코딩 – UTF-8
배경
완벽한 유니코드 인코딩은 UTF-16
이 인코딩은 16 비트 단위로 하나의 문자를 표현
UTF-16 을 기존의 Char 형에서 문자열로 취급할 때 중간에
(NULL,0) 이 있을 수 있다 . ( 문자열의 끝을 알려 버리는 문제 발생 )
대안으로 문자열 중간에 Null 이 나오지 않도록 고안
구조
유니코드 문자는 1 바이트에서 4 바이트까지 가변적으로 인코딩
BMP 에 위치한 문자는 1~3 바이트로 인코딩
나머지 16 개의 보충언어판에 위치한 문자는 4 바이트로 인코딩
ISO10646 (≈ 유니코드) 인코딩 – UTF-16
특징
유니코드 영역만을 이용한 인코딩
가변 인코딩 : BMP= 2byte 표현 , 보충언어판 =4byte 표현
0~16 개의 모든 유니코드 언어판을 표현 가능
대행문자 영역 2,048 개를 제외한 63,488 개의 코드 표현 (BMP –
0Plane)
대행문자 영역 2 개의 쌍을 이용하여 16 개의 보충언어판 표현 가능
( 즉 17 개의 모든 유니코드 언어판을 표현 가능 )
높은 코드 효율로 유니코드 표준에서 지원하는 17 개의 언어판에
대해서만 인코딩 가능
39.
ISO10646 (≈ 유니코드) 인코딩 – UTF-16
기본언어판 (BMP) 2byte 로 표현
대행코드 조합으로 UTF-16 코드값 생성 공식 (4byte)
CodeValue = (HighSurrogate - 0xD800) x
(LowSurrogate - 0xDC00) + 0x10000
CodeValue 는 UTF-32 코드값
상위대행코드 영역의 시작점 : 0xD800
하위대행코드 영역의 시작점 : 0xDC00
보충언어판은 0x10000 부터 시작 (+0x10000 의 이유 )
CodeValue 는 U+10000 ~ U+10FFFF 까지 1048576 개의 값을 가
질 수 있게 됩니다 .
상위대행코드가 나오면 반드시 하위대행코드가 연달아 기술되어야
합니다 . (2byte(BMP 영역 ), 4byte( 보충언어판영역 ) 을 구분 가능 )
40.
ISO10646 (≈ 유니코드) 인코딩 – UTF-32
UTF-32 는 32 비트 (4byte) 로 모든 유니코드 문자를 표현
고정길이 인코딩 4byte
UCS-4 차이점 !
17 개의 언어판만을 대상으로 하는 UCS-4 의 부분집합
인코딩 영역
0x00000000 ~ 0x0010FFFF ( 영역만으로 제한 )
제한을 풀면 UCS-4 와 동일
41.
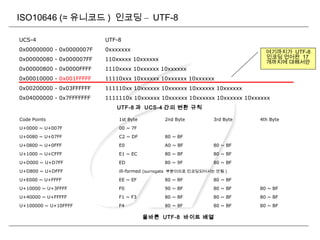
ISO10646 (≈ 유니코드) 인코딩 정리
인코딩 그룹 언어판 문자수 ( 표준 ) 문자수 ( 이론적 )
UCS-2 0 0(BMP) 216
=65,536 216
=65,536
UCS-4 0 ~ 127 0 ~ 32,767 231
=2,147,483,648 231
=2,147,483,648
UTF-8 0 0 ~ 16 17*216
-211
=1,112,064 231
=2,147,483,648
UTF-16 0 0 ~ 16 17*216
-211
=1,112,064 17*216
-211
=1,112,064
UTF-32 0 0 ~ 16 17*216
-211
=1,112,064 231
=2,147,483,648
각 인코딩별 표현 가능한 문자 수
42.
인코딩 SUMMARY
ASCII
National Variantof ISO 646
National Variant of ISO 8859
ISO/IEC 2022
ISO 2022 구조
한국 KSC5601,CP949, EUC-KR
중국 GB2312, GBK
일본 JIS x0201,JIS x 0208 ,JISx0212, Shift-JIS, EUC-JP
UNICODE ≈ ISO10646
인코딩 방식
UTF-16, UTF-8, UTF-32, UCS-2, UCS-4 의 차이점 .
43.
Application 별 인코딩
CDJoliet 파일시스템 = UCS-2
MP3 ID3 V2 Tag = UTF-8
OS File System
FAT,NTFS - UTF-16
HFS+ (MAC OS:Hierarchical File System) – UTF 8
Ext3(Linux) - UTF, EUC 중 선택가능
44.
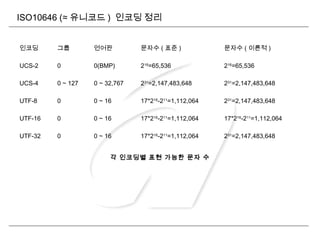
LCD 비트맵 폰트출력과정 – EUC KR
GL : ASCII
GR : KSC 5601
Bitmap Array Order 0 1 2 3 4
KSC5601 Code(2byte) 0xA1A2 0xA1A3 0xA1A4 0xA1A5 0xA1A6
KSC5601 폰트 (16x16)
、 。 · ‥ …
KSC 5601 폰트의 경
우 KSC 5601 코드순
서대로 정렬되어 있으
므로 맵핑테이블 필
요 없이 OFFSET
만 정하면 된다 .
파일시스템
EUC-KR 인코딩
KSC 5601 to KSC
5601 비트맵 폰트
맵핑 (16x16)
오프셋
폰트 출력
EUC-KR 폰트 출력
ASCII to ASCII
비트맵 폰트
맵핑 (8x16)
오프셋
45.
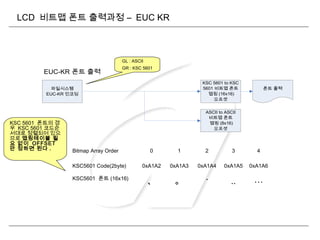
LCD 비트맵 폰트출력과정 – UTF-8
파일시스템
UTF-8 인코딩
Decode UNICODE
KSC5601코드 to
폰트 변환 맵핑
오프셋 설정
UNICODE to
KSC5601 맵핑
테이블
폰트 출력
파일시스템
UTF-8 인코딩
Decode UNICODE
UNICODE to 폰트
맵핑 오프셋
폰트 출력
UTF 8 폰트 출력
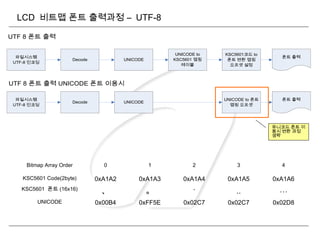
UTF 8 폰트 출력 UNICODE 폰트 이용시
Bitmap Array Order 0 1 2 3 4
KSC5601 Code(2byte) 0xA1A2 0xA1A3 0xA1A4 0xA1A5 0xA1A6
KSC5601 폰트 (16x16)
、 。 · ‥ …
UNICODE 0x00B4 0xFF5E 0x02C7 0x02C7 0x02D8
유니코드 폰트 이
용시 변환 과정
생략
#2 주로 쓰이는 한국어, 중국어 ,일본어 , 유니코드 문자셋 인코딩에 대해 설명드리겠습니다.
아시다시피 문자인코딩 자체만으로도 큰 하나의 학문이기 때문에 짧은 시간에 자세히 설명드리기는 힘들 것 같습니다.
PPT자료에서 짧게 설명된 부분은 별도로 만든 문서를 세미나 이후에 메일로 보내드리도록 하겠습니다.
오늘 주의 깊게 보셔야 할 부분은 ISO 2022의 구조! , 유니코드 인코딩간의 차이점!이 되겠습니다.
#4 부호화된 문자집합 때문에 문자인코딩과 문자셋이 계속 헷갈릴 수 있습니다. 부호화된 문자집합을 그대로 사용하여도 문자인코딩이 되기 때문.
UCS-2,ISO2022가 대표적인 예
CCS는 문자셋이면서 인코딩이기도 하다고 생각하시면 됩니다.
지금 부터 쭉 보시면서 어떤게 CCS인지 확인 하시면서 발표를 들으시면 좋을 것 같습니다.
#5 ASCII는 0x21부터 시작하지요? 왜 그럴까요? 뒤에 ISO 2022 규격에 대해 설명드릴텐데 GL 영역의 시작점을 한번 확인해보세요.
#7 매우 중요한 내용입니다 대부분의 문자셋이 ISO 2022의 규격을 따르고 있기 때문에 ISO2022 구조만 이해하시면 오늘 발표내용의 70%는 끝났다고 볼 수 있습니다.
나중에 KSC5601 설명드릴때 구조는 보다 정확히 아실 수 있습니다.
인코딩은 다른 문자셋도 포함이 가능하므로 포함관계는 EUC-KR이 크다고 볼수 있습니다.
앞으로 설명드릴 문자셋이랑 인코딩은 대부분 ISO2022와 ISO10646-1(유니코드) 규격을 참조하고 있다.
#9 좀 더 자세한 것은 다음 장에 한글 인코딩을 설명하면서 KSC5601에서 실제로 ISO2022구조를 확인 해보도록 하겠습니다.
1BYTE GL 영역 G0는 왜 반드시 ASCII 여야 하나? 왜? 각 문자셋들의 Escape Sequence G0 –G3까지의 문자맵핑 정의가 ASCII코드를 기준으로 하고 있기 때문.
#10 먼저 왜 코드요소는 4개인가?
8bit의 경우 자판이 두벌 GL과 GR이 있는데 여기에 Locking shift를 하면 4개의 코드요소가 생깁니다.
ISO2022에 맞는 인코딩을 만들려면 여러가지 문자셋을 G0부터 G3까지의 코드요소에 할당을 합니다. ( 이는 C0(CL)영역에 G0-G3까지의 영역에 맵핑된 문자를 정의합니다. ) 타자기로 치면 활자를 망치에 새기는 거죠 그리고 이 4가지 코드요소 코드테이블에 Escape Sequence(Locking shift)를 이용하여 GL영역과 GR영역에 맵핑하여 사용하게 됩니다.
ISO2022에서 G0 –G3 에 각각의 문자셋들이 들어갈때 표현하는 국제 표준을 만들었습니다.
#11 7bit의 경우 C0의 Locking Shift에 의해 G0,G1를 호출 가능 ESC를 이용 C1을 호출 C1의 Locking Shift에 의해 G2 G3 호출가능
8bit는 CL CR 이용
#33 차이점 존재 ! 유니코드는 17개의 언어판에 대해서만 지칭!
ISO10646은 256개의 언어판을 그룹이라하고 이 그룹이 128개 있음
#35 유니코드 표준 3.0에서는 49,194 문자가 정의되었고 이들은 모두 BMP에 한정되어 정의되었으나, 3.1에서는 BMP에 2개의 문자를 추가하고, 보충언어판에 44,944개의 문자를 추가하였습니다. 새로 추가된 문자들은 음표, 고대문자, 한자(CJK Ideographic Extension B) 등입니다.
제 15, 16 언어판에 대한 설명이 조금 필요할 듯 합니다. 이 두개의 언어판은 개인사용(Private Use)로 지정되었습니다. 개발자들에게는 일종의 보너스라고 말하는 사람들도 있군요. 어쨌던 이 두 언어판은 상위대행코드중 마지막 128개 코드와 하위대행코드의 조합으로 지정됩니다(UTF-16 인코딩의 경우). 이 때문인지 유니코드 3.1에서는BMP의 U+DB80 ~ U+DBFF 영역을 별도로 분리하여 High Private Use Surrogates라고 이름이 붙여졌습니다.





![ISO/IEC 2022
ISO/IEC 2022 규격 – 7bit, 8bit 두 종류로 구성
7bit 규격은 7~80 년대 Usenet, E-mail 교환을 위한 규격이다 . ( 자세한
설명 생략 )
관련 문자셋 (CJK 8bit, 2byte)
한국 : KSC-5601 ( 완성형 ), CP949 (CCS)
일본 : JIS x 0208, JIS x 0213 (CCS)
중국 : GB2312, GBK(CP939) (CCS)
관련 인코딩
한국 : EUC-KR (⊃ KSC5601, KSC5636[ASCII] )
일본 : EUC-JP
중국 : EUC-CN](https://image.slidesharecdn.com/random-150612135306-lva1-app6891/85/slide-6-320.jpg)









![일본어 인코딩 -JIS X 0208 (94x94)
구조 (ISO 2022 8bit 규격 준수 )
ASCII 1 바이트 (GL = G0)
2 바이트 구조 , (GL 영역에 맵핑 [CCS] GL=G1) [Single shift]
GL 영역 각 행들 (= GL 영역의 첫째 바이트 x 94 문자 )
Row 1-8(0x21 ~ 0x28): 한자가 아닌 문자들 ( 문장 부호 , 그림 문
자 , 히라가나 , 가타카나 , 그리스 문자 , 키릴 문자 등 )
Row16-31(0x30 ~ 0x4F): 제 1 수준 한자 영역 ( 발음 순서대로 , 가
장 많이 사용되는 2965 자를 추림 )
Row32-68(0x50 ~ 0x74): 제 2 수준 한자 영역 ( 발음 순서대로 , 그
다음 많이 사용되는 3390 자를 추림 )](https://image.slidesharecdn.com/random-150612135306-lva1-app6891/85/slide-20-320.jpg)

![일본어 인코딩 – JIS X 0213 문자셋
JIS x 0208 의 확장판
정식명칭 : 정보교환을 위한 7bit,8bit 2 바이트 부호화 확장형 Kanji
문자셋 (Kanji = 일본에서 사용되는 한문 )
구조
2 Plane[2 개의 94x94 문자셋 ] (G0,G1 코드요소 ) – SHIFT LOCKING
필요
Plane 1 : JISx0208 (Kanji sets Level 1~3) 과 non-Kanji Character 총
8836 문자
Plane 2 : Kanji sets Level 4
총 문자수는 11,233 자
EUC-JIS-2004, ISO2022-2004, SHIFT-JIS-2004 에서 지원](https://image.slidesharecdn.com/random-150612135306-lva1-app6891/85/slide-22-320.jpg)
![일본어 인코딩 – EUC-JP
인코딩 비트 : 8 bit
ISO/IEC 2022 규격 준수
구조
4 개의 문자셋 (Plane
G0,G1,G2,G3) 이용
CR 영역의 0x8e 와 0x8f 의
SS(Single-Shift) 코드 이용
1/2/3 바이트 가변폭 인코딩
화면 출력과 코드 너비가 다른
인코딩
CL(Control-Left): 0x00-0x1f
GL(Graphic-Left): 0x20-0x7f
CR(Control-Right): 0x80-0x9f
GR(Graphic-Right): 0xA0-0xff
문자셋 코드 설명
ASCII [0x20-0x7f] 아스키는 항상 GL 에 배치됩니다 .
JIS X 0201 0x8e [0xa1-0xdf] JIS X 0201 중 반각 카타카나 부분은 앞
에 0x8e 를 쓴 다음에 씁니다 .
(GR)
JIS X 0208 [0xa1-0xfe] [0xa1-0xfe] JIS X 0208 문자들은 각각 MSB 를 세
팅해서 그냥 씁니다 . (GR)
JIS X 0212 0x8f [0xa1-0xfe] [0xa1-0xfe] JIS X 02012 문자들은 0x8f 를 앞에 쓴
다음에 MSB 를 세팅해서 씁니다 .
(GR)](https://image.slidesharecdn.com/random-150612135306-lva1-app6891/85/slide-23-320.jpg)
![일본어 인코딩 – SHIFT-JIS
탄생배경
1980 년대 JIS X 0201(GL ASCII GR 가타카나 할당 [CCS]).
한문 표시 하드웨어의 등장 . 그에 걸맞는 인코딩의 필요성 도래
인코딩 구조
ISO 2022 확장 방법으로는 하위호환성을 유지하면 JIS X 0208
을 지원 불가
JIS X 0201 에서 사용하고 있지 않던 영역 (0x81~0x9F[CR],
0xE0~0xEF[GR] ) 에 JIS X 0208 을 별도의 계산 과정으로 할당 .
(Seconde Byte 는 GL 영역도 사용 )
Shift_JIS 0xF0 ~ 0xFF(GR) 까지의 첫 바이트에는 아무 글자도 할
당되어 있지 않음 -> 추가를 통해 CP932 탄생
De Facto standard](https://image.slidesharecdn.com/random-150612135306-lva1-app6891/85/slide-24-320.jpg)

![중국어 인코딩 – GB2312 (94x94 문자셋 )
Guojia Biaozhun 2312
1980 년 제정된 간체 국가표준 (ISO 2022 규격 )
GBK,GB18030 이 제정되었지만 현재도 널리 사용
6763 개의 한자와 기호 , 히라가나 , 카타카나 , Pinyin( 병음입력
- 알파벳 ) 등을 포함해서 모두 7445 글자로 구성
동일한 구조의 번체표준 GB/T12345 ([ 예 ] 코드포인트 39-7A
GB2312 => 囯 , GB/T12345 => 國 )
99.75% 의 실용한문의 입력을 커버](https://image.slidesharecdn.com/random-150612135306-lva1-app6891/85/slide-26-320.jpg)





![ISO10646 (≈ 유니코드 ) 인코딩
UCS-2: Universal Character Set 2
Universal Multipe-Octet Coded Character Set 2
ISO10646 의 규격
오직 BMP 의 65,536 코드만을 정의 , 2 바이트로 표현
유니코드를 순서대로 표현 . 2byte=[65536]
UCS-4: Universal Character Set 4
Universal Multipe-Octet Coded Character Set 4
ISO10646 의 규격
128 개의 언어판 그룹 ( 언어판 그룹 =256 언어판 )
128*(256 언어판 ) = 32,768 언어판을 정의
대략 231
= 2,147,483,648 문자 표현
유니코드 전체를 포괄 .](https://image.slidesharecdn.com/random-150612135306-lva1-app6891/85/slide-35-320.jpg)






















































![[Emocon 2017 S/S] 20170414 유니코드(Unicode)로 오픈소스에 기여하기](https://cdn.slidesharecdn.com/ss_thumbnails/20170414-170429081753-thumbnail.jpg?width=640&height=640&fit=bounds)