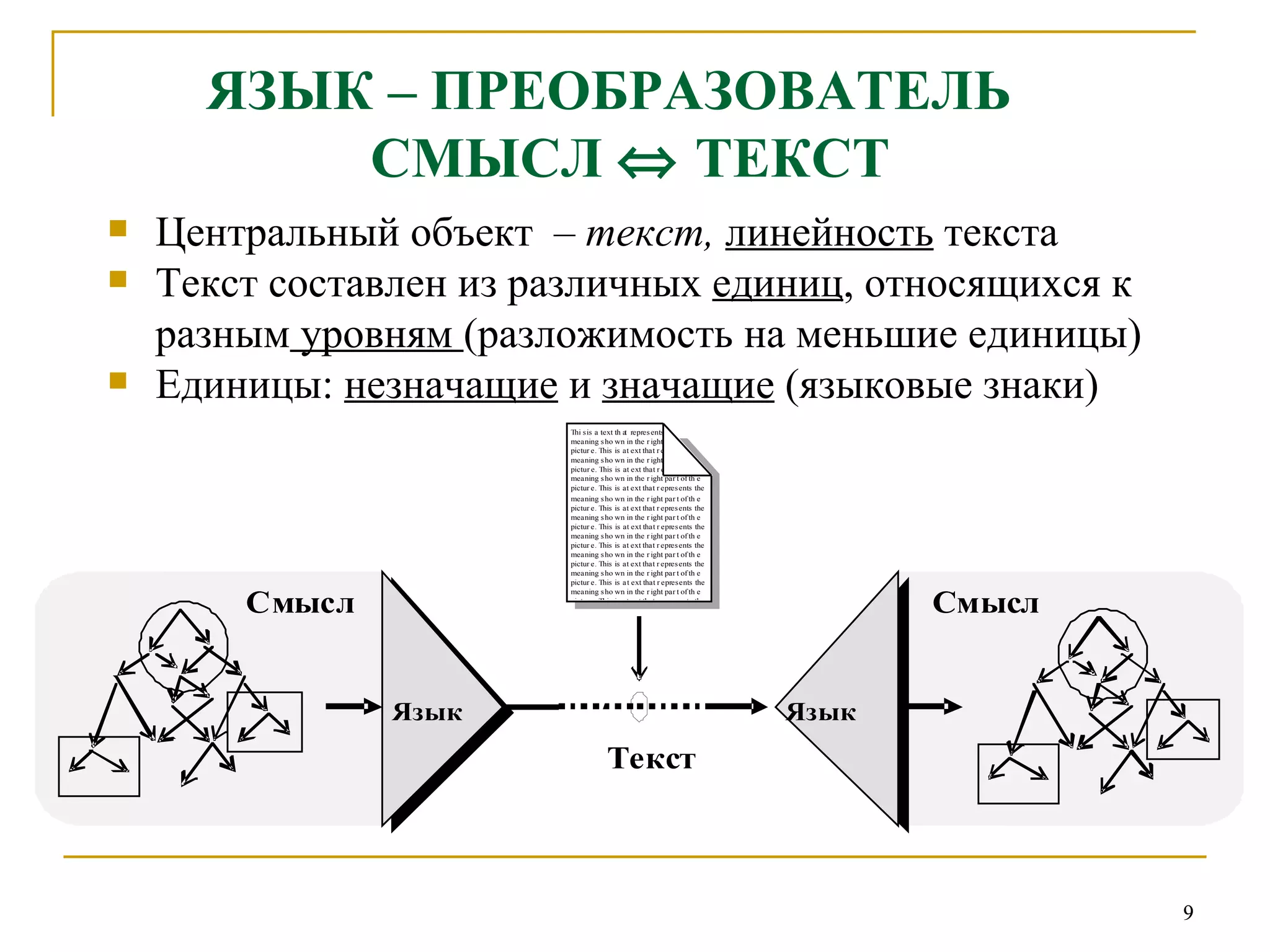
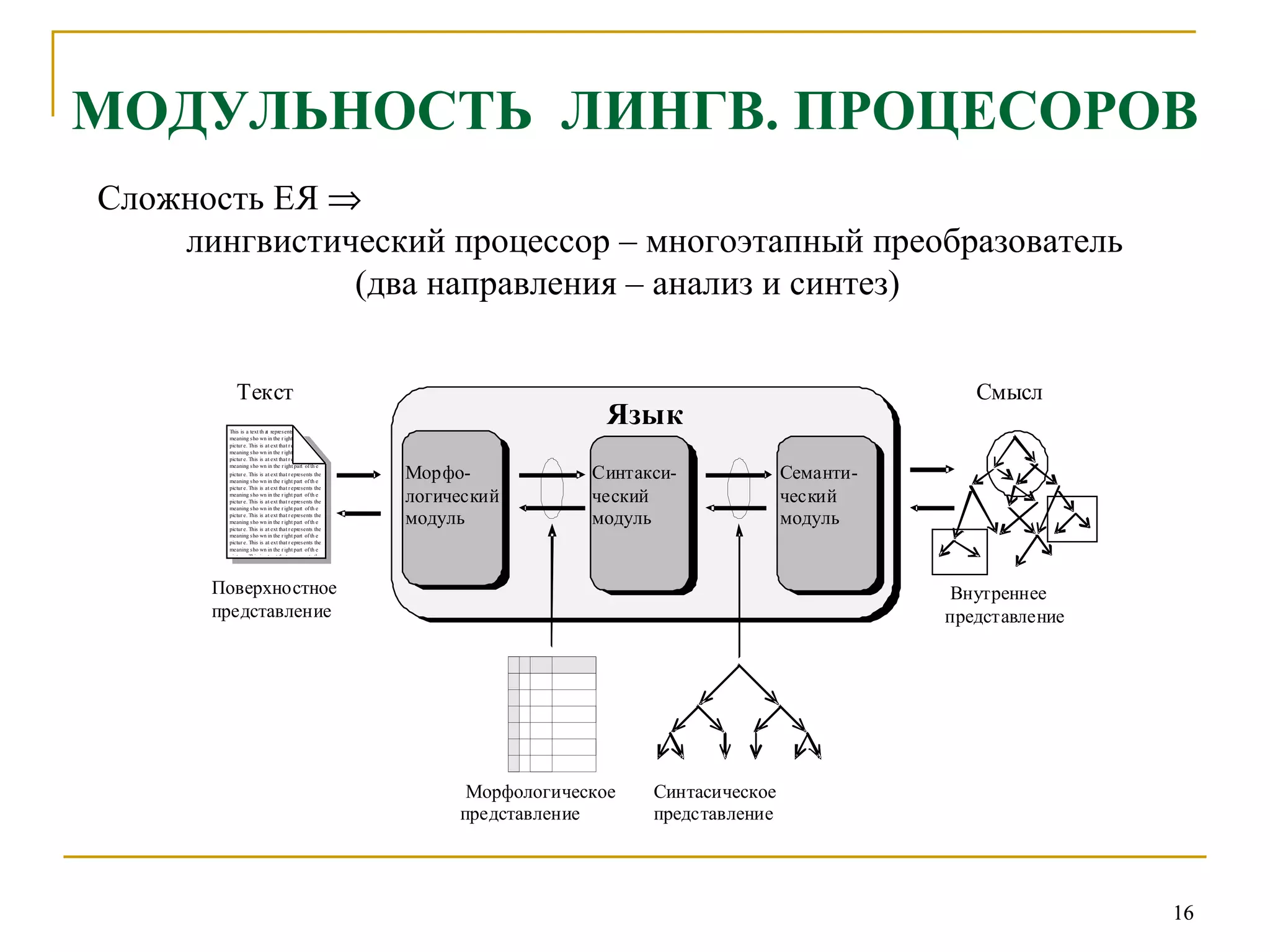
Документ представляет введение в автоматическую обработку текстов на естественном языке (АОН) и охватывает ее исторические аспекты, основные задачи, методы и ресурсы. Основное внимание уделяется лингвистическим и компьютерным подходам к обработке естественного языка, а также моделированию и трудностям, связанным с разнообразием языков. В заключение рассматриваются прикладные задачи, такие как машинный перевод и анализ текстов.