Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Teppei Kurita
PPTX, PDF
1,324 views
カメラでの偏光取得における円偏光と位相遅延の考え方
偏光を取得できるカメラで円偏光と位相遅延をどう考えるかについてまとめました。
Technology
◦
Related topics:
Computer Vision Insights
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 10 times
1
/ 31
2
/ 31
Most read
3
/ 31
4
/ 31
5
/ 31
Most read
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
Most read
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
NDTスキャンマッチング 第1回3D勉強会@PFN 2018年5月27日
by
Kitsukawa Yuki
PPTX
SLAM勉強会(PTAM)
by
Masaya Kaneko
PDF
SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~
by
SSII
PDF
SLAM開発における課題と対策の一例の紹介
by
miyanegi
PDF
SSII2018TS: 3D物体検出とロボットビジョンへの応用
by
SSII
PPTX
ORB-SLAMの手法解説
by
Masaya Kaneko
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
by
SSII
PPTX
SSII2020TS: 物理ベースビジョンの過去・現在・未来 〜 カメラ・物体・光のインタラクションを モデル化するには 〜
by
SSII
NDTスキャンマッチング 第1回3D勉強会@PFN 2018年5月27日
by
Kitsukawa Yuki
SLAM勉強会(PTAM)
by
Masaya Kaneko
SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~
by
SSII
SLAM開発における課題と対策の一例の紹介
by
miyanegi
SSII2018TS: 3D物体検出とロボットビジョンへの応用
by
SSII
ORB-SLAMの手法解説
by
Masaya Kaneko
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
by
SSII
SSII2020TS: 物理ベースビジョンの過去・現在・未来 〜 カメラ・物体・光のインタラクションを モデル化するには 〜
by
SSII
What's hot
PPTX
3次元計測とフィルタリング
by
Norishige Fukushima
PDF
局所特徴量と統計学習手法による物体検出
by
MPRG_Chubu_University
PDF
3次元レジストレーション(PCLデモとコード付き)
by
Toru Tamaki
PPTX
球面フィッティングの導出と実装
by
j_rocket_boy
PPTX
USVSEG:齧歯超音波発声の検出手法
by
Ryosuke Tachibana
PDF
SLAM入門 第2章 SLAMの基礎
by
yohei okawa
PPTX
関東コンピュータビジョン勉強会
by
nonane
PPTX
BRDFモデルの変遷
by
Teppei Kurita
PDF
コンピューテーショナルフォトグラフィ
by
Norishige Fukushima
PDF
Random Forestsとその応用
by
MPRG_Chubu_University
PDF
ディジタル信号処理 課題解説 その5
by
noname409
PDF
FPGAをロボット(ROS)で「やわらかく」使うには
by
Hideki Takase
PPTX
基底変形型教師ありNMFによる実楽器信号分離 (in Japanese)
by
Daichi Kitamura
PDF
SSII2019TS: プロジェクタ・カメラシステムが変わる! ~時間同期の制御で広がる応用~
by
SSII
PDF
線形?非線形?
by
nishio
PDF
勉強か?趣味か?人生か?―プログラミングコンテストとは
by
Takuya Akiba
PDF
Sift特徴量について
by
la_flance
PDF
SSII2019企画: 点群深層学習の研究動向
by
SSII
PDF
第1回 配信講義 計算科学技術特論A (2021)
by
RCCSRENKEI
PDF
オープンソース SLAM の分類
by
Yoshitaka HARA
3次元計測とフィルタリング
by
Norishige Fukushima
局所特徴量と統計学習手法による物体検出
by
MPRG_Chubu_University
3次元レジストレーション(PCLデモとコード付き)
by
Toru Tamaki
球面フィッティングの導出と実装
by
j_rocket_boy
USVSEG:齧歯超音波発声の検出手法
by
Ryosuke Tachibana
SLAM入門 第2章 SLAMの基礎
by
yohei okawa
関東コンピュータビジョン勉強会
by
nonane
BRDFモデルの変遷
by
Teppei Kurita
コンピューテーショナルフォトグラフィ
by
Norishige Fukushima
Random Forestsとその応用
by
MPRG_Chubu_University
ディジタル信号処理 課題解説 その5
by
noname409
FPGAをロボット(ROS)で「やわらかく」使うには
by
Hideki Takase
基底変形型教師ありNMFによる実楽器信号分離 (in Japanese)
by
Daichi Kitamura
SSII2019TS: プロジェクタ・カメラシステムが変わる! ~時間同期の制御で広がる応用~
by
SSII
線形?非線形?
by
nishio
勉強か?趣味か?人生か?―プログラミングコンテストとは
by
Takuya Akiba
Sift特徴量について
by
la_flance
SSII2019企画: 点群深層学習の研究動向
by
SSII
第1回 配信講義 計算科学技術特論A (2021)
by
RCCSRENKEI
オープンソース SLAM の分類
by
Yoshitaka HARA
Similar to カメラでの偏光取得における円偏光と位相遅延の考え方
PDF
2次元/3次元幾何学変換の統一的な最適計算論文
by
doboncho
PDF
最適コントラスト補正による視程障害画像の明瞭化論文
by
doboncho
PDF
Prmu 200603
by
guest28a271
PDF
Prmu 200603
by
guest28a271
PDF
水平線検出による船体動揺映像の安定化スライド
by
doboncho
PDF
task physics assignment No6 (sample)
by
Class On Cloud -
PDF
SSII2018TS: コンピュテーショナルイルミネーション
by
SSII
PDF
2016年度秋学期 画像情報処理 第14回 逆投影法による再構成 (2017. 1. 19)
by
Akira Asano
PDF
2022年度秋学期 画像情報処理 第11回 逆投影法による再構成 (2022. 12. 9)
by
Akira Asano
PDF
2015年度春学期 画像情報処理 第14回 逆投影法による再構成
by
Akira Asano
PDF
2014年度春学期 画像情報処理 第14回 逆投影法による再構成 (2014. 7. 23)
by
Akira Asano
PDF
2015年度春学期 画像情報処理 第13回 Radon変換と投影定理
by
Akira Asano
PPTX
Direct Sparse Odometryの解説
by
Masaya Kaneko
PDF
2014年度春学期 画像情報処理 第13回 Radon変換と投影定理 (2014. 7. 16)
by
Akira Asano
PDF
2021年度秋学期 画像情報処理 第11回 逆投影法による再構成 (2021. 12. 3)
by
Akira Asano
PDF
2021年度秋学期 画像情報処理 第10回 Radon変換と投影定理 (2021. 11. 19)
by
Akira Asano
PDF
CVPR2019読み会 "A Theory of Fermat Paths for Non-Line-of-Sight Shape Reconstruc...
by
Hajime Mihara
PDF
2019年度秋学期 画像情報処理 第12回 逆投影法による再構成 (2019. 12. 20)
by
Akira Asano
PPTX
遠赤外線カメラと可視カメラを利用した悪条件下における画像取得
by
Masayuki Tanaka
PDF
2020年度秋学期 画像情報処理 第11回 Radon変換と投影定理 (2020. 12. 4)
by
Akira Asano
2次元/3次元幾何学変換の統一的な最適計算論文
by
doboncho
最適コントラスト補正による視程障害画像の明瞭化論文
by
doboncho
Prmu 200603
by
guest28a271
Prmu 200603
by
guest28a271
水平線検出による船体動揺映像の安定化スライド
by
doboncho
task physics assignment No6 (sample)
by
Class On Cloud -
SSII2018TS: コンピュテーショナルイルミネーション
by
SSII
2016年度秋学期 画像情報処理 第14回 逆投影法による再構成 (2017. 1. 19)
by
Akira Asano
2022年度秋学期 画像情報処理 第11回 逆投影法による再構成 (2022. 12. 9)
by
Akira Asano
2015年度春学期 画像情報処理 第14回 逆投影法による再構成
by
Akira Asano
2014年度春学期 画像情報処理 第14回 逆投影法による再構成 (2014. 7. 23)
by
Akira Asano
2015年度春学期 画像情報処理 第13回 Radon変換と投影定理
by
Akira Asano
Direct Sparse Odometryの解説
by
Masaya Kaneko
2014年度春学期 画像情報処理 第13回 Radon変換と投影定理 (2014. 7. 16)
by
Akira Asano
2021年度秋学期 画像情報処理 第11回 逆投影法による再構成 (2021. 12. 3)
by
Akira Asano
2021年度秋学期 画像情報処理 第10回 Radon変換と投影定理 (2021. 11. 19)
by
Akira Asano
CVPR2019読み会 "A Theory of Fermat Paths for Non-Line-of-Sight Shape Reconstruc...
by
Hajime Mihara
2019年度秋学期 画像情報処理 第12回 逆投影法による再構成 (2019. 12. 20)
by
Akira Asano
遠赤外線カメラと可視カメラを利用した悪条件下における画像取得
by
Masayuki Tanaka
2020年度秋学期 画像情報処理 第11回 Radon変換と投影定理 (2020. 12. 4)
by
Akira Asano
Recently uploaded
PDF
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
カメラでの偏光取得における円偏光と位相遅延の考え方
1.
カメラでの偏光取得における円偏光と位相遅延の考え方 Teppei Kurita
2.
偏光を取得できるカメラ • 最近続々と登場 • 物体の偏光状態を解析できる、偏光度など Sony
XCG-CP510 https://www.sony.co.jp/Produc ts/ISP/products/model/pc/XC G-CP510.html LUCID VP-PHX050S-P/Q http://www.viewplus.co.jp/product_luc id/1_index_detail.html ただ観測される信号値において、円偏光や位相遅延の影響に言及している解説がない
3.
円偏光 • 光の振動が円のように伝わる偏光 • [円偏光、直線偏光]
∈ 楕円偏光 円偏光 直線偏光 楕円偏光 偏光 – Wikipedia https://ja.wikipedia.org/wiki/%E5%81%8F%E5%85%89
4.
円偏光 • 円偏光は、楕円偏光のなかでX,Y成分が等しく位相差が半周期ずれている特殊型である • 円偏光を特に使っていると言及されている場合は、実際に円偏光かどうかに関わらずその回転の向きを利用 しているということが多い 右回り円偏光
左回り円偏光
5.
位相遅延(回転方向) • 偏光の回転方向は偏光成分x,yの位相差によって決まる http://www.cybernet.co.jp/optical/course/optics/opt06/opt03.html x成分がy成分に対し 進んでいる場合 =右回り x成分がy成分に対し 遅れている場合 =左回り
6.
位相遅延(回転方向) • 偏光は回転成分を保持している場合、物体で反射すると回転軸が反転する(位相遅延する)ことがある • 材料特性(誘電体/金属)によってその反転度合いが変わってくる •
後で詳しく述べる
7.
脱線 • オリオン大星雲において巨大な円偏光が観測された • なぜこのような円偏光が生まれたのかは未だ解明されていない 黄:左回り円偏光 赤:右回り円偏光 http://www.nao.ac.jp/releaselist/archive/20100406/result.html
8.
ストークスベクトルを用いた偏光状態遷移 http://www.chem.sci.osaka-u.ac.jp/lab/tsukahara/takechi/background02.html 𝒔 = 𝑠0
𝑠1 𝑠2 𝑠3 𝑇 𝑠0 :光強度 𝑠1 :水平直線優越偏光成分 (0[deg]-90[deg] 成分) 𝑠2 :45[deg]直線優越偏光成分 (45[deg]-135[deg] 成分) 𝑠3 :右向き円優越偏光成分 (右円-左円成分) 𝐬′ = 𝐂 𝜙 𝐃 𝛿; 𝐧 𝐑 𝜃; 𝐧 𝐂 −𝜙 𝐬 1.入力光のストークスベクトル 2.鏡面反射でのストークスベクトルの遷移
9.
ストークスベクトルのイメージ • 幾何学的に描く(直線偏光の場合) θ 45°優勢(𝐴45)135°優勢(𝐴135) 0°優勢(𝐴0) 90°優勢(𝐴90) cosθ sinθ cos(45-θ) sin(45-θ) 直線偏光 (強度s0=1とする) 𝑠1 =
𝐴0 2 − 𝐴90 2 𝑠2 = 𝐴45 2 − 𝐴135 2 𝑠1 = cos2 𝜃 − sin2 𝜃 = 2 cos2 𝜃 − 1 = cos 2𝜃 𝑠2 = cos2 (45° − 𝜃) − sin2 45° − 𝜃 = 2 cos2 45° − 𝜃 − 1 = cos 90° − 2𝜃 = cos 90° cos 2𝜃 + sin 90° sin 2𝜃 = sin 2𝜃 無偏光の場合 𝑠0 > 𝑠1 2 + 𝑠2 2 + 𝑠3 2 = 0 直線偏光の場合 𝑠0 = 𝑠1 2 + 𝑠2 2 𝑠3 = 0 楕円偏光の場合 𝑠0 = 𝑠1 2 + 𝑠2 2 + 𝑠3 2 円偏光の場合 𝑠0 = 𝑠3 𝑠1, 𝑠2 = 0 𝒔 = 𝑠0 𝑠1 𝑠2 𝑠3 𝑇 𝑠0 :光強度 𝑠1 :水平直線優越偏光成分 (0[deg]-90[deg] 成分) 𝑠2 :45[deg]直線優越偏光成分 (45[deg]-135[deg] 成分) 𝑠3 :右向き円優越偏光成分 (右円-左円成分)
10.
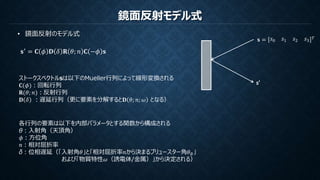
鏡面反射モデル式 • 鏡面反射のモデル式 𝐬′ =
𝐂 𝜙 𝐃 𝛿 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 ストークスベクトルsは以下のMueller行列によって線形変換される 𝐂(𝜙):回転行列 𝐑(𝜃; 𝑛):反射行列 𝐃 𝛿 :遅延行列(更に要素を分解すると𝐃 𝜃; 𝑛; 𝜔 となる) 各行列の要素は以下を内部パラメータとする関数から構成される θ:入射角(天頂角) 𝜙:方位角 𝑛:相対屈折率 δ:位相遅延(「入射角𝜃」と「相対屈折率𝑛から決まるブリュースター角𝜃 𝐵」 および「物質特性𝜔(誘電体/金属)」から決定される) s’ 𝐬 = 𝑠0 𝑠1 𝑠2 𝑠3 𝑇
11.
MUELLER行列 • 各Mueller行列の中身 𝐂(𝜙) = 1
0 0 cos 2𝜙 0 0 − sin 2𝜙 0 0 sin 2𝜙 0 0 cos 2𝜙 0 0 1 回転行列 反射行列 𝐑(𝜃; 𝑛) = 𝑅 𝑝+𝑅 𝑠 2 𝑅 𝑝−𝑅 𝑠 2 0 0 𝑅 𝑝−𝑅 𝑠 2 𝑅 𝑝+𝑅 𝑠 2 0 0 0 0 𝑅 𝑝 𝑅 𝑠 0 0 0 0 𝑅 𝑝 𝑅 𝑠 遅延行列 𝐃(𝛿) = 1 0 0 0 0 1 0 0 0 0 cos 𝛿 sin 𝛿 0 0 − sin 𝛿 cos 𝛿 誘電体 𝛿 = 0° (𝜃 ≤ 𝜃 𝐵) 𝛿 = 180° (𝜃 > 𝜃 𝐵) 金属 𝛿 = 180° − 𝜃 𝜃 𝐵 = arctan 𝑛 𝑅 𝑝 = 𝑛2 cos 𝜃− 𝑛2−sin2 𝜃 𝑛2 cos 𝜃+ 𝑛2−sin2 𝜃 2 𝑅 𝑠 = cos 𝜃− 𝑛2−sin2 𝜃 cos 𝜃+ 𝑛2−sin2 𝜃 2
12.
鏡面反射計算 • 一般解 𝐬′ = 𝐂
𝜙 𝐃 𝛿 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 𝐂 −𝜙 𝐬 = 1 0 0 cos 2𝜙 0 0 sin 2𝜙 0 0 − sin 2𝜙 0 0 cos 2𝜙 0 0 1 𝑠0 𝑠1 𝑠2 𝑠3 = 𝑠0 𝑠1 cos 2𝜙 + 𝑠2 sin 2𝜙 −𝑠1 sin 2𝜙 + 𝑠2 cos 2𝜙 𝑠3
13.
鏡面反射計算 • 一般解 𝐬′ = 𝐂
𝜙 𝐃 𝛿 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 = 𝑅 𝑝 + 𝑅 𝑠 2 𝑅 𝑝 − 𝑅 𝑠 2 0 0 𝑅 𝑝 − 𝑅 𝑠 2 𝑅 𝑝 + 𝑅 𝑠 2 0 0 0 0 𝑅 𝑝 𝑅 𝑠 0 0 0 0 𝑅 𝑝 𝑅 𝑠 𝑠0 𝑠1 cos 2𝜙 + 𝑠2 sin 2𝜙 −𝑠1 sin 2𝜙 + 𝑠2 cos 2𝜙 𝑠3 = 𝑠0 𝑅 𝑝 + 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 sin 2𝜙 −𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 + 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 𝑠3 𝑅 𝑝 𝑅 𝑠
14.
鏡面反射計算 • 一般解 𝐬′ = 𝐂
𝜙 𝐃 𝛿 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 𝐃 𝛿 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 = 1 0 0 0 0 1 0 0 0 0 cos 𝛿 sin 𝛿 0 0 − sin 𝛿 cos 𝛿 𝑠0 𝑅 𝑝 + 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 sin 2𝜙 −𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 + 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 𝑠3 𝑅 𝑝 𝑅 𝑠 = 𝑠0 𝑅 𝑝 + 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 sin 2𝜙 −𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 cos 𝛿 + 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 cos 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 sin 𝛿 𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 − 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 𝛿
15.
鏡面反射計算 • 一般解 𝐬′ = 𝐂
𝜙 𝐃 𝛿 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 𝐂 𝜙 𝐃 𝛿 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 = 1 0 0 cos 2𝜙 0 0 − sin 2𝜙 0 0 sin 2𝜙 0 0 cos 2𝜙 0 0 1 𝑠0 𝑅 𝑝 + 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 sin 2𝜙 −𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 cos 𝛿 + 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 cos 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 sin 𝛿 𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 − 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 𝛿 = 𝑠0 𝑅 𝑝 + 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 cos2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 sin2 2𝜙 cos 𝛿 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 − 𝑠3 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 sin2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 cos2 2𝜙 cos 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 − 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 𝛿
16.
鏡面反射による偏光状態一般解 • 鏡面反射による偏光状態変化の一般解は以下で表される 𝐬′ = 𝐂
𝜙 𝐃 𝛿 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 𝒔 = 𝑠0 𝑠1 𝑠2 𝑠3 𝑇 s’ この式が重要 𝐬′ = 𝑠0 𝑅 𝑝 + 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 cos2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 sin2 2𝜙 cos 𝛿 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 − 𝑠3 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 sin2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 cos2 2𝜙 cos 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 − 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 𝛿 楕円偏光が入射する場合、s0~s4の項が全て残る
17.
鏡面反射による偏光状態一般解 • 無偏光の光が特定の物体で反射したとき、 𝑠0 =
1 𝑠1, 𝑠2, 𝑠3 = 0 𝒔 = 1 0 0 0 𝑇 s’ 𝐬′ = 𝑠0 𝑅 𝑝 + 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 cos2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 sin2 2𝜙 cos 𝛿 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 − 𝑠3 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 sin2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 cos2 2𝜙 cos 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 − 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 𝛿
18.
鏡面反射による偏光状態一般解 • 無偏光の光が特定の物体で反射したとき、 𝑠0 =
1 𝑠1, 𝑠2, 𝑠3 = 0 𝒔 = 1 0 0 0 𝑇 s’ 𝐬′ = 𝑅 𝑝 + 𝑅 𝑠 2 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 0 無偏光の光が特定の物体で反射したとき、 1.天頂角/屈折率によって偏光の強度が変わる 2.天頂角/方位角/屈折率によって偏光角度が変わる 3.偏光の回転方向(位相差)への影響は0である
19.
鏡面反射による偏光状態一般解 • 0°優勢の直線偏光が特定の物体で反射したとき、 𝑠0, 𝑠1
= 1 𝑠2, 𝑠3 = 0 𝒔 = 1 1 0 0 𝑇 s’ 𝐬′ = 𝑠0 𝑅 𝑝 + 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 cos2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 sin2 2𝜙 cos 𝛿 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 − 𝑠3 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 sin2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 cos2 2𝜙 cos 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 − 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 𝛿
20.
鏡面反射による偏光状態一般解 • 0°優勢の直線偏光が特定の物体で反射したとき、 𝑠0, 𝑠1
= 1 𝑠2, 𝑠3 = 0 𝒔 = 1 1 0 0 𝑇 s’ 𝐬′ = 𝑅 𝑝 + 𝑅 𝑠 2 + 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑅 𝑝 + 𝑅 𝑠 2 cos2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 sin2 2𝜙 cos 𝛿 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 + 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 0°の光が特定の物体で反射したとき、 1.天頂角/方位角/屈折率によって偏光の強度が変わる 2.天頂角/方位角/屈折率/位相遅延によって偏光角度が変わる 3.天頂角/方位角/屈折率/位相遅延によって偏光の回転方向(位相差)が変わる 誘電体の場合は位相差0となり直線偏光のままになる
21.
鏡面反射による偏光状態一般解 𝑠0, 𝑠3 =
1 𝑠1, 𝑠2 = 0 𝒔 = 1 0 0 1 𝑇 s’ 𝐬′ = 𝑠0 𝑅 𝑝 + 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 cos2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 sin2 2𝜙 cos 𝛿 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 − 𝑠3 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 sin2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 cos2 2𝜙 cos 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 − 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 𝛿 • 円偏光(右向き)が特定の物体で反射したとき、
22.
鏡面反射による偏光状態一般解 • 円偏光(右向き)が特定の物体で反射したとき、 𝑠0, 𝑠3
= 1 𝑠1, 𝑠2 = 0 𝒔 = 1 0 0 1 𝑇 s’ 𝐬′ = 𝑅 𝑝 + 𝑅 𝑠 2 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 − 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 + 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 𝑅 𝑝 𝑅 𝑠 cos 𝛿 0°の光が特定の物体で反射したとき、 1.天頂角/屈折率によって偏光の強度が変わる 2.天頂角/方位角/屈折率/位相遅延によって偏光角度が変わる 3.天頂角/屈折率/位相遅延よって偏光の回転方向(位相差)が変わる
23.
まとめ 光が特定の物体で反射したとき、偏光状態は以下の要素に依存して変化する 入射光 無偏光 直線偏光
楕円偏光 円偏光 光強度 𝜃、𝑛 𝜃、𝜙、𝑛 𝜃、𝜙、𝑛 𝜃、𝑛 偏光角度 𝜃、𝜙、𝑛 𝜃、𝜙、𝑛、𝜔 𝜃、𝜙、𝑛、𝜔 𝜃、𝜙、𝑛、𝜔 回転方向(位相差) 変化なし 𝜃、𝜙、𝑛、𝜔 𝜃、𝜙、𝑛、𝜔 𝜃、𝑛、𝜔 θ:入射角(天頂角) 𝜙:方位角 𝑛 :相対屈折率 𝜔:物質特性(誘電体/金属) 直線偏光になる 楕円偏光になる直線偏光(誘電体) 楕円偏光(金属) になる
24.
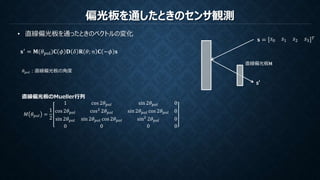
偏光板を通したときのセンサ観測 • 直線偏光板を通ったときのベクトルの変化 𝐬 =
𝑠0 𝑠1 𝑠2 𝑠3 𝑇 s’ 直線偏光板M 直線偏光板のMueller行列 𝑀 𝜃 𝑝𝑜𝑙 = 1 2 1 cos 2𝜃 𝑝𝑜𝑙 sin 2𝜃 𝑝𝑜𝑙 0 cos 2𝜃 𝑝𝑜𝑙 cos2 2𝜃 𝑝𝑜𝑙 sin 2𝜃 𝑝𝑜𝑙 cos 2𝜃 𝑝𝑜𝑙 0 sin 2𝜃 𝑝𝑜𝑙 sin 2𝜃 𝑝𝑜𝑙 cos 2𝜃 𝑝𝑜𝑙 sin2 2𝜃 𝑝𝑜𝑙 0 0 0 0 0 𝐬′ = 𝐌(𝜃pol)𝐂 𝜙 𝐃 𝛿 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 𝜃 𝑝𝑜𝑙:直線偏光板の角度
25.
偏光板を通したときのセンサ観測 • 直線偏光板を通ったときのベクトルの変化 𝐬′ =
𝐌(𝜃pol)𝐂 𝜙 𝐃 𝛿 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 𝐬′ = 1 2 1 cos 2𝜃 𝑝𝑜𝑙 sin 2𝜃 𝑝𝑜𝑙 0 cos 2𝜃 𝑝𝑜𝑙 cos2 2𝜃 𝑝𝑜𝑙 sin 2𝜃 𝑝𝑜𝑙 cos 2𝜃 𝑝𝑜𝑙 0 sin 2𝜃 𝑝𝑜𝑙 sin 2𝜃 𝑝𝑜𝑙 cos 2𝜃 𝑝𝑜𝑙 sin2 2𝜃 𝑝𝑜𝑙 0 0 0 0 0 𝑠0 𝑅 𝑝 + 𝑅 𝑠 2 + 𝑠1 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠2 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 cos 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 cos2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 sin2 2𝜙 cos 𝛿 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 − 𝑠3 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 𝑠0 𝑅 𝑝 − 𝑅 𝑠 2 sin 2𝜙 + 𝑠1 𝑅 𝑝 + 𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜙 cos 2𝜙 + 𝑠2 𝑅 𝑝 + 𝑅 𝑠 2 sin2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 cos2 2𝜙 cos 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 𝑠1 𝑅 𝑝 𝑅 𝑠 sin 2𝜙 sin 𝛿 − 𝑠2 𝑅 𝑝 𝑅 𝑠 cos 2𝜙 sin 𝛿 + 𝑠3 𝑅 𝑝 𝑅 𝑠 cos 𝛿
26.
偏光板を通したときのセンサ観測 𝑠0 ′ = 𝑠0 2 𝑅 𝑝+𝑅 𝑠 2 + 𝑅
𝑝−𝑅 𝑠 2 cos 2𝜃 𝑝𝑜𝑙 cos 2𝜙 + 𝑅 𝑝−𝑅 𝑠 2 sin 2𝜃 𝑝𝑜𝑙 sin 2𝜙 + 𝑠1 2 𝑅 𝑝−𝑅 𝑠 2 cos 2𝜙 + 𝑅 𝑝+𝑅 𝑠 2 cos2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 sin2 2𝜙 cos 𝛿 cos 2𝜃 𝑝𝑜𝑙 + 𝑅 𝑝+𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 sin 2𝜃 𝑝𝑜𝑙 sin 2𝜙 cos 2𝜙 + 𝑠2 2 𝑅 𝑝−𝑅 𝑠 2 sin 2𝜙 + 𝑅 𝑝+𝑅 𝑠 2 − 𝑅 𝑝 𝑅 𝑠 cos 𝛿 cos 2𝜃 𝑝𝑜𝑙 sin 2𝜙 cos 2𝜙 + 𝑅 𝑝+𝑅 𝑠 2 sin2 2𝜙 + 𝑅 𝑝 𝑅 𝑠 cos2 2𝜙 cos 𝛿 sin 2𝜃 𝑝𝑜𝑙 + 𝑠3 2 − 𝑅 𝑝 𝑅 𝑠 cos 2𝜃 𝑝𝑜𝑙 sin 2𝜙 + 𝑅 𝑝 𝑅 𝑠 sin 2𝜃 𝑝𝑜𝑙 cos 2𝜙 sin 𝛿
27.
偏光板を通したときのセンサ観測 • 直線偏光板を通ったときのベクトルの変化 𝐬′ = 𝑠0′ 𝑠0′cos
2𝜃 𝑝𝑜𝑙 𝑠0′cos 2𝜃 𝑝𝑜𝑙 0 𝐬′ = 𝐌(𝜃pol)𝐂 𝜙 𝐃 𝛿 𝐑 𝜃; 𝑛 𝐂 −𝜙 𝐬 𝑠0 ′ = 𝑠0 𝑅 𝑝+𝑅 𝑠 4 + 𝑅 𝑝−𝑅 𝑠 4 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠1 𝑅 𝑝−𝑅 𝑠 4 cos 2𝜙 + 𝑅 𝑝+𝑅 𝑠 4 cos 2𝜙 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 − 𝑅 𝑝 𝑅 𝑠 2 sin 2𝜙 cos 𝛿 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠2 𝑅 𝑝−𝑅 𝑠 4 sin 2𝜙 + 𝑅 𝑝+𝑅 𝑠 4 sin 2𝜙 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 + 𝑅 𝑝 𝑅 𝑠 2 cos 2𝜙 cos 𝛿 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠3 𝑅 𝑝 𝑅 𝑠 2 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 sin 𝛿 𝑠0′が最終的にセンサが観測可能な信号値である
28.
偏光板を通したときのセンサ観測 • 無偏光の光の場合 • 𝑠0
= 1 • 𝑠1, 𝑠2, 𝑠3 = 0 𝑠0 ′ = 𝑠0 𝑅 𝑝+𝑅 𝑠 4 + 𝑅 𝑝−𝑅 𝑠 4 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠1 𝑅 𝑝−𝑅 𝑠 4 cos 2𝜙 + 𝑅 𝑝+𝑅 𝑠 4 cos 2𝜙 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 − 𝑅 𝑝 𝑅 𝑠 2 sin 2𝜙 cos 𝛿 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠2 𝑅 𝑝−𝑅 𝑠 4 sin 2𝜙 + 𝑅 𝑝+𝑅 𝑠 4 sin 2𝜙 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 + 𝑅 𝑝 𝑅 𝑠 2 cos 2𝜙 cos 𝛿 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠3 𝑅 𝑝 𝑅 𝑠 2 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 sin 𝛿 𝑠0 ′ = 𝑅 𝑝 + 𝑅 𝑠 4 + 𝑅 𝑝 − 𝑅 𝑠 4 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 よくある鏡面反射のモデル式になる
29.
偏光板を通したときのセンサ観測 • 0°優勢の直線偏光の場合 • 𝑠0,
𝑠1 = 1 • 𝑠2, 𝑠3 = 0 𝑠0 ′ = 𝑠0 𝑅 𝑝+𝑅 𝑠 4 + 𝑅 𝑝−𝑅 𝑠 4 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠1 𝑅 𝑝−𝑅 𝑠 4 cos 2𝜙 + 𝑅 𝑝+𝑅 𝑠 4 cos 2𝜙 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 − 𝑅 𝑝 𝑅 𝑠 2 sin 2𝜙 cos 𝛿 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠2 𝑅 𝑝−𝑅 𝑠 4 sin 2𝜙 + 𝑅 𝑝+𝑅 𝑠 4 sin 2𝜙 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 + 𝑅 𝑝 𝑅 𝑠 2 cos 2𝜙 cos 𝛿 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠3 𝑅 𝑝 𝑅 𝑠 2 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 sin 𝛿 𝑠0 ′ = 𝑅 𝑝 + 𝑅 𝑠 4 + 𝑅 𝑝 − 𝑅 𝑠 4 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 + 𝑅 𝑝 − 𝑅 𝑠 4 cos 2𝜙 + 𝑅 𝑝 + 𝑅 𝑠 4 cos 2𝜙 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 − 𝑅 𝑝 𝑅 𝑠 2 sin 2𝜙 cos 𝛿 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙
30.
偏光板を通したときのセンサ観測 • 右回り円偏光の場合 • 𝑠0,
𝑠3 = 1 • 𝑠1, 𝑠2 = 0 𝑠0 ′ = 𝑠0 𝑅 𝑝+𝑅 𝑠 4 + 𝑅 𝑝−𝑅 𝑠 4 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠1 𝑅 𝑝−𝑅 𝑠 4 cos 2𝜙 + 𝑅 𝑝+𝑅 𝑠 4 cos 2𝜙 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 − 𝑅 𝑝 𝑅 𝑠 2 sin 2𝜙 cos 𝛿 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠2 𝑅 𝑝−𝑅 𝑠 4 sin 2𝜙 + 𝑅 𝑝+𝑅 𝑠 4 sin 2𝜙 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 + 𝑅 𝑝 𝑅 𝑠 2 cos 2𝜙 cos 𝛿 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 +𝑠3 𝑅 𝑝 𝑅 𝑠 2 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 sin 𝛿 𝑠0 ′ = 𝑅 𝑝 + 𝑅 𝑠 4 + 𝑅 𝑝 − 𝑅 𝑠 4 cos 2 𝜃 𝑝𝑜𝑙 − 𝜙 + 𝑅 𝑝 𝑅 𝑠 2 sin 2 𝜃 𝑝𝑜𝑙 − 𝜙 sin 𝛿
31.
まとめ • 光が特定の物体で反射して、直線偏光板を通したセンサで観測されたとき、信号値は以下の要素に依存して変化する 入射光 無偏光
直線偏光 楕円偏光 円偏光 光強度 𝜃 𝑝𝑜𝑙、𝜃、𝜙、𝑛 𝜃 𝑝𝑜𝑙、𝜃、𝜙、𝑛、𝜔 𝜃 𝑝𝑜𝑙、𝜃、𝜙、𝑛、𝜔 𝜃 𝑝𝑜𝑙、𝜃、𝜙、𝑛、𝜔 𝜃 𝑝𝑜𝑙:直線偏光板角度 θ:天頂角(入射角) 𝜙:方位角 𝑛 :相対屈折率 𝜔:物質特性(誘電体/金属) つまり「無偏光の光」を前提したとき「のみ」物体の物質特性による位相遅延を無視して良くなる → 無偏光以外の光が物体に照射している可能性があるときは、観測される信号値に位相遅延の影響があ ると考えた方が良い
Editor's Notes
#8
赤外感度 生命誕生の謎の足掛かりに 地球に落下した隕石にアミノ酸が含まれていたのは、 大規模な円偏光に原始太陽系が飲みこまれ照射された結果 アミノ酸が偏ったためであるという説
Download



![円偏光
• 光の振動が円のように伝わる偏光
• [円偏光、直線偏光] ∈ 楕円偏光
円偏光 直線偏光 楕円偏光
偏光 – Wikipedia https://ja.wikipedia.org/wiki/%E5%81%8F%E5%85%89](https://image.slidesharecdn.com/cpolar-191128071728/85/slide-3-320.jpg)




![ストークスベクトルを用いた偏光状態遷移
http://www.chem.sci.osaka-u.ac.jp/lab/tsukahara/takechi/background02.html
𝒔 = 𝑠0 𝑠1 𝑠2 𝑠3
𝑇
𝑠0 :光強度
𝑠1 :水平直線優越偏光成分 (0[deg]-90[deg] 成分)
𝑠2 :45[deg]直線優越偏光成分 (45[deg]-135[deg] 成分)
𝑠3 :右向き円優越偏光成分 (右円-左円成分)
𝐬′ = 𝐂 𝜙 𝐃 𝛿; 𝐧 𝐑 𝜃; 𝐧 𝐂 −𝜙 𝐬
1.入力光のストークスベクトル
2.鏡面反射でのストークスベクトルの遷移](https://image.slidesharecdn.com/cpolar-191128071728/85/slide-8-320.jpg)
![ストークスベクトルのイメージ
• 幾何学的に描く(直線偏光の場合)
θ
45°優勢(𝐴45)135°優勢(𝐴135)
0°優勢(𝐴0)
90°優勢(𝐴90)
cosθ
sinθ
cos(45-θ)
sin(45-θ)
直線偏光
(強度s0=1とする)
𝑠1 = 𝐴0
2
− 𝐴90
2
𝑠2 = 𝐴45
2
− 𝐴135
2
𝑠1 = cos2
𝜃 − sin2
𝜃 = 2 cos2
𝜃 − 1 = cos 2𝜃
𝑠2 = cos2
(45° − 𝜃) − sin2
45° − 𝜃 = 2 cos2
45° − 𝜃 − 1
= cos 90° − 2𝜃 = cos 90° cos 2𝜃 + sin 90° sin 2𝜃 = sin 2𝜃
無偏光の場合
𝑠0 > 𝑠1
2
+ 𝑠2
2
+ 𝑠3
2
= 0
直線偏光の場合
𝑠0 = 𝑠1
2
+ 𝑠2
2
𝑠3 = 0
楕円偏光の場合
𝑠0 = 𝑠1
2
+ 𝑠2
2
+ 𝑠3
2
円偏光の場合
𝑠0 = 𝑠3
𝑠1, 𝑠2 = 0
𝒔 = 𝑠0 𝑠1 𝑠2 𝑠3
𝑇
𝑠0 :光強度
𝑠1 :水平直線優越偏光成分 (0[deg]-90[deg] 成分)
𝑠2 :45[deg]直線優越偏光成分 (45[deg]-135[deg] 成分)
𝑠3 :右向き円優越偏光成分 (右円-左円成分)](https://image.slidesharecdn.com/cpolar-191128071728/85/slide-9-320.jpg)





















![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)























































