Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Koji Yamada
PDF, PPTX
4,867 views
SQL Server のインデックス設計
SQL Server でのインデックス設計の基本的な考え方 - 対象者 - 正規化を含めたテーブル設計は理解しているが、インデックス設計に悩んでいる方
Software
◦
Related topics:
Insights on Software Development
•
Read more
4
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 29
2
/ 29
Most read
3
/ 29
Most read
4
/ 29
5
/ 29
6
/ 29
7
/ 29
8
/ 29
9
/ 29
10
/ 29
11
/ 29
12
/ 29
13
/ 29
14
/ 29
15
/ 29
16
/ 29
17
/ 29
18
/ 29
19
/ 29
20
/ 29
21
/ 29
22
/ 29
23
/ 29
24
/ 29
25
/ 29
26
/ 29
27
/ 29
28
/ 29
29
/ 29
More Related Content
PDF
DDD x CQRS 更新系と参照系で異なるORMを併用して上手くいった話
by
Koichiro Matsuoka
PDF
2025年現在のNewSQL (最強DB講義 #36 発表資料)
by
NTT DATA Technology & Innovation
PPTX
BuildKitによる高速でセキュアなイメージビルド
by
Akihiro Suda
PDF
型安全性入門
by
Akinori Abe
PPTX
SQLチューニング入門 入門編
by
Miki Shimogai
PDF
3種類のTEE比較(Intel SGX, ARM TrustZone, RISC-V Keystone)
by
Kuniyasu Suzaki
PDF
マイクロにしすぎた結果がこれだよ!
by
mosa siru
PDF
TLS, HTTP/2演習
by
shigeki_ohtsu
DDD x CQRS 更新系と参照系で異なるORMを併用して上手くいった話
by
Koichiro Matsuoka
2025年現在のNewSQL (最強DB講義 #36 発表資料)
by
NTT DATA Technology & Innovation
BuildKitによる高速でセキュアなイメージビルド
by
Akihiro Suda
型安全性入門
by
Akinori Abe
SQLチューニング入門 入門編
by
Miki Shimogai
3種類のTEE比較(Intel SGX, ARM TrustZone, RISC-V Keystone)
by
Kuniyasu Suzaki
マイクロにしすぎた結果がこれだよ!
by
mosa siru
TLS, HTTP/2演習
by
shigeki_ohtsu
What's hot
PDF
まじめに!できる!LT
by
Akabane Hiroyuki
PDF
Pythonによる黒魔術入門
by
大樹 小倉
PDF
テスト文字列に「うんこ」と入れるな
by
Kentaro Matsui
PDF
REST API のコツ
by
pospome
PDF
ドメイン駆動設計サンプルコードの徹底解説
by
増田 亨
PDF
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
PPTX
モノリスからマイクロサービスへの移行 ~ストラングラーパターンの検証~(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
PDF
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
PDF
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
by
Mikiya Okuno
PDF
ドメイン駆動設計 本格入門
by
増田 亨
PDF
ソーシャルゲームのためのデータベース設計
by
Yoshinori Matsunobu
PDF
Dockerの期待と現実~Docker都市伝説はなぜ生まれるのか~
by
Masahito Zembutsu
PDF
できる!並列・並行プログラミング
by
Preferred Networks
PPTX
ゲームエンジニアのためのデータベース設計
by
sairoutine
PDF
Vacuum徹底解説
by
Masahiko Sawada
PDF
Docker Compose 徹底解説
by
Masahito Zembutsu
PDF
チケット駆動開発の解説~タスク管理からプロセス改善へ
by
akipii Oga
PDF
Amazon RDSを参考にしたとりまチューニング
by
Shunsuke Mihara
PDF
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」
by
Takuto Wada
PDF
Where狙いのキー、order by狙いのキー
by
yoku0825
まじめに!できる!LT
by
Akabane Hiroyuki
Pythonによる黒魔術入門
by
大樹 小倉
テスト文字列に「うんこ」と入れるな
by
Kentaro Matsui
REST API のコツ
by
pospome
ドメイン駆動設計サンプルコードの徹底解説
by
増田 亨
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
モノリスからマイクロサービスへの移行 ~ストラングラーパターンの検証~(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
by
Mikiya Okuno
ドメイン駆動設計 本格入門
by
増田 亨
ソーシャルゲームのためのデータベース設計
by
Yoshinori Matsunobu
Dockerの期待と現実~Docker都市伝説はなぜ生まれるのか~
by
Masahito Zembutsu
できる!並列・並行プログラミング
by
Preferred Networks
ゲームエンジニアのためのデータベース設計
by
sairoutine
Vacuum徹底解説
by
Masahiko Sawada
Docker Compose 徹底解説
by
Masahito Zembutsu
チケット駆動開発の解説~タスク管理からプロセス改善へ
by
akipii Oga
Amazon RDSを参考にしたとりまチューニング
by
Shunsuke Mihara
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」
by
Takuto Wada
Where狙いのキー、order by狙いのキー
by
yoku0825
Similar to SQL Server のインデックス設計
PDF
データベースのインデックスの種類と内部の仕組み.pdf
by
釣りキチ翔平
PPTX
SQL Server Performance Tuning Essentials
by
Masaki Hirose
PDF
SQL Server チューニング基礎
by
Microsoft
PDF
MySQL Index勉強会外部公開用
by
CROOZ, inc.
PPTX
Microsoft Azure - SQL Data Warehouse
by
Microsoft
PDF
Sql serverインデックスの断片化と再構築の必要性について
by
貴仁 大和屋
PPT
SQLチューニング勉強会資料
by
Shinnosuke Akita
PPTX
RDBのインデックスについて.pptx
by
Tetsuro Nagae
PPTX
SQL Server 入門
by
Tsuyoshi Kitagawa
PDF
Sql server data store data access internals
by
Masayuki Ozawa
PPT
20090107 Postgre Sqlチューニング(Sql編)
by
Hiromu Shioya
PDF
ヤフー社内でやってるMySQLチューニングセミナー大公開
by
Yahoo!デベロッパーネットワーク
PDF
C11,12 SQL Server 2012 Performance Tuning by Yukio Kumazawa
by
Insight Technology, Inc.
PDF
2018年度 若手技術者向け講座 インデックス
by
keki3
PPTX
SQLアンチパターンNight ライトニングトーク
by
Itabashi Masayuki
PDF
C13 SQL Server2012知られざるTips集 by 平山理
by
Insight Technology, Inc.
PDF
MySQL 入門的なはなし
by
Yuya Takeyama
PDF
[db tech showcase Sapporo 2015] A16:DBママが教えるインデックスのしつけ方 by 株式会社日立製作所 情報・通信システ...
by
Insight Technology, Inc.
PDF
SQLアンチパターン(インデックスショットガン)
by
Tomoaki Uchida
PPTX
開発者の方向けの Sql server(db) t sql 振り返り
by
Oda Shinsuke
データベースのインデックスの種類と内部の仕組み.pdf
by
釣りキチ翔平
SQL Server Performance Tuning Essentials
by
Masaki Hirose
SQL Server チューニング基礎
by
Microsoft
MySQL Index勉強会外部公開用
by
CROOZ, inc.
Microsoft Azure - SQL Data Warehouse
by
Microsoft
Sql serverインデックスの断片化と再構築の必要性について
by
貴仁 大和屋
SQLチューニング勉強会資料
by
Shinnosuke Akita
RDBのインデックスについて.pptx
by
Tetsuro Nagae
SQL Server 入門
by
Tsuyoshi Kitagawa
Sql server data store data access internals
by
Masayuki Ozawa
20090107 Postgre Sqlチューニング(Sql編)
by
Hiromu Shioya
ヤフー社内でやってるMySQLチューニングセミナー大公開
by
Yahoo!デベロッパーネットワーク
C11,12 SQL Server 2012 Performance Tuning by Yukio Kumazawa
by
Insight Technology, Inc.
2018年度 若手技術者向け講座 インデックス
by
keki3
SQLアンチパターンNight ライトニングトーク
by
Itabashi Masayuki
C13 SQL Server2012知られざるTips集 by 平山理
by
Insight Technology, Inc.
MySQL 入門的なはなし
by
Yuya Takeyama
[db tech showcase Sapporo 2015] A16:DBママが教えるインデックスのしつけ方 by 株式会社日立製作所 情報・通信システ...
by
Insight Technology, Inc.
SQLアンチパターン(インデックスショットガン)
by
Tomoaki Uchida
開発者の方向けの Sql server(db) t sql 振り返り
by
Oda Shinsuke
SQL Server のインデックス設計
1.
SQL Serverのインデックス設計 インデックス設計の基本的な考え方 山田公次 2018/6/12
2.
/28 自己紹介 山田 公次(Yamada Koji) •
名古屋在住の C#per • 現在は .NET 系のソフト開発に携わっています • 約10年ほどフリーランスで活動していた時期もあ り、青色申告のスキルも得ています(^^) • これまで、金融やインフラ系、不動産業界などの 様々なシステム開発に携わり、SQL Serverや OracleなどでDBのスキルを育ててきました 2 @hamu502
3.
/28 目的と対象者 本資料の目的 • 以下のような方が、「何となく」ではなく、論拠 を持ってインデックス設計できること。 • テーブルの正規化は分かるが、インデック スの理解度が低いと感じている方 •
テーブル設計はできるが、インデックス設計に 自信がない方 3
4.
/28 アジェンダ 4 1.インデックスの概要 2.インデックスの種類 3.インデックスの設計基準
5.
1. インデックスの概要 5
6.
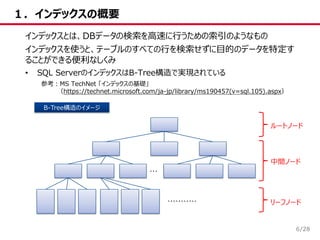
/28 1.インデックスの概要 6 インデックスとは、DBデータの検索を高速に行うための索引のようなもの インデックスを使うと、テーブルのすべての行を検索せずに目的のデータを特定す ることができる便利なしくみ • SQL ServerのインデックスはB-Tree構造で実現されている 参考:MS
TechNet 「インデックスの基礎」 (https://technet.microsoft.com/ja-jp/library/ms190457(v=sql.105).aspx) ルートノード 中間ノード リーフノード ・・・ ・・・・・・・・・・・ B-Tree構造のイメージ
7.
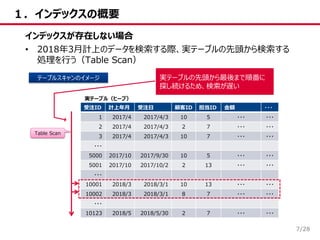
/28 1.インデックスの概要 7 インデックスが存在しない場合 • 2018年3月計上のデータを検索する際、実テーブルの先頭から検索する 処理を行う(Table Scan) 受注ID
計上年月 受注日 顧客ID 担当ID 金額 ・・・ 1 2017/4 2017/4/3 10 5 ・・・ ・・・ 2 2017/4 2017/4/3 2 7 ・・・ ・・・ 3 2017/4 2017/4/3 10 7 ・・・ ・・・ ・・・ 5000 2017/10 2017/9/30 10 5 ・・・ ・・・ 5001 2017/10 2017/10/2 2 13 ・・・ ・・・ ・・・ 10001 2018/3 2018/3/1 10 13 ・・・ ・・・ 10002 2018/3 2018/3/1 8 7 ・・・ ・・・ ・・・ 10123 2018/5 2018/5/30 2 7 ・・・ ・・・ 実テーブル(ヒープ) Table Scan テーブルスキャンのイメージ 実テーブルの先頭から最後まで順番に 探し続けるため、検索が遅い
8.
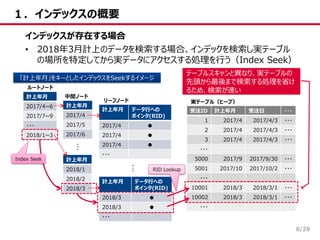
/28 1.インデックスの概要 8 インデックスが存在する場合 • 2018年3月計上のデータを検索する場合、インデックを検索し実テーブル の場所を特定してから実データにアクセスする処理を行う(Index Seek) 受注ID
計上年月 受注日 ・・・ 1 2017/4 2017/4/3 ・・・ 2 2017/4 2017/4/3 ・・・ 3 2017/4 2017/4/3 ・・・ ・・・ 5000 2017/9 2017/9/30 ・・・ 5001 2017/10 2017/10/2 ・・・ ・・・ 10001 2018/3 2018/3/1 ・・・ 10002 2018/3 2018/3/1 ・・・ ・・・ 計上年月 2017/4 2017/5 2017/6 計上年月 2017/4~6 2017/7~9 ・・・ 2018/1~3 計上年月 2018/1 2018/2 2018/3 計上年月 データ行への ポインタ(RID) 2017/4 ● 2017/4 ● 2017/4 ● ・・・ 計上年月 データ行への ポインタ(RID) 2018/3 ● 2018/3 ● ・・・ ルートノード 中間ノード リーフノード 実テーブル(ヒープ) 「計上年月」をキーとしたインデックスをSeekするイメージ … … テーブルスキャンと異なり、実テーブルの 先頭から最後まで検索する処理を省け るため、検索が速い Index Seek RID Lookup
9.
2. インデックスの種類 9
10.
/28 2.インデックスの種類 10 SQL Server での主要なインデックスの種類 •
クラスタ化インデックス • リーフノードがデータ行となるB-Tree構造のインデックス • テーブルのデータ行を、インデックスに設定したキー値に基づいて並べ替えて格納 • 1テーブルに1つのみ設定可能 • 非クラスタ化インデックス • データ行とは独立したB-Tree構造のインデックス • クラスター化インデックスが設定されたテーブル、またはヒープ上に定義 • 1テーブルに複数設定可能 • 付加列インデックス • キー列に加えて非キー列を付加できるように拡張した非クラスター化インデックス インデックスの目的による分類 • 一意インデックス • キーの値が重複することがなく、テーブル行を一意に特定するインデックス • 複合インデックス • 複数のキー値を指定したインデックス • 検索条件や取得列をインデックスのみで賄う目的で作成した複合インデックスを「カバーリ ングインデックス」と言う
11.
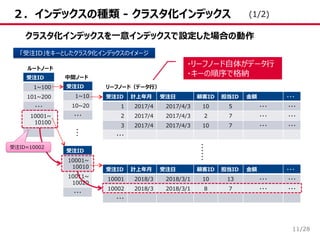
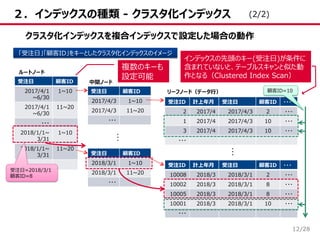
/28 2.インデックスの種類 - クラスタ化インデックス 11 クラスタ化インデックスを一意インデックスで設定した場合の動作 「受注ID」をキーとしたクラスタ化インデックスのイメージ 受注ID
計上年月 受注日 顧客ID 担当ID 金額 ・・・ 1 2017/4 2017/4/3 10 5 ・・・ ・・・ 2 2017/4 2017/4/3 2 7 ・・・ ・・・ 3 2017/4 2017/4/3 10 7 ・・・ ・・・ ・・・ 受注ID 計上年月 受注日 顧客ID 担当ID 金額 ・・・ 10001 2018/3 2018/3/1 10 13 ・・・ ・・・ 10002 2018/3 2018/3/1 8 7 ・・・ ・・・ ・・・ 受注ID 1~10 10~20 ・・・ 受注ID 1~100 101~200 ・・・ 10001~ 10100 受注ID 10001~ 10010 10011~ 10020 ・・・ ルートノード 中間ノード リーフノード(データ行) … …… 受注ID=10002 ・リーフノード自体がデータ行 ・キーの順序で格納 (1/2)
12.
/28 2.インデックスの種類 - クラスタ化インデックス 12 クラスタ化インデックスを複合インデックスで設定した場合の動作 「受注日」「顧客ID」をキーとしたクラスタ化インデックスのイメージ 受注日
顧客ID 2017/4/1 ~6/30 1~10 2017/4/1 ~6/30 11~20 ・・・ 2018/1/1~ 3/31 1~10 2018/1/1~ 3/31 11~20 ・・・ ルートノード … 受注ID 計上年月 受注日 顧客ID ・・・ 2 2017/4 2017/4/3 2 ・・・ 1 2017/4 2017/4/3 10 ・・・ 3 2017/4 2017/4/3 10 ・・・ ・・・ 受注日 顧客ID 2017/4/3 1~10 2017/4/3 11~20 ・・・ 中間ノード 受注日 顧客ID 2018/3/1 1~10 2018/3/1 11~20 ・・・ 受注ID 計上年月 受注日 顧客ID ・・・ 10008 2018/3 2018/3/1 2 ・・・ 10002 2018/3 2018/3/1 8 ・・・ 10005 2018/3 2018/3/1 8 ・・・ 10001 2018/3 2018/3/1 10 ・・・ ・・・ … リーフノード(データ行) 受注日=2018/3/1 顧客ID=8 複数のキーも 設定可能 インデックスの先頭のキー(受注日)が条件に 含まれていないと、テーブルスキャンと似た動 作となる(Clustered Index Scan) 顧客ID=10 (2/2)
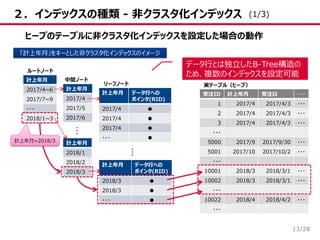
13.
/28 2.インデックスの種類 - 非クラスタ化インデックス 13 ヒープのテーブルに非クラスタ化インデックスを設定した場合の動作 「計上年月」をキーとした非クラスタ化インデックスのイメージ 受注ID
計上年月 受注日 ・・・ 1 2017/4 2017/4/3 ・・・ 2 2017/4 2017/4/3 ・・・ 3 2017/4 2017/4/3 ・・・ ・・・ 5000 2017/9 2017/9/30 ・・・ 5001 2017/10 2017/10/2 ・・・ ・・・ 10001 2018/3 2018/3/1 ・・・ 10002 2018/3 2018/3/1 ・・・ ・・・ 10022 2018/4 2018/4/2 ・・・ ・・・ 計上年月 2017/4 2017/5 2017/6 計上年月 2017/4~6 2017/7~9 ・・・ 2018/1~3 計上年月 2018/1 2018/2 2018/3 計上年月 データ行への ポインタ(RID) 2017/4 ● 2017/4 ● 2017/4 ● ・・・ ● 計上年月 データ行への ポインタ(RID) 2018/3 ● 2018/3 ● ・・・ ● ルートノード 中間ノード リーフノード 実テーブル(ヒープ) … … 計上年月=2018/3 データ行とは独立したB-Tree構造の ため、複数のインデックスを設定可能 (1/3)
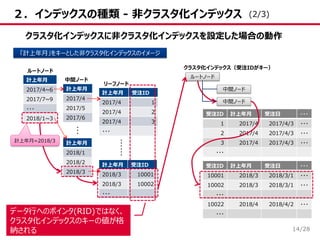
14.
/28 2.インデックスの種類 - 非クラスタ化インデックス 14 クラスタ化インデックスに非クラスタ化インデックスを設定した場合の動作 「計上年月」をキーとした非クラスタ化インデックスのイメージ 受注ID
計上年月 受注日 ・・・ 1 2017/4 2017/4/3 ・・・ 2 2017/4 2017/4/3 ・・・ 3 2017/4 2017/4/3 ・・・ ・・・ 計上年月 2017/4 2017/5 2017/6 計上年月 2017/4~6 2017/7~9 ・・・ 2018/1~3 計上年月 2018/1 2018/2 2018/3 計上年月 受注ID 2017/4 1 2017/4 2 2017/4 3 ・・・ 計上年月 受注ID 2018/3 10001 2018/3 10002 ・・・ ルートノード 中間ノード リーフノード クラスタ化インデックス(受注IDがキー) … …… ルートノード 中間ノード 中間ノード 計上年月=2018/3 受注ID 計上年月 受注日 ・・・ 10001 2018/3 2018/3/1 ・・・ 10002 2018/3 2018/3/1 ・・・ ・・・ 10022 2018/4 2018/4/2 ・・・ ・・・データ行へのポインタ(RID)ではなく、 クラスタ化インデックスのキーの値が格 納される (2/3)
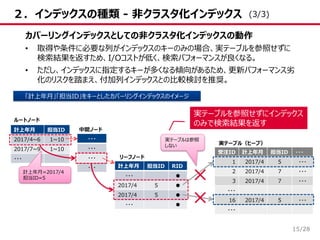
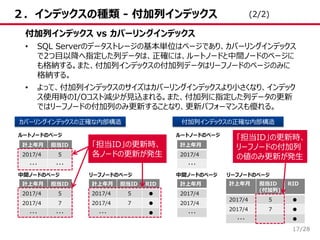
15.
/28 2.インデックスの種類 - 非クラスタ化インデックス 15 「計上年月」「担当ID」をキーとしたカバーリングインデックスのイメージ 受注ID
計上年月 担当ID ・・・ 1 2017/4 5 ・・・ 2 2017/4 7 ・・・ 3 2017/4 7 ・・・ ・・・ 16 2017/4 5 ・・・ ・・・ カバーリングインデックスとしての非クラスタ化インデックスの動作 • 取得や条件に必要な列がインデックスのキーのみの場合、実テーブルを参照せずに 検索結果を返すため、I/Oコストが低く、検索パフォーマンスが良くなる。 • ただし、インデックスに指定するキーが多くなる傾向があるため、更新パフォーマンス劣 化のリスクを踏まえ、付加列インデックスとの比較検討を推奨。 実テーブル(ヒープ) ・・・ ・・・ ・・・ ・・・ 計上年月 担当ID 2017/4~6 1~10 2017/7~9 1~10 ・・・ 計上年月 担当ID RID ・・・ ● 2017/4 5 ● 2017/4 5 ● ・・・ ● 中間ノード リーフノード 計上年月=2017/4 担当ID=5 ルートノード 実テーブルは参照 しない 実テーブルを参照せずにインデックス のみで検索結果を返す (3/3)
16.
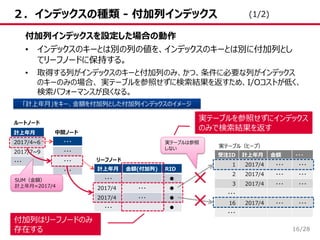
/28 2.インデックスの種類 - 付加列インデックス 16 付加列インデックスを設定した場合の動作 •
インデックスのキーとは別の列の値を、インデックスのキーとは別に付加列とし てリーフノードに保持する。 • 取得する列がインデックスのキーと付加列のみ、かつ、条件に必要な列がインデックス のキーのみの場合、 実テーブルを参照せずに検索結果を返すため、I/Oコストが低く、 検索パフォーマンスが良くなる。 「計上年月」をキー、金額を付加列とした付加列インデックスのイメージ 受注ID 計上年月 金額 ・・・ 1 2017/4 ・・・ ・・・ 2 2017/4 ・・・ ・・・ 3 2017/4 ・・・ ・・・ ・・・ 16 2017/4 ・・・ ・・・ ・・・ 実テーブル(ヒープ) ・・・ ・・・ ・・・ ・・・ 計上年月 2017/4~6 2017/7~9 ・・・ 計上年月 金額(付加列) RID ・・・ ● 2017/4 ・・・ ● 2017/4 ・・・ ● ・・・ ● 中間ノード リーフノード SUM(金額) 計上年月=2017/4 ルートノード 実テーブルは参照 しない 実テーブルを参照せずにインデックス のみで検索結果を返す 付加列はリーフノードのみ 存在する (1/2)
17.
/28 2.インデックスの種類 - 付加列インデックス 17 付加列インデックス
vs カバーリングインデックス • SQL Serverのデータストレージの基本単位はページであり、カバーリングインデックス で2つ目以降へ指定した列データは、正確には、ルートノードと中間ノードのページに も格納する。また、付加列インデックスの付加列データはリーフノードのページのみに 格納する。 • よって、付加列インデックスのサイズはカバーリングインデックスより小さくなり、インデック ス使用時のI/Oコスト減少が見込まれる。また、付加列に指定した列データの更新 ではリーフノードの付加列のみ更新することなり、更新パフォーマンスも優れる。 計上年月 担当ID 2017/4 5 ・・・ ・・・ 計上年月 担当ID RID 2017/4 5 ● 2017/4 7 ● ・・・ ● 中間ノードのページ リーフノードのページ ルートノードのページ (2/2) カバーリングインデックスの正確な内部構造 計上年月 担当ID 2017/4 5 2017/4 7 ・・・ ・・・ 計上年月 2017/4 ・・・ 中間ノードのページ リーフノードのページ ルートノードのページ 付加列インデックスの正確な内部構造 計上年月 2017/4 2017/4 ・・・ 計上年月 担当ID (付加列) RID 2017/4 5 ● 2017/4 7 ● ・・・ ● 「担当ID」の更新時、 各ノードの更新が発生 「担当ID」の更新時、 リーフノードの付加列 の値のみ更新が発生
18.
3. インデックスの設計基準 18
19.
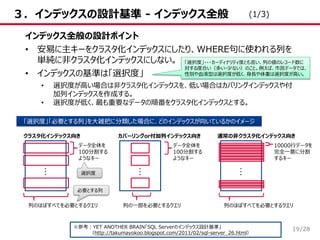
/28 3.インデックスの設計基準 - インデックス全般 インデックス全般の設計ポイント •
安易に主キーをクラスタ化インデックスにしたり、WHERE句に使われる列を 単純に非クラスタ化インデックスにしない。 • インデックスの基準は「選択度」 • 選択度が高い場合は非クラスタ化インデックスを、低い場合はカバリングインデックスや付 加列インデックスを作成する。 • 選択度が低く、最も重要なデータの順番をクラスタ化インデックスとする。 ※参考:YET ANOTHER BRAIN「SQL Serverのインデックス設計基準」 (http://takumayokoo.blogspot.com/2011/02/sql-server_26.html) 「選択度」「必要とする列」を大雑把に分類した場合に、どのインデックスが向いているかのイメージ クラスタ化インデックス向き … データ全体を 100分割する ようなキー 列のほぼすべてを必要とするクエリ カバーリングor付加列インデックス向き… データ全体を 100分割する ようなキー 列の一部を必要とするクエリ 通常の非クラスタ化インデックス向き … 10000行データを 完全一意に分割 するキー 列のほぼすべてを必要とするクエリ 選択度 必要とする列 (1/3) 19 「選択度」・・・カーディナリティ度とも言い、列の値のレコード数に 対する度合い(多い・少ない)のこと。例えば、市民データでは、 性別や血液型は選択度が低く、身長や体重は選択度が高い。
20.
/28 3.インデックスの設計基準 - インデックス全般 Microsoftのガイドラインで重要な点(1/2) •
テーブル内のデータが変更された場合にインデックスをすべて調整するため、 INSERT、UPDATE、DELETE、および MERGE のパフォーマンスに影響 することを考慮する。 • 頻繁に更新するテーブルにはインデックスを設定しすぎないようにし、インデックスの幅を狭 く、つまり列数を可能な限り少なくする。 • 更新の必要が少なく、容量の大きいテーブルの場合、クエリのパフォーマンスを向上させる にはインデックスを多数使用する。 • 小さなテーブルではインデックスを作成しない方がよい場合もある。 • クエリの種類とクエリ内での列の使用方法を評価する。 • 完全一致検索クエリで使用される列は、非クラスター化インデックス、または、クラスター化 インデックスにする適切な候補になる。 ※参考:MS TechNet「インデックスの設計の全般的なガイドライン」 (https://technet.microsoft.com/ja-jp/library/ms191195(v=sql.105).aspx) (2/3) 20
21.
/28 3.インデックスの設計基準 - インデックス全般 Microsoftのガイドラインで重要な点(2/2) •
列内のデータの分布を調べる • インデックスを設定した列にほとんど一意の値がない場合や、このような列を結合する場合、 クエリに時間がかかることがよくある。 • インデックスに複数の列が含まれる場合は、列の順序を考慮する。 • 等しい (=)、より大きい (>)、より小さい (<)、BETWEEN などの検索条件の WHERE 句で使用されるか、結合に含まれる列は、先頭に配置します。その他の列は、 差異の程度、つまり最も差異の大きいものから最も差異の小さいものの順に配置する。 ※参考:MS TechNet「インデックスの設計の全般的なガイドライン」 (https://technet.microsoft.com/ja-jp/library/ms191195(v=sql.105).aspx) (3/3) 21
22.
/28 3.インデックスの設計基準 - クラスタ化インデックス クラスタ化インデックスの設計ポイント •
データが物理的にかたまっていてほしい単位を表す列をキーとする。 • 「日付」「顧客」「商品カテゴリ」など、全ての仕様を考慮して、最重要なデータの順番をク ラスタ化インデックスにすべき。 • 安易にテーブルの主キーをクラスタ化インデックスのキーにしない。 • 主キーはサロゲートキーであることも多く、主キーを範囲検索で使うことは、殆ど(もしくは 全く)無い。 • 主キーでクラスタ化インデックスを設定してしまうと、範囲検索に殆ど使われないにもかかわ らず、データが主キーの順番で並ぶことになり、範囲検索ではパフォーマンスが悪くなる。 • SQL Serverのデフォルトでは、主キーでクラスタ化インデックスを設定するため、仕様理 解が深まったタイミングなどで、再検討することを推奨。 ※参考:YET ANOTHER BRAIN「SQL Serverのインデックス設計基準」 (http://takumayokoo.blogspot.com/2011/02/sql-server_26.html) (1/3) 22
23.
/28 3.インデックスの設計基準 - クラスタ化インデックス Microsoftのガイドラインで重要な点(1/2) •
ほとんどの場合、各テーブルには、次の条件を満たす単一または複数の列に 基づいて定義されたクラスタ化インデックスを作成することを推奨。 • 頻繁に使用されるクエリに使用可能。 • 一意性が高い。 • 範囲クエリで使用可能。 • データがどのようにアクセスされるかを理解し、次の処理を行うクエリには、クラ スタ化インデックスを使用することを検討する。 • BETWEEN、>、>=、<、および <= などの演算子を使用して、ある範囲の値を返す。 • 大きな結果セットを返す。 • JOIN 句を使用する。通常、これらは外部キー列になる。 • ORDER BY 句または GROUP BY 句を使用する。 ※参考:MS TechNet「クラスタ化インデックスの設計ガイドライン」 (https://technet.microsoft.com/ja-jp/library/ms190639(v=sql.105).aspx) (2/3) 23
24.
/28 3.インデックスの設計基準 - クラスタ化インデックス Microsoftのガイドラインで重要な点(2/2) •
キーの定義に使用する列はできるだけ少なくする必要があるため、次の 1 つ 以上の条件を満たす列を使用する。 • 一意な値または多数の異なる値を含む。 • 順次アクセスされる。 • テーブル内で一意であることが確実なため、IDENTITY として定義されている。 • テーブルから取得したデータの並べ替えに頻繁に使用される。 ※参考:MS TechNet「クラスタ化インデックスの設計ガイドライン」 (https://technet.microsoft.com/ja-jp/library/ms190639(v=sql.105).aspx) (3/3) 24
25.
/28 3.インデックスの設計基準 - 非クラスタ化インデックス 非クラスタ化インデックスの設計ポイント •
安易に非クラスタ化インデックスを作成しない。 • 選択度(Selectivity)が低い列をキーにすると、インデックスで絞り込んだ結果のデータ 行が多くなり、場合によっては、インデックスを経由するよりテーブルスキャンの方が速くなる。 • カバーリングインデックス、付加列インデックスを使い分ける。 • 取得する列と条件に必要な列のみで範囲検索できる、かつ、更新頻度が低い場合は、カ バーリングインデックスを検討する。 • 条件に必要な列のみで範囲検索できる、かつ、更新頻度が低い場合は、条件に必要な 列をキー、取得する列を付加列とした付加列インデックスを検討する。 ※参考:YET ANOTHER BRAIN「SQL Serverのインデックス設計基準」 (http://takumayokoo.blogspot.com/2011/02/sql-server_26.html) (1/3) 25
26.
/28 3.インデックスの設計基準 - 非クラスタ化インデックス Microsoftのガイドラインで重要な点(1/2) •
クエリの述語や結合条件で頻繁に使用される列に対して非クラスター化イン デックスを作成する。 • ただし、不要な列を追加しないようにする。 • インデックス列を追加しすぎると、必要なディスク領域が増え、インデックスのメンテナンスの パフォーマンスも低下する可能性がある。 • インデックスの列数はできる限り抑える。 • 更新の必要が少なく、容量の大きいデータベースまたはテーブルの場合、ク エリのパフォーマンスを向上させるには非クラスター化インデックスを多数作成 するのが適している。 • 適切に定義されたデータのサブセットに対してフィルター選択されたインデックスを作成する ことを検討 • テーブルの更新頻度が高いOLTPアプリケーションでは、インデックスを過度に 作成することは勧めない。 ※参考:MS TechNet「非クラスタ化インデックスの設計ガイドライン」 (https://technet.microsoft.com/ja-jp/library/ms179325(v=sql.105).aspx) (2/3) 26
27.
/28 3.インデックスの設計基準 - 非クラスタ化インデックス Microsoftのガイドラインで重要な点(2/2) •
データがどのようにアクセスされるかを理解し、次に示す特徴があるクエリには 非クラスター化インデックスを使用することを検討する。 • JOIN 句または GROUP BY 句を使用している。 • 大きな結果セットを返さないクエリ。 • 完全一致を返すクエリの検索条件 (WHERE 句など) に頻繁に使用される列を含んで いる。 • 次に示す特徴に 1 つ以上該当する列を考慮する。 • クエリを包括している。 • 姓と名の組み合わせなど、多数の異なる値が格納されている。(他の列にクラスター化イン デックスが使用されている場合) ※参考:MS TechNet「非クラスタ化インデックスの設計ガイドライン」 (https://technet.microsoft.com/ja-jp/library/ms179325(v=sql.105).aspx) (3/3) 27
28.
/28 3.インデックスの設計基準 - 実際に有効か確認する 28 実際には、各テーブルのデータ量やテーブル内のキーの値の偏りなどDBの統計 情報により、SQL
Server のオプティマイザがインデックスの使用有無を含む 「実行計画」を作成し、DBにアクセスします。 よって、想定するデータ量や値の偏りのあるテストデータを用いて、使用するクエ リの「実行計画」を取得し、設計したインデックスが有効に機能するか確認する ことが大切です。 以下のサイトを参考に「実行計画」を取得し、作成したインデックスが「Index Seek」で使われることを確認し、インデックスが使われなかったり、 「Index Seek」で使われなかった場合はクエリやインデックスを見直してください。 • Markus Winand氏「開発者のためのSQLパフォーマンスの全て」内の 「実行計画」 - 「 SQL Server」 • https://use-the-index-luke.com/ja/sql/explain-plan/sql-server
29.
ご清聴ありがとうございました
Download

































































![[db tech showcase Sapporo 2015] A16:DBママが教えるインデックスのしつけ方 by 株式会社日立製作所 情報・通信システ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015a16rdbgeneralhitachi-150925022106-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

