Download as PDF, PPTX





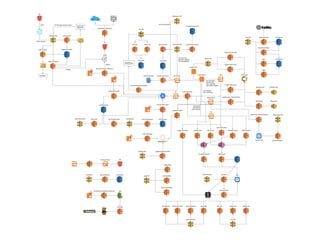




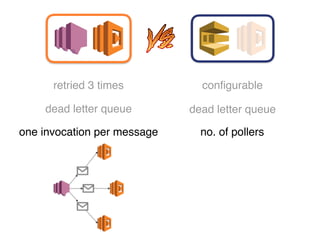
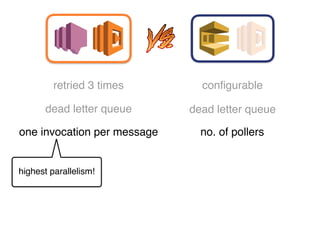
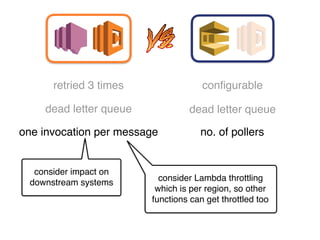


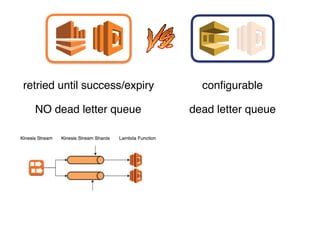
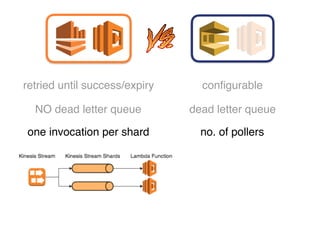

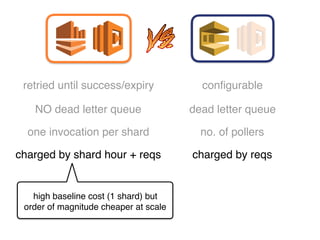





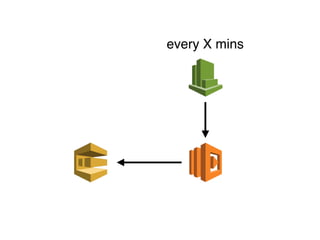





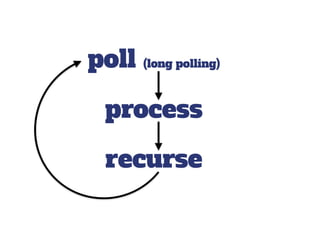
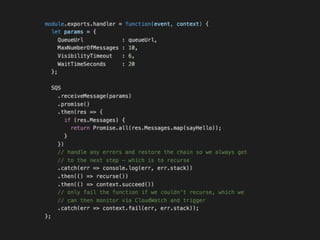
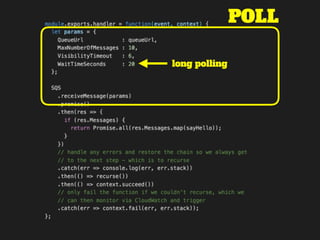
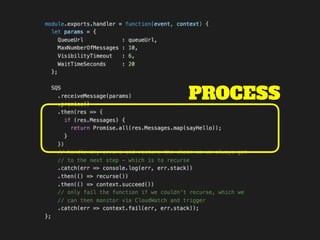
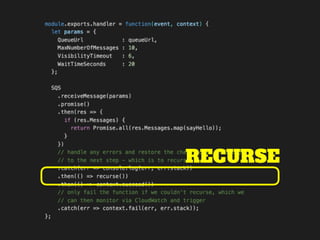



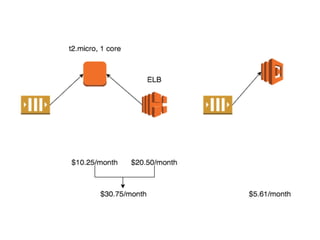

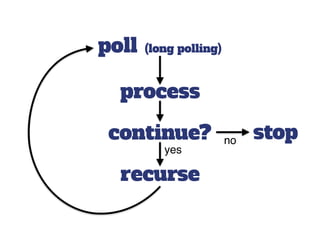
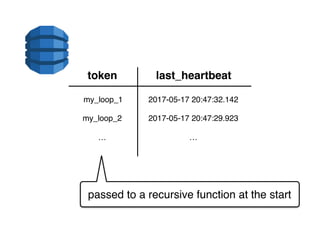
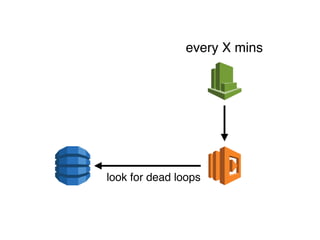
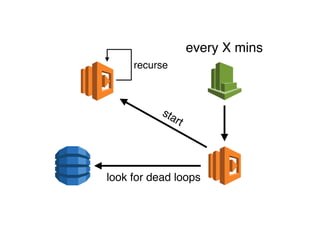
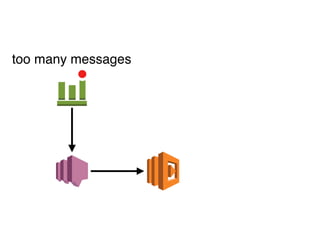
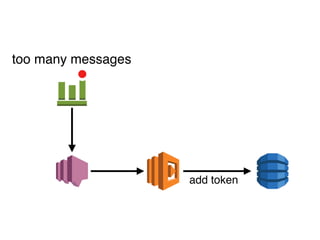
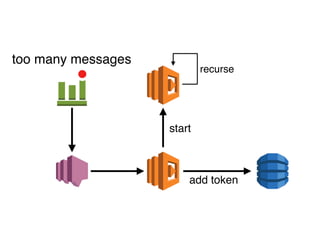
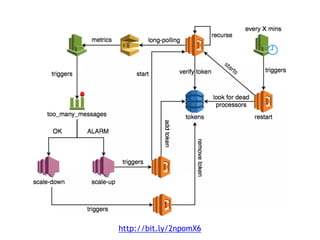





The document discusses the configuration and cost considerations of using AWS Lambda with SQS as an ingress source, highlighting the importance of dead letter queues and parallelism. It emphasizes that while SQS is useful, it may not be the appropriate solution for every scenario, and manual or autoscaling alternatives could be needed for unpredictable traffic. Additionally, the document references links to further resources on processing SQS with Lambda.

























































