Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Yusuke Shirakawa
PPTX, PDF
7,489 views
大規模トラフィックにどのように備えて負荷対策を実施しているのか?
HAKODATE Developer Conference 2019
Technology
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 15 times
1
/ 59
2
/ 59
Most read
3
/ 59
4
/ 59
5
/ 59
6
/ 59
7
/ 59
8
/ 59
9
/ 59
10
/ 59
11
/ 59
12
/ 59
13
/ 59
14
/ 59
Most read
15
/ 59
16
/ 59
17
/ 59
18
/ 59
19
/ 59
20
/ 59
21
/ 59
22
/ 59
23
/ 59
24
/ 59
25
/ 59
26
/ 59
27
/ 59
28
/ 59
29
/ 59
30
/ 59
31
/ 59
32
/ 59
33
/ 59
34
/ 59
35
/ 59
36
/ 59
37
/ 59
38
/ 59
39
/ 59
40
/ 59
41
/ 59
42
/ 59
43
/ 59
44
/ 59
45
/ 59
46
/ 59
47
/ 59
48
/ 59
49
/ 59
50
/ 59
51
/ 59
52
/ 59
53
/ 59
54
/ 59
55
/ 59
56
/ 59
57
/ 59
58
/ 59
59
/ 59
More Related Content
PDF
開発速度が速い #とは(LayerX社内資料)
by
mosa siru
PDF
シリコンバレーの「何が」凄いのか
by
Atsushi Nakada
PDF
新入社員のための大規模ゲーム開発入門 サーバサイド編
by
infinite_loop
PDF
AWSのログ管理ベストプラクティス
by
Akihiro Kuwano
PDF
大規模ソーシャルゲームを支える技術~PHP+MySQLを使った高負荷対策~
by
infinite_loop
PPTX
スマホゲームのチート手法とその対策 [DeNA TechCon 2019]
by
DeNA
PPTX
CEDEC2019 大規模モバイルゲーム運用におけるマスタデータ管理事例
by
sairoutine
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
開発速度が速い #とは(LayerX社内資料)
by
mosa siru
シリコンバレーの「何が」凄いのか
by
Atsushi Nakada
新入社員のための大規模ゲーム開発入門 サーバサイド編
by
infinite_loop
AWSのログ管理ベストプラクティス
by
Akihiro Kuwano
大規模ソーシャルゲームを支える技術~PHP+MySQLを使った高負荷対策~
by
infinite_loop
スマホゲームのチート手法とその対策 [DeNA TechCon 2019]
by
DeNA
CEDEC2019 大規模モバイルゲーム運用におけるマスタデータ管理事例
by
sairoutine
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
What's hot
PPTX
分散トレーシングAWS:X-Rayとの上手い付き合い方
by
Recruit Lifestyle Co., Ltd.
PPTX
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
PDF
45分間で「ユーザー中心のものづくり」ができるまで詰め込む
by
Yoshiki Hayama
PDF
ソーシャルゲームのためのデータベース設計
by
Yoshinori Matsunobu
PPTX
ネットストーカー御用達OSINTツールBlackBirdを触ってみた.pptx
by
Shota Shinogi
PDF
「のどが渇いた」というユーザーに何を出す? ユーザーの「欲しい」に惑わされない、本当のインサイトを見つけるUXデザイン・UXリサーチ
by
Yoshiki Hayama
PDF
イミュータブルデータモデル(入門編)
by
Yoshitaka Kawashima
PDF
Dockerからcontainerdへの移行
by
Kohei Tokunaga
PPTX
クラウドでも非機能要求グレードは必要だよね
by
YoshioSawada
PPTX
BuildKitによる高速でセキュアなイメージビルド
by
Akihiro Suda
PDF
オンラインゲームの仕組みと工夫
by
Yuta Imai
PDF
Mercari JPのモノリスサービスをKubernetesに移行した話 PHP Conference 2022 9/24
by
Shin Ohno
PDF
コンテナ未経験新人が学ぶコンテナ技術入門
by
Kohei Tokunaga
PPTX
DeNAの最新のマスタデータ管理システム Oyakata の全容
by
sairoutine
PDF
インフラエンジニアの綺麗で優しい手順書の書き方
by
Shohei Koyama
PDF
ZOZOTOWNのマルチクラウドへの挑戦と挫折、そして未来
by
Hiromasa Oka
PDF
Unified JVM Logging
by
Yuji Kubota
PDF
[GKE & Spanner 勉強会] Cloud Spanner の技術概要
by
Google Cloud Platform - Japan
PDF
ドメイン駆動設計入門
by
増田 亨
PDF
BuildKitの概要と最近の機能
by
Kohei Tokunaga
分散トレーシングAWS:X-Rayとの上手い付き合い方
by
Recruit Lifestyle Co., Ltd.
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
45分間で「ユーザー中心のものづくり」ができるまで詰め込む
by
Yoshiki Hayama
ソーシャルゲームのためのデータベース設計
by
Yoshinori Matsunobu
ネットストーカー御用達OSINTツールBlackBirdを触ってみた.pptx
by
Shota Shinogi
「のどが渇いた」というユーザーに何を出す? ユーザーの「欲しい」に惑わされない、本当のインサイトを見つけるUXデザイン・UXリサーチ
by
Yoshiki Hayama
イミュータブルデータモデル(入門編)
by
Yoshitaka Kawashima
Dockerからcontainerdへの移行
by
Kohei Tokunaga
クラウドでも非機能要求グレードは必要だよね
by
YoshioSawada
BuildKitによる高速でセキュアなイメージビルド
by
Akihiro Suda
オンラインゲームの仕組みと工夫
by
Yuta Imai
Mercari JPのモノリスサービスをKubernetesに移行した話 PHP Conference 2022 9/24
by
Shin Ohno
コンテナ未経験新人が学ぶコンテナ技術入門
by
Kohei Tokunaga
DeNAの最新のマスタデータ管理システム Oyakata の全容
by
sairoutine
インフラエンジニアの綺麗で優しい手順書の書き方
by
Shohei Koyama
ZOZOTOWNのマルチクラウドへの挑戦と挫折、そして未来
by
Hiromasa Oka
Unified JVM Logging
by
Yuji Kubota
[GKE & Spanner 勉強会] Cloud Spanner の技術概要
by
Google Cloud Platform - Japan
ドメイン駆動設計入門
by
増田 亨
BuildKitの概要と最近の機能
by
Kohei Tokunaga
Similar to 大規模トラフィックにどのように備えて負荷対策を実施しているのか?
PPTX
モンスターストライクにおける負荷対策
by
Yusuke Shirakawa
PDF
[AWS Summit 2012] クラウドデザインパターン#5 CDP バッチ処理編
by
Amazon Web Services Japan
PDF
地方企業がソーシャルゲーム開発を成功させるための10のポイント
by
Kentaro Matsui
PDF
システム運用 (インフラ編)
by
Takashi Abe
PDF
DMMのゲームプラットフォームで利用している技術やシステム構成、レガシーシステムが抱える課題、解決のためのシステムリプレイスの進め方
by
DMM_GAMES_PF
PDF
[AWS Summit 2012] クラウドデザインパターン#7 CDP キャンペーンサイト編 (Wordpress)
by
Amazon Web Services Japan
PDF
エンターテイメント業界におけるAWS活用事例
by
Amazon Web Services Japan
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
PDF
ソーシャルゲームのEMR活用事例
by
知教 本間
PPTX
初心者向け負荷軽減のはなし
by
Oonishi Takaaki
PDF
20120407 ASP.NET+C#で開発する大規模ソーシャルゲーム
by
hideyuki ikeda
PDF
0730 bp study#35発表資料
by
Yasuhiro Horiuchi
PDF
20130226 Amazon Web Services 勉強会(新宿)
by
真吾 吉田
PDF
CDP キャンペーンサイト編 UPDATE
by
Hiroyasu Suzuki
PDF
20121019 engineer startup_meeting
by
Shuichi Wada
PDF
Data Center As A Computer 2章前半
by
Akinori YOSHIDA
PDF
クラウドセキュリティ基礎 @セキュリティ・ミニキャンプ in 東北 2016 #seccamp
by
Masahiro NAKAYAMA
PPT
Performance and Scalability of Web Service
by
Shinji Tanaka
PDF
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
PDF
20100520 【qpstudy01】 チームでトライ!インフラ構築のススメ
by
Yukitaka Ohmura
モンスターストライクにおける負荷対策
by
Yusuke Shirakawa
[AWS Summit 2012] クラウドデザインパターン#5 CDP バッチ処理編
by
Amazon Web Services Japan
地方企業がソーシャルゲーム開発を成功させるための10のポイント
by
Kentaro Matsui
システム運用 (インフラ編)
by
Takashi Abe
DMMのゲームプラットフォームで利用している技術やシステム構成、レガシーシステムが抱える課題、解決のためのシステムリプレイスの進め方
by
DMM_GAMES_PF
[AWS Summit 2012] クラウドデザインパターン#7 CDP キャンペーンサイト編 (Wordpress)
by
Amazon Web Services Japan
エンターテイメント業界におけるAWS活用事例
by
Amazon Web Services Japan
Cloudera大阪セミナー 20130219
by
Cloudera Japan
ソーシャルゲームのEMR活用事例
by
知教 本間
初心者向け負荷軽減のはなし
by
Oonishi Takaaki
20120407 ASP.NET+C#で開発する大規模ソーシャルゲーム
by
hideyuki ikeda
0730 bp study#35発表資料
by
Yasuhiro Horiuchi
20130226 Amazon Web Services 勉強会(新宿)
by
真吾 吉田
CDP キャンペーンサイト編 UPDATE
by
Hiroyasu Suzuki
20121019 engineer startup_meeting
by
Shuichi Wada
Data Center As A Computer 2章前半
by
Akinori YOSHIDA
クラウドセキュリティ基礎 @セキュリティ・ミニキャンプ in 東北 2016 #seccamp
by
Masahiro NAKAYAMA
Performance and Scalability of Web Service
by
Shinji Tanaka
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
20100520 【qpstudy01】 チームでトライ!インフラ構築のススメ
by
Yukitaka Ohmura
Recently uploaded
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):コアマイクロシステムズ株式会社 テーマ 「AI HPC時代のトータルソリューションプロバイダ」
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ1「大規模AIの能力を最大限に活用するHPE Comp...
by
PC Cluster Consortium
PDF
論文紹介:DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
by
Toru Tamaki
PDF
論文紹介:HiLoRA: Adaptive Hierarchical LoRA Routing for Training-Free Domain Gene...
by
Toru Tamaki
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ2「『Slinky』 SlurmとクラウドのKuber...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ3「『TrinityX』 AI時代のクラスターマネジメ...
by
PC Cluster Consortium
PDF
論文紹介:MotionMatcher: Cinematic Motion Customizationof Text-to-Video Diffusion ...
by
Toru Tamaki
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ3「IT運用とデータサイエンティストを強力に支援するH...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):エヌビディア合同会社 テーマ1「NVIDIA 最新発表製品等のご案内」
by
PC Cluster Consortium
PPTX
ChatGPTのコネクタ開発から学ぶ、外部サービスをつなぐMCPサーバーの仕組み
by
Ryuji Egashira
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):富士通株式会社 テーマ1「HPC&AI: Accelerating material develo...
by
PC Cluster Consortium
PDF
AI開発の最前線を変えるニューラルネットワークプロセッサと、未来社会における応用可能性
by
Data Source
PDF
膨大なデータ時代を制する鍵、セグメンテーションAIが切り拓く解析精度と効率の革新
by
Data Source
PPTX
2025年11月24日情報ネットワーク法学会大井哲也発表「API利用のシステム情報」
by
Tetsuya Oi
PDF
ニューラルプロセッサによるAI処理の高速化と、未知の可能性を切り拓く未来の人工知能
by
Data Source
PCCC25(設立25年記念PCクラスタシンポジウム):コアマイクロシステムズ株式会社 テーマ 「AI HPC時代のトータルソリューションプロバイダ」
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ1「大規模AIの能力を最大限に活用するHPE Comp...
by
PC Cluster Consortium
論文紹介:DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
by
Toru Tamaki
論文紹介:HiLoRA: Adaptive Hierarchical LoRA Routing for Training-Free Domain Gene...
by
Toru Tamaki
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ2「『Slinky』 SlurmとクラウドのKuber...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ3「『TrinityX』 AI時代のクラスターマネジメ...
by
PC Cluster Consortium
論文紹介:MotionMatcher: Cinematic Motion Customizationof Text-to-Video Diffusion ...
by
Toru Tamaki
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ3「IT運用とデータサイエンティストを強力に支援するH...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):エヌビディア合同会社 テーマ1「NVIDIA 最新発表製品等のご案内」
by
PC Cluster Consortium
ChatGPTのコネクタ開発から学ぶ、外部サービスをつなぐMCPサーバーの仕組み
by
Ryuji Egashira
PCCC25(設立25年記念PCクラスタシンポジウム):富士通株式会社 テーマ1「HPC&AI: Accelerating material develo...
by
PC Cluster Consortium
AI開発の最前線を変えるニューラルネットワークプロセッサと、未来社会における応用可能性
by
Data Source
膨大なデータ時代を制する鍵、セグメンテーションAIが切り拓く解析精度と効率の革新
by
Data Source
2025年11月24日情報ネットワーク法学会大井哲也発表「API利用のシステム情報」
by
Tetsuya Oi
ニューラルプロセッサによるAI処理の高速化と、未知の可能性を切り拓く未来の人工知能
by
Data Source
大規模トラフィックにどのように備えて負荷対策を実施しているのか?
1.
大規模トラフィックにどのように備えて 負荷対策を実施しているのか? 株式会社ミクシィ モンスト事業本部 開発室 室長 白川裕介
2.
自己紹介
3.
自己紹介 - 氏名 - 白川裕介 -
経歴 - 2012年に新卒でミクシィに入社。 - SNS「mixi」でアドネットワークを担当したのちXFLAGのアドテクスタジオへ異動 - その後、モンストの開発に携わりマネージャーを経験 - 現在では開発室の室長として、モンストに関わるエンジニア組織を統括
4.
モンスターストライク
5.
モンスターストライク 自分のモンスターを引っ張って弾き、敵のモンスターに当てて倒していくという、スマートフォンの特性を活用した、 誰でも簡単に楽しめるアクションRPGです。ゲームはターン制をとっており、 一緒にいる友だちと最大4人まで同時に遊べる協力プレイ(マルチプレイ)が特長です。 2013年の10月の提供開始から現在※までの世界累計利用者数5,100万人を突破 ※ 2019年07月時点 「世界累計利用者数 5,100万人を突破したスマホアプリ」
6.
モンストドリームカンパニー 「モンパニ」は、最大4人同時に遊べる協力プレイ(マルチプレイ)で、 家族や友だちとわいわい盛り上がることのできるカジュアルな「ひっぱりすごろくゲーム」です。 スマホアプリ「モンスターストライク」でおなじみのキャラクターたちが、 それぞれの特徴や能力を活かした職業に就いた姿で活躍する公式スピンオフゲームです。 「モンスト公式スピンオフゲーム ゆるっとワイワイ!ひっぱりすごろく!」
7.
アジェンダ モンストを支えるシステム アーキテクチャ構成 負荷対策について 2018年末に向けて実施した内容 2019年末に向けて実施している内容 まとめ ・ ・ ・ ・ ・ ・
8.
モンストを支えるシステム
9.
利用中のシステム • クライアント • 開発言語:
C++ • ゲームエンジン: Cocos2d-x • サーバー • 開発言語: Ruby • フレームワーク: Padrino • デプロイツール: Capistrano • 自動化ツール: Chef, Ansible, Terraform
10.
監視システム • Nagios • サーバー監視 •
kibana • ログ可視化 • CloudForecast • リソースのモニタリング • Grafana • APIリクエストなどをモニタリング
11.
アーキテクチャ構成
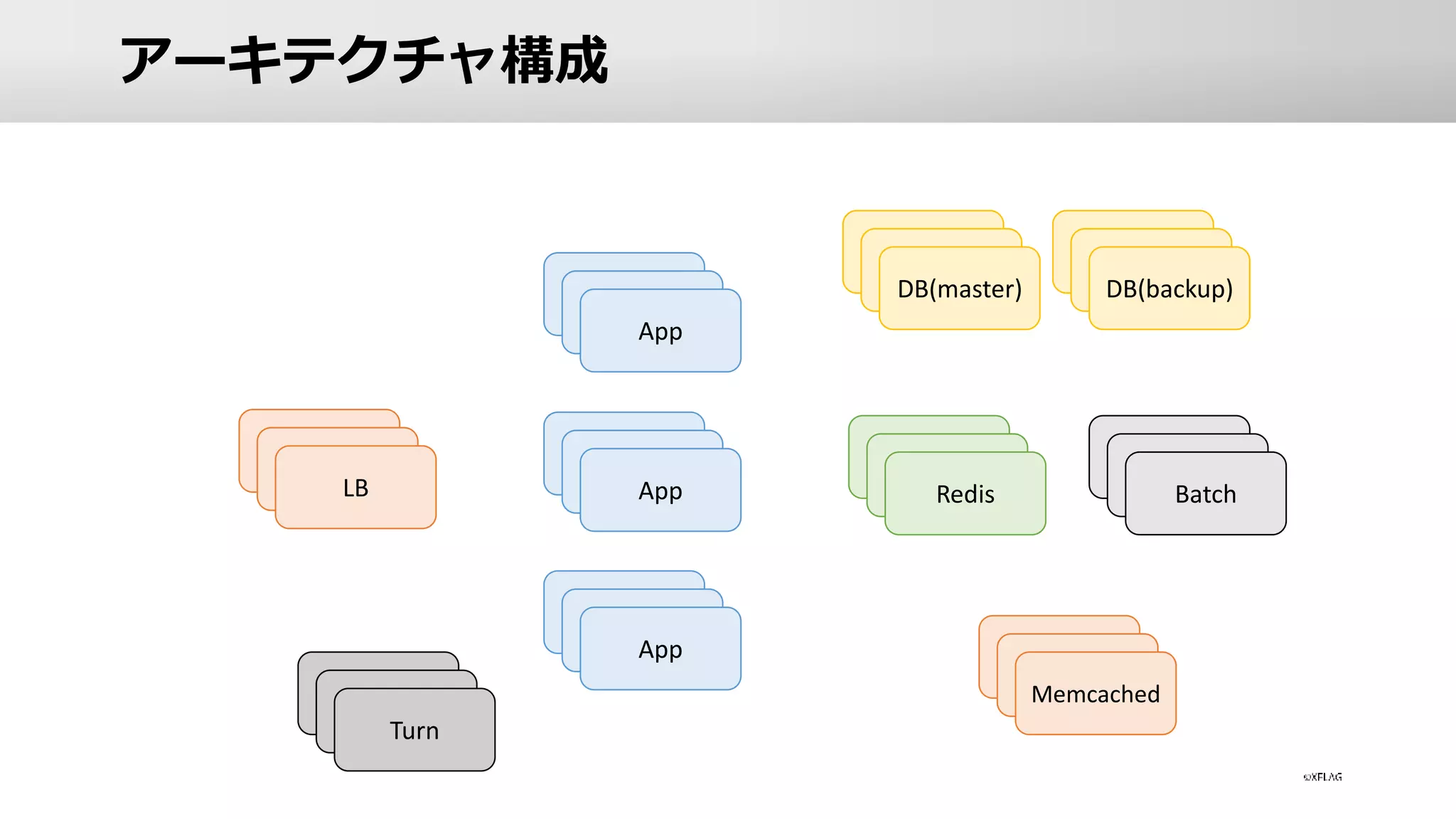
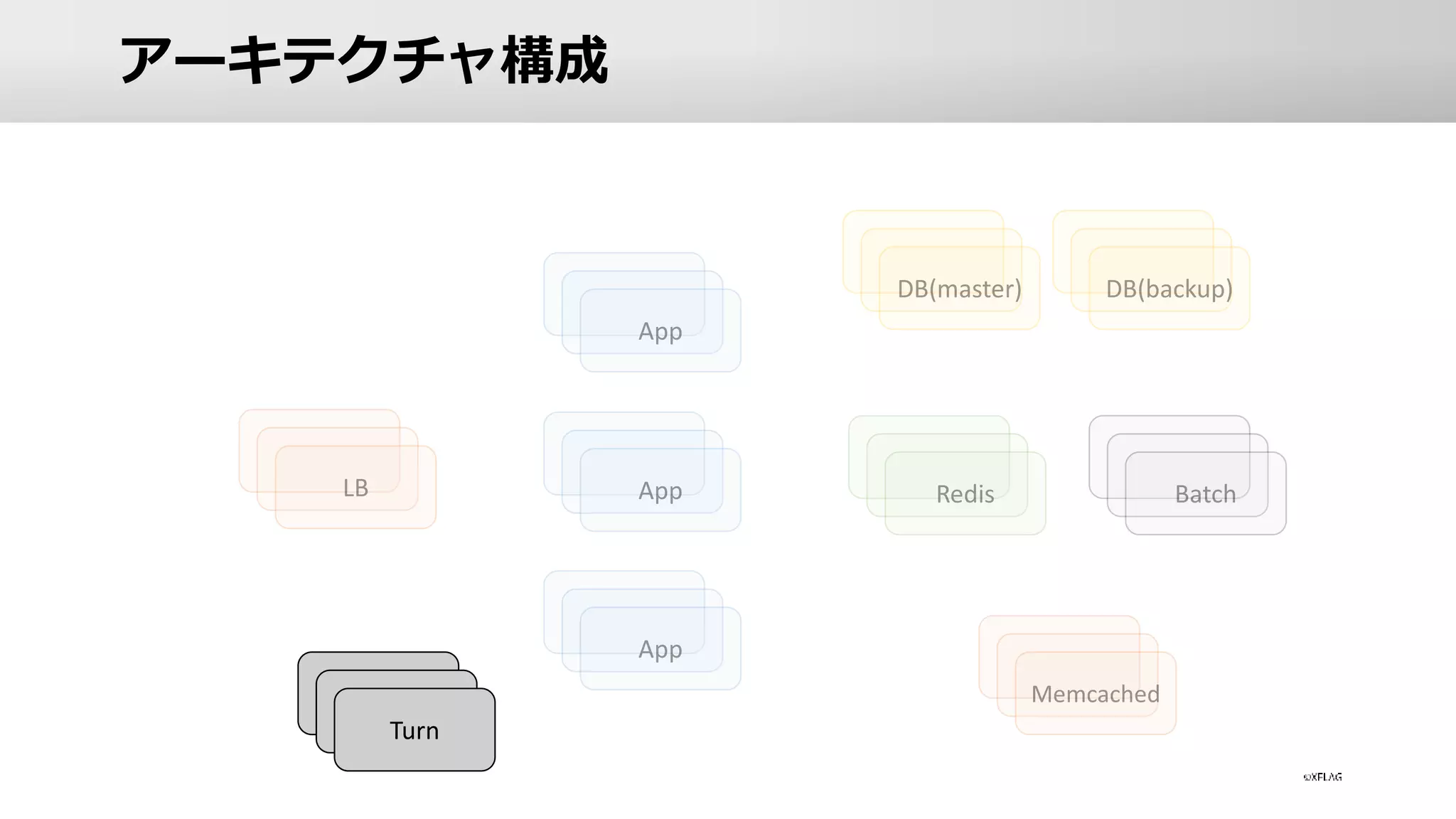
12.
アーキテクチャ構成 LB App App App DB(master) DB(backup) Redis Memcached Batch Turn
13.
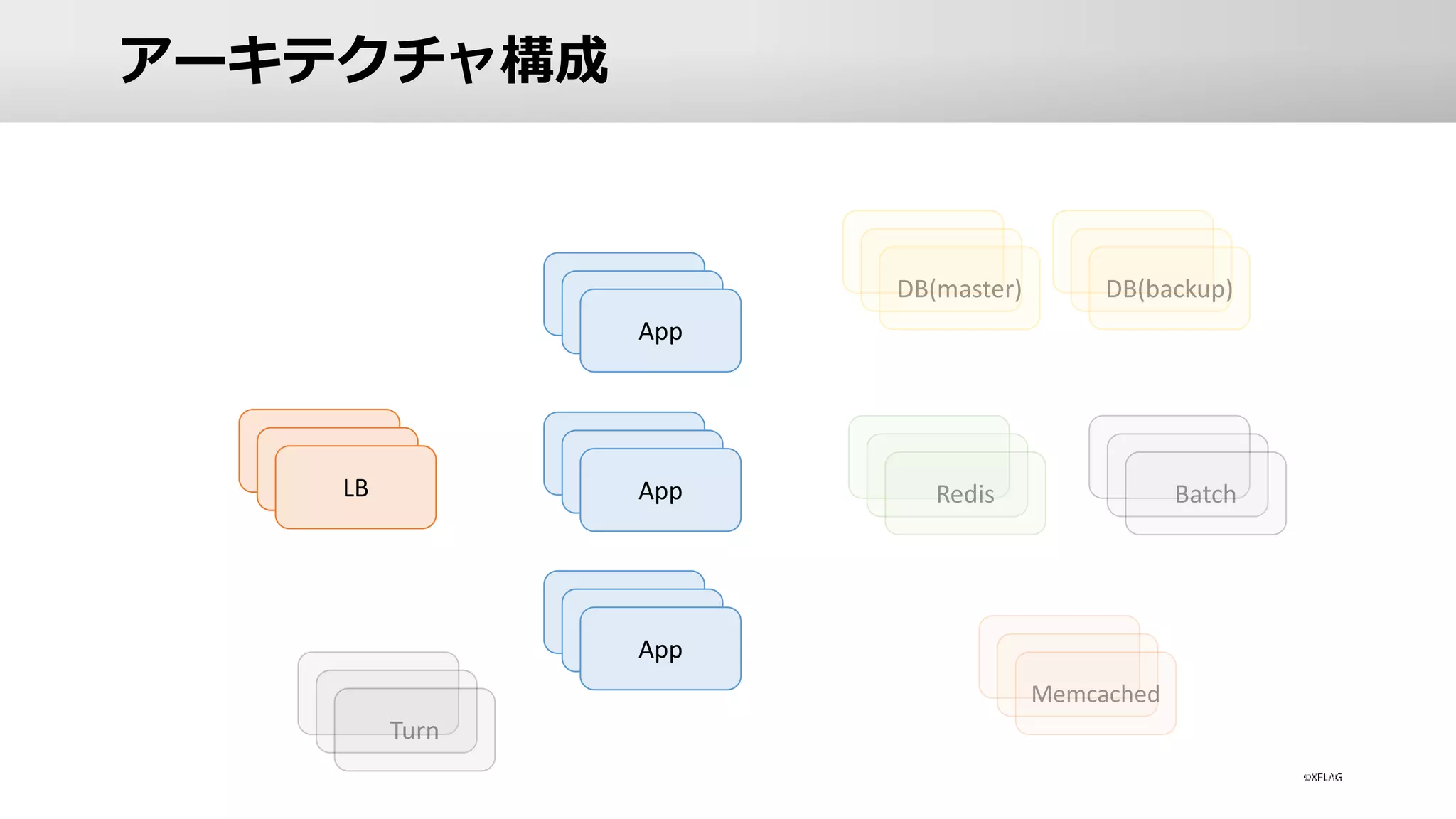
アーキテクチャ構成 LB App App App
14.
App • ロードバランサー • A10を利用し配下に約200台のAppサーバーを配置 •
Appサーバー • マルチクラウドで計算リソースの確保 • AWS / GCP / IBM を利用 • オンプレサーバーも利用 • ハイブリット構成にしている理由 • 単一点障害の回避 • 在庫の確保の柔軟性
15.
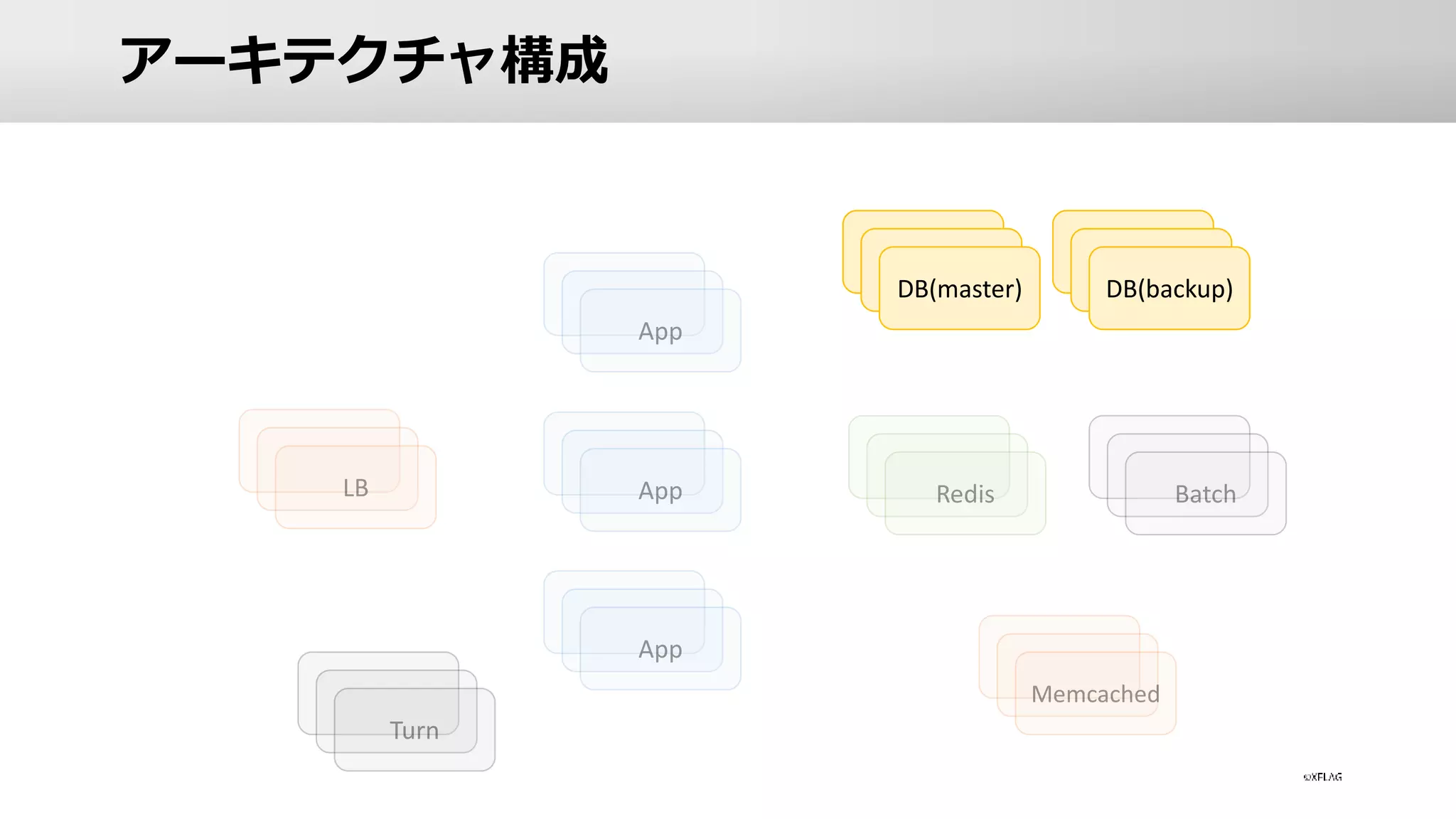
アーキテクチャ構成 DB(master) DB(backup)
16.
DB • 全てオンプレサーバーで構成 • 約300台稼働中 •
複数拠点・複数系統でサーバー故障に備える • DBサーバーへのアプローチ • 水平分割 / 垂直分割 • Indexやクエリの最適化 • 高性能なマシンを投入 (高いIO性能を出せるもの) • IOMemory / NVMeを利用
17.
DBサーバー障害への対策 • データが完全に消失しないように何重にも防衛 • DCレベルでの冗長化 •
DBサーバーは2拠点での冗長化 • DC毎に複数系統に冗長化 • master - backup構成 • 定期的にDBのSnapshotをとりクラウド上に保存 • 数週間分のbinlogのBackupを保持
18.
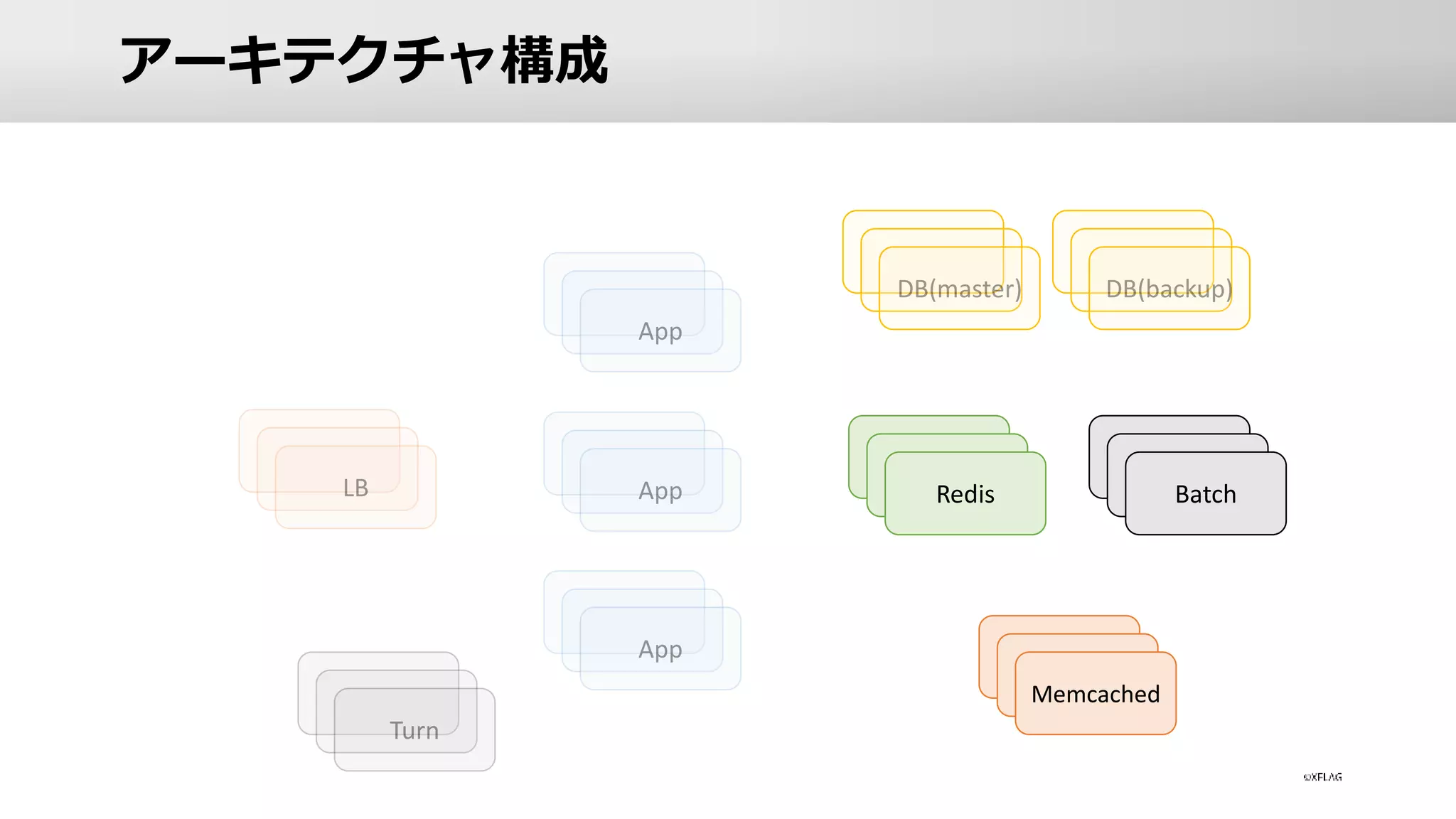
アーキテクチャ構成 Redis Memcached Batch
19.
Redis / Batch
/ memcached • Redis / Batch • Resqueを利用した非同期処理 • ミッションの達成判定や報酬付与などを非同期処理で実施 • memcached • すべてオンプレサーバーで構成 • DBサーバーとの距離を重視 • DB性能限界へのアプローチとしてCacheを用いる • モンストではCacheの比重が大きい • app <=> memcached の往復が100回を超えるAPIもある • Cacheを利用することによりレスポンスの高速化を実現 • Replica Poolを用意しサーバー障害へ対策
20.
アーキテクチャ構成 Turn
21.
マルチを実現している技術について • Turnとは • Traversal
Using Relays around NAT (TURN) • RFC5766 • http://tools.ietf.org/html/rfc5766 • 「NAT超え」を可能にするための技術 • ホスト/ゲスト間の通信はTurnサーバーを介してパケットをリレー • Turnサーバーを経由することによりNATを超えた通信を実現 • モンスターストライクのリアルタイム通信を支える技術 • https://speakerdeck.com/genkami/monsutasutoraikufalseriarutaimutong-xin-wozhi-eruji-shu
22.
アーキテクチャ構成まとめ その1 • 稼働中のサーバーはトータルで約1,000台 •
DBサーバー: 約300台、Appサーバー: 約200台 • Turnサーバーを利用しマルチプレイを実現 • パケットのリレーを行う用途 • Cacheを多用することでレスポンスの高速化 • モンストではmemecachedを利用 • Resqueを利用した非同期処理 • バックエンドはRedis
23.
アーキテクチャ構成まとめ その2 • ハイブリッド構成 •
自社DCのオンプレサーバーとクラウドサーバーの併用 • 単一点障害の回避や柔軟な在庫の確保 • サーバー障害に対して、何重もの対策を実施 • DCの冗長構成 • 2つDCを利用しDCレベルでの冗長化を実現 • memcachedのReplica Poolの用意
24.
負荷対策について
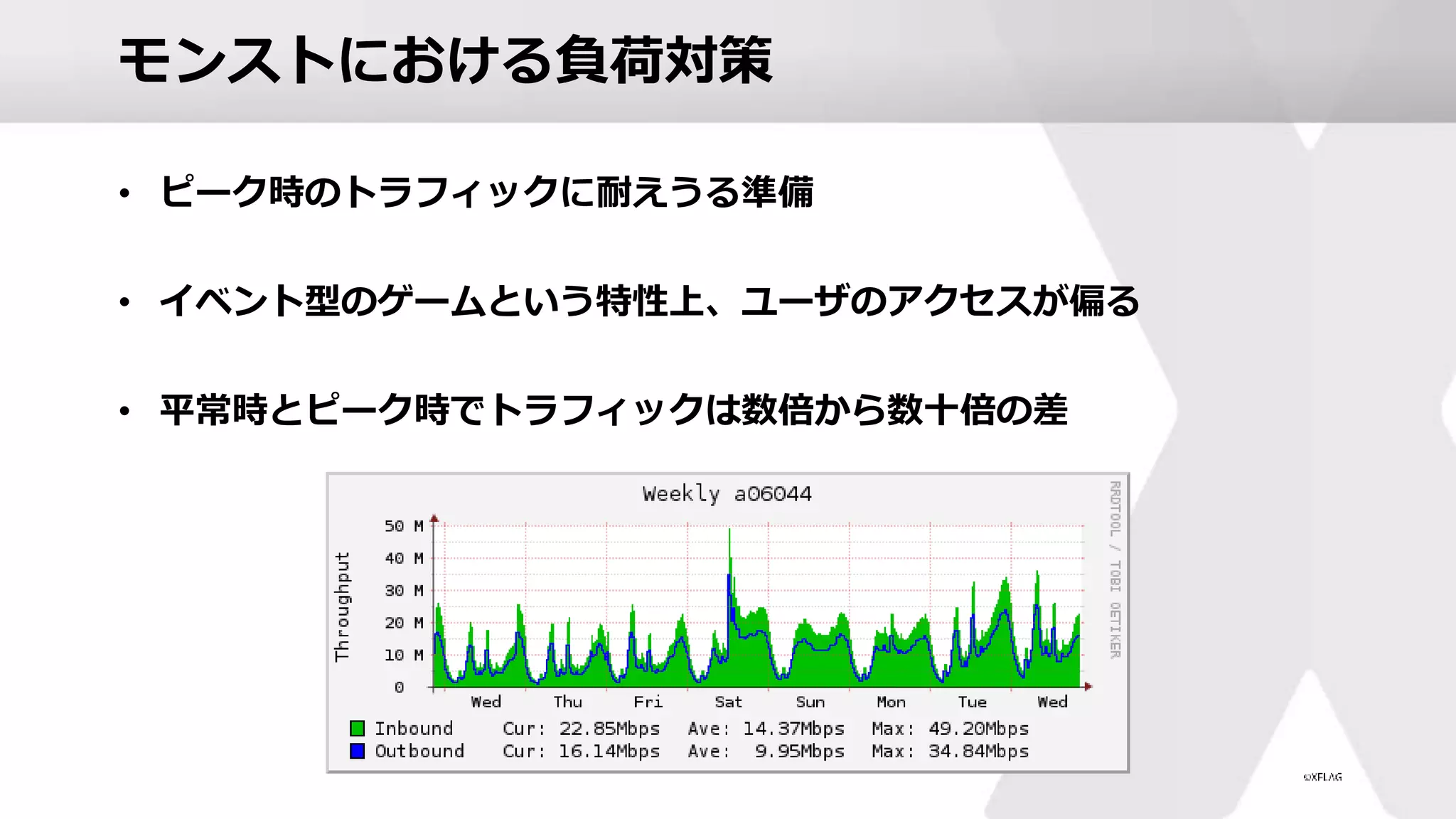
25.
モンストにおける負荷対策 • ピーク時のトラフィックに耐えうる準備 • イベント型のゲームという特性上、ユーザのアクセスが偏る •
平常時とピーク時でトラフィックは数倍から数十倍の差
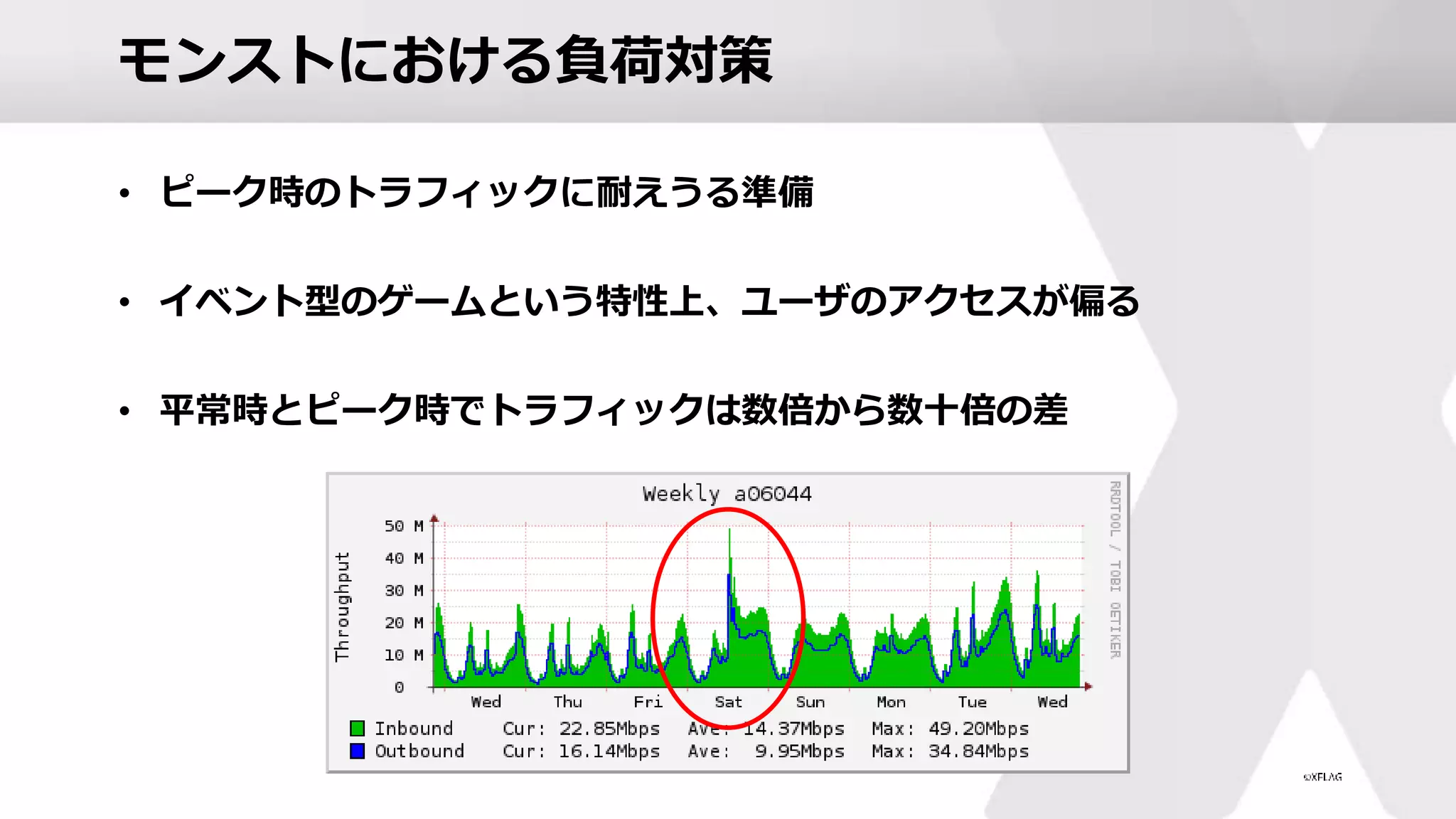
26.
モンストにおける負荷対策 • ピーク時のトラフィックに耐えうる準備 • イベント型のゲームという特性上、ユーザのアクセスが偏る •
平常時とピーク時でトラフィックは数倍から数十倍の差
27.
モンストにおける負荷対策 • アクセスの増大が予想されるタイミング • コラボ開始のタイミング •
コラボ限定のガチャやクエストが開始 • 限定クエストが開催されるタイミング • 高難易度のクエストなど • 限定アイテムが配布やキャンペーン開始タイミング • 最近のイベントだと 「30連以上確定アゲインガチャ」 • 対応 • Appサーバーのスケールアウト • 事前に負荷が想定されるDBをスケールアップ / スケールアウト
28.
Appサーバーの負荷対策 • Appサーバーをスケールアウト • モンストではAppサーバーをCPUのコア数換算で試算 •
1コアあたりUnicornのworker数を1としている • 例: 64コアのマシンならworker数は64となるように設定 • Appサーバーが増えると同時に処理できるリクエストの数が増加 • デメリット • DBへのアクセスも増えるためDBへの負荷が増加 • 通信量が増えるためネットワークのトラフィックが増加 • 台数を多く並べれば並べるほどよいというわけではない
29.
DBサーバーの負荷対策 • スケールアップ • 負荷が高くなりそうなDBサーバーを高性能なマシンに入れ替え •
IOMemory / NVMe (高いIO性能を出せるもの) • スケールアウト • 垂直分割(vertical partitioning) • 一部のテーブルを別のDBへ移動 • 水平分割 (horizontal partitioning) • 1つのテーブルの各行を別々のテーブルへ分散 • モンストではシャーディングを用いて実施
30.
シャーディング • シャーディングとは? • 特定のアルゴリズムに従いデータを複数のDBに分散させる手法 •
その結果DBへのアクセスを分散させることが可能 • モンストにおけるシャーディングを用いた負荷分散手法 • https://speakerdeck.com/haman29/bcu-30-server-9
31.
昨年の年末について
32.
年末年始のモンスト • 年越しと共にアクセスが急増しピークを迎える • 主に0時から始まる新ガチャがメイン •
年越しのタイミングでログイン処理が急増 • そしてガチャが回される • 負荷の傾向 • APIリクエストが滞留 • データベースでslowクエリが多発 • 膨大なリクエストを捌き切ることができない
33.
2018年の年末に向けての取り組み • 2017年は緊急メンテは未実施とはいえ • 快適なサービスの提供はできていない •
振り返るともっとやれたことはあった • 2018年はやれることは全部やる • やっておけばよかったという後悔はしない • これまで負荷対策としては実施しなかったアプリケーションの最適化 • クライアントエンジニアも負荷対策に巻き込む
34.
2018年の年末に向けて • アプリケーションからのアプローチ • クライアント
/ サーバー双方からのアプローチ • インフラからのアプローチ • 年末に向けて機器調達や回線増強 • サーバー機器のスケールアップ • これまでの負荷対策のメイン • これまでの年末年始の結果 • 2016年はサーバー負荷による緊急メンテを実施 • 2017年は2時間程度アクセスが重い状況
35.
アプリケーションからのアプローチ
36.
アプリケーションからのアプローチ • ピーク時はログインで詰まる • 年越しでログインするユーザが急増 •
年越しのタイミングでユーザはタイトルに戻る • タイトルに戻らなくてもゲーム内の表示は更新されるのだが • ログイン時に走るリクエストはモンスト内でも負荷が高いものが多い • ボトルネック部分を見つけ出し対処する箇所を決定 • ログイン時のフローを大幅に改修 • ログイン時に必要なAPIを高速化 これまでの傾向からこれら2つを対応することに決定
37.
アプリケーションからのアプローチ 1. ログイン時のフロー大幅に改修 • モンストはログイン時(ゲーム起動時)にデータを一気に取得 •
起動後の画面遷移等を早くするため • ログイン時の処理はリリースから5年間積み上がっている • 改修はほとんど実施されていない • 今回はログイン時のフローに手を入れる
38.
アプリケーションからのアプローチ • 現状のログイン時のフローを整理から始める • ログイン時に必要なAPIの数 •
アプリ起動からホーム画面への遷移で13回もAPIリクエストが発生 • 13回のリクエストがすべて成功した場合のみOK • 1つでも失敗すると最初からやりなおし
39.
アプリケーションからのアプローチ • 結果 • ログイン時に必要ないAPIの呼び出しをやめる •
ログイン時に13本必要だったAPIを3本にまとめる • 効果 • 高負荷時のログイン成功確率が増加 • APIリクエスト数が減るので成功確率も上がる • また通常時もログイン失敗する確率が激減 • 必要なネットワーク帯域が減少 • 一方でログイン時の処理が遅くなるデメリット • これまでは13本のリクエストを並列実行していた
40.
アプリケーションからのアプローチ 2. App timeの長いAPIを高速化 •
ログイン時に必要なAPIで致命的に遅いものが存在 • 高負荷時には指数関数的に遅くなる • そのAPIの名は deck/get • ユーザの所持しているキャラクターを全部取得する • 最大で約5,000体所持可能 • モンストでは起動時にユーザの所持するモンスターを再取得
41.
アプリケーションからのアプローチ • キャラクターに付随する情報を全所有キャラで検索 • 1ユーザで最大5体のみ所持可能な情報 •
多くても100体程度しか保持していない情報 • 対応 • 事前に付加情報を持つキャラリストを作成し保持 • 取得した全キャラクターと照らし合わせてつなぎ合わせる
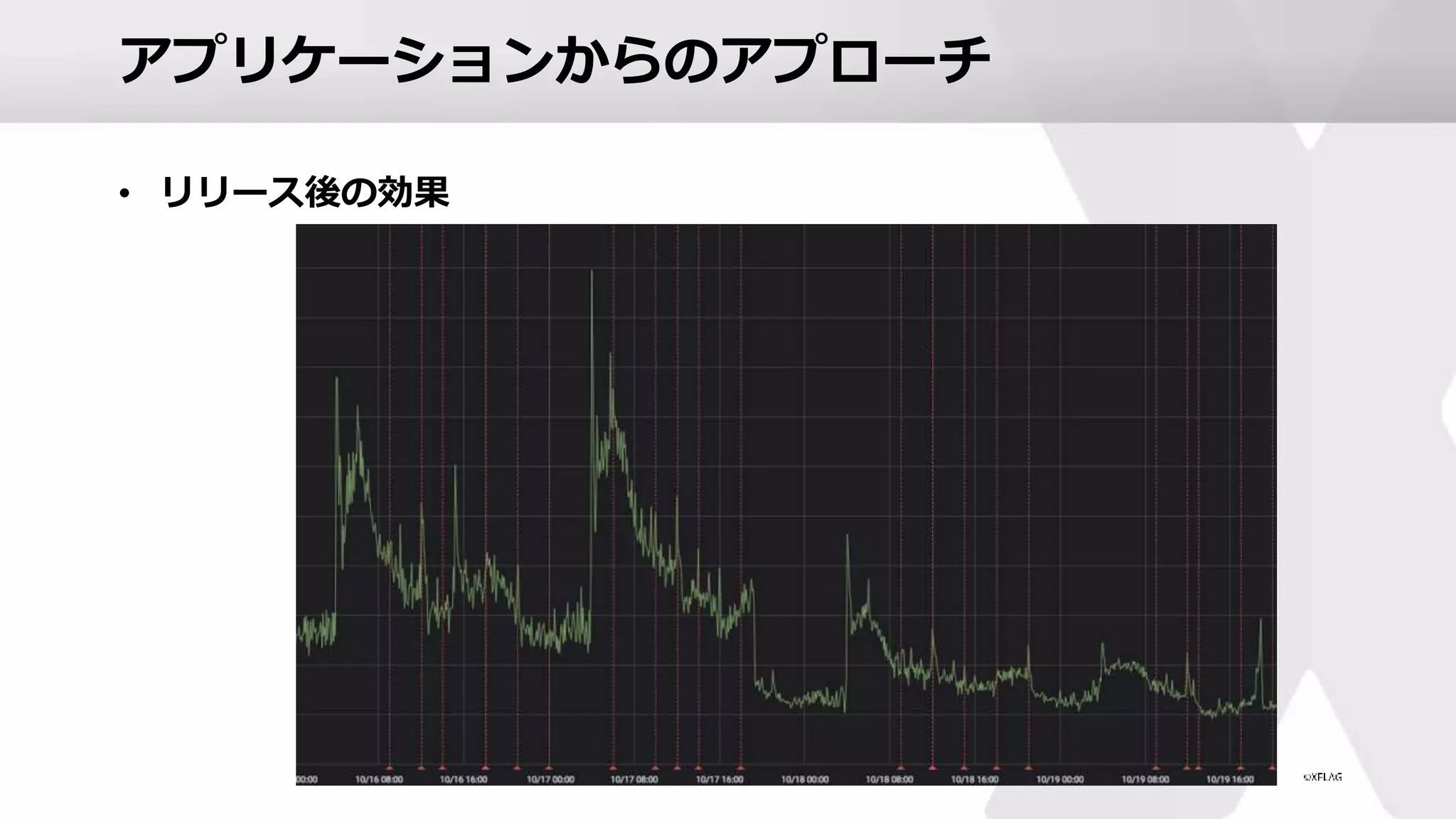
42.
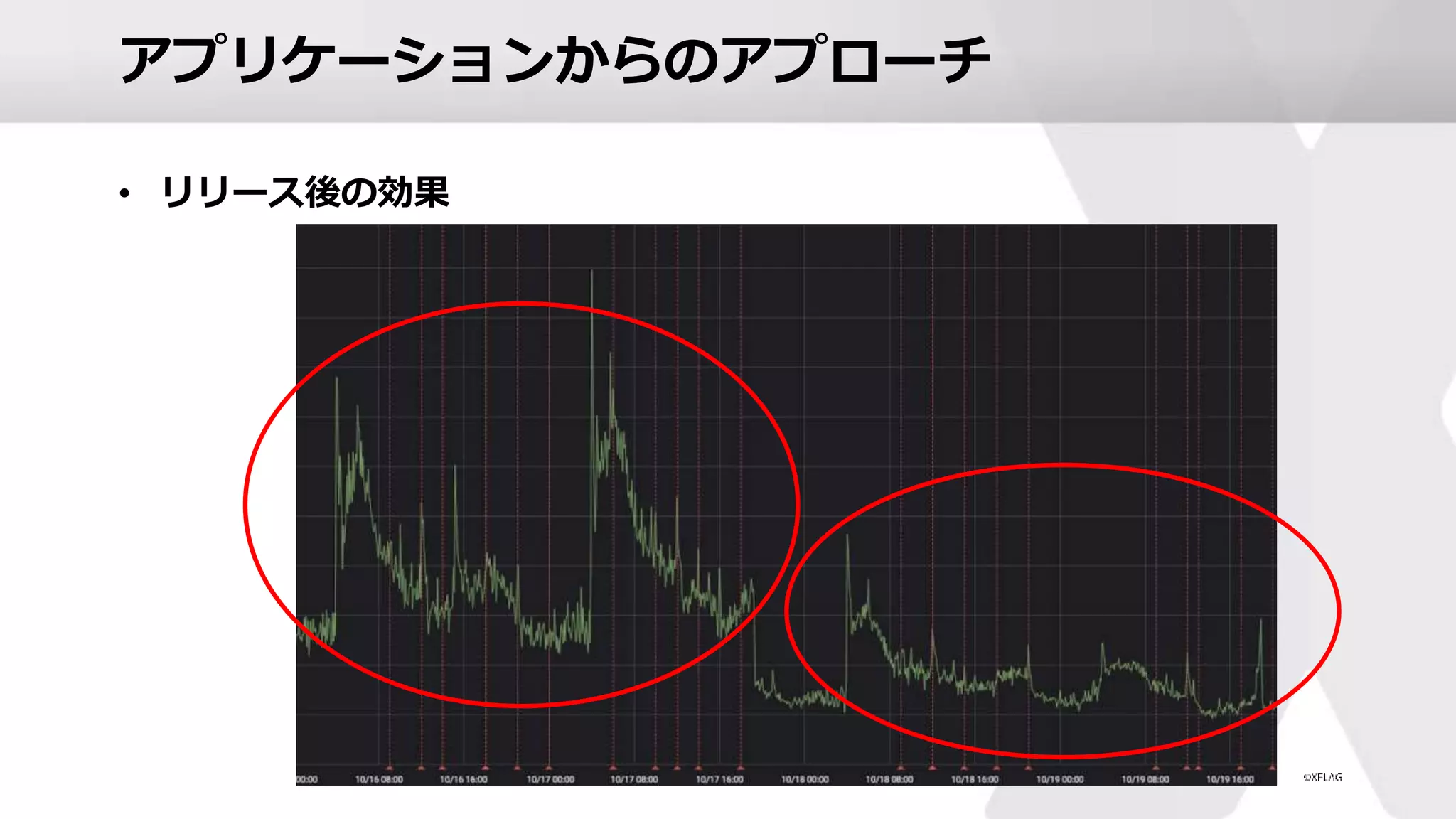
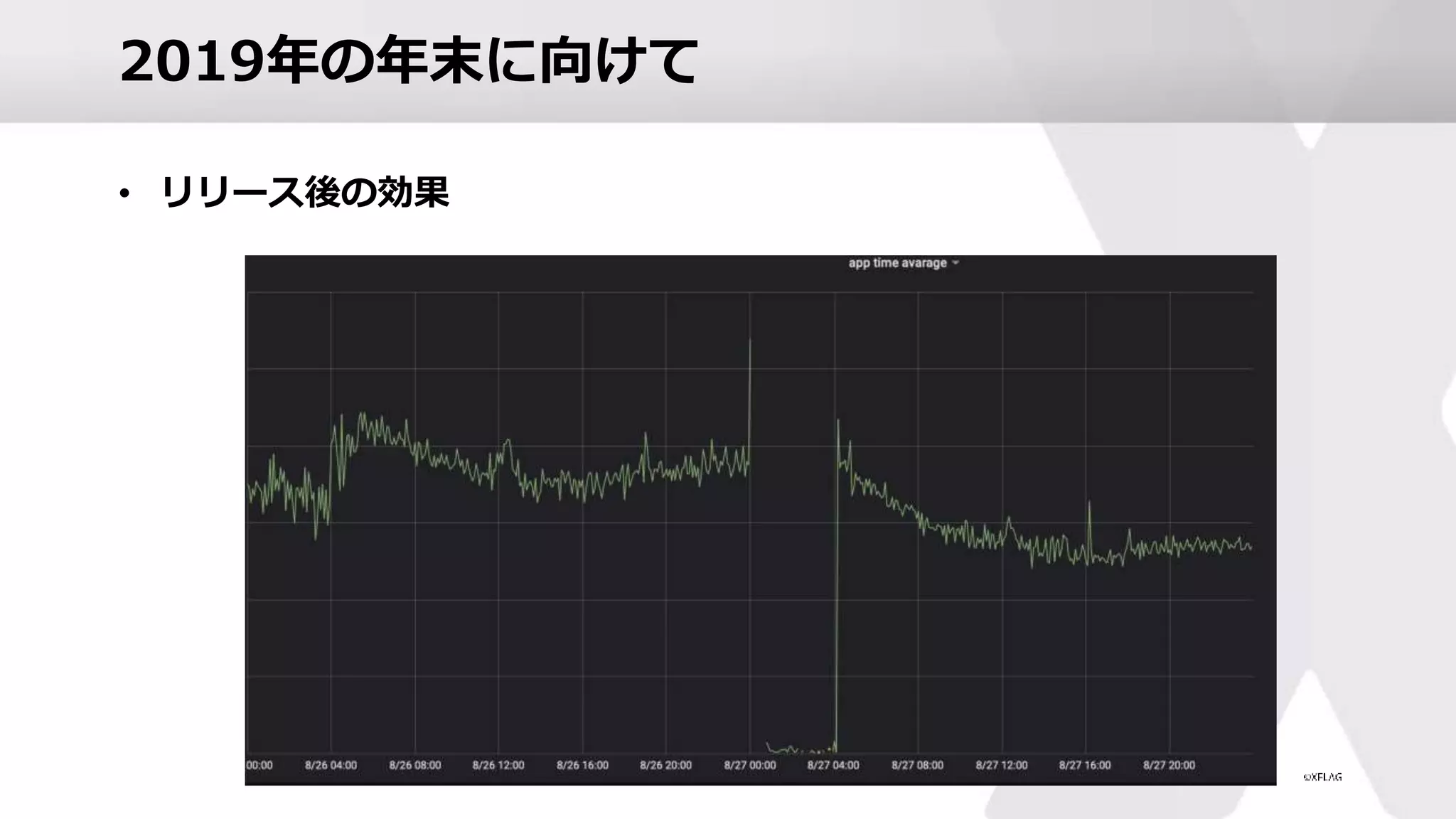
アプリケーションからのアプローチ • リリース後の効果
43.
アプリケーションからのアプローチ • リリース後の効果
44.
インフラからのアプローチ
45.
インフラからのアプローチ • 通常時のappサーバー • CPUコア数換算で12,000core •
モンストのシステム構成はmemcachedを多用 • memcachedはすべて自社DCのサーバーで運用 • 1つのリクエストで何度もサーバー間の通信が発生 • 自社DCとの物理的距離が大きく影響 • クラウド事業者の選定ではレイテンシーを最重要視 • 複数のクラウド事業者を利用 • 柔軟なリソースの確保が可能 • 障害発生時のリカバリーが可能
46.
インフラからのアプローチ • Appサーバーの増強がメイン • リソースの状況 •
オンプレサーバーの増強 • DBやmemcachedとの距離が最短 • クラウドサーバーのリソース確保 • 自社DCとの距離が比較的近い IBM/GCPなど • ネットワーク帯域の増強 • 各クラウド事業者と弊社DCとの間の専用回線 • 対応 • 年末に向けては 26,000コア を目標 • max connectionの上限近くまで確保
47.
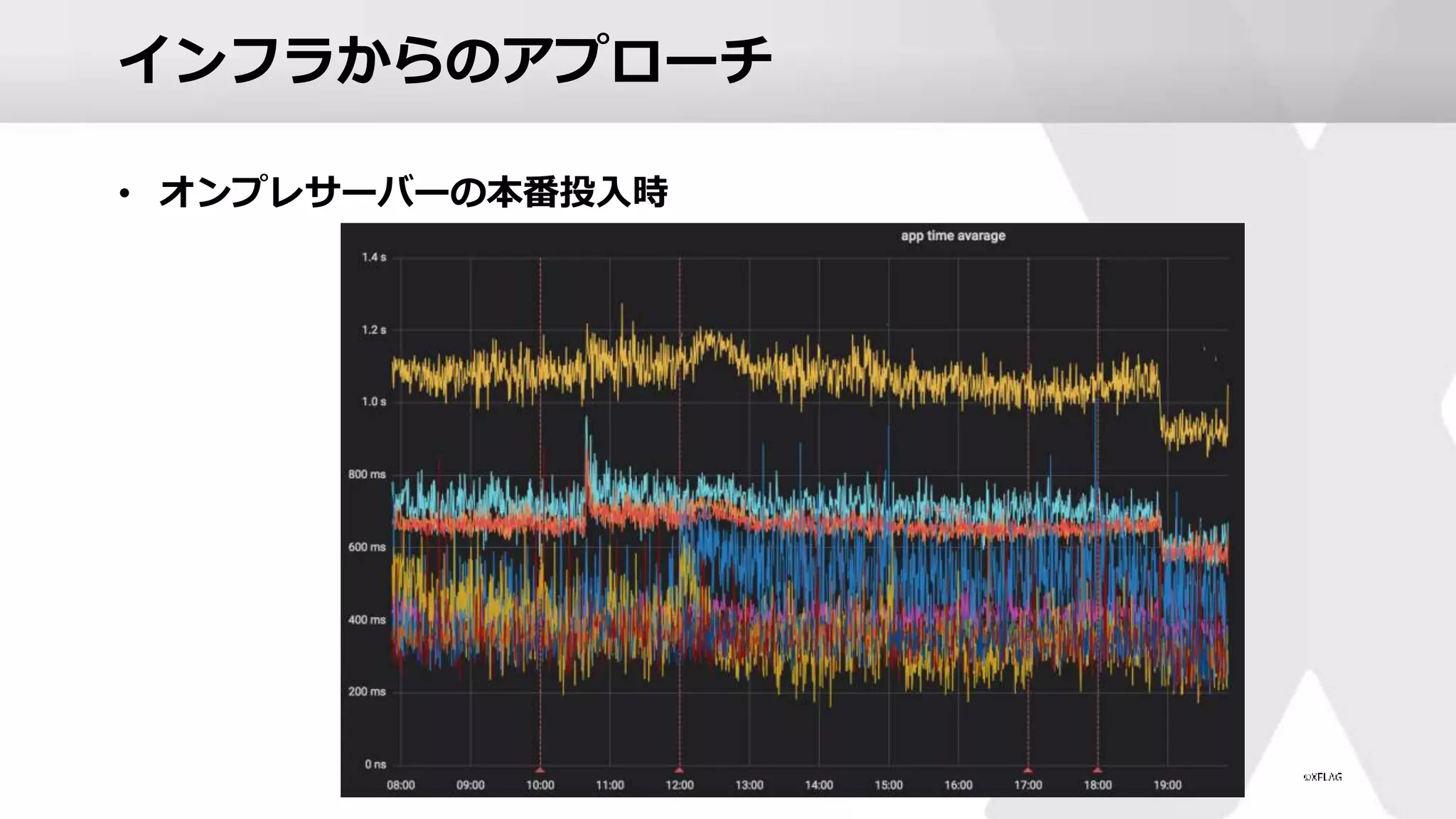
インフラからのアプローチ • オンプレサーバーの本番投入時
48.
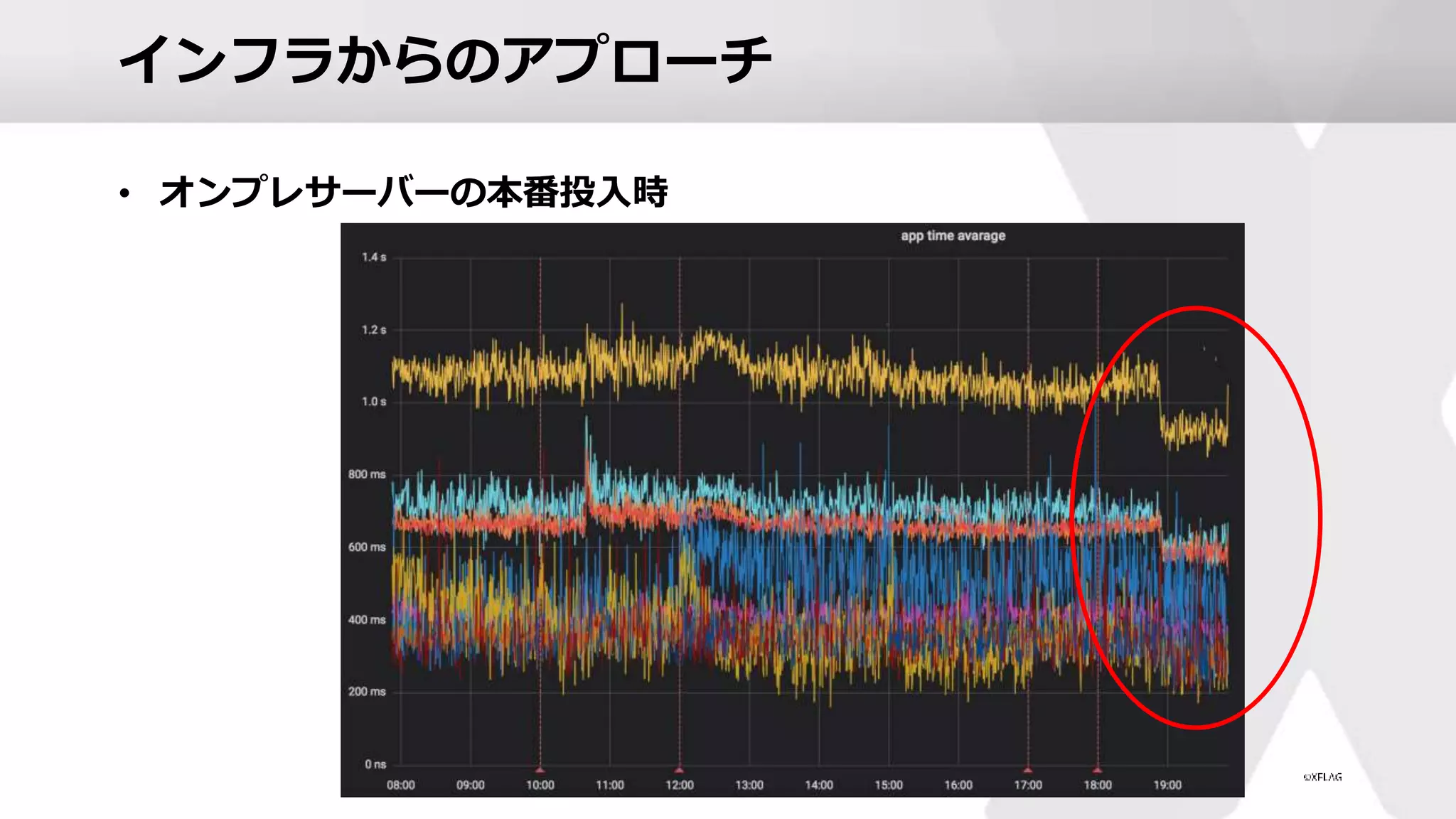
インフラからのアプローチ • オンプレサーバーの本番投入時
49.
結果
50.
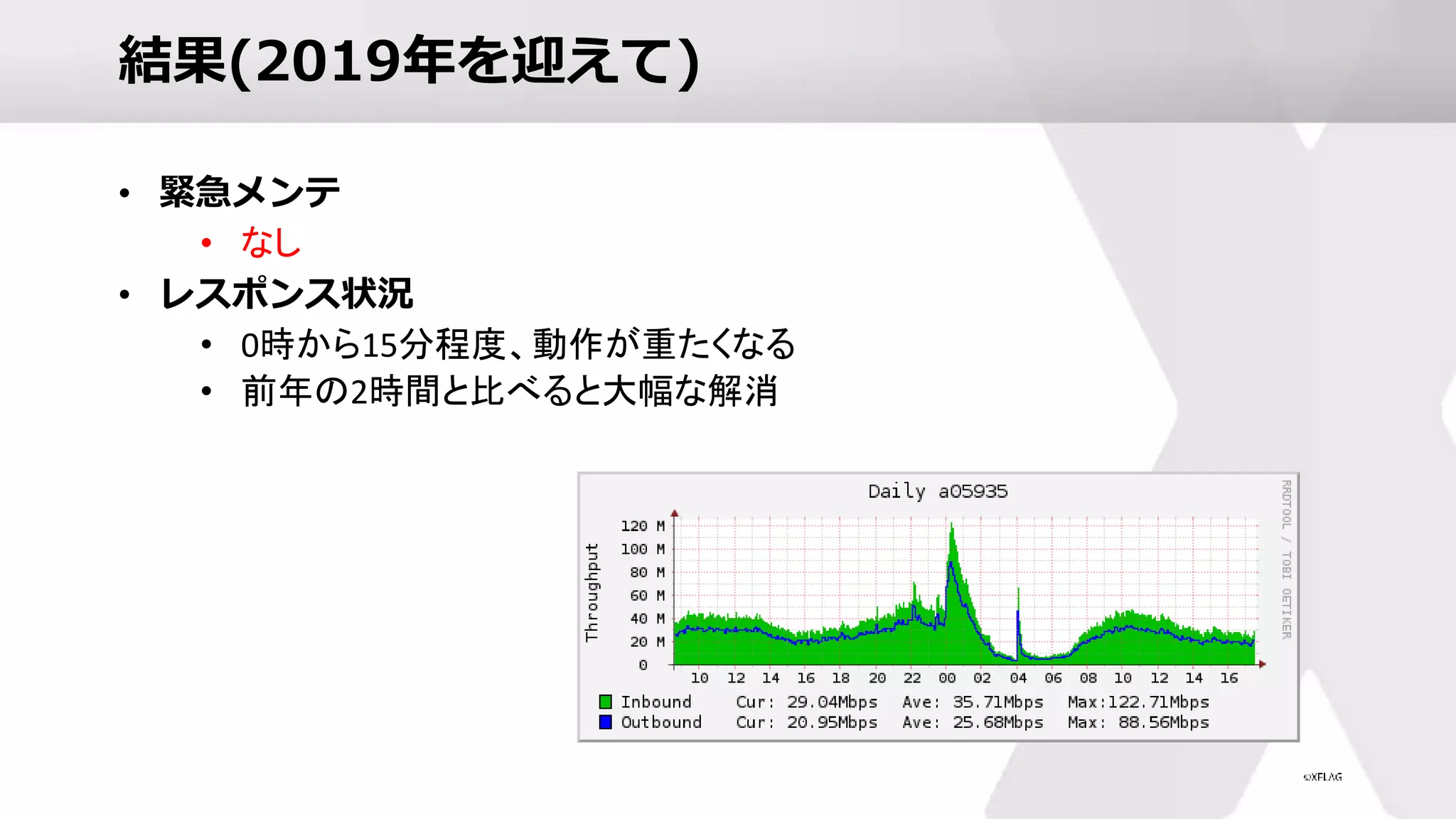
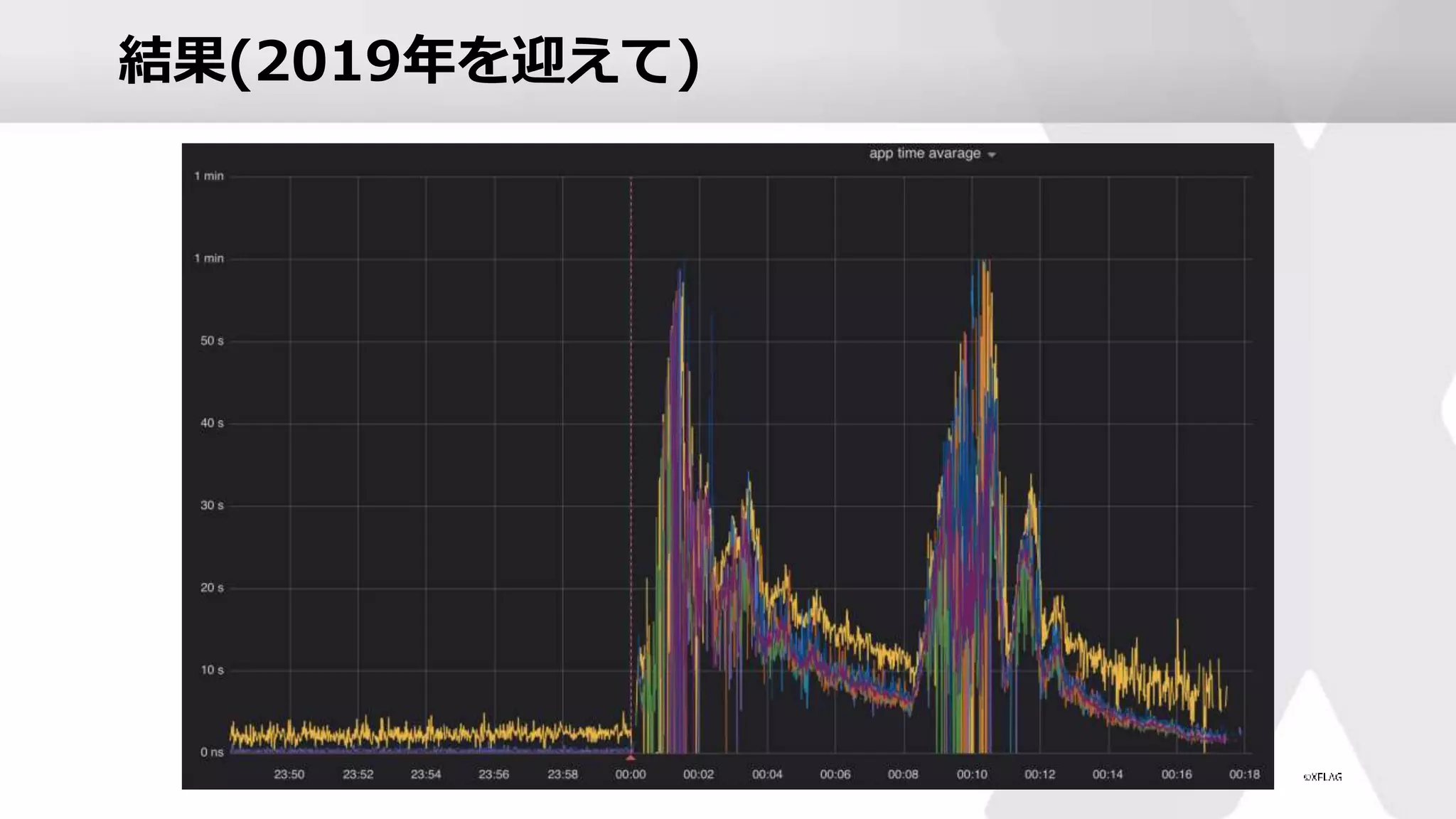
結果(2019年を迎えて) • 緊急メンテ • なし •
レスポンス状況 • 0時から15分程度、動作が重たくなる • 前年の2時間と比べると大幅な解消
51.
結果(2019年を迎えて)
52.
2019年末に向けて
53.
2019年の年末に向けて • さらなるAPIの高速化に向けて • フレンド一覧の取得の改善 •
ログイン時に必要な情報だけに絞る • フレンドに付随するユーザデータ • フレンドの助っ人キャラ一覧など • 必要なタイミングで必要な情報を取得する • フレンド一覧/助っ人一覧を表示するタイミングで取得
54.
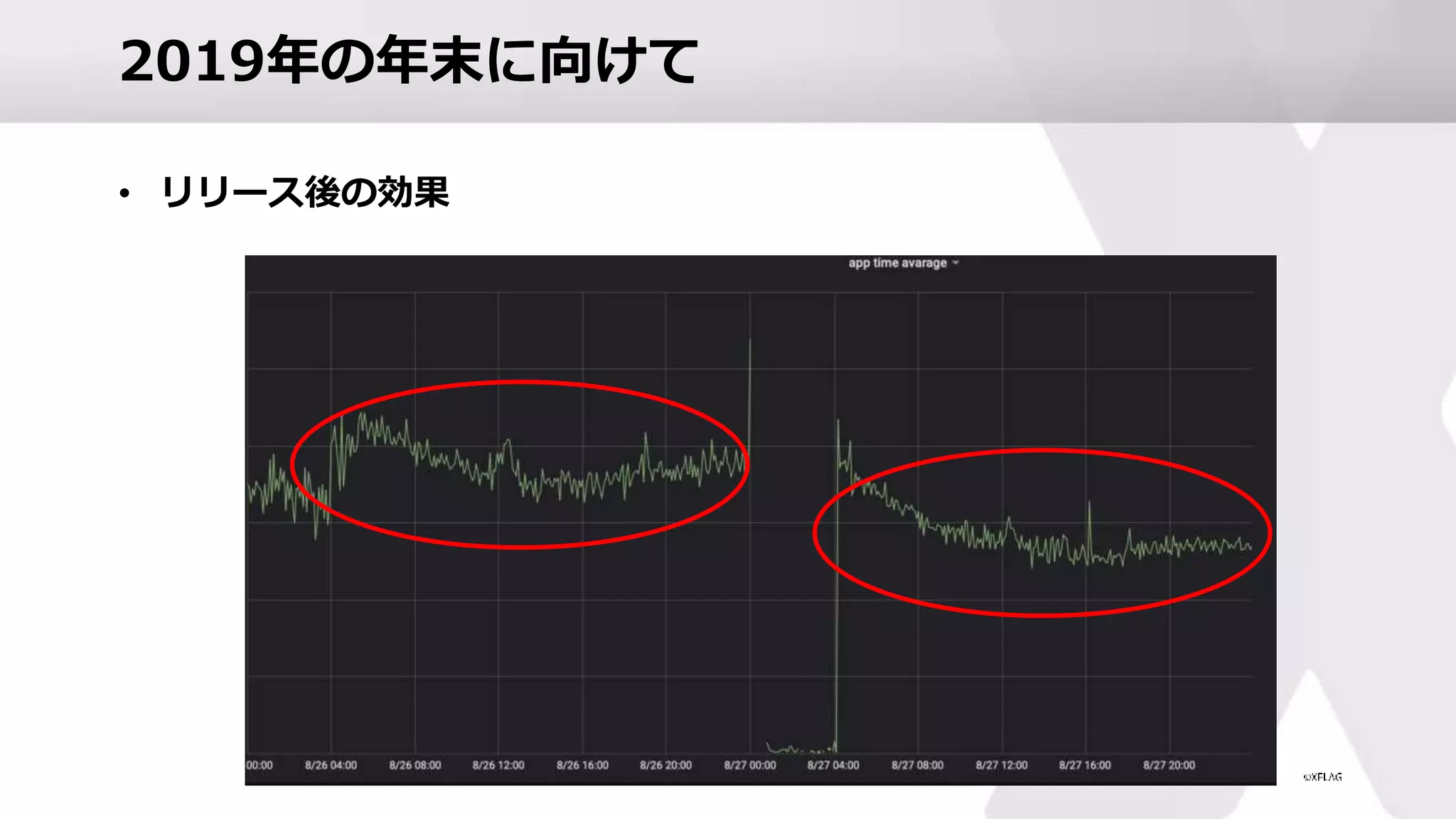
2019年の年末に向けて • リリース後の効果
55.
2019年の年末に向けて • リリース後の効果
56.
ログインフローの改善 • deck/getのさらなる改善 • モンスターの全件取得から差分取得に変更 •
前回取得時からの差分を取得 • 変更のあったモンスターのみの取得 • 差分取得にすることによりクライアントの処理も軽減
57.
まとめ • 起こっている現象をしっかりと分析 • ボトルネックとなっている箇所を修正 •
基本的な負荷対策や修正をしっかり行うことが大事 • 負荷対策の方法は色々ある • Appサーバーの増強 / DBサーバーの増強、分散 • サーバーアプリケーションの改善 • クライアントの改善 特別なことは何もなく当たり前のことをしっかりと実行していく
58.
まとめ 基本的なことを当たり前に実行できるチームが良いチーム
Editor's Notes
#13
CDNについて追加してもいいかも
#14
CDNについて追加してもいいかも
#58
ほぼ全て書き直す
Download


















































![スマホゲームのチート手法とその対策 [DeNA TechCon 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/techcon2019funakubo-190218065153-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://cdn.slidesharecdn.com/ss_thumbnails/gke02-200121091040-thumbnail.jpg?width=640&height=640&fit=bounds)



![[AWS Summit 2012] クラウドデザインパターン#5 CDP バッチ処理編](https://cdn.slidesharecdn.com/ss_thumbnails/aws-summit-cdp-05-121001104857-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[AWS Summit 2012] クラウドデザインパターン#7 CDP キャンペーンサイト編 (Wordpress)](https://cdn.slidesharecdn.com/ss_thumbnails/aws-summit-cdp-07-121002233247-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




























