6.5.1 Using IF-THENRules for Classification
適合ルールが存在しない時のクラス推測方法
Default rule
条件部は空
⇒どのルールも適用されなかった時に,最終的に適用される
Default class を特定するために用いられる(トレーニングセットに基
づく)
Default class は多数あるクラスのひとつや,どのルールもカバーし
ていないタプルの多数派のクラスの可能性もある
8
9.
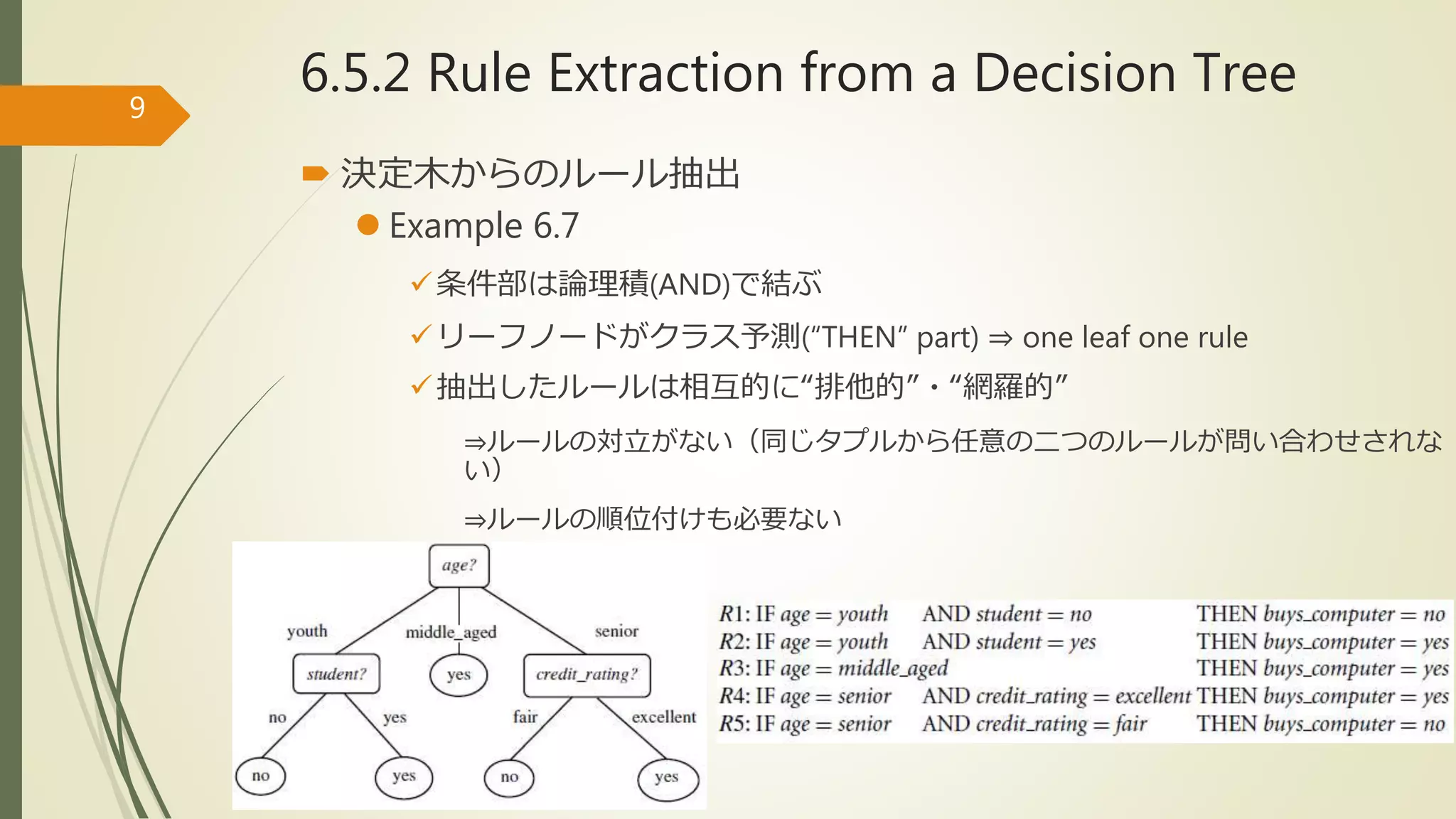
6.5.2 Rule Extractionfrom a Decision Tree
決定木からのルール抽出
Example 6.7
条件部は論理積(AND)で結ぶ
リーフノードがクラス予測(“THEN” part) ⇒ one leaf one rule
抽出したルールは相互的に“排他的”・“網羅的”
⇒ルールの対立がない(同じタプルから任意の二つのルールが問い合わせされな
い)
⇒ルールの順位付けも必要ない
9
10.
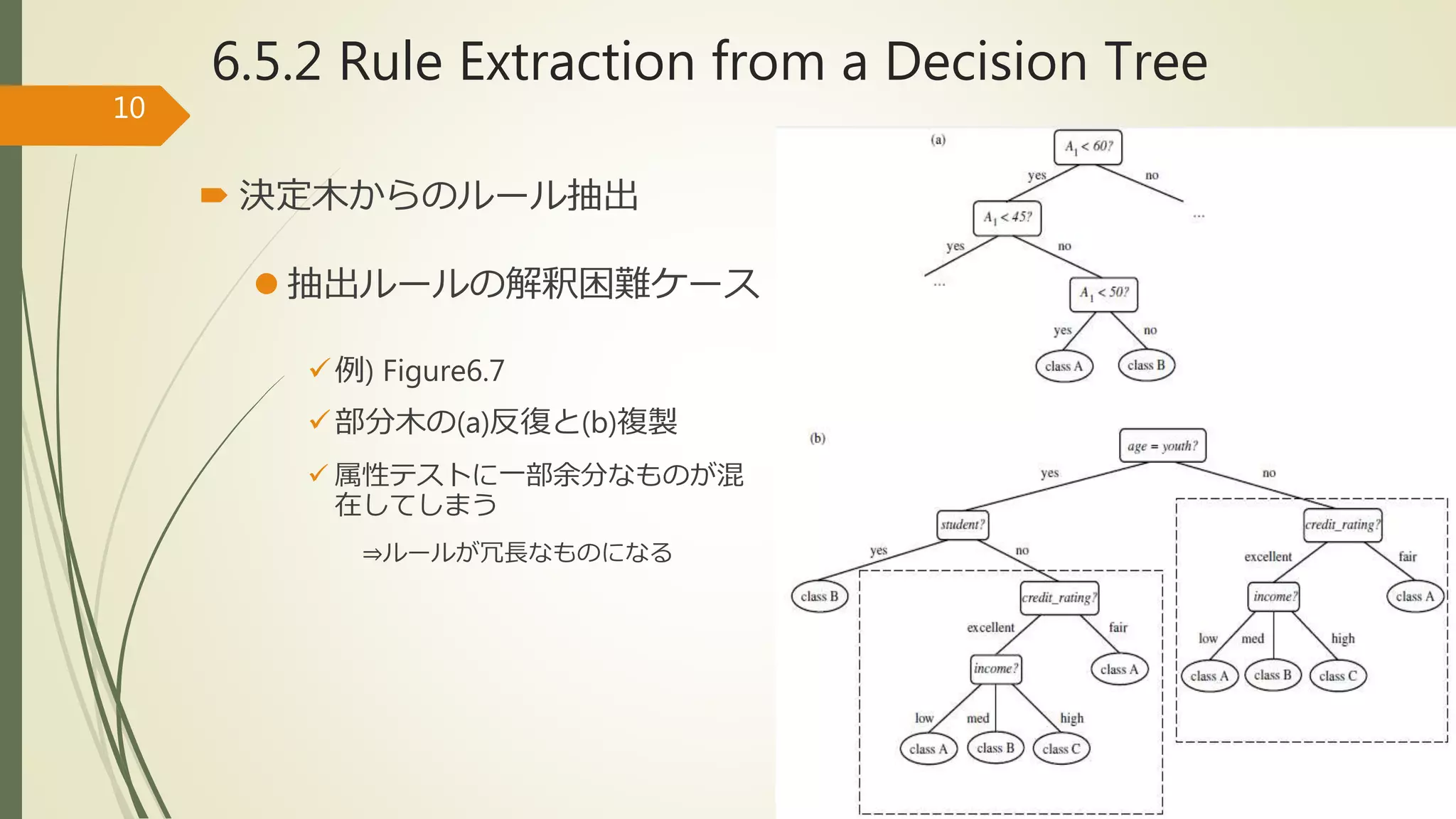
6.5.2 Rule Extractionfrom a Decision Tree
決定木からのルール抽出
抽出ルールの解釈困難ケース
例) Figure6.7
部分木の(a)反復と(b)複製
属性テストに一部余分なものが混
在してしまう
⇒ルールが冗長なものになる
10
11.
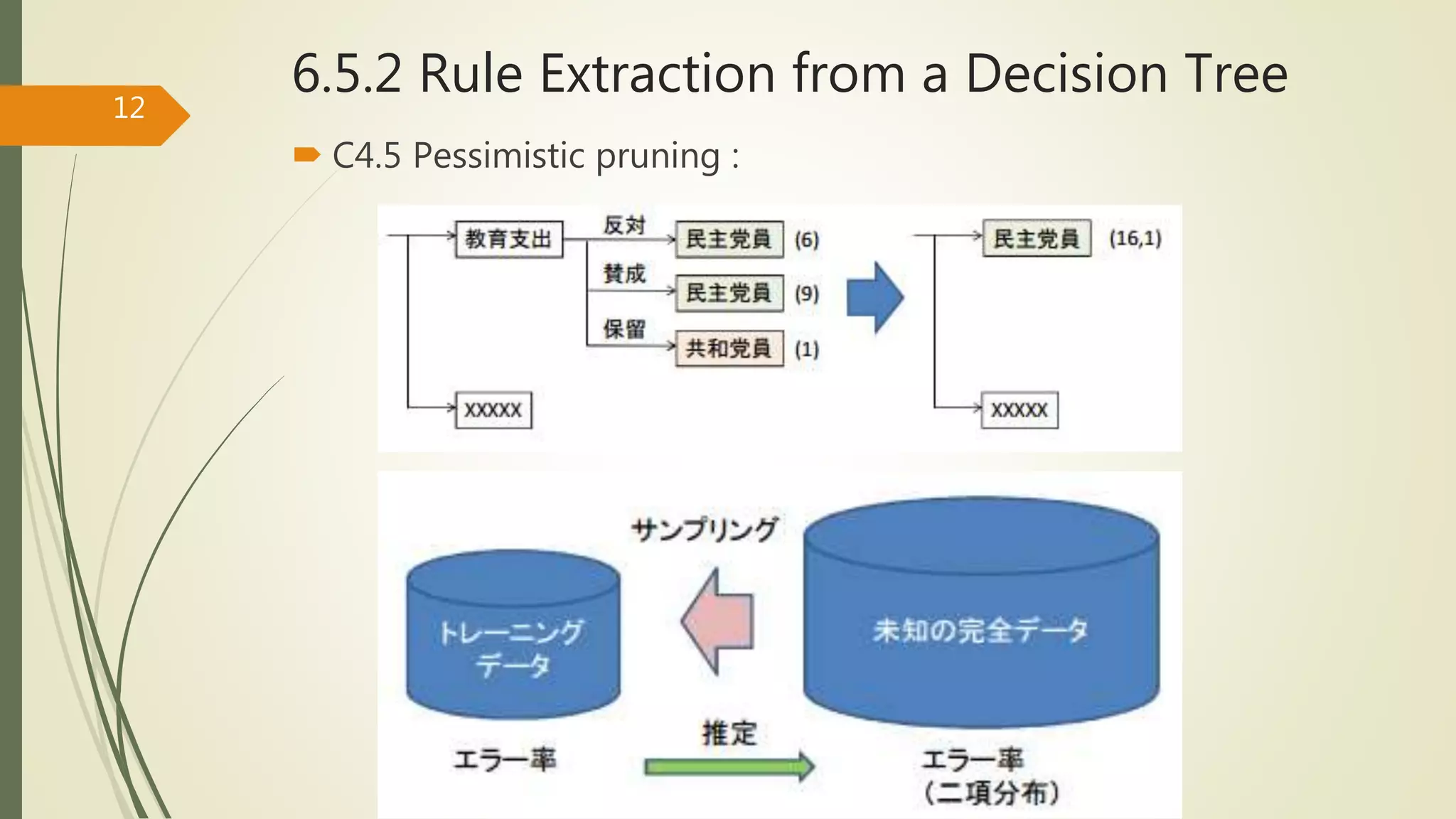
C4.5 ではpessimistic pruning を採用
Pessimistic pruning :
終端ノードに含まれる n 個のデータを母集団から取り出した
サンプルとみなし,そのサンプルのエラー率から母集団のエ
ラー率を統計的に推定し,その推定値に基づいて枝刈りを行う
手法.
枝刈りの基準を決めるパラメータとして,危険率 (信頼度) が
あり,危険率が小さいほど多く枝刈りが行われる.C4.5 では
危険率 0.25 が一般的に用いられる.
11
6.5.2 Rule Extraction from a Decision Tree
12.
C4.5 Pessimisticpruning :
12
6.5.2 Rule Extraction from a Decision Tree
13.
枝切りを行うことによって新たな問題発生
ルールの相互的排他性・網羅性が崩れてしまう可能性がある
上記を防ぐために,C4.5ではclass-based ordering schemeを採
用
class-based ordering scheme :
最初にクラスごとにルールセットを作成する
FPエラー(クラスCに分類されたが,実際はクラスCではない)
が小さいクラスが優先度が高い
FPエラーが高いクラスから枝切り
13
6.5.2 Rule Extraction from a Decision Tree
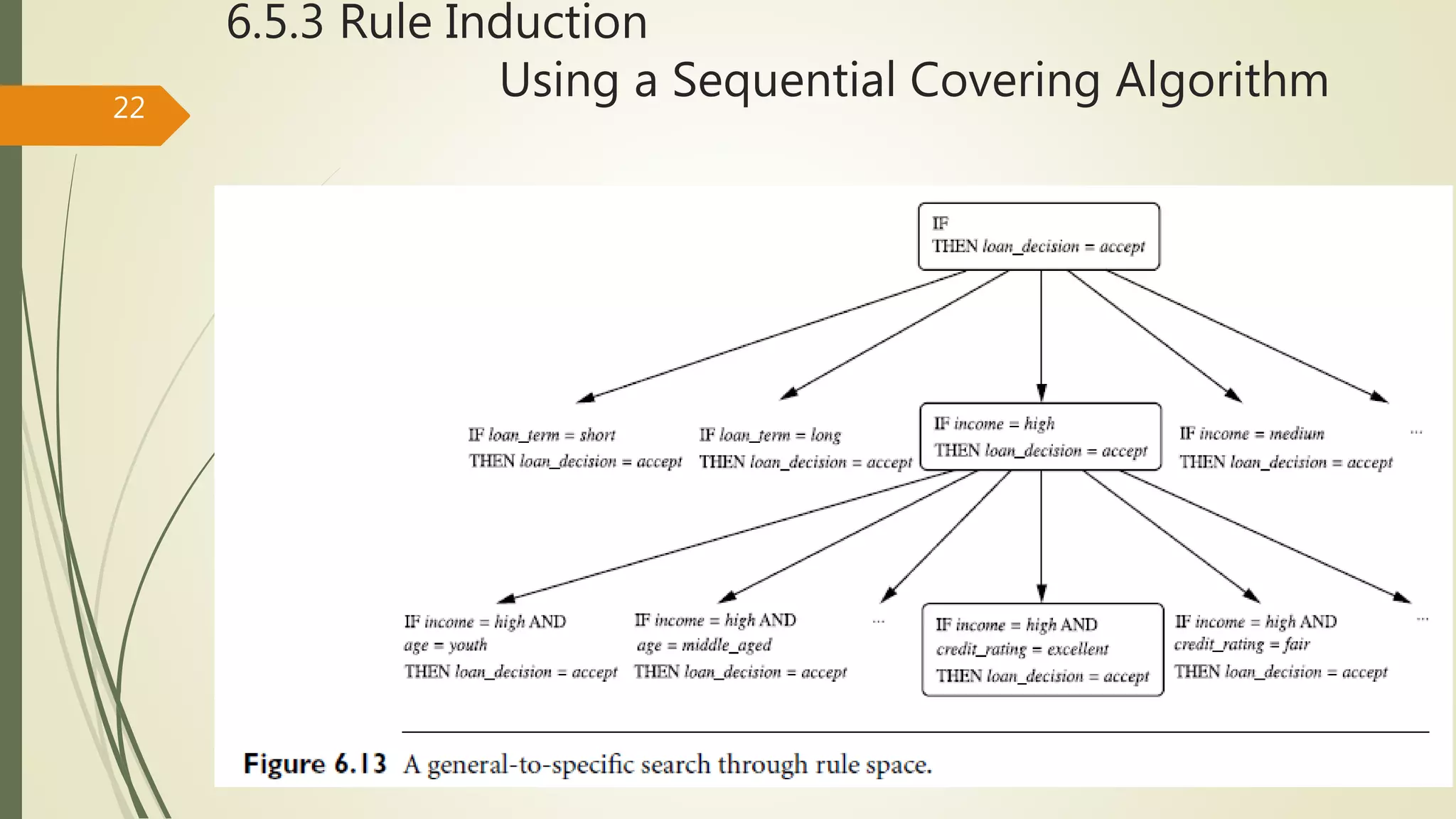
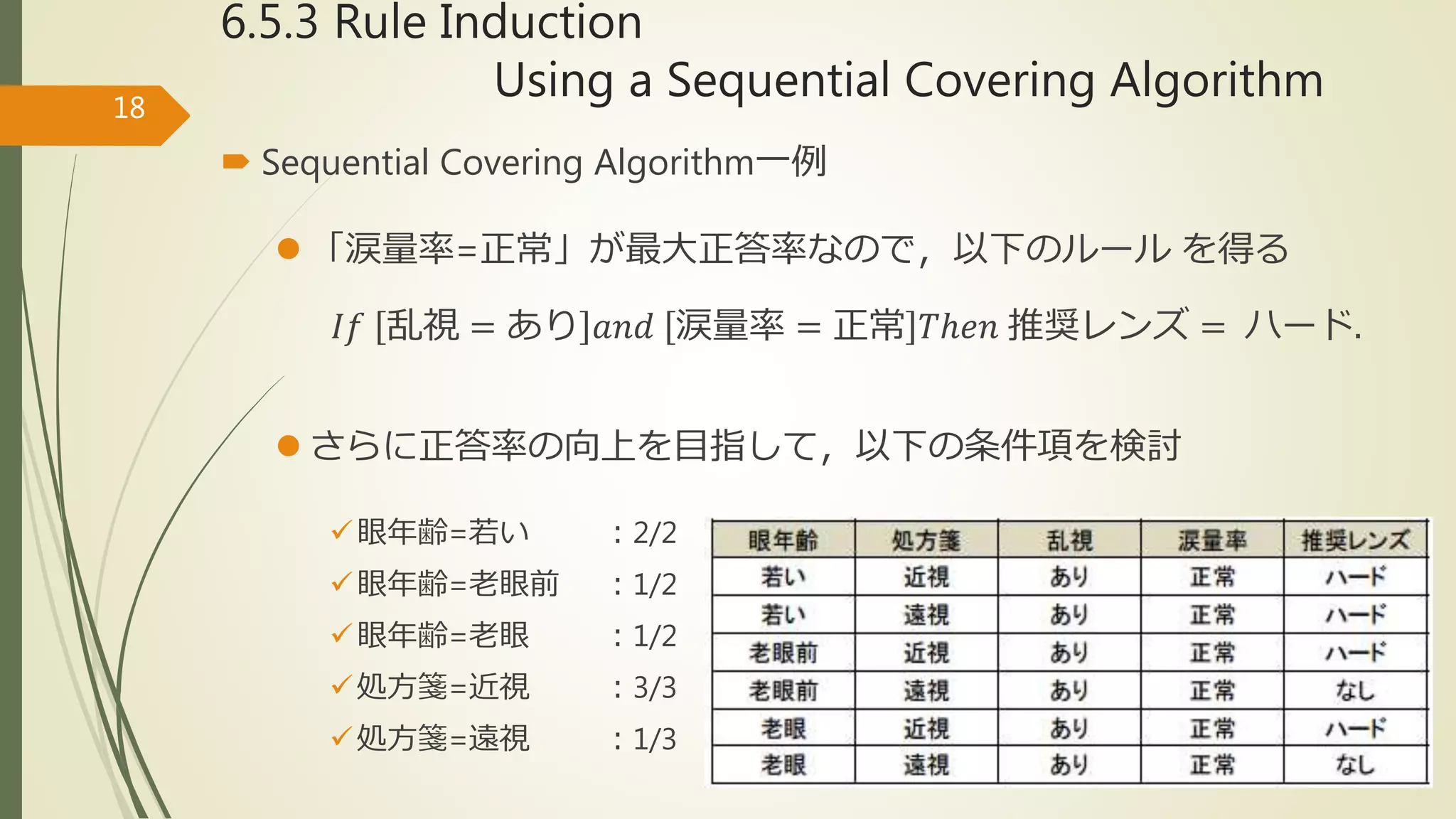
6.5.3 Rule Induction
Usinga Sequential Covering Algorithm26
Rule Quality Measures ①エントロピー ②FOIL
クラスCに対するルールを学習する
R: IF condition THEN class = c.
ある属性テストとの論理積をとったcondition’を考える
R′: IF condition′ THEN class = c.
R’がどのRよりも最適なルールであることを確かめる













![6.5.3 Rule Induction
Using a Sequential Covering Algorithm17
Sequential Covering Algorithm一例
ここで未知の項[?]で考えられる条件項は,以下の7つ
眼年齢=若い :2/4
眼年齢=老眼前 :1/4
眼年齢=老眼 :1/4
処方箋=近視 :3/6
処方箋=遠視 :1/6
涙量率=減少 :0/6
涙量率=正常 :4/6](https://image.slidesharecdn.com/dm6-200213181522/75/Data-Mining-6-5-Rule-Based-Classification-17-2048.jpg)
![6.5.3 Rule Induction
Using a Sequential Covering Algorithm19
Sequential Covering Algorithm一例
「眼年齢=若い」と「処方箋=近視」が最大正答率100%だが,カ
バー数の多い「処方箋=近視」 を採用し,以下のルールを得る
If [乱視 =あり] and [涙量率 =正常] and [処方箋 =近視] Then 推
奨レンズ =ハード
このルールは24事例のうちの 3事例しかカバーしていないので,3
事例をデータセットから削除し,ルール学習を繰り返す](https://image.slidesharecdn.com/dm6-200213181522/75/Data-Mining-6-5-Rule-Based-Classification-19-2048.jpg)
![6.5.3 Rule Induction
Using a Sequential Covering Algorithm20
Sequential Covering Algorithm一例
同様にして正答率1/1の以下のルー
ルが得られる
If [眼年齢 =若い] and [乱視 =あり]
and [涙量率 =正常] Then 推奨レンズ
=ハード
次に,推奨レンズが「ソフト」と
「なし」のルールを生成する](https://image.slidesharecdn.com/dm6-200213181522/75/Data-Mining-6-5-Rule-Based-Classification-20-2048.jpg)