A CHARACTERSET
A CHARACTER ENCODING
A CHARACTER SET VS A CHARACTER ENCODING
4
A character set is a collection of letters and symbols used in a writing
system. For example, the ASCII character set covers letters and symbols for
English text (http://www.w3.org)
케릭터셋, 문자셋, 문자집합 으로 불림
A character encoding is the key that maps a particular byte or sequence
of bytes to particular characters that the font renders as text.
(http://www.w3.org)
문자 집합을 컴퓨터가 사용할 수 있도록 특정 바이트로 변환
5.
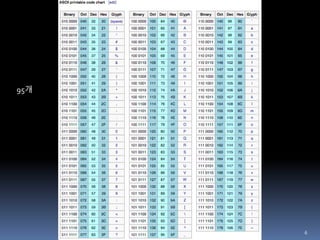
ASCII
디지털 장비들과의문자 전달, 처리, 저장 필요
American Standard Code For Information Interchange
알파벳 대소문자 95, 제어 문자 33 (총 128개 문자)
7 bit
US-ASCII, US7ASCII, IBM367, CP367, CSASCII로 불림
5
리눅스에서 작성하고 윈도우 에서 볼 경우
Control Character
9
윈도우 작성 하고 리눅스 에서 볼 경우
10.
Extended ASCII
8bit를사용한 여러 버전의 확장 ASCII 만들어냄
128까지는ASCII와 동일 하고 그 이후 128~255 나라에 맞
는 언어와 심볼 추가
ISO 8859 Series 표준 채택
그중에서 ISO 8859-1(또는 ISO Latin 1) 가 가장 많이 쓰임
MS 에서는 ISO 8859-1과 유사한Windows-1252 사용
128-159 제어 문자로 사용
아시아 문자 표현 불가능
10
한글 문자 집합과인코딩
영어, 유럽어는 알파벳을 기초로 사용하므
로 256개의 코드로 충분
중국, 일본, 한국( CJK Chinese-Japanese-
Korean)에서 사용하는 한자, 한글, 병음, 주
음 기호 확장 ASCII로 처리 불가능
한글 처리 하는 방법 조합형과 완성형
12
13.
한글 조합형/완성형
조합형
-초성, 중성, 종성을 조합하여 만드는 방법
- N 바이트 조합형
- 3바이트 조합형
- 2바이트 조합형
완성형
- 각각의 음절에 코드 부여
- 7바이트 완성형
- 2바이트 완성형
13
14.
조합형 : N바이트
각각의 개별적인 한글 자모를 영문자에 매칭
2바이트 에서 5바이트 사용
시작과 끝에 SI(Shift in) ^N, SO(Shift Out) ^O
삽입 하여 한글 인식
전영규 ^NXfDWjWAw^O
저ㄴ여ㅇㄱㅠ
14
15.
조합형 : 3바이트
한 글자의 길이가 가변적인 n바이트 단점을
보완하기 위해 탄생
항상 3바이트 유지
- 초성, 중성, 종성 각각 1바이트씩 할당
- 종성 없는 경우 ‘채움 글자’로 3바이트 유지
- ㅄ 과 같은 겹낱자도 1바이트 표현
2바이트 조합형이 나오면서 자취를 감춤
15
16.
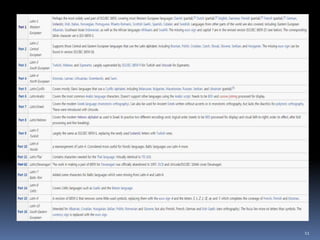
조합형 : 2바이트
초성, 중성, 종성에 각각 5 bit씩 할당
처음 1 bit는 1로 표시 하여 한글임을 표시
한국 IBM, 삼보, 금성 조합형, 삼성 조합형 업체들만의 조합형 만듦
으로써 호환 불가능
16
17.
완성형 : 7비트
청계천 주변 상가에서 만들어져서
“청계천 한글” 이라고 불림
일반적으로 조합에 한글 사용
- aB와 같이 로마자 소문자 뒤에
- }a와 같이 기호 뒤에 로마자가 오는 경우
dBase -> 늦 ASE 로 표기
17
18.
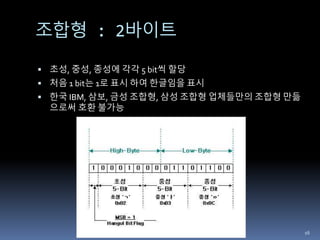
완성형 : 2바이트
각각의 음절에 2바이트씩 부여
KSC5601-1987(현재 KS X 1001)으로 채택
공식적으로 ISO/IEC 2022 의 호환성 위해
많은 상용 업체들의 조합형 선택에 형평성 문제가 있어 완성형을
선택 했다는 후문도 있음
18
KSC5601-1987(KSX 1001)
한국어문자 집합( euc-kr 은 인코딩)
현대 한글 11,172중
한글 2, 350자, 한자 4,888 표현 가능
한글 창제의 원리 초,중,종성 구별이 없어 단
순한 부호에 불과하다는 의견
20
21.
EUC-KR
EUC(Extended UnixCode)
벨 연구소에서 유닉스에서 영어를 제외한 문자
표시하기 위한 인코딩
EUC-CN, EUC-TW, EUC-JP
EUC-KR
- 한글 인코딩
- 영문 KSC5636 (KS X 1003) ( -> ₩)
- 한글 KSC5601-1987 (KS X 1001) 한글2,350자
21
한글 815
조합형을사용 하고 있던 아래아한글이
완성형을 사용 했던 MS 워드를 디스 했던 광고
MS 워드에서 ‘비행기가 날아간다 쓩~’ 를 표시
할수 없어 ‘비행기가 날아간다 ㅆ ㅠ ㅇ ~’로 표
시
MS 워드는 쓔 자가 없어 생긴 문제
한글 815
23
24.
확장 완성형 코드
MS가 독자적으로 제정한 인코딩
완성형에서 사용할 수 없었던 8,822자 추가 하면서 현대
한글 11,172 표현 가능
표준이 아님에도 불구하고 윈도우 95와 점유율과 함께 널
리 사용
MS949, CP949,Win949 라고도 표현
Outlook, IE, Frontpage 등에서는 MS949를 ks_c_5601-1987
로 표시 하기도 함
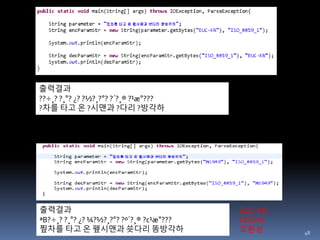
“똠방각하” 몇가지 문자 표현 가능
24
25.
유니코드 탄생 배경
한 시스템 또는 문서에서 여러 언어 섞어 쓰
기 불가능
언어가 틀린 두 지역간에 문서 교환 불가능
영어 résumés -> 히브리어 r ג sum ג s
25
26.
유니코드 시작
ISO에서 표준 ISO 10646 문자셋을 만들기 위해 시작
- 정식 이름은 UCS(UniversalCharacter Set)
Apple, Xerox, Sun, MS 등이 다국어 지원 위해 Unicode 컨소시엄 조
직
Unicode 컨소시엄이 ISO 에게 자신들의 표준 사용할 것을 제안 하
면서 1993년 ISO 10646-1 국제 표준 만들어짐
ISO와 Unicode 컨소시엄은 각자 목적이 달라 각자 나름대로의 버
전을 발전 시키고 있음
26
27.
27
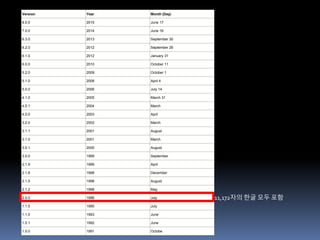
Version Year Month(Day)
8.0.0 2015 June 17
7.0.0 2014 June 16
6.3.0 2013 September 30
6.2.0 2012 September 26
6.1.0 2012 January 31
6.0.0 2010 October 11
5.2.0 2009 October 1
5.1.0 2008 April 4
5.0.0 2006 July 14
4.1.0 2005 March 31
4.0.1 2004 March
4.0.0 2003 April
3.2.0 2002 March
3.1.1 2001 August
3.1.0 2001 March
3.0.1 2000 August
3.0.0 1999 September
2.1.9 1999 April
2.1.8 1998 December
2.1.5 1998 August
2.1.2 1998 May
2.0.0 1996 July
1.1.5 1995 July
1.1.0 1993 June
1.0.1 1992 June
1.0.0 1991 Octobe
11,172자의 한글 모두 포함
28.
유니코드 기본 개념
전 세계의 문자를 특정 번호를 매겨서 테이
블로 관리 (코드 포인트)
U+0041
U+ : Unicode
0041 : 코드 포인트 값 (16진수)
코드 포인트 값은 단순한 일렬번호가 아니
라 문자 범위 별로 여러 블록으로 쪼개져 있
음.
28
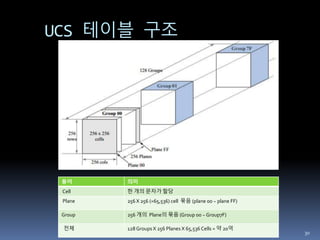
UCS 테이블 구조
30
용어의미
Cell 한 개의 문자가 할당
Plane 256 X 256 (=65,536) cell 묶음 (plane 00 ~ plane FF)
Group 256 개의 Plane의 묶음 (Group 00 ~ Group7F)
전체 128 Groups X 256 Planes X 65,536 Cells = 약 20억
31.
유니코드 체계
Unicode는UCS 서브셋
Group00 의 Plane00 ~ Plane16 까지( 17개)
17 Planes * 65536 = 약 100만개
31
32.
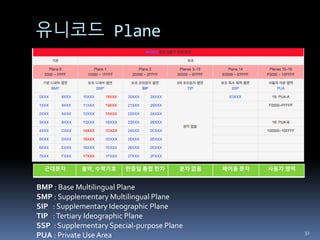
유니코드 Plane
32
근대문자 음악,수학기호 한중일 통합 한자 문자 없음 제어용 문자 사용자 영역
BMP : Base Multilingual Plane
SMP : Supplementary Multilingual Plane
SIP : Supplementary Ideographic Plane
TIP :Tertiary Ideographic Plane
SSP : Supplementary Special-purpose Plane
PUA : Private Use Area
33.
• 알파벳 ‘A’
•한글 ‘가’
• 음표
• plane 번호 5bit + Cell 번호 16 bit = 21bit
유니코드 코드 포인트
33
유니코드 인코딩
코드포인트를 바이트 코드로 표현
UTF (UCSTransformation Format)
UTF-32
UTF-16
UTF-8
36
37.
• 모든 코드포인트가 32비트로 1:1 매핑
• 남는 11 개 비트는 0으로 채워짐
• 4byte 고정길이, 메모리 낭비가 심해 거의 사
용 되지 않음
• ISO UCS-4 와 동일
UTF-32
37
38.
UTF-16
많이 사용되는현대 문자의 99%가 BMP영
역(즉 대다수가 2byte임)
UTF-32 보다 저장 공간이 적음
2, 4바이트 가변 길이 인코딩
ISO UCS-2와 동일
38
39.
Surrogate Code points
초기 유니코드는 16bit character set 였기
때문에 모든 문자 표현하기 역부족
남아 있는 코드 포인트를 확장
Surrogate(대리 영역)을 만들었음
High Surrogate U+D800 ~ U+DBFF
Low Surrogate U+DC00 ~ U+DFFF
UTF-16 에서 사용됨
39
40.
UTF-16
BMP(Plane00)에 해당하는문자는 5bit를 생략하므로 5bit 제거하고
16bit 로 1:1매핑
40
• BMP 영역을 벗어나는 문자는 32bit로(4byte) 인코딩
- U+1D160 – U+10000 = D160 (0000 1101 0001 0110 0000)
- high 10 bit 0000 1101 00
- low 10 bit 01 0110 0000
- U+D800(high surrogate) + U+34(high 10 bit) = U+D834
- U+DC00(low surrogate) + U+160(low 10 bit) = U+DD60
- D834 DD60
41.
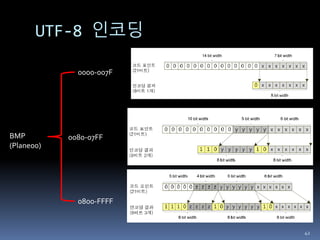
UTF-8
UTF-16은 ASCII마저도 2byte 이지만
UTF-8 ASCII 1byte
가장 많이 사용되는 인코딩
BMP 영역 1-3 byte
BMP 외 영역 4 byte
41
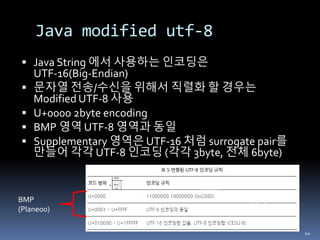
Java modified utf-8
Java String 에서 사용하는 인코딩은
UTF-16(Big-Endian)
문자열 전송/수신을 위해서 직렬화 할 경우는
Modified UTF-8 사용
U+0000 2byte encoding
BMP 영역 UTF-8 영역과 동일
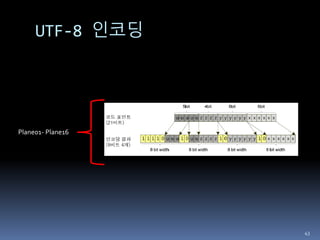
Supplementary 영역은 UTF-16 처럼 surrogate pair를
만들어 각각 UTF-8 인코딩 (각각 3byte, 전체 6byte)
44
6byte
2byte
BMP
(Plane00)
45.
BOM
유니코드에서 Big-Endian,Little-Endian 구별하기 위해
컴퓨터 메모리와 같은 1차원 공간에서 여러 개의 연속
된 대상을 배열 하는 방법
45
Encoding 표현
UTF-16 BE FE FF
UTF-16 LE FF FE
UTF-32 BE 00 00 FE FF
UTF-32 LE FF FE 00 00
46.
SUMMARY
ASCII ->Extended ASCII -> ISO 8859 Series
한글처리 조합형/완성형
KSC5601-1987 이 재정이 되었지만 현대 한글 표
현하지 못함
확장 MS949가 출시 되어 한글 표준을 외산
업체가 정한거나 마찬가지
여러 문자들을 표현하기 유니코드 탄생
46














































![[TAOCP] 1.3.1 MIX 설명](https://cdn.slidesharecdn.com/ss_thumbnails/taocp131-110415151427-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[Emocon 2017 S/S] 20170414 유니코드(Unicode)로 오픈소스에 기여하기](https://cdn.slidesharecdn.com/ss_thumbnails/20170414-170429081753-thumbnail.jpg?width=640&height=640&fit=bounds)






