Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Marwa'n Smadi
6,137 views
احصاء Spss
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 55 times
1
/ 150
2
/ 150
3
/ 150
4
/ 150
5
/ 150
6
/ 150
7
/ 150
8
/ 150
9
/ 150
10
/ 150
11
/ 150
12
/ 150
13
/ 150
14
/ 150
15
/ 150
16
/ 150
17
/ 150
Most read
18
/ 150
Most read
19
/ 150
20
/ 150
21
/ 150
22
/ 150
23
/ 150
24
/ 150
25
/ 150
Most read
26
/ 150
27
/ 150
28
/ 150
29
/ 150
30
/ 150
31
/ 150
32
/ 150
33
/ 150
34
/ 150
35
/ 150
36
/ 150
37
/ 150
38
/ 150
39
/ 150
40
/ 150
41
/ 150
42
/ 150
43
/ 150
44
/ 150
45
/ 150
46
/ 150
47
/ 150
48
/ 150
49
/ 150
50
/ 150
51
/ 150
52
/ 150
53
/ 150
54
/ 150
55
/ 150
56
/ 150
57
/ 150
58
/ 150
59
/ 150
60
/ 150
61
/ 150
62
/ 150
63
/ 150
64
/ 150
65
/ 150
66
/ 150
67
/ 150
68
/ 150
69
/ 150
70
/ 150
71
/ 150
72
/ 150
73
/ 150
74
/ 150
75
/ 150
76
/ 150
77
/ 150
78
/ 150
79
/ 150
80
/ 150
81
/ 150
82
/ 150
83
/ 150
84
/ 150
85
/ 150
86
/ 150
87
/ 150
88
/ 150
89
/ 150
90
/ 150
91
/ 150
92
/ 150
93
/ 150
94
/ 150
95
/ 150
96
/ 150
97
/ 150
98
/ 150
99
/ 150
100
/ 150
101
/ 150
102
/ 150
103
/ 150
104
/ 150
105
/ 150
106
/ 150
107
/ 150
108
/ 150
109
/ 150
110
/ 150
111
/ 150
112
/ 150
113
/ 150
114
/ 150
115
/ 150
116
/ 150
117
/ 150
118
/ 150
119
/ 150
120
/ 150
121
/ 150
122
/ 150
123
/ 150
124
/ 150
125
/ 150
126
/ 150
127
/ 150
128
/ 150
129
/ 150
130
/ 150
131
/ 150
132
/ 150
133
/ 150
134
/ 150
135
/ 150
136
/ 150
137
/ 150
138
/ 150
139
/ 150
140
/ 150
141
/ 150
142
/ 150
143
/ 150
144
/ 150
145
/ 150
146
/ 150
147
/ 150
148
/ 150
149
/ 150
150
/ 150
More Related Content
PDF
كورس التحليل الاحصائي بأستخدام SPSS
by
احمد الجسار
PDF
تحليل الاستبيان
by
cherifmouh
PDF
الاختبارات الاحصائية
by
أ. مراد هرشه
PDF
تحليل البيانات باستخدام برنامج spss . ا
by
Hisham Hussein
PPT
محاضرات تحليل احصائي Spss
by
chamkki999
PDF
اختيار التحليل الاحصائي المناسب 1435 -الورشة الثانية
by
researchcenterm
PPTX
Statistics
by
Ahmad Albalawi
PPS
المحاضرة الاولى تعريف علم الاحصاء والرموز الاحصائية
by
College of Agriculture , Univeristy of Diyala
كورس التحليل الاحصائي بأستخدام SPSS
by
احمد الجسار
تحليل الاستبيان
by
cherifmouh
الاختبارات الاحصائية
by
أ. مراد هرشه
تحليل البيانات باستخدام برنامج spss . ا
by
Hisham Hussein
محاضرات تحليل احصائي Spss
by
chamkki999
اختيار التحليل الاحصائي المناسب 1435 -الورشة الثانية
by
researchcenterm
Statistics
by
Ahmad Albalawi
المحاضرة الاولى تعريف علم الاحصاء والرموز الاحصائية
by
College of Agriculture , Univeristy of Diyala
What's hot
PDF
كل ما يجب أن تعرفه عن البرمجة اللغوية العصبية (1)
by
hossam888555
PDF
اختيار التحليل الاحصائي المناسب 1435 -الورشة الأولى
by
researchcenterm
PPSX
التحكم في الضغوط والوقت وترتيب الاولويات 1 2
by
Dr. Mahmoud Afara
PDF
جدارات القائد المعد للقادة
by
رؤية للحقائب التدريبية
PPSX
مهارة إعداد التقارير
by
مركز الخبرة العالمية للدراسات والاستشارات والتدريب
PDF
مهارات كتابة التقارير و اعداد الخطابات .pdf
by
MohammedRashad42
DOCX
دورة صيانة مختصر
by
Younes Almansoob
PPTX
الأساليب الإحصائية المناسبة فى البحوث العلمية
by
DrMuhammadTamerKhatt
PDF
مهارات الاتصال والتواصل م. احمد فليونة
by
Eng. Ahmed Falyouna
PPS
Strategic planning
by
HAZEM ABO ELNIL
PDF
الذكاء الاصطناعي
by
رؤية للحقائب التدريبية
PPT
خطوات البحث العلمي.ppt الجيد والقابل للتطبيق
by
essamkhalf2
PDF
Artificial Intelligence_الذكاء الإصطناعي
by
Abduljabbar Al-dhufri
PDF
التفكير الابداعي
by
رؤية للحقائب التدريبية
PPSX
برنامج أرشفة مستندات
by
Ahmed Eldib
PPTX
المحاضرة الأولى مقدمة عن الحاسوب
by
د. عائشة بليهش العمري
PDF
Teaching think skills (Ar) تعليم مهارات التفكير
by
Abdullah Muhammad
PPTX
إدارة الذات
by
ahmedmagdysaber
PPT
الخريطة الذهنية
by
mohammed alismail
PPS
مقدمة في علم الإحصاء
by
Hashim ElHadi
كل ما يجب أن تعرفه عن البرمجة اللغوية العصبية (1)
by
hossam888555
اختيار التحليل الاحصائي المناسب 1435 -الورشة الأولى
by
researchcenterm
التحكم في الضغوط والوقت وترتيب الاولويات 1 2
by
Dr. Mahmoud Afara
جدارات القائد المعد للقادة
by
رؤية للحقائب التدريبية
مهارة إعداد التقارير
by
مركز الخبرة العالمية للدراسات والاستشارات والتدريب
مهارات كتابة التقارير و اعداد الخطابات .pdf
by
MohammedRashad42
دورة صيانة مختصر
by
Younes Almansoob
الأساليب الإحصائية المناسبة فى البحوث العلمية
by
DrMuhammadTamerKhatt
مهارات الاتصال والتواصل م. احمد فليونة
by
Eng. Ahmed Falyouna
Strategic planning
by
HAZEM ABO ELNIL
الذكاء الاصطناعي
by
رؤية للحقائب التدريبية
خطوات البحث العلمي.ppt الجيد والقابل للتطبيق
by
essamkhalf2
Artificial Intelligence_الذكاء الإصطناعي
by
Abduljabbar Al-dhufri
التفكير الابداعي
by
رؤية للحقائب التدريبية
برنامج أرشفة مستندات
by
Ahmed Eldib
المحاضرة الأولى مقدمة عن الحاسوب
by
د. عائشة بليهش العمري
Teaching think skills (Ar) تعليم مهارات التفكير
by
Abdullah Muhammad
إدارة الذات
by
ahmedmagdysaber
الخريطة الذهنية
by
mohammed alismail
مقدمة في علم الإحصاء
by
Hashim ElHadi
احصاء Spss
1.
ﺠﺎﻤﻌﺔ ﺍﻟﻘﺩﺱ ﺍﻟﻤﻔﺘﻭﺤﺔ ﺍﻟﺩﻟﻴل
ﺍﻟﻌﻤﻠﻲ ﻟﻤﻘﺭﺭ ﺍﻹﺤﺼﺎﺀ ﺍﻟﺘﻁﺒﻴﻘﻲ 3625 ﺤﻘﻭﻕ ﺍﻟﻁﺒﻊ ﻤﺤﻔﻭﻅﺔ 5002 1
2.
ﺇﻋﺩﺍﺩ ﺍﻟﻤﺎﺩﺓ ﺍﻟﻌﻠﻤﻴﺔ:
ﺃ. ﻋﻤﺎﺩ ﻨﺸﻭﺍﻥ 2
3.
ﺍﻟﺼﻔﺤﺔ
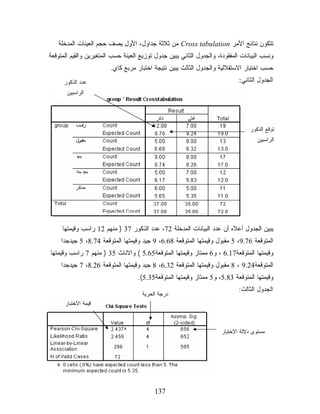
ﺍﻟﻤﻭﻀﻭﻉ ﺍﻟﺭﻗﻡ 6 ﻤﻘﺩﻤﺔ ﻋﻥ ﺒﺭﻨﺎﻤﺞ SPSSﺨﺎﺼﺔ ﺒﺎﻟﻤﻘﺭﺭ. 6 ﺍﻟﻤﻭﺍﺼﻔﺎﺕ ﺍﻟﺘﻲ ﻴﺠﺏ ﺃﻥ ﺘﺘﻭﺍﻓﺭ ﻓﻲ ﺠﻬﺎﺯ ﺍﻟﻜﻤﺒﻴﻭﺘﺭ ﻟﻠﺘﻌﺎﻤل ﻤﻊ ﺒﺭﻨﺎﻤﺞ 1. 0.21 SPSS 8 ﺘﻌﺭﻴﻑ ﺒﺭﻨﺎﻤﺞ SPSS 2. 8 ﺸﺎﺸﺎﺕ ﺒﺭﻨﺎﻤﺞ 0.21 SPSSﻭ ﻗﻭﺍﺌﻤﻪ 21 ﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻓﻲ ﺒﺭﻨﺎﻤﺞ SPSS 3. 61 ﺍﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ 4. 02 ﻜﻴﻔﻴﺔ ﺤﺴﺎﺏ ﻤﻘﺎﻴﻴﺱ ﺍﻟﻨﺯﻋﺔ ﺍﻟﻤﺭﻜﺯﻴﺔ ﻭﺍﻟﺘﺸﺘﺕ 5. 52 ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻻﺤﺼﺎﺌﻴﺔ ﻭﺁﻟﻴﺎﺕ ﺍﻟﺘﻌﺎﻤل ﻤﻌﻬﺎ ﻓﻲ ﺒﺭﻨﺎﻤﺞ .SPSS 6. 72 ﺍﻟﻭﺤﺩﺓ ﺍﻷﻭﻟﻰ: ﺍﻻﺴﺘﺩﻻل ﺍﻻﺤﺼﺎﺌﻲ ﺤﻭل ﻤﺠﺘﻤﻊ ﻭﺍﺤﺩ 92 ﺘﻘﺩﻴﺭ ﻭﺴﻁ ﻤﺠﺘﻤﻊ ﺒﻨﻘﻁﺔ ﻭ ﺒﻔﺘﺭﺓ ﺜﻘﺔ 1. 43 ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻭﻕ ﺍﻟﻤﺘﻌﻠﻘﺔ ﺒﻭﺴﻁ ﻤﺠﺘﻤﻊ ﻭﺍﺤﺩ 2. 93 ﺘﻘﺩﻴﺭ ﺍﻟﻨﺴﺒﺔ ﺒﻨﻘﻁﺔ ﻭﺒﻔﺘﺭﺓ ﺜﻘﺔ 3. 54 ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻟﻤﺘﻌﻠﻘﺔ ﻟﻨﺴﺒﺔ ﻓﻲ ﺍﻟﻤﺠﺘﻤﻊ ﺍﻟﻭﺍﺤﺩ 4. 94 ﺍﻟﻔﺭﻀﻴﺎﺕ ﻭﻓﺘﺭﺍﺕ ﺍﻟﺜﻘﺔ ﺤﻭل ﺘﺒﺎﻴﻥ ﻤﺠﺘﻤﻊ ﻭﺍﺤﺩ 5. 55 ﺍﻟﻭﺤﺩﺓ ﺍﻟﺜﺎﻨﻴﺔ: ﺍﻻﺴﺘﺩﻻل ﺍﻻﺤﺼﺎﺌﻲ ﺤﻭل ﺘﺒﺎﻴﻥ ﻤﺠﺘﻤﻌﻴﻥ 65 ﻓﺘﺭﺍﺕ ﺍﻟﺜﻘﺔ ﻭﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻭﻕ ﺒﻴﻥ ﻤﺘﻭﺴﻁ ﻤﺠﺘﻤﻌﻴﻥ ﻤﺴﺘﻘﻠﻴﻥ 1. 36 ﻓﺘﺭﺍﺕ ﺍﻟﺜﻘﺔ ﻭﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻭﻕ ﺒﻴﻥ ﻤﺘﻭﺴﻁﻲ ﻤﺠﺘﻤﻌﻴﻥ ﻤﺭﺘﺒﻁﻴﻥ. 2. 96 ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ ﻭﻓﺘﺭﺍﺕ ﺍﻟﺜﻘﺔ ﺤﻭل ﺍﻟﻨﺴﺒﺔ ﺒﻴﻥ ﺘﺒﺎﻴﻥ ﻤﺠﺘﻤﻌﻴﻥ 3. 57 ﺍﻟﻭﺤﺩﺓ ﺍﻟﺜﺎﻟﺜﺔ: ﺍﻻﻨﺤﺩﺍﺭ ﻭﺍﻻﺭﺘﺒﺎﻁ 77 ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻟﻤﺘﻌﻠﻘﺔ ﺒﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻭﻤﻘﻁﻌﻪ 1. 78 ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻟﻤﺘﻌﻠﻘﺔ ﺒﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ )ﺒﻴﺭﺴﻭﻥ(. 2. 3
4.
ﺍﻟﺼﻔﺤﺔ
ﺍﻟﻤﻭﻀﻭﻉ ﺍﻟﺭﻗﻡ 09 ﺍﻟﻭﺤﺩﺓ ﺍﻟﺭﺍﺒﻌﺔ: ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻷﺤﺎﺩﻱ ﻭﺍﻟﺜﻨﺎﺌﻲ 19 ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻷﺤﺎﺩﻱ 1. 79 ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﺜﻨﺎﺌﻲ 2. 401 ﺍﻟﻭﺤﺩﺓ ﺍﻟﺨﺎﻤﺴﺔ: ﺍﻟﻁﺭﻕ ﻏﻴﺭ ﺍﻟﻤﻌﻠﻤﻴﺔ 501 ﻤﻘﺎﺭﻨﺔ ﻭﺴﻴﻁ ﻤﺠﺘﻤﻊ ﺒﻭﺴﻴﻁ ﺍﻟﻌﻴﻨﺔ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ 1. ﻓﻲ ﺤﺎﻟﺔ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﺼﻐﻴﺭﺓ ﻓﻲ ﺤﺎﻟﺔ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﻜﺒﻴﺭﺓ 901 ﺍﻟﻤﻘﺎﺭﻨﺔ ﺒﻴﻥ ﻭﺴﻴﻁ )ﺘﻭﺯﻴﻊ( ﻤﺠﺘﻤﻌﻴﻥ ﻤﺭﺘﺒﻁﻴﻥ 2. 901 ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ 311 ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﺨﺘﺒﺎﺭ ﻭﻟﻜﻜﺴﻥ 811 ﺍﺨﺘﺒﺎﺭ ﻤﺎﻥ-ﻭﻴﺘﻨﻲ ﻟﻠﻤﻘﺎﺭﻨﺔ ﺒﻴﻥ ﻭﺴﻴﻁ ﻤﺠﺘﻤﻌﻴﻥ ﻤﺴﺘﻘﻠﻴﻥ. Mann 3. Whitney Test 421 ﺍﺨﺘﺒﺎﺭ ﻜﺭﻭﺴﻜﺎل-ﻭﺍﻻﺱ ﻟﻠﻤﻘﺎﺭﻨﺔ ﺒﻴﻥ ﺘﻭﺯﻴﻊ ﻋﺩﺓ ﻤﺠﺘﻤﻌﺎﺕ ﻤﺴﺘﻘﻠﺔ 4. 031 ﺍﺨﺘﺒﺎﺭ ﺍﻻﺴﺘﻘﻼﻟﻴﺔ 5. 831 ﺍﺨﺘﺒﺎﺭ ﺠﻭﺩﺓ ﺍﻟﻤﻁﺎﺒﻘﺔ 6. 341 ﺍﺨﺘﺒﺎﺭ ﺍﻟﻌﺸﻭﺍﺌﻴﺔ. 7. 641 ﺍﺨﺘﺒﺎﺭ ﻓﺭﻴﺩﻤﺎﻥ ﻟﻠﻤﻘﺎﺭﻨﺔ ﺒﻴﻥ ﺘﻭﺯﻴﻊ ﻋﺩﺓ ﻤﺠﺘﻤﻌﺎﺕ ﻤﺭﺘﺒﻁﺔ 8. 4
5.
ﻤﻘﺩﻤﺔ ﻤﺨﺘﺼﺭﺓ ﻋﻥ
ﺒﺭﻨﺎﻤﺞ 0.21 SPSS 5
6.
ﻤﻘﺩﻤﺔ ﻋﻥ ﺒﺭﻨﺎﻤﺞ
SPSSﺨﺎﺼﺔ ﺒﺎﻟﻤﻘﺭﺭ ﻓﻲ ﻫﺫﺍ ﺍﻟﺠﺯﺀ ﻤﻥ ﻫﺫﺍ ﺍﻟﺩﻟﻴل ﺴﻨﺘﻌﺭﺽ ﺇﻟﻰ ﺍﻟﻤﺒﺎﺩﺉ ﺍﻻﺴﺎﺴﻴﺔ ﺍﻟﺘﻲ ﺴﺘﺤﺘﺎﺠﻬﺎ ﻻﺴﺘﺨﺩﺍﻡ ﺒﺭﻨﺎﻤﺞ 0.21 SPSSﺍﻟﺘﻲ ﺴﺘﺴﺎﻋﺩﻙ ﻓﻲ ﺘﻨﻔﻴﺫ ﺍﻟﺠﺯﺀ ﺍﻟﻌﻤﻠﻲ ﻤﻥ ﻤﻘﺭﺭ ﺍﻻﺤﺼﺎﺀ ﺍﻟﺘﻁﺒﻴﻘﻲ ، ﺤﻴﺙ ﺴﻨﺘﻌﺭﻑ ﻋﻠﻰ ﺒﺭﻨﺎﻤﺞ 0.21 SPSSﻭﻋﻠﻰ ﺍﻟﺸﺎﺸﺎﺕ ﺍﻟﺘﻲ ﻴﺠﺏ ﺃﻥ ﺘﺘﻌﺎﻤل ﻤﻌﻬﺎ ﻭﺍﻟﺘﻌﺭﻑ ﻋﻠﻰ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻭﻜﻴﻔﻴﺔ ﺘﻌﺭﻴﻑ ﻫﺫﻩ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻭﺍﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻭﻤﻥ ﺜﻡ ﻜﻴﻔﻴﺔ ﺤﺴﺎﺏ ﻤﻘﺎﻴﻴﺱ ﺍﻟﻨﺯﻋﺔ ﺍﻟﻤﺭﻜﺯﻴﺔ ﻓﻲ ﺒﺭﻨﺎﻤﺞ 0.21 SPSSﻭﻓﻲ ﺍﻟﻨﻬﺎﻴﺔ ﺴﻨﺘﻌﺭﻑ ﻋﻠﻰ ﺘﻌﺭﻴﻔﺎﺕ ﺨﺎﺼﺔ ﺒﺒﺭﻨﺎﻤﺞ SPSSﻟﺘﻤﻜﻨﻙ ﻤﻥ ﺍﻟﺘﻌﺎﻤل ﻤﻊ ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻻﺤﺼﺎﺌﻴﺔ ﻭﻜﻴﻔﻴﺔ ﺍﻟﺘﻌﺎﻤل ﻤﻊ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻻﺤﺼﺎﺌﻴﺔ ﺍﻟﻤﻭﺠﻭﺩﺓ ﻓﻲ ﺍﻟﺒﺭﻨﺎﻤﺞ. 1: ﺍﻟﻤﻭﺍﺼﻔﺎﺕ ﺍﻟﺘﻲ ﻴﺠﺏ ﺃﻥ ﺘﺘﻭﺍﻓﺭ ﻓﻲ ﺠﻬﺎﺯ ﺍﻟﻜﻤﺒﻴﻭﺘﺭ ﻟﻠﺘﻌﺎﻤل ﻤﻊ ﺒﺭﻨﺎﻤﺞ SPSS 0.21 ﻭﻜﻴﻔﻴﺔ ﺘﺸﻐﻴﻠﻪ ﻟﻜﻲ ﺘﺴﺘﻁﻴﻊ ﺍﻟﻌﻤل ﻤﻊ ﺒﺭﻨﺎﻤﺞ 0.21 SPSSﻴﺠﺏ ﺃﻥ ﺘﺘﻭﻓﺭ ﻓﻲ ﺠﻬﺎﺯ ﺍﻟﻜﻤﺒﻴﻭﺘﺭ ﺒﻌﺽ ﺍﻟﻤﻭﺍﺼﻔﺎﺕ ﺃﻭ ﺍﻟﻤﺘﻁﻠﺒﺎﺕ ﻭﺍﻟﺤﺩ ﺍﻷﺩﻨﻰ ﻤﻨﻬﺎ ﻫﻲ ﻜﺎﻟﺘﺎﻟﻲ: 1. Processor (CPU): Pentium or Pentium-class processor running at 90MHz or .faster 2. Memory (RAM): 128MB minimum 3. Display type : SVGA (800 x 600 resolution) or higher 4. Hard Disk Space: Minimum of 220MB available disk space 5. .)Media: CD-ROM (for installation 6. Mouse: Required 7. .Platform: Windows 98/Me/NT4 with SP6/2000/XP ﺘﺸﻐﻴل ﺒﺭﻨﺎﻤﺞ SPSS ﺒﻌﺩ ﺃﻥ ﺘﻘﻭﻡ ﺒﺘﺜﺒﻴﺕ ﺒﺭﻨﺎﻤﺞ 0.21 SPSSﻋﻠﻰ ﺍﻟﺠﻬﺎﺯ ﻨﻘﻭﻡ ﺒﺘﺸﻐﻴﻠﻪ ﻋﻥ ﻁﺭﻴﻕ ﻤﺠﻤﻭﻋﺔ ﺍﻟﺒﺭﺍﻤﺞ ﻓﻲ ﺍﻟﻘﺎﺌﻤﺔ ﺍﺒﺩﺃ 6
7.
ﻓﺘﻅﻬﺭ ﻟﻨﺎ ﺍﻟﺸﺎﺸﺔ
ﺍﻟﺘﺎﻟﻴﺔ ﻟﺤﻅﻴﺎ ﹰ ﺘﺤﺘﻭﻱ ﺍﻟﺸﺎﺸﺔ ﺍﻟﺴﺎﺒﻘﺔ ﻋﻠﻰ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﺨﺎﺼﺔ ﺒﺎﻟﻤﺴﺘﺨﺩﻡ ﺍﻟﺘﻲ ﺘﻡ ﺍﺩﺨﺎﻟﻬﺎ ﺨﻼل ﻋﻤﻠﻴﺔ ﺘﺜﺒﻴﺕ ﺒﺭﻨﺎﻤﺞ • 0.21 .SPSS 7
8.
2: ﺘﻌﺭﻴﻑ ﺒﺭﻨﺎﻤﺞ
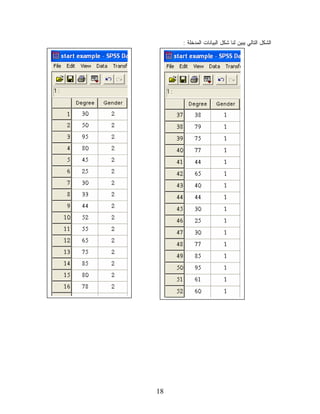
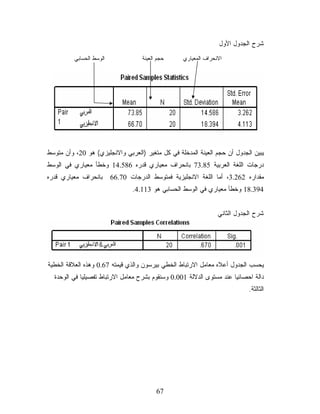
SPSS ﺒﻌﺩ ﺘﺸﻐﻴل ﺍﻟﺒﺭﻨﺎﻤﺞ، ﺴﻨﺘﻌﺭﻑ ﻋﻠﻰ ﻜﺎﻤل ﺒﻴﺌﺔ ﺍﻟﺒﺭﻨﺎﻤﺞ ﻤﻥ ﺸﺎﺸﺎﺕ، ﻭﻜﻴﻔﻴﺔ ﺍﻟﺘﻌﺎﻤل ﻤﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ، ﻭﻤﺎ ﻫﻲ ﺍﻟﺒﺭﺍﻤﺞ ﺍﻟﺘﻲ ﻴﺴﺘﻁﻴﻊ ﺃﻥ ﻴﺘﻌﺎﻤل ﻤﻌﻬﺎ ﺍﻟﺒﺭﻨﺎﻤﺞ ﻭﻁﺒﻴﻌﺔ ﺍﻟﻨﺘﺎﺌﺢ ﻭﺍﻟﺩﻭﺍل ﺍﻻﺤﺼﺎﺌﻴﺔ ﺍﻟﺘﻲ ﻴﻁﺒﻘﻬﺎ ﺍﻟﺒﺭﻨﺎﻤﺞ، ﺒﺎﺨﺘﺼﺎﺭ ﺴﻨﺘﻌﺭﻑ ﻋﻠﻰ ﺍﻤﻜﺎﻨﺎﺕ ﻫﺫﺍ ﺍﻟﺒﺭﻨﺎﻤﺞ. ﺸﺎﺸﺎﺕ ﺒﺭﻨﺎﻤﺞ 0.21 SPSS 1. ﻴﺘﻜﻭﻥ ﺒﺭﻨﺎﻤﺞ 0.21 SPSSﻤﻥ 8 ﺸﺎﺸﺎﺕ، ﻟﻜل ﺸﺎﺸﺔ ﻤﻥ ﻫﺫﻩ ﺍﻟﺸﺎﺸﺎﺕ ﺍﺴﺘﺨﺩﺍﻤﺎﺕ ﻭﻤﻬﺎﻡ ﺨﺎﺼﺔ ﺒﻬﺎ، ﻭﻤﻥ ﺍﻟﺠﺩﻴﺭ ﺒﺎﻟﺫﻜﺭ ﺃﻥ ﺍﺴﺘﺨﺩﺍﻡ ﻫﺫﺍ ﺍﻟﺒﺭﻨﺎﻤﺞ ﺨﻼل ﻫﺫﺍ ﺍﻟﻤﻘﺭﺭ ﻻ ﻴﺘﻁﻠﺏ ﻤﻨﻙ ﺍﻟﺘﻌﺎﻤل ﻤﻊ ﺠﻤﻴﻊ ﺍﻟﺸﺎﺸﺎﺕ ﺍﻟﺜﻤﺎﻨﻴﺔ، ﻭﻟﻜﻥ ﻴﺠﺏ ﺃﻥ ﺘﺘﻤﻜﻥ ﻤﻥ ﺍﻟﺘﻌﺎﻤل ﻤﻊ ﺸﺎﺸﺘﻴﻥ ﺃﺴﺎﺴﻴﺘﻴﻥ ﻓﻘﻁ ﻭﻫﻤﺎ ﺸﺎﺸﺔ ﺍﻟﺒﻴﺎﻨﺎﺕ Data Editorﻭﺸﺎﺸﺔ ﻋﺎﺭﺽ ﺍﻟﻨﺘﺎﺌﺞ . Viewer :(Dataﻫﻲ ﺃﻭل ﺸﺎﺸﺔ ﺘﺭﺍﻫﺎ ﻋﻨﺩﻤﺎ ﺘﺸﻐل ﺒﺭﻨﺎﻤﺞ ﺸﺎﺸﺔ ﺍﻟﺘﻌﺎﻤل ﻤﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ )Editor ﺃ. SPSSﻭﻤﻥ ﺨﻼﻟﻬﺎ ﺘﻌﺭﺽ ﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﻠﻔﺎﺕ ﻭﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻭﺘﻌﺭﻴﻑ ﻫﺫﻩ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺘﻲ ﺘﺘﻜﻭﻥ ﻤﻨﻬﺎ ﺘﻠﻙ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﻗﻴﻤﻬﺎ ﻭﺘﻨﻘﺴﻡ ﻫﺫﻩ ﺍﻟﺸﺎﺸﺔ ﺇﻟﻰ ﻭﺭﻗﺘﻲ ﻋﻤل Spread Sheetﻭﻟﻜﻥ ﻤﺠﺎﺯﺍ ﺴﻨﺴﻤﻴﻬﻤﺎ ﺸﺎﺸﺘﻴﻥ ﹰ ﻓﺭﻋﻴﺘﻴﻥ ﻭﻫﻤﺎ: ﻭﻫﻲ ﺍﻟﺠﺯﺀ ﺍﻟﺫﻱ ﺘﻌﺭﺽ ﻓﻴﻪ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺸﺎﺸﺔ ﺍﻅﻬﺎﺭ ﺍﻟﺒﻴﺎﻨﺎﺕ :Data View • ﻭﺘﻜﻭﻥ ﻋﻠﻰ ﺸﻜل Spread Sheetﻭﻴﻜﻭﻥ ﻓﻲ ﺃﻋﻠﻰ ﻜل ﻋﻤﻭﺩ ﺍﺴﻤﺎﺀ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺘﻲ ﻴﺘﻜﻭﻥ ﻤﻨﻬﺎ ﺍﻟﻤﻠﻑ ﻜﻤﺎ ﻫﻭ ﻤﺒﻴﻥ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 8
9.
ﻭﻴﻌﺒﺭ ﻜل ﺴﻁﺭ
ﻤﻥ ﻫﺫﻩ ﺍﻟﺸﺎﺸﺔ ﻋﻥ ﺒﻴﺎﻨﺎﺕ ﺤﺎﻟﺔ ﻤﻌﻴﻨﺔ ﺃﻭ ﺴﺠل ﻤﻌﻴﻥ ﻷﺤﺩ ﺃﻓﺎﺭﺩ ﺍﻟﻌﻴﻨﺔ، ﻭﻜل ﻋﻤﻭﺩ ﻴﻌﺒﺭ ﻋﻥ ﺒﻴﺎﻨﺎﺕ ﺃﺤﺩ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺃﻱ ﺒﻴﺎﻨﺎﺕ ﺍﻟﻌﻴﻨﺔ ﻜﺎﻤﻠﺔ ﻓﻲ ﺫﻟﻙ ﺍﻟﻤﺘﻐﻴﺭ. ﻭﻫﻭ ﺍﻟﺠﺯﺀ ﺍﻟﺨﺎﺹ ﺒﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺸﺎﺸﺔ ﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ : Variable View • ﻭﻨﻭﻉ ﺍﻟﻤﺘﻐﻴﺭ ﻭﻋﺭﻀﻪ ﻭﻋﻨﻭﺍﻨﻪ ﻭﻗﻴﻤﻪ ﻭﻗﻴﺎﺱ ﺘﺩﺭﻴﺠﻪ ﺇﻟﺦ...، ﺒﺤﻴﺙ ﻴﻜﻭﻥ ﻜل ﺴﻁﺭ ﻤﻥ ﻫﺫﻩ ﺍﻟﺸﺎﺸﺔ ﻴﻌﺒﺭ ﻋﻥ ﺘﻌﺭﻴﻑ ﻤﺘﻐﻴﺭ ﻤﻌﻴﻥ ﻜﻤﺎ ﻫﻭ ﻤﺒﻴﻥ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 9
10.
Variable Viewﻋﻥ
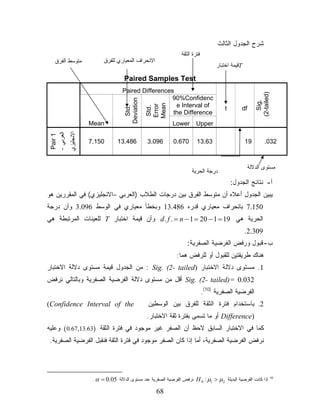
ﻁﺭﻴﻕ ﻭﻴﻤﻜﻨﻙ ﺍﻻﻨﺘﻘﺎل ﺒﻴﻥ ﺸﺎﺸﺘﻲ ﺍﻅﻬﺎﺭ ﺍﻟﺒﻴﺎﻨﺎﺕ Data Viewﻭﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﻨﻘﺭ ﺍﻟﻤﺯﺩﻭﺝ ﻋﻠﻰ ﺃﻋﻠﻰ ﺃﻱ ﻋﻤﻭﺩ )ﻤﺘﻐﻴﺭ( ﻓﻲ Data Viewﺃﻭ ﺒﺎﺨﺘﻴﺎﺭ ﺸﺎﺸﺔ Variable Viewﺃﺴﻔل ﺸﺎﺸﺔ ،Data Editorﺃﻭ ﺍﻟﻨﻘﺭ ﺍﻟﻤﺯﺩﻭﺝ ﻋﻠﻰ ﺴﻁﺭ ﺘﻌﺭﻴﻑ ﺃﻱ ﻤﻥ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻓﻲ ﺸﺎﺸﺔ .Variable View ﻭﻫﻲ ﺍﻟﺸﺎﺸﺔ ﺍﻟﺘﻲ ﺘﻅﻬﺭ ﻋﻠﻴﻬﺎ ﻨﺘﺎﺌﺞ ﺍﻟﺘﺤﻠﻴل ﺍﻻﺤﺼﺎﺌﻲ ﻭﺘﻅﻬﺭ ﺏ: ﺸﺎﺸﺔ ﺍﻟﻌﺎﺭﺽ :Viewer ﻫﺫﺍ ﺍﻟﺸﺎﺸﺔ ﻋﻨﺩ ﺍﺠﺭﺍﺀ ﺃﻭل ﺇﺠﺭﺍﺀ ﺍﺤﺼﺎﺌﻲ ﻓﺘﻅﻬﺭ ﻨﺘﻴﺠﺘﻪ ﻓﻲ ﺸﺎﺸﺔ ﺠﺩﻴﺩﺓ ﻫﻲ ﺸﺎﺸﺔ .Viewerﺒﺎﻤﻜﺎﻨﻙ ﻤﻥ ﺨﻼﻟﻬﺎ ﺍﻟﺘﻌﺩﻴل ﻭﺍﺴﺘﻌﺭﺍﺽ ﺍﻟﻨﺘﺎﺌﺞ، ﺍﻅﻬﺎﺭ ﺃﻭ ﺍﺨﻔﺎﺀ ﺒﻌﺽ ﺃﻭ ﻜل ﺍﻟﻨﺘﺎﺌﺞ، ﻭﺘﺒﺎﺩل ﺍﻟﻨﺘﺎﺌﺞ ﻤﻊ ﺸﺎﺸﺎﺕ ﺃﺨﺭﻯ. ﺘﺘﻜﻭﻥ ﺸﺎﺸﺔ Viewerﻤﻥ ﺠﺯﺌﻴﻥ، ﺍﻟﺠﺯﺀ ﺍﻷﻭل ﻫﻭ ﺍﻟﺠﺯﺀ ﺍﻷﻴﺴﺭ ﺍﻟﺨﺎﺹ ﺒﻌﻨﻭﺍﻥ ﻭﺍﻟﻌﻨﻭﺍﻴﻥ ﺍﻟﻔﺭﻋﻴﺔ ﻟﻺﺠﺭﺍﺀﺍﺕ ﺍﻻﺤﺼﺎﺌﻴﺔ ﺍﻟﺘﻲ ﻴﻨﻔﺫﻫﺎ ﺍﻟﻤﺴﺘﺨﺩﻡ، ﻭﺍﻟﺠﺯﺀ ﺍﻷﻴﻤﻥ ﺍﻟﺨﺎﺹ ﻫﻭ ﺍﻟﺠﺯﺀ ﺍﻟﺫﻱ ﻴﺤﺘﻭﻱ ﻋﻠﻰ ﺍﻟﻨﺘﺎﺌﺞ ﺍﻻﺤﺼﺎﺌﻴﺔ ﻟﻼﺠﺭﺍﺀ ﺍﻻﺤﺼﺎﺌﻲ، ﻭﻤﺎ ﺘﺤﺘﻭﻴﻪ ﻤﻥ ﺠﺩﺍﻭل ﻭﺭﺴﻭﻤﺎﺕ ﺃﻭ ﺤﺘﻰ ﺘﻁﺒﻴﻘﺎﺕ ﺃﺨﺭﻯ ﻜﻤﺎ ﻫﻭ ﻤﺒﻴﻥ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 01
11.
ﺍﻟﻘﻭﺍﺌﻡ )(Menus
2. ﻟﻜل ﺸﺎﺸﺔ ﻤﻥ ﺸﺎﺸﺎﺕ 0.21 SPSSﺘﺘﻨﺎﺴﺏ ﻤﻊ ﻤﻬﻤﺎﺘﻬﺎ ، ﻭﻜل ﻗﺎﺌﻤﺔ ﻓﻴﻬﺎ ﺍﻟﻌﺩﻴﺩ ﻤﻥ ﺍﻟﻤﻬﺎﻡ ﻭﻟﻜﻥ ﺍﻟﻤﺸﺘﺭﻙ ﻓﻴﻬﺎ ﺠﻤﻴﻌﺎ ﻗﺎﺌﻤﺘﻴﻥ ) (Analyze, Graphsﺍﻟﺘﻲ ﺴﻨﺴﺘﺨﺩﻤﻬﺎ ﻻﺤﻘﺎ. ﹰ ﹰ 11
12.
3: ﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ
ﻓﻲ ﺒﺭﻨﺎﻤﺞ SPSS ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻫﻲ ﻋﺒﺎﺭﺓ ﻋﻥ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﺘﻲ ﺴﺘﺩﺨﻠﻬﺎ، ﻓﺘﻜﻭﻥ ﻋﻠﻰ ﺸﻜل ﺍﺴﻤﺎﺀ ﺃﻭ ﺃﺭﻗﺎﻡ ﻋﻠﻰ ﺸﻜل ﺭﻤﻭﺯ ﻤﻌﻴﻨﺔ ﺃﻭ ﻜﻤﻴﺎﺕ، ﻭﻴﺘﻌﺎﻤل ﺒﺭﻨﺎﻤﺞ SPSSﻤﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻋﻠﻰ ﺃﻨﻬﺎ ﻤﺘﻐﻴﺭﺍﺕ ﻤﺜل ﺃﻥ ﻨﺨﺘﺎﺭ ﺍﻟﻤﺘﻐﻴﺭ Ageﻹﺩﺨﺎل ﺒﻴﺎﻨﺎﺕ ﺍﻟﻌﻤﺭ ﻭﻫﻜﺫﺍ. ﻭﻴﻘﺒل ﺒﺭﻨﺎﻤﺞ SPSSﺍﺴﻤﺎﺀ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻭﺍﻟﺒﻴﺎﻨﺎﺕ ﺒﺎﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻭﺍﻻﻨﺠﻠﻴﺯﻴﺔ. ﺍﻟﻤﺘﻐﻴﺭ Variable ﺴﺠل Case ﻭﻴﺘﻡ ﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻋﻥ ﻁﺭﻴﻕ ﺸﺎﺸﺔ Variable Viewﻓﻜل ﻤﺘﻐﻴﺭ ﻨﺭﻴﺩ ﺘﻌﺭﻴﻔﻪ ﻴﻜﻭﻥ ﻟﻪ ﺴﺠل )ﺴﻁﺭ( ﺘﻌﺭﻴﻑ ﻜﻤﺎ ﻫﻭ ﻤﺒﻴﻥ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺴﺎﺒﻕ ﻭﻴﺸﻤل ﺍﺴﻡ ﺍﻟﻤﺘﻐﻴﺭ ﻭﻨﻭﻋﻪ، ﻭﻋﺭﻀﻪ ﻭﺘﺩﺭﻴﺞ ﻗﻴﺎﺴﻪ... ﻭﺍﻻﻥ ﻋﺯﻴﺯﻱ ﺍﻟﺩﺍﺭﺱ ﺴﻨﻭﻀﺢ ﻜل ﻋﻨﺼﺭ ﻤﻥ ﻋﻨﺎﺼﺭ ﺍﻟﺴﺠل: ﺍﺴﻤﺎﺀ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ Variable Name 1. ﻟﻜﻲ ﺘﻌﺭﻑ ﺍﻟﻤﺘﻐﻴﺭ ﻴﺠﺏ ﺃﻥ ﺘﻜﺘﺏ ﺍﺴﻡ ﺍﻟﻤﺘﻐﻴﺭ ﻓﻲ ﺴﻁﺭ ﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭ ﻓﻲ ﺸﺎﺸﺔ Variables Viewﻓﻴﻤﻜﻥ ﺃﻥ ﻴﻜﻭﻥ ﺍﺴﻡ ﺍﻟﻤﺘﻐﻴﺭ ﻫﻭ ﺍﻟﺠﻨﺱ ﻭﺍﻟﺫﻱ ﺴﻨﺴﻤﻴﻪ .gender 21
13.
ﻨﻭﻉ ﺍﻟﻤﺘﻐﻴﺭ ﺍﺴﻡ
ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻤﻨﺎﺯل ﺍﻟﻌﺸﺭﻴﺔ ﻭﺼﻑ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻜﻭﺩ ﻋﺭﺽ ﺍﻟﻌﻤﻭﺩ ﺘﺩﺭﻴﺞ ﻤﻘﻴﺎﺴﻪ ﻭﻴﺠﺏ ﺃﻥ ﺘﺤﻘﻕ ﺍﺴﻤﺎﺀ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺸﺭﻭﻁ ﺍﻟﺘﺎﻟﻴﺔ: ﻴﺠﺏ ﺍﻥ ﻴﺒﺩﺃ ﺒﺤﺭﻑ ﻭﻻ ﻴﻤﻜﻥ ﺃﻥ ﻴﻨﺘﻬﻲ ﺒﻔﺘﺭﺓ ﻭﺃﻥ ﻻ ﻴﺘﺠﺎﻭﺯ ﻋﺩﺩ ﺍﻻﺤﺭﻑ 46 ﻭﺃﻥ ﻻ ﻴﺘﻜﺭﺭ ﺍﺴﻡ • ﺍﻟﻤﺘﻐﻴﺭ ﻻ ﻴﻤﻜﻥ ﺍﺴﺘﺨﺩﺍﻡ ﺍﻟﻔﺭﺍﻍ ﺒﻴﻥ ﺍﻻﺤﺭﻑ • ﻻ ﻴﻤﻜﻨﻙ ﺍﺴﺘﺨﺩﺍﻡ ﺍﻟﺭﻤﻭﺯ ﺃﻭ ﺍﻻﺸﺎﺭﺍﺕ ﻤﺜل %، ^، |، #، $، &، ﺃﻭ ﺍﻷﻗﻭﺍﺱ. • ﻻ ﻴﻤﻜﻨﻙ ﺍﺴﺘﺨﺩﺍﻡ ﻋﻼﻤﺎﺕ ﺍﻟﺘﺭﻗﻴﻡ ﻤﺜل ؟ ! : * ، “ ; ‘ • ﻤﻤﻨﻭﻉ ﺃﻥ ﻴﻜﻭﻥ ﺃﺴﻡ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺃﺤﺩ ﺍﻟﻜﻠﻤﺎﺕ ﺍﻟﺘﺎﻟﻴﺔ ﻷﻨﻬﺎ ﺍﺴﻤﺎﺀ ﻤﺤﺠﻭﺯﺓ ﻷﻭﺍﻤﺭ ﻤﻌﻴﻨﺔ ﻓﻲ ﺒﺭﻨﺎﻤﺞ • SPSSﻤﺜل .)…(ALL, NE, EQ, TO, LE, LT, BY, OR, GT, AND, NOT, GE, WITH, etc ﺃﻨﻭﺍﻉ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ Variable Types 2. ﻭﻫﻨﺎ ﻟﻜﻲ ﺘﺘﻌﺎﻤل ﻤﻊ ﺍﻟﻤﻭﺍﻀﻴﻊ ﺍﻟﻤﻭﺠﻭﺩﺓ ﻓﻲ ﺍﻟﻤﻘﺭﺭ ﻋﻠﻴﻙ ﻓﻘﻁ ﺃﻥ ﺘﺘﻌﺎﻤل ﻓﻘﻁ ﻤﻊ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺭﻗﻤﻴﺔ ﻭﺍﻟﺘﻲ ﺴﻨﺸﺭﺤﻬﺎ ﺘﻔﺼﻴﻠﻴﺎ. ﹰ ﻟﺘﻌﺭﻴﻑ ﻨﻭﻉ ﺍﻟﻤﺘﻐﻴﺭ ﻓﻲ ﺸﺎﺸﺔ Variable Viewﻓﻲ ﺒﺭﻨﺎﻤﺞ SPSS ﻴﺠﺏ ﺃﻥ ﺘﻀﻐﻁ ﻫﻨﺎ ﺤﺘﻰ ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ ﻭﻤﻥ ﺜﻡ ﺘﺨﺘﺎﺭ ﻨﻭﻉ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺫﻱ ﺘﺭﻴﺩ ﺘﻌﺭﻴﻔﻪ ﻭﺃﻨﻭﺍﻉ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﻤﻤﻜﻨﺔ ﻫﻲ: 31
14.
1:ﺍﻟﺭﻗﻤﻲ ) :(Numericﻭﻫﻲ
ﺍﻟﺒﻴﺎﻨﺎﺕ )ﺍﻟﻤﺘﻐﻴﺭﺍﺕ( ﺍﻟﺘﻲ ﺘﻜﻭﻥ ﻗﻴﻤﻬﺎ ﺍﺭﻗﺎﻡ، ﻭﺍﻟﻤﺘﻐﻴﺭ ﻫﻨﺎ ﻴﻘﺒل ﺍﻻﺭﻗﺎﻡ ﺒﺼﻴﻎ ﻤﻌﻴﻨﺔ ﻤﺜل Scientific Notationﻭﻏﻴﺭﻫﺎ. ﻭﻫﻲ ﻨﻭﻋﻴﻥ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﻤﺘﺼﻠﺔ :Continuouseﻭﻫﻲ ﻤﺜل ﺍﻟﻌﻤﺭ ﻭﺍﻟﻭﺯﻥ ﻭﺍﻟﻁﻭل ﻭﺍﻟﺭﺍﺘﺏ ﻭﺩﺭﺠﺔ أ. ﺍﻟﻁﺎﻟﺏ .... ﺃﻱ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺘﻲ ﻗﻴﻤﻬﺎ ﻏﻴﺭ ﻤﺤﺩﻭﺩﺓ ﺍﻟﻌﺩﺩ. ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﻨﻭﻋﻴﺔ :Catogorialﻭﻫﻲ ﻤﺜل ﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ ﻭﺍﻟﺤﺎﻟﺔ ﺍﻻﺠﺘﻤﺎﻋﻴﺔ ﻭﺍﻟﻤﺅﻫل ﺍﻟﻌﻠﻤﻲ ب. ﺃﻱ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺘﻲ ﻗﻴﻤﻬﺎ ﻤﺤﺩﻭﺩﺓ ﺍﻟﻌﺩﺩ ، ﻓﻤﺜﻼ ﻤﻤﻜﻥ ﺍﻥ ﺘﻌﺭﻑ ﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ ﻋﻠﻰ ﺃﺴﺎﺱ ﺃﻨﻪ ﺭﻗﻤﻲ ﺒﺤﻴﺙ ﻴﻜﻭﻥ ﺫﻜﺭ=1 ﻭﺃﻨﺜﻰ =2. ﻭﻫﻜﺫﺍ ﺃﻱ ﺃﻥ ﺘﻜﻭﻥ ﺍﻟﻘﻴﻡ ﺍﻟﻤﺩﺨﻠﺔ ﻓﻌﻠﻴﺎ ﻫﻲ ﺃﺭﻗﺎﻡ ﻭﻟﻜﻥ ﹰ ﺍﻟﺭﻗﻡ ﻴﺭﻤﺯ ﺇﻟﻰ ﻨﻭﻉ ﺃﻭ ﺘﺼﻨﻴﻑ ﻟﻠﻤﺘﻐﻴﺭ. 2.ﻤﺘﻐﻴﺭ ﺍﻟﻔﺎﺼﻠﺔ :Comma 3.ﻤﺘﻐﻴﺭ ﺍﻟﻨﻘﻁﺔ :Dot 4.ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻌﻠﻤﻲ :Scientific Notation 5.ﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺘﺎﺭﻴﺦ Date 6.ﻤﺘﻐﻴﺭ ﺍﻟﻌﻤﻼﺕ :Custom Currency 7.ﻤﺘﻐﻴﺭ ﻋﻼﻤﺔ ﺍﻟﺩﻭﻻﺭ :Dollar 8.ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺤﺭﻓﻲ :String ﻭﻫﻲ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺘﻲ ﺘﻜﻭﻥ ﺒﻴﺎﻨﺎﺘﻬﺎ ﻋﻠﻰ ﺸﻜل ﺃﺤﺭﻑ ﺃﻭ ﻜﻠﻤﺎﺕ ﺃﻭ ﺤﺘﻰ ﺃﺭﻗﺎﻡ ﺃﻱ ﺃﻨﻙ ﺘﺴﺘﻁﻴﻊ ﺃﻥ ﺘﻜﺘﺏ ﻓﻴﻬﺎ ﺃﻱ ﺸﻲﺀ. ﻭﺘﻨﻘﺴﻡ ﺇﻟﻰ ﻨﻭﻋﻴﻥ ﺃ.ﻤﺘﻐﻴﺭﺍﺕ ﺤﺭﻓﻴﺔ: ﻭﺘﺴﺘﺨﺩﻡ ﻓﻲ ﺤﺎﻟﺔ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺃﻥ ﺘﻜﻭﻥ ﺤﺭﻓﻴﺔ ﻏﻴﺭ ﻤﺼﻨﻔﺔ ﻤﺜل ﻤﺘﻐﻴﺭ ﺍﺴﻡ ﺍﻟﻁﺎﻟﺏ ﺏ.ﻤﺘﻐﻴﺭﺍﺕ ﻨﻭﻋﻴﺔ: ﻭﻫﺫﻩ ﺍﻟﺤﺎﻟﺔ ﻋﻨﺩﻤﺎ ﺘﻜﻭﻥ ﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺤﺭﻓﻲ ﺒﻴﺎﻨﺎﺕ ﻤﺼﻨﻔﺔ ﻤﺜل ﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ ﻜﻤﺎ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﻨﻭﻋﻴﺔ ﺍﻟﺭﻗﻤﻴﺔ ﻟﻜﻥ ﻴﻜﻭﻥ ﺭﻤﺯ ﺍﻟﺫﻜﺭ ﻤﺜﻼ "ﺫ" ﻭﺍﻻﻨﺜﻰ "ﺙ". :Widthﻭﻫﻭ ﻋﺩﺩ ﺨﺎﻨﺎﺕ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﺘﻲ ﻨﺭﻴﺩ ﺍﺩﺨﺎﻟﻬﺎ. 3. ﻋﺭﺽ ﺍﻟﺒﻴﺎﻨﺎﺕ :Decimalﻭﻫﻭ ﻋﺩﺩ ﺍﻟﺨﺎﻨﺎﺕ ﺍﻟﻌﺸﺭﻴﺔ ﺍﻟﺘﻲ ﺴﻴﺴﺘﻌﻤﻠﻬﺎ ﺍﻟﻤﺴﺘﺨﺩﻡ ﻓﻲ ﻋﻤﻠﻴﺔ ﻋﺩﺩ ﺍﻟﻤﻨﺎﺯل ﺍﻟﻌﺸﺭﻴﺔ 4. ﺍﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ. 41
15.
ﺃﺤﻴﺎﻨﺎ ﺘﺘﺸﺎﺒﻪ ﺃﺴﻤﺎﺀ
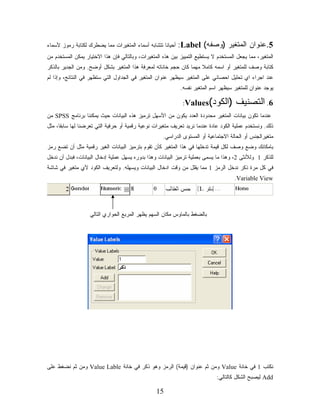
ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻤﻤﺎ ﻴﻀﻁﺭﻙ ﻟﻜﺘﺎﺒﺔ ﺭﻤﻭﺯ ﻷﺴﻤﺎﺀ ﹰ 5.ﻋﻨﻭﺍﻥ ﺍﻟﻤﺘﻐﻴﺭ )ﻭﺼﻔﻪ( :Label ﺍﻟﻤﺘﻐﻴﺭ، ﻤﻤﺎ ﻴﺠﻌل ﺍﻟﻤﺴﺘﺨﺩﻡ ﻻ ﻴﺴﺘﻁﻴﻊ ﺍﻟﺘﻤﻴﻴﺯ ﺒﻴﻥ ﻫﺫﻩ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ، ﻭﺒﺎﻟﺘﺎﻟﻲ ﻓﺈﻥ ﻫﺫﺍ ﺍﻻﺨﺘﻴﺎﺭ ﻴﻤﻜﻥ ﺍﻟﻤﺴﺘﺨﺩﻡ ﻤﻥ ﻜﺘﺎﺒﺔ ﻭﺼﻑ ﻟﻠﻤﺘﻐﻴﺭ ﺃﻭ ﺍﺴﻤﻪ ﻜﺎﻤﻼ ﻤﻬﻤﺎ ﻜﺎﻥ ﺤﺠﻡ ﺨﺎﻨﺎﺘﻪ ﻟﻤﻌﺭﻓﺔ ﻫﺫﺍ ﺍﻟﻤﺘﻐﻴﺭ ﺒﺸﻜل ﺃﻭﻀﺢ. ﻭﻤﻥ ﺍﻟﺠﺩﻴﺭ ﺒﺎﻟﺫﻜﺭ ﹰ ﻋﻨﺩ ﺍﺠﺭﺍﺀ ﺍﻱ ﺘﺤﻠﻴل ﺍﺤﺼﺎﺌﻲ ﻋﻠﻰ ﺍﻟﻤﺘﻐﻴﺭ ﺴﻴﻅﻬﺭ ﻋﻨﻭﺍﻥ ﺍﻟﻤﺘﻐﻴﺭ ﻓﻲ ﺍﻟﺠﺩﺍﻭل ﺍﻟﺘﻲ ﺴﺘﻅﻬﺭ ﻓﻲ ﺍﻟﻨﺘﺎﺌﺞ، ﻭﺇﺫﺍ ﻟﻡ ﻴﻭﺠﺩ ﻋﻨﻭﺍﻥ ﻟﻠﻤﺘﻐﻴﺭ ﺴﻴﻅﻬﺭ ﺍﺴﻡ ﺍﻟﻤﺘﻐﻴﺭ ﻨﻔﺴﻪ. :Values 6. ﺍﻟﺘﺼﻨﻴﻑ )ﺍﻟﻜﻭﺩ( ﻋﻨﺩﻤﺎ ﺘﻜﻭﻥ ﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺘﻐﻴﺭ ﻤﺤﺩﻭﺩﺓ ﺍﻟﻌﺩﺩ ﻴﻜﻭﻥ ﻤﻥ ﺍﻷﺴﻬل ﺘﺭﻤﻴﺯ ﻫﺫﻩ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺤﻴﺙ ﻴﻤﻜﻨﻨﺎ ﺒﺭﻨﺎﻤﺞ SPSSﻤﻥ ﺫﻟﻙ. ﻭﻨﺴﺘﺨﺩﻡ ﻋﻤﻠﻴﺔ ﺍﻟﻜﻭﺩ ﻋﺎﺩﺓ ﻋﻨﺩﻤﺎ ﻨﺭﻴﺩ ﺘﻌﺭﻴﻑ ﻤﺘﻐﻴﺭﺍﺕ ﻨﻭﻋﻴﺔ ﺭﻗﻤﻴﺔ ﺃﻭ ﺤﺭﻓﻴﺔ ﺍﻟﺘﻲ ﺘﻌﺭﻀﻨﺎ ﻟﻬﺎ ﺴﺎﺒﻘﹰ، ﻤﺜل ﺎ ﻤﺘﻐﻴﺭﺍﻟﺠﻨﺱ ﺃﻭ ﺍﻟﺤﺎﻟﺔ ﺍﻻﺠﺘﻤﺎﻋﻴﺔ ﺃﻭ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺩﺭﺍﺴﻲ. ﺒﺎﻤﻜﺎﻨﻙ ﻭﻀﻊ ﻭﺼﻑ ﻟﻜل ﻗﻴﻤﺔ ﺘﺩﺨﻠﻬﺎ ﻓﻲ ﻫﺫﺍ ﺍﻟﻤﺘﻐﻴﺭ ﻜﺄﻥ ﺘﻘﻭﻡ ﺒﺘﺭﻤﻴﺯ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻐﻴﺭ ﺭﻗﻤﻴﺔ ﻤﺜل ﺃﻥ ﺘﻀﻊ ﺭﻤﺯ ﻟﻠﺫﻜﺭ 1 ﻭﻟﻸﻨﺜﻰ 2، ﻭﻫﺫﺍ ﻤﺎ ﻴﺴﻤﻰ ﺒﻌﻤﻠﻴﺔ ﺘﺭﻤﻴﺯ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﻫﺫﺍ ﺒﺩﻭﺭﻩ ﻴﺴﻬل ﻋﻤﻠﻴﺔ ﺇﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ، ﻓﺒﺩل ﺃﻥ ﻨﺩﺨل ﻓﻲ ﻜل ﻤﺭﺓ ﺫﻜﺭ ﻨﺩﺨل ﺍﻟﺭﻤﺯ 1 ﻤﻤﺎ ﻴﻘﻠل ﻤﻥ ﻭﻗﺕ ﺍﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﻴﺴﻬﻠﻪ. ﻭﻟﺘﻌﺭﻴﻑ ﺍﻟﻜﻭﺩ ﻷﻱ ﻤﺘﻐﻴﺭ ﻓﻲ ﺸﺎﺸﺔ .Variable View ﺒﺎﻟﻀﻐﻁ ﺒﺎﻟﻤﺎﻭﺱ ﻤﻜﺎﻥ ﺍﻟﺴﻬﻡ ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ ﻨﻜﺘﺏ 1 ﻓﻲ ﺨﺎﻨﺔ Valueﻭﻤﻥ ﺜﻡ ﻋﻨﻭﺍﻥ )ﻗﻴﻤﺔ( ﺍﻟﺭﻤﺯ ﻭﻫﻭ ﺫﻜﺭ ﻓﻲ ﺨﺎﻨﺔ Value Lableﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ Addﻟﻴﺼﺒﺢ ﺍﻟﺸﻜل ﻜﺎﻟﺘﺎﻟﻲ: 51
16.
ﻨﻜﺭﺭ ﺍﻟﻌﻤﻠﻴﺔ ﻟﺭﻤﺯ
ﺍﻷﻨﺜﻰ 2 ﻭﻋﻨﺩ ﺍﻻﻨﺘﻬﺎﺀ ﻤﻥ ﺘﻌﺭﻴﻑ ﺍﻟﻜﻭﺩ ﻨﻀﻐﻁ .Ok 7.ﻋﺭﺽ ﺍﻟﻌﻤﻭﺩ :Columnﻭﻓﻲ ﻫﺫﻩ ﺍﻟﺨﺎﻨﺔ ﺘﺤﺩﺩ ﻋﺭﺽ ﺍﻟﻌﻤﻭﺩ ﺍﻟﺫﻱ ﻴﻭﺠﺩ ﻓﻴﻪ ﺍﻟﻤﺘﻐﻴﺭ ﻓﻲ ﺸﺎﺸﺔ Data .View 8.ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﻔﻘﻭﺩﺓ :Missing Valuesﻋﻨﺩ ﺍﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ ﺒﻌﺽ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺘﻜﻭﻥ ﻏﻴﺭ ﻤﻭﺠﻭﺩﺓ ﻓﻨﺼﻨﻔﻬﺎ ﻋﻠﻰ ﺃﺴﺎﺱ ﺃﻨﻬﺎ ﺒﻴﺎﻨﺎﺕ ﻤﻔﻘﻭﺩﺓ .Missing Values 9.ﻤﻭﻗﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ :Alignﻭﻫﻭ ﺘﺤﺩﻴﺩ ﻤﻭﻗﻊ ﺍﻅﻬﺎﺭ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﺍﻟﺨﻼﻴﺎ ﻓﻲ ﺸﺎﺸﺔ ﺍﻅﻬﺎﺭ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻫل ﺴﺘﻜﻭﻥ ﻋﻠﻰ ﻴﺴﺎﺭ ﺃﻭ ﻭﺴﻁ ﺃﻭ ﻴﻤﻴﻥ ﺍﻟﺨﻠﻴﺔ. 01.ﺘﺩﺭﻴﺠﺎﺕ ﺍﻟﻘﻴﺎﺱ :Measurement Scaleﻭﻫﻭ ﺘﺤﺩﻴﺩ ﻨﻭﻉ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻫل ﺘﻘﻊ ﺘﺤﺕ ﺘﺩﺭﻴﺞ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻻﺴﻤﻴﺔ Nominalﺃﻭ ﺘﺭﺘﻴﺒﻴﺔ Ordinalﺃﻭ )ﻨﺴﺒﻴﺔ ﺃﻭ ﻓﺘﺭﺓ( Scalﻜﻤﺎ ﻤﺭ ﻤﻌﻙ ﻋﺯﻴﺯﻱ ﺍﻟﺩﺍﺭﺱ ﻓﻲ ﻤﻘﺭﺭ ﻤﺒﺎﺩﺉ ﺍﻻﺤﺼﺎﺀ ﻭﺒﺸﻜل ﺘﻔﺼﻴﻠﻲ. ﻗﺒل ﺍﻟﺒﺩﺀ ﻓﻲ ﺘﻌﺭﻴﻑ ﻜﻴﻔﻴﺔ ﺇﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﺭﻗﻤﻴﺔ ﻭﺍﻟﻐﻴﺭ ﺭﻗﻤﻴﺔ ﻭﻏﻴﺭﻫﺎ ﺴﻨﺘﻌﺭﻑ ﻋﻠﻰ 4: ﺇﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ : ﺃﻫﻡ ﺍﻟﻤﻔﺎﺘﻴﺢ ﻭﺍﺴﺘﺨﺩﺍﻤﻬﺎ ﻓﻲ ﺒﺭﻨﺎﻤﺞ SPSSﻭﺍﻟﻤﺒﻴﻨﺔ ﻓﻲ ﺍﻟﺠﺩﻭل ﺍﻟﺘﺎﻟﻲ: ﺍﻟﻭﻅﻴﻔﺔ ﺍﻟﻤﻔﺘﺎﺡ ﺇﺫﻫﺏ ﺇﻟﻰ ﺃﻭل ﺨﻠﻴﺔ ﻓﻲ ﺍﻟﺤﺎﻟﺔ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻷﻭل Home ﺇﺫﻫﺏ ﻵﺨﺭ ﺨﻠﻴﺔ ﻓﻲ ﺍﻟﺤﺎﻟﺔ ﻋﻨﺩ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻻﺨﻴﺭ End ﺇﺫﻫﺏ ﺇﻟﻰ ﺃﻭل ﺨﻠﻴﺔ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ﻋﻨﺩ ﺍﻟﺸﻁﺭ ﺍﻷﻭل +Ctrl ﺇﺫﻫﺏ ﻵﺨﺭ ﺨﻠﻴﺔ ﻓﻲ ﺍﻟﺤﺎﻟﺔ ﻋﻨﺩ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻻﺨﻴﺭ +Ctrl ﺇﺫﻫﺏ ﺇﻟﻰ ﺁﺨﺭ ﺨﻠﻴﺔ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ﻋﻨﺩ ﺍﻟﺤﺎﻟﺔ ﺍﻷﺨﻴﺭﺓ +Ctrl ﺇﺫﻫﺏ ﺇﻟﻰ ﺃﻭل ﺨﻠﻴﺔ ﻓﻲ ﺍﻟﺤﺎﻟﺔ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻷﻭل +Ctrl ﺇﺫﻫﺏ ﺇﻟﻰ ﺃﻭل ﺨﻠﻴﺔ ﻓﻲ ﺍﻟﺴﻁﺭ ﺍﻷﻭل ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻷﻭل Ctrl+Home ﺇﺫﻫﺏ ﺇﻟﻰ ﺁﺨﺭ ﺨﻠﻴﺔ ﻓﻲ ﺍﻟﺴﻁﺭ ﺍﻷﺨﻴﺭ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻷﺨﻴﺭ Ctrl + End 61
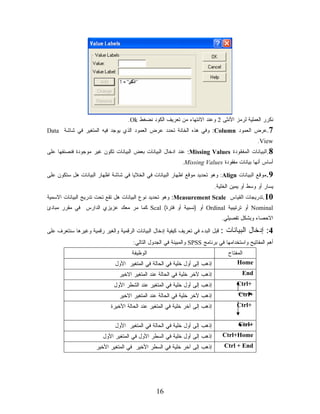
17.
ﺍﻥ ﻋﻤﻠﻴﺔ ﺍﺩﺨﺎل
ﺍﻟﺒﻴﺎﻨﺎﺕ ﺴﻬﻠﺔ ﺠﺩﺍ ﻓﻲ ﺒﺭﻨﺎﻤﺞ ،SPSSﻓﻬﻲ ﺘﻘﺭﻴﻴﺎ ﻜﻁﺭﻴﻘﺔ ﺍﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﺒﺭﻨﺎﻤﺞ ،Excel ﹰ ﹰ ﻭﻟﺩﻴﻙ ﺍﻟﺤﺭﻴﺔ ﻓﻲ ﺍﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ ﺒﺸﻜل ﻋﻤﻭﺩﻱ ﺃﻭ ﺒﺸﻜل ﺃﻓﻘﻲ، ﻓﻔﻲ ﺍﻟﺤﺎﻟﺔ ﺍﻷﻭﻟﻰ ﺘﺩﺨل ﻤﺘﻐﻴﺭ ﻓﺂﺨﺭ ﻭﺃﻤﺎ ﺍﻟﺤﺎﻟﺔ ﺍﻟﺜﺎﻨﻴﺔ ﻓﺈﻨﻙ ﺘﺩﺨل ﺤﺎﻟﺔ ﻓﺄﺨﺭﻯ. ﻭﺘﻜﻭﻥ ﻫﺫﻩ ﺍﻟﻌﻤﻠﻴﺔ ﺒﺎﻟﺨﻁﻭﺍﺕ ﺍﻟﺘﺎﻟﻴﺔ: ﻤﻥ ﻏﻴﺭ ﺍﻟﻀﺭﻭﺭﻱ ﺃﻥ ﺘﻌﺭﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻗﺒل ﻋﻤﻠﻴﺔ ﺍﻻﺩﺨﺎل ﻟﻜﻥ ﻤﻥ ﺍﻟﻤﻔﻀل ﺃﻥ ﺘﻘﻭﻡ ﺒﺫﻟﻙ • ﻷﻥ ﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺘﻘﻠل ﻤﻥ ﺨﻁﺄ ﺍﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ. ﺘﻔﺘﺢ ﺸﺎﺸﺔ .Data View • ﺘﺫﻫﺏ ﺇﻟﻰ ﺍﻟﻤﻜﺎﻥ ﺍﻟﺫﻱ ﺘﺭﻴﺩ ﺍﻥ ﺘﺩﺨل ﻓﻴﻪ ﺍﻟﺒﻴﺎﻨﺎﺕ، ﻭﺘﻀﻐﻁ ﺒﺎﻟﻤﺎﻭﺱ ﻋﻠﻰ ﺍﻟﺨﻠﻴﺔ ﺍﻟﻤﻁﻠﻭﺒﺔ. • ﺘﻜﺘﺏ ﻗﻴﻤﺔ ﺍﻟﺨﻠﻴﺔ ﻓﺘﻅﻬﺭ ﻗﻴﻤﺔ ﺍﻻﺩﺨﺎل ﻓﻲ ﺍﻋﻠﻰ ﺸﺎﺸﺔ ، Data Viewﻭﻤﻥ ﺜﻡ ﺘﻀﻐﻁ Enter • ﻓﺘﻅﻬﺭ ﺍﻟﻘﻴﻤﺔ ﺍﻟﻤﺩﺨﻠﺔ ﻓﻲ ﻤﻜﺎﻥ ﺍﺩﺨﺎﻟﻬﺎ. ﻤﺜﺎل 1: ﻟﻨﻌﺭﻑ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ ﺩﺭﺠﺔ ﺍﻟﻁﺎﻟﺏ ) (Degreeﻭﺠﻨﺱ ﺍﻟﻁﺎﻟﺏ ) (Genderﻤﻥ ﺜﻡ ﻟﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﺘﺎﻟﻴﺔ. ﺍﻻﻨﺎﺙ ﺩﺭﺠﺎﺕ ﺃﻭﻻ: ﹰ 08 58 57 56 55 25 44 33 03 52 54 08 59 05 03 59 88 09 77 27 57 06 04 75 55 25 84 48 78 87 77 37 57 ﺍﻟﺫﻜﻭﺭ ﺩﺭﺠﺎﺕ ﺜﺎﻨﻴﺎ: ﹰ 77 03 52 03 44 04 56 44 77 57 97 48 83 54 58 67 26 44 24 77 66 56 89 59 63 84 16 06 59 58 07 89 08 39 57 71
18.
ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ ﻴﺒﻴﻥ
ﻟﻨﺎ ﺸﻜل ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺩﺨﻠﺔ : 81
19.
ﻻﻅﻬﺎﺭ ﻗﻴﻤﺔ ﺭﻤﻭﺯ
ﺍﻟﻤﺘﻐﻴﺭ Genderﺃﻱ ﺍﻅﻬﺎﺭ ﺫﻜﺭ ﺒﺩل ﺍﻟﺭﻤﺯ 1 ﻓﻲ ﺸﺎﺸﺔ ﻋﺭﺽ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﺃﻨﺜﻰ ﺒﺩل ﺍﻟﺭﻤﺯ 2، ﻤﻥ ﺨﻼل ﺍﻟﻘﺎﺌﻤﺔ Viewﻨﺨﺘﺎﺭ ، Value Lableﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ ﻓﺘﻅﻬﺭ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺒﺎﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 91
20.
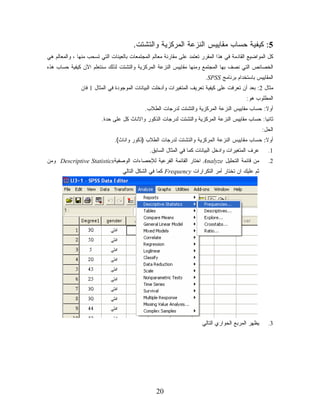
5: ﻜﻴﻔﻴﺔ ﺤﺴﺎﺏ
ﻤﻘﺎﻴﻴﺱ ﺍﻟﻨﺯﻋﺔ ﺍﻟﻤﺭﻜﺯﻴﺔ ﻭﺍﻟﺘﺸﺘﺕ. ﻜل ﺍﻟﻤﻭﺍﻀﻴﻊ ﺍﻟﻘﺎﺩﻤﺔ ﻓﻲ ﻫﺫﺍ ﺍﻟﻤﻘﺭﺭ ﺘﻌﺘﻤﺩ ﻋﻠﻰ ﻤﻘﺎﺭﻨﺔ ﻤﻌﺎﻟﻡ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ ﺒﺎﻟﻌﻴﻨﺎﺕ ﺍﻟﺘﻲ ﺘﺴﺤﺏ ﻤﻨﻬﺎ ، ﻭﺍﻟﻤﻌﺎﻟﻡ ﻫﻲ ﺍﻟﺨﺼﺎﺌﺹ ﺍﻟﺘﻲ ﻨﺼﻑ ﺒﻬﺎ ﺍﻟﻤﺠﺘﻤﻊ ﻭﻤﻨﻬﺎ ﻤﻘﺎﻴﻴﺱ ﺍﻟﻨﺯﻋﺔ ﺍﻟﻤﺭﻜﺯﻴﺔ ﻭﺍﻟﺘﺸﺘﺕ ﻟﺫﻟﻙ ﺴﻨﺘﻌﻠﻡ ﺍﻵﻥ ﻜﻴﻔﻴﺔ ﺤﺴﺎﺏ ﻫﺫﻩ ﺍﻟﻤﻘﺎﻴﻴﺱ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺒﺭﻨﺎﻤﺞ .SPSS ﻤﺜﺎل 2: ﺒﻌﺩ ﺃﻥ ﺘﻌﺭﻓﺕ ﻋﻠﻰ ﻜﻴﻔﻴﺔ ﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻭﺃﺩﺨﻠﺕ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﻭﺠﻭﺩﺓ ﻓﻲ ﺍﻟﻤﺜﺎل 1 ﻓﺎﻥ ﺍﻟﻤﻁﻠﻭﺏ ﻫﻭ: ﺃﻭﻻ: ﺤﺴﺎﺏ ﻤﻘﺎﻴﻴﺱ ﺍﻟﻨﺯﻋﺔ ﺍﻟﻤﺭﻜﺯﻴﺔ ﻭﺍﻟﺘﺸﺘﺕ ﻟﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ. ﹰ ﺜﺎﻨﻴﺎ: ﺤﺴﺎﺏ ﻤﻘﺎﻴﻴﺱ ﺍﻟﻨﺯﻋﺔ ﺍﻟﻤﺭﻜﺯﻴﺔ ﻭﺍﻟﺘﺸﺘﺕ ﻟﺩﺭﺠﺎﺕ ﺍﻟﺫﻜﻭﺭ ﻭﺍﻻﻨﺎﺙ ﻜل ﻋﻠﻰ ﺤﺩﺓ. ﹰ ﺍﻟﺤل: ﺃﻭﻻ: ﺤﺴﺎﺏ ﻤﻘﺎﻴﻴﺱ ﺍﻟﻨﺯﻋﺔ ﺍﻟﻤﺭﻜﺯﻴﺔ ﻭﺍﻟﺘﺸﺘﺕ ﻟﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ )ﺫﻜﻭﺭ ﻭﺍﻨﺎﺙ(. ﹰ ﻋﺭﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻭﺍﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻜﻤﺎ ﻓﻲ ﺍﻟﻤﺜﺎل ﺍﻟﺴﺎﺒﻕ. 1. ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﺍﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ ﻟﻺﺤﺼﺎﺀﺍﺕ ﺍﻟﻭﺼﻔﻴﺔ Descriptive Statisticsﻭﻤﻥ 2. ﺜﻡ ﻋﻠﻴﻙ ﺍﻥ ﺘﺨﺘﺎﺭ ﺃﻤﺭ ﺍﻟﺘﻜﺭﺍﺭﺍﺕ Frequencyﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 3. 02
21.
ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭ
Degreeﻟﺨﺎﻨﺔ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ Variableﻭﺫﻟﻙ ﻤﻥ ﺨﻼل ﺍﻟﻀﻐﻁ ﺒﺎﻟﻤﺎﻭﺱ ﻋﻠﻰ ﺍﻟﻤﺘﻐﻴﺭ ﻭﻤﻥ ﺜﻡ 4. ﺍﻟﻀﻐﻁ ﻋﻠﻰ ﺍﻟﺴﻬﻡ )ﺃﻭ ﻤﻥ ﺨﻼل ﺍﻟﻀﻐﻁ ﻤﺭﺘﻴﻥ ﺒﺎﻟﻤﺎﻭﺱ ﻋﻠﻰ ﺍﻟﻤﺘﻐﻴﺭ .(Degree ﺒﺎﻟﻀﻐﻁ ﻋﻠﻰ ﺯﺭ Statisticsﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ ﻭﻨﺨﺘﺎﺭ ﻤﻨﻪ ﺤﺴﺎﺏ ﺍﻟﻤﻘﺎﻴﻴﺱ ﺍﻻﺤﺼﺎﺌﻴﺔ ﺍﻟﺘﻲ 5. ﺘﻘﻊ ﺘﺤﺕ ﻤﻘﺎﻴﻴﺱ ﺍﻟﻨﺯﻋﺔ ﺍﻟﻤﺭﻜﺯﻴﺔ Central Tendencyﻭﻤﻘﺎﻴﻴﺱ ﺍﻟﺘﺸﺘﺕ Dispersionﻭﺍﻟﺭﺒﻴﻌﺎﺕ ......Quartile ﺒﺎﻟﻀﻐﻁ ﻋﻠﻰ Continueﻨﻌﻭﺩ ﻟﻠﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺨﺎﺹ ﺒﺎﻷﻤﺭ Frequencyﺍﻟﺴﺎﺒﻕ ﻭﻨﻀﻐﻁ Ok 6. ﻟﻠﺤﺼﻭل ﻋﻠﻰ ﺍﻟﻨﺘﺎﺌﺞ ﺍﻟﺘﺎﻟﻴﺔ 12
22.
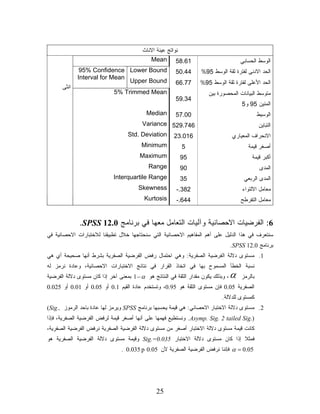
ﻨﺘﻴﺠﺔ ﺃﻤﺭ ﺍﻟﺘﻜﺭﺍﺭﺍﺕ
Frequency Statistics Degree N Valid 86 ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ Missing 0 ﻋﺩﺩ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﻔﻘﻭﺩﺓ Mean 47.16 ﺍﻟﻤﺘﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ Std. Error of Mean 317.2 ﺍﻟﺨﻁﺄ ﺍﻟﻤﻌﻴﺎﺭﻱ ﻓﻲ ﺤﺴﺎﺏ ﺍﻟﻭﺴﻁ Median 00.56 ﺍﻟﻭﺴﻴﻁ Mode )30(a ﺃﺼﻐﺭ ﻤﻨﻭﺍل ﺍﻟﻤﻨﻭﺍل Std. Deviation 273.22 ﺍﻻﻨﺤﺭﺍﻑ ﺍﻟﻤﻌﻴﺎﺭﻱ Variance 625.005 ﺍﻟﺘﺒﺎﻴﻥ Skew ness 203.- ﻤﻌﺎﻤل ﺍﻻﻟﺘﻭﺍﺀ Std. Error of Skew ness 192. ﺍﻟﺨﻁﺄ ﺍﻟﻤﻌﻴﺎﺭﻱ ﻓﻲ ﺤﺴﺎﺏ ﻤﻌﺎﻤل ﺍﻻﻟﺘﻭﺍﺀ Kurtosis 787.- ﻤﻌﺎﻤل ﺍﻟﺘﻔﺭﻁﺢ Std. Error of Kurtosis ﺍﻟﺨﻁﺄ ﺍﻟﻤﻌﻴﺎﺭﻱ ﻓﻲ ﺤﺴﺎﺏ ﻓﻲ ﺤﺴﺎﺏ ﻤﻌﺎﻤل 475. ﺍﻟﺘﻔﺭﻁﺢ Range 39 ﺍﻟﻤﺩﻯ Minimum 5 ﺃﺼﻐﺭ ﻗﻴﻤﺔ Maximum 89 ﺃﻜﺒﺭ ﻗﻴﻤﺔ Sum 8914 ﻤﺠﻤﻭﻉ ﺍﻟﻘﻴﻡ Percentiles 52 00.44 ﺍﻟﻤﺌﻴﻥ 52 05 00.56 ﺍﻟﻤﺌﻴﻥ 05 )ﺍﻟﻭﺴﻴﻁ( 57 57.77 ﺍﻟﻤﺌﻴﻥ 57 a Multiple modes exist. The smallest value is shown ﺜﺎﻨﻴﺎ: ﺤﺴﺎﺏ ﻤﻘﺎﻴﻴﺱ ﺍﻟﻨﺯﻋﺔ ﺍﻟﻤﺭﻜﺯﻴﺔ ﻭﺍﻟﺘﺸﺘﺕ ﻟﺩﺭﺠﺎﺕ ﺍﻟﺫﻜﻭﺭ ﻭﺍﻻﻨﺎﺙ ﻜل ﻋﻠﻰ ﺤﺩﺓ. ﹰ 1. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻜﻤﺎ ﺫﻜﺭ ﺍﻨﻔﺎ. 2. ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﺍﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ ﻟﻺﺤﺼﺎﺀﺍﺕ ﺍﻟﻭﺼﻔﻴﺔ Descriptive Statisticsﻭﻤﻥ ﺜﻡ ﻋﻠﻴﻙ ﺍﻥ ﺘﺨﺘﺎﺭ ﺃﻤﺭ ﺍﺴﺘﻜﺸﻑ Exploreﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 22
23.
3. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 4. ﻨﻨﻘل ﻤﺘﻐﻴﺭ ﺍﻟﺩﺭﺠﺎﺕ Degreeﺇﻟﻰ ﺨﺎﻨﺔ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺘﺎﺒﻌﺔ ﻭﻨﻨﻘل ﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ Genderﺇﻟﻰ ﺇﻟﻰ ﺨﺎﻨﺔ .Factor Listﻭﻤﻥ ﺜﻡ ﻨﻀﻊ ﻋﻼﻤﺔ ﻋﻠﻰ ﺨﺎﻨﺔ Statisticsﻹﻅﻬﺎﺭ ﺍﻻﺤﺼﺎﺀﺍﺕ ﻓﻘﻁ ﺩﻭﻥ ﺍﻅﻬﺎﺭ ﺭﺴﻭﻤﺎﺕ. 32
24.
5. ﻨﻀﻐﻁ
Okﻟﻴﻅﻬﺭ ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲ. Descriptives Gender Statistic ﻨﻭﺍﺘﺞ ﻋﻴﻨﺔ ﺍﻟﺫﻜﻭﺭ Mean 96.46 ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ 95% Confidence Lower Bound 42.75 ﺍﻟﺤﺩ ﺍﻻﺩﻨﻰ ﻟﻔﺘﺭﺓ ﺜﻘﺔ ﺍﻟﻭﺴﻁ 59% Interval for Mean Upper Bound 31.27 ﺍﻟﺤﺩ ﺍﻷﻋﻠﻰ ﻟﻔﺘﺭﺓ ﺜﻘﺔ ﺍﻟﻭﺴﻁ 59% ﺫﻜﺭ 5% Trimmed Mean ﻤﺘﻭﺴﻁ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺤﺼﻭﺭﺓ ﺒﻴﻥ 29.46 ﺍﻟﻤﺌﻴﻥ 59 ﻭ5 Median 00.66 ﺍﻟﻭﺴﻴﻁ 182.964 Variance ﺍﻟﺘﺒﺎﻴﻥ 366.12 Std. Deviation ﺍﻻﻨﺤﺭﺍﻑ ﺍﻟﻤﻌﻴﺎﺭﻱ Minimum 52 ﺃﺼﻐﺭ ﻗﻴﻤﺔ Maximum 89 ﺃﻜﺒﺭ ﻗﻴﻤﺔ Range 37 ﺍﻟﻤﺩﻯ Interquartile Range 63 ﺍﻟﻤﺩﻯ ﺍﻟﺭﺒﻌﻲ Skewness 091.- ﻤﻌﺎﻤل ﺍﻻﻟﺘﻭﺍﺀ Kurtosis 041.1- ﻤﻌﺎﻤل ﺍﻟﺘﻔﺭﻁﺢ 42
25.
ﻨﻭﺍﺘﺞ ﻋﻴﻨﺔ ﺍﻻﻨﺎﺙ
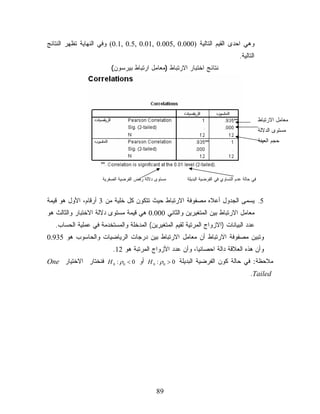
16.85 Mean ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ 95% Confidence Lower Bound 44.05 ﺍﻟﺤﺩ ﺍﻻﺩﻨﻰ ﻟﻔﺘﺭﺓ ﺜﻘﺔ ﺍﻟﻭﺴﻁ 59% Interval for Mean Upper Bound 77.66 ﺍﻟﺤﺩ ﺍﻷﻋﻠﻰ ﻟﻔﺘﺭﺓ ﺜﻘﺔ ﺍﻟﻭﺴﻁ 59% ﺍﻨﺜﻰ 5% Trimmed Mean ﻤﺘﻭﺴﻁ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺤﺼﻭﺭﺓ ﺒﻴﻥ 43.95 ﺍﻟﻤﺌﻴﻥ 59 ﻭ5 Median 00.75 ﺍﻟﻭﺴﻴﻁ 647.925 Variance ﺍﻟﺘﺒﺎﻴﻥ 610.32 Std. Deviation ﺍﻻﻨﺤﺭﺍﻑ ﺍﻟﻤﻌﻴﺎﺭﻱ Minimum 5 ﺃﺼﻐﺭ ﻗﻴﻤﺔ Maximum 59 ﺃﻜﺒﺭ ﻗﻴﻤﺔ Range 09 ﺍﻟﻤﺩﻯ Interquartile Range 53 ﺍﻟﻤﺩﻯ ﺍﻟﺭﺒﻌﻲ Skewness 283.- ﻤﻌﺎﻤل ﺍﻻﻟﺘﻭﺍﺀ Kurtosis 446.- ﻤﻌﺎﻤل ﺍﻟﺘﻔﺭﻁﺢ 6: ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻻﺤﺼﺎﺌﻴﺔ ﻭﺁﻟﻴﺎﺕ ﺍﻟﺘﻌﺎﻤل ﻤﻌﻬﺎ ﻓﻲ ﺒﺭﻨﺎﻤﺞ 0.21 .SPSS ﺴﻨﺘﻌﺭﻑ ﻓﻲ ﻫﺫﺍ ﺍﻟﺩﻟﻴل ﻋﻠﻰ ﺃﻫﻡ ﺍﻟﻤﻔﺎﻫﻴﻡ ﺍﻻﺤﺼﺎﺌﻴﺔ ﺍﻟﺘﻲ ﺴﻨﺤﺘﺎﺠﻬﺎ ﺨﻼل ﺘﻁﺒﻴﻘﻨﺎ ﻟﻼﺨﺘﺒﺎﺭﺍﺕ ﺍﻻﺤﺼﺎﺌﻴﺔ ﻓﻲ ﺒﺭﻨﺎﻤﺞ 0.21 .SPSS 1. ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻭﻫﻲ ﺍﺤﺘﻤﺎل ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺒﺸﺭﻁ ﺃﻨﻬﺎ ﺼﺤﻴﺤﺔ ﺃﻱ ﻫﻲ ﻨﺴﺒﺔ ﺍﻟﺨﻁﺄ ﺍﻟﻤﺴﻤﻭﺡ ﺒﻬﺎ ﻓﻲ ﺍﺘﺨﺎﺫ ﺍﻟﻘﺭﺍﺭ ﻓﻲ ﻨﺘﺎﺌﺞ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻻﺤﺼﺎﺌﻴﺔ، ﻭﻋﺎﺩﺓ ﻨﺭﻤﺯ ﻟﻪ ، ﻭﺒﺫﻟﻙ ﻴﻜﻭﻥ ﻤﻘﺩﺍﺭ ﺍﻟﺜﻘﺔ ﻓﻲ ﺍﻟﻨﺘﺎﺌﺞ ﻫﻭ 1 − αﺒﻤﻌﻨﻰ ﺁﺨﺭ ﺇﺫﺍ ﻜﺎﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ α ﺒﺎﻟﺭﻤﺯ ﺍﻟﺼﻔﺭﻴﺔ 50.0 ﻓﺈﻥ ﻤﺴﺘﻭﻯ ﺍﻟﺜﻘﺔ ﻫﻭ 59.0، ﻭﺘﺴﺘﺨﺩﻡ ﻋﺎﺩﺓ ﺍﻟﻘﻴﻡ 1.0 ﺃﻭ 50.0 ﺃﻭ 10.0 ﺃﻭ 520.0 ﻜﻤﺴﺘﻭﻯ ﻟﻠﺩﻻﻟﺔ. 2. ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﺍﻻﺤﺼﺎﺌﻲ: ﻫﻲ ﻗﻴﻤﺔ ﻴﺤﺴﺒﻬﺎ ﺒﺭﻨﺎﻤﺞ SPSSﻭﻴﺭﻤﺯ ﻟﻬﺎ ﻋﺎﺩﺓ ﺒﺎﺤﺩ ﺍﻟﺭﻤﻭﺯ ,.(Sig ). .Asymp. Sig. 2 tailed Sigﻭﻨﺴﺘﻁﻴﻊ ﻓﻬﻤﻬﺎ ﻋﻠﻰ ﺃﻨﻬﺎ ﺃﺼﻐﺭ ﻗﻴﻤﺔ ﻟﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ، ﻓﺈﺫﺍ ﻜﺎﻨﺕ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﺃﺼﻐﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ، ﻓﻤﺜﻼ ﺇﺫﺍ ﻜﺎﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ 530.0=. Sigﻭﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻫﻭ ﹰ 50.0 = αﻓﺈﻨﻨﺎ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻷﻥ 50.0 . 0.035 p 52
26.
ﻭﻴﻤﻜﻥ ﻓﻬﻡ ﻗﻴﻤﺔ
ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻋﻠﻰ ﺃﻨﻬﺎ ﺃﻜﺒﺭ ﻗﻴﻤﺔ ﻟﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ ﻓﻼﺤﻅ ﺃﻥ 530.0 0.05 fﺒﺎﻟﺘﺎﻟﻲ ﻻ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ ﺃﻱ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. ﻭﻤﻥ ﺍﻟﺠﺩﻴﺭ ﺒﺎﻟﺫﻜﺭ ﺍﻥ ﺒﺭﻨﺎﻤﺞ SPSSﻴﻌﺘﻤﺩ ﻋﺎﺩﺓ ﻓﻲ ﻋﻤﻠﻴﺎﺘﻪ ﺍﻟﺤﺴﺎﺒﻴﺔ ﻟﺤﺴﺎﺏ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺒﺄﻥ ﹰ ﺘﻜﻭﻥ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻫﻲ ﺤﺎﻟﺔ ﺍﻟﻤﺴﺎﻭﺍﺓ ﻭﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ ﻫﻲ ﺤﺎﻟﺔ ﻋﺩﻡ ﺍﻟﻤﺴﺎﻭﺍﺓ. ﻭﻟﺫﻟﻙ ﻋﻨﺩﻤﺎ ﻨﻘﻭل ﺃﻥ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ﻤﺜﻼ ﻫﻭ 50.0 ﻓﺈﻨﻨﺎ ﻨﺘﻌﺎﻤل ﻤﻌﻬﺎ ﺒﺎﻟﺠﺎﻨﺏ ﺍﻟﻨﻅﺭﻱ ﻋﻠﻰ ﺃﻨﻬﺎ ﻤﻘﺴﻤﺔ ﻟﺠﺯﺌﻴﻥ 520.0 ﻋﻠﻰ ﻤﻨﻁﻘﺔ ﺍﻟﺭﻓﺽ ﻓﻲ ﹰ ﺍﻟﻴﻤﻴﻥ ﻭ 520.0 ﻋﻠﻰ ﻤﻨﻁﻘﺔ ﺍﻟﻘﺒﻭل ﻭﺒﺭﻨﺎﻤﺞ SPSSﻴﺘﻌﺎﻤل ﻤﻌﻬﺎ ﺒﻨﻔﺱ ﺍﻷﺴﻠﻭﺏ. ﺃﻤﺎ ﺇﺫﺍ ﻜﺎﻨﺕ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ ﻓﻲ ﺍﻟﺠﺎﻨﺏ ﺍﻟﻨﻅﺭﻱ ﻫﻲ ﺤﺎﻟﺔ )ﺃﻜﺒﺭ ﺃﻭ ﺃﺼﻐﺭ( ﻓﺒﺭﻨﺎﻤﺞ SPSSﻻ ﻴﺘﻌﺎﻤل ﻤﻊ ﻫﻜﺫﺍ ﺤﺎﻻﺕ ﻓﻲ ﺒﻌﺽ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﺨﺎﺼﺔ ﺍﻟﺘﻲ ﺴﻨﺒﻴﻨﻬﺎ ﻓﻲ ﻭﻗﺘﻬﺎ، ﻭﺒﺎﻟﺘﺎﻟﻲ ﻟﻨﺴﺘﻁﻴﻊ ﺤل ﺍﻟﻤﺴﺎﺌل ﺍﻟﻤﻭﺠﻭﺩﺓ ﺒﺎﻟﺠﺎﻨﺏ ﺍﻟﻨﻅﺭﻱ ﻤﻥ ﺍﻟﻤﻘﺭﺭ ﻓﻲ ﺤﺎﻟﺔ ﻜﻭﻥ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ ﻫﻲ ﺤﺎﻟﺔ )ﺃﻜﺒﺭ ﺃﻭ ﺃﺼﻐﺭ( ﻤﻥ ﺨﻼل ﺒﺭﻨﺎﻤﺞ SPSSﻴﺠﺏ ﺍﻥ ﻨﻀﺎﻋﻑ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻋﻨﺩ ﺍﻟﺘﻌﺎﻤل ﻤﻊ ﺒﺭﻨﺎﻤﺞ SPSSﺃﻭ ﻨﻘﺴﻡ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻋﻠﻰ 2 ﻭﻤﻥ ﺜﻡ ﻨﻘﺎﺭﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻤﻊ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. ﻓﻤﺜﻼ ﺇﺫﺍ ﻜﺎﻨﺕ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ ﻓﻲ ﺍﻟﺠﺎﻨﺏ ﺍﻟﻨﻅﺭﻱ ﻫﻭ ﺤﺎﻟﺔ )ﺃﻜﺒﺭ( ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = αﻓﻨﺭﻓﺽ ﹰ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺒﺭﻨﺎﻤﺞ SPSSﺇﺫﺍ ﻜﺎﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ . Sigﺃﻗل ﻤﻥ 01.0، ﺃﻭ ﺇﺫﺍ ﻜﺎﻥ ﻨﺼﻑ . Sigﺃﻗل ﻤﻥ 50.0. 62
27.
ﺍﻟﻭﺤﺩﺓ ﺍﻷﻭﻟﻰ ﺍﻻﺴﺘﺩﻻل
ﺍﻻﺤﺼﺎﺌﻲ ﺤـﻭل ﻤﺠـﺘﻤﻊ ﻭﺍﺤـﺩ 72
28.
ﺍﻟﻭﺤﺩﺓ ﺍﻷﻭﻟﻰ:ﺍﻻﺴﺘﺩﻻل ﺍﻻﺤﺼﺎﺌﻲ
ﺤـﻭل ﻤﺠـﺘﻤﻊ ﻭﺍﺤـﺩ ﻓﻲ ﻤﻌﻅﻡ ﺃﻨﻭﺍﻉ ﺍﻟﺩﺭﺍﺴﺎﺕ ﻻ ﻨﺴﺘﻁﻴﻊ ﺩﺭﺍﺴﺔ ﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ ﻜﺎﻤﻠﺔ، ﻭﺫﻟﻙ ﻟﻜﺜﺭﺓ ﻜﺘﻁﻠﺒﺎﺕ ﻭﻜﻠﻔﺔ ﻫﻜﺫﺍ ﺩﺭﺍﺴﺎﺕ، ﻭﺒﺎﻟﺘﺎﻟﻲ ﺘﻡ ﺍﺘﺒﺎﻉ ﺍﺴﻠﻭﺏ ﺒﺩﻴل ﻭﻫﻭ ﺍﺴﻠﻭﺏ ﺴﺤﺏ ﺍﻟﻌﻴﻨﺎﺕ، ﻭﻟﻜﻥ ﻫﺫﺍ ﺍﻻﺴﻠﻭﺏ ﻟﻪ ﻋﺩﺓ ﻤﺨﺎﻁﺭ ﻓﻤﻥ ﺍﻟﻤﻤﻜﻥ ﺍﻥ ﺘﻜﻭﻥ ﺍﻟﻌﻴﻨﺔ ﻏﻴﺭ ﻤﻤﺜﻠﺔ ﺒﺸﻜل ﺠﻴﺩ ﻟﻠﻤﺠﺘﻤﻊ، ﻭﺫﻟﻙ ﻤﻥ ﺤﻴﺙ ﺼﻔﺎﺕ ﺍﻟﻤﺠﺘﻤﻊ، ﺃﻭ ﺒﻤﻌﻨﻰ ﺁﺨﺭ ﻻ ﻴﻭﺠﺩ ﺘﻭﺍﻓﻕ ﺒﻴﻥ ﺍﻟﻤﺠﺘﻤﻊ ﻭﺍﻟﻌﻴﻨﺔ ﻭﺫﻟﻙ ﻷﻨﻨﺎ ﻨﺨﺘﺎﺭ ﻋﻴﻨﺎﺕ ﻋﺸﻭﺍﺌﻴﺔ ﻭﺒﺎﻟﺘﺎﻟﻲ ﻤﻥ ﺍﻟﻁﺒﻴﻌﻲ ﺃﻥ ﻴﻜﻭﻥ ﻫﻨﺎﻙ ﺍﺨﺘﻼﻑ ﺒﺴﻴﻁ ﺒﻴﻥ ﺍﻟﻌﻴﻨﺔ ﻭﺍﻟﻤﺠﺘﻤﻊ ﻓﻲ ﺍﻟﺼﻔﺎﺕ ﺃﻭ ﺍﻟﻤﻌﺎﻟﻡ ﺍﻻﺴﺎﺴﻴﺔ ﻤﺜل ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ ﺃﻭ ﺍﻟﺘﺒﺎﻴﻥ ....، ﻟﺫﺍ ﻋﻨﺩ ﺍﺴﺘﺨﺩﺍﻡ ﺍﺴﻠﻭﺏ ﺍﻟﻌﻴﻨﺎﺕ ﻨﻠﺠﺄ ﻟﺘﻘﺩﻴﺭ ﺼﻔﺎﺕ ﺍﻟﻤﺠﺘﻤﻊ ﺒﻁﺭﻴﻘﺘﻴﻥ ﻫﻤﺎ ﻁﺭﻴﻘﺔ ﺍﻟﻨﻘﻁﺔ ﺃﻭ ﻭﻁﺭﻴﻘﺔ ﺍﻟﻔﺘﺭﺓ ﻤﻤﺎ ﻴﺅﺩﻱ ﺇﻟﻰ ﻭﺠﻭﺩ ﻤﺴﺘﻭﻯ ﻟﻠﺜﻘﺔ ﻓﻲ ﻨﺘﺎﺌﺞ ﺍﻟﻌﻴﻨﺎﺕ. ﻭﻤﻥ ﻫﻨﺎ ﺒﺭﺯ ﺍﻻﺤﺼﺎﺀ ﺍﻻﺴﺘﻨﺘﺎﺠﻲ، ﻭﺍﻟﺫﻱ ﻤﻥ ﺨﻼﻟﻪ ﻨﺴﺘﻁﻴﻊ ﺍﺴﺘﻨﺘﺎﺝ ﺍﻟﻨﺘﺎﺌﺞ ﻋﻠﻰ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ ﻭﻟﻜﻥ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﻌﻴﻨﺎﺕ، ﻭﺫﻟﻙ ﺒﺎﻟﻁﺒﻊ ﺇﺫﺍ ﺘﻭﺍﻓﻕ ﺍﻟﻌﻴﻨﺎﺕ ﻤﻊ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ، ﻭﻭﺫﻟﻙ ﻋﻥ ﻁﺭﻴﻕ ﺍﺴﺘﺨﺩﺍﻡ ﺍﺨﺘﺒﺎﺭﺍﺕ ﺍﺤﺼﺎﺌﻴﺔ ﻤﻬﻤﺘﻬﺎ ﺍﻻﺴﺎﺴﻴﺔ ﺍﻟﺘﺄﻜﺩ ﻤﻥ ﺃﻥ ﻫﺫﻩ ﺍﻟﻔﺭﻭﻕ ﻨﺘﺠﺕ ﻋﻥ ﻋﺸﻭﺍﺌﻴﺔ ﺍﻟﻌﻴﻨﺎﺕ، ﺍﻱ ﺃﻥ ﺍﻟﻔﺭﻕ ﺒﻴﻥ ﺍﻟﻌﻴﻨﺔ ﻭﺍﻟﻤﺠﺘﻤﻊ ﻨﺎﺘﺞ ﻋﻥ ﻋﺸﻭﺍﺌﻴﺔ ﺍﻟﻌﻴﻨﺔ )ﺭﺍﺠﻌﺎ ﺇﻟﻰ ﺼﺩﻓﺔ ﺍﺨﺘﻴﺎﺭ ﻫﺫﻩ ﹰ ﺍﻟﻌﻴﻨﺔ ﺒﺎﻟﺫﺍﺕ( ﺃﻡ ﺃﻨﻪ ﺩﺍل ﺍﺤﺼﺎﺌﻴﺎ ﺒﻤﻌﻨﻰ ﻟﻭ ﺴﺤﺒﻨﺎ ﺃﻱ ﻋﻴﻨﺔ ﻋﺸﻭﺍﺌﻴﺔ ﺃﺨﺭﻯ ﺴﻨﺤﺼل ﻋﻠﻰ ﻫﺫﻩ ﹰ ﺍﻟﻔﺭﻭﻕ. ﻓﻲ ﻫﺫﻩ ﺍﻟﻭﺤﺩﺓ ﺴﻨﻌﺘﻤﺩ ﻋﻠﻰ ﺍﻟﻤﺜﺎل ﺍﻟﺘﺎﻟﻲ ﻓﻲ ﺠﻤﻴﻊ ﺍﻻﺴﺎﻟﻴﺏ ﺍﻻﺤﺼﺎﺌﻴﺔ ﺍﻟﺘﻲ ﺴﻨﻘﻭﻡ ﺒﻬﺎ. ﻤﺜﺎل 1: ﻓﻲ ﺩﺭﺍﺴﺔ ﻟﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻓﻲ ﺠﺎﻤﻌﺔ ﺍﻟﻘﺩﺱ ﺍﻟﻤﻔﺘﻭﺤﺔ ﺴﺤﺒﺕ ﻋﻴﻨﺔ ﻋﺸﻭﺍﺌﻴﺔ ﻤﻥ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﺍﻟﺫﻴﻥ ﺘﻘﺩﻤﻭﺍ ﻻﻤﺘﺤﺎﻥ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻭﻜﺎﻨﺕ ﺩﺭﺠﺎﺘﻬﻡ ﻜﻤﺎ ﻴﻠﻲ: 03 05 59 08 54 52 03 33 44 25 55 56 57 58 08 87 78 48 84 25 55 75 04 06 57 27 77 09 88 59 82
29.
1. ﺘﻘﺩﻴﺭ ﻭﺴﻁ
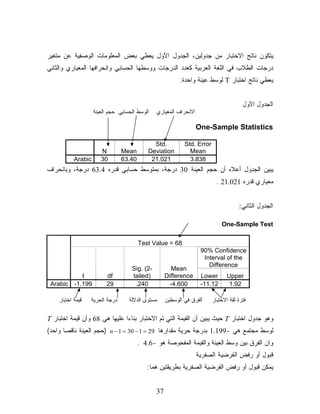
ﻤﺠﺘﻤﻊ ﺒﻨﻘﻁﺔ ﻭﺒﻔﺘﺭﺓ ﺜﻘﺔ. ﻤﺜﺎل 2 : ﺇﺫﺍ ﺃﺭﺩﻨﺎ ﺘﻘﺩﻴﺭ ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ ﻟﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻓﺴﺤﺒﺕ ﻋﻴﻨﺔ ﻤﻥ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﺍﻟﻤﺒﻴﻨﺔ ﻓﻲ ﺍﻟﻤﺜﺎل ﺭﻗﻡ )1( ﻓﻘﺩﺭ ﻤﺘﻭﺴﻁ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺒﻁﺭﻴﻘﺔ ﺍﻟﻨﻘﻁﺔ ﻭﺒﻔﺘﺭﺓ ﺜﻘﺔ ﻤﻘﺩﺍﺭﻫﺎ 09%. ﺍﻟﺤل: 1. ﻨﻌﺭﻑ ﺍﻟﻤﺘﻐﻴﺭ ) (Arabicﻭﻨﺩﺨل ﺒﻴﺎﻨﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻴﻪ ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 2. ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ )ﺍﻻﺤﺼﺎﺀﺍﺕ ﺍﻟﻭﺼﻔﻴﺔ( Descriptive Statisticsﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﻷﻤﺭ ﺍﺴﺘﻜﺸﻑ Exploreﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 92
30.
3. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ ﺍﻟﺨﺎﺹ ﺒﺎﻷﻤﺭ . Explore 03
31.
4. ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭ
) (Arabicﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺴﻬﻡ ﺇﻟﻰ ﺨﺎﻨﺔ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺘﺎﺒﻌﺔ Dependent List ﻭﻤﻥ ﺜﻡ ﻨﻀﻊ ﻋﻼﻤﺔ ﻋﻠﻰ ﺨﺎﻨﺔ . Statistics 2 1 5. ﻨﻀﻐﻁ ﻋﻠﻰ ﺯﺭ Statisticsﻟﺘﺤﺩﻴﺩ ﺍﻻﺤﺼﺎﺌﻴﺎﺕ ﻭﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﺍﻟﻤﻁﻠﻭﺒﺔ ﻓﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 3 6. ﻨﻜﺘﺏ ﻤﻘﺩﺍﺭ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ 09 ﻓﻲ ﺍﻟﺨﺎﻨﺔ ﺍﻟﺨﺎﺼﺔ ﺒﻔﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻟﻠﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ Confidence Interval for Meanﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ Continueﻟﻼﺴﺘﻤﺭﺍﺭ ﻭﺍﻟﻌﻭﺩﺓ ﻟﻠﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺴﺎﺒﻕ ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ Okﻟﻴﻅﻬﺭ ﺍﻟﻨﺎﺘﺞ. ﻨﺎﺘﺞ ﺍﻻﻤﺭ ﺍﺴﺘﻜﺸﻑ :Explore 13
32.
ﺘﻘﺩﻴﺭ ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ
ﺒﻨﻘﻁﺔ Descriptives Statistic Std. Error Arabic 04.36 Mean 838.3 %09 Lower ﺍﻟﺤﺩ ﺍﻻﺩﻨﻰ ﻟﻔﺘﺭﺓ ﺍﻟﺜﻘﺔ Confidence 88.65 Bound Interval for Upper Mean 29.96 Bound ﺍﻟﺤﺩ ﺍﻷﻋﻠﻰ ﻟﻔﺘﺭﺓ ﺍﻟﺜﻘﺔ 5% Trimmed Mean 96.36 ﺍﻟﻭﺴﻴﻁ Median 05.26 ﺍﻟﺘﺒﺎﻴﻥ 309.144 Variance ﺍﻻﻨﺤﺭﺍﻑ Std. Deviation 120.12 ﺍﻟﻤﻌﻴﺎﺭﻱ ﺍﻟﻘﻴﻤﺔ ﺍﻟﺼﻐﺭﻯ Minimum 52 ﺍﻟﻘﻴﻤﺔ ﺍﻟﻌﻅﻤﻰ Maximum 59 ﺍﻟﻤﺩﻯ Range 07 ﺍﻟﻤﺩﻯ ﺍﻟﺭﺒﻌﻲ Interquartile Range 43 ﻤﻌﺎﻤل ﺍﻻﻟﺘﻭﺍﺀ Skewness 491.- 724. ﻤﻌﺎﻤل ﺍﻟﺘﻔﺭﻁﺢ Kurtosis 451.1- 338. ﻴﺘﻜﻭﻥ ﻨﺎﺘﺞ ﺍﻻﻤﺭ Exploreﻤﻥ ﺠﺩﻭﻟﻴﻥ ﺍﻷﻭل ﻴﺼﻑ ﻋﺩﺩ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺩﺨﻠﺔ ﻭﺍﻟﻐﻴﺭ ﻤﺩﺨل ﻤﻨﻬﺎ ﺃﻭ ﻤﺎ ﻴﺴﻤﻰ )ﺒﺎﻟﻘﻴﻡ ﺍﻟﻤﻔﻘﻭﺩﺓ (Missing Valueﺃﻤﺎ ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ ﻓﻬﻭ ﺍﻟﺠﺩﻭل ﺍﻟﻤﻬﻡ ﺍﻟﺫﻱ ﺘﺤﺴﺏ ﻓﻴﻪ ﻤﻘﺎﻴﻴﺱ ﺍﻟﻨﺯﻋﺔ ﺍﻟﻤﺭﻜﺯﻴﺔ ﻭﺍﻟﺘﺸﺘﺕ ﺍﻟﻤﺒﻴﻨﺔ ﻋﻠﻰ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ. ﻭﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺃﻥ ﻤﻘﺩﺍﺭ ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ ﻫﻭ 04.36 ﻭﺃﻥ ﺍﻟﺤﺩ ﺃﻷﺩﻨﻰ ﻟﻔﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻫﻭ 88.65 ﻭﺍﻟﺤﺩ ﺍﻻﻋﻠﻰ ﻟﻬﺎ ﻫﻭ 29.96 ﻭﺒﺫﻟﻙ ﺘﻜﻭﻥ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﺍﻟﻤﻁﻠﻭﺒﺔ ﺒﻨﺴﺒﺔ 09% ﻭﻫﻲ )29.96 ,88.65( . 23
33.
33
34.
2. ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻭﻕ
ﺍﻟﻤﺘﻌﻠﻘﺔ ﺒﻭﺴﻁ ﻤﺠﺘﻤﻊ ﻭﺍﺤﺩ ﻤﺜﺎل 3: ﺇﺫﺍ ﺇﺩﻋﻰ ﺍﺴﺘﺎﺫ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺃﻥ ﻤﺘﻭﺴﻁ ﺩﺭﺠﺎﺕ ﻁﻼﺒﻪ ﻫﻭ 86 ﻓﺴﺤﺒﺕ ﻋﻴﻨﺔ ﻤﻥ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺍﻟﻤﺒﻴﻨﻴﺔ ﻓﻲ ﺍﻟﻤﺜﺎل ﺭﻗﻡ )1( ﺍﻟﺴﺎﺒﻕ ﻓﻬل ﺍﺩﻋﺎﺀ ﺍﻻﺴﺘﺎﺫ ﺼﺤﻴﺢ ﺃﻡ ﺨﺎﻁﺊ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 01.0 = α؟ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ 08 58 57 56 54 52 03 33 44 25 55 08 59 05 03 59 88 09 77 25 55 75 04 06 57 27 84 48 78 87 ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺎﺕ : ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻻ ﻴﻭﺠﺩ ﻓﺭﻕ ﺩﺍل ﺒﻴﻥ ﻤﺘﻭﺴﻁ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻋﻥ 86 ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ: ﻴﻭﺠﺩ ﻓﺭﻕ ﺩﺍل ﺒﻴﻥ ﻤﺘﻭﺴﻁ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻋﻥ 86 ﻭﻟﻘﺒﻭل ﺃﻭ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺎﺕ ﺘﻭﺠﺩ ﻁﺭﻴﻘﺘﻴﻥ ﺍﻟﻁﺭﻴﻘﺔ ﺍﻻﻭﻟﻰ: ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻻﻤﺭ Exploreﺍﻟﺴﺎﺒﻕ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻷﻤﺭ Exploreﻓﻲ ﺍﻟﻤﺜﺎل ﺍﻟﺴﺎﺒﻕ ﺤﻴﺙ ﻜﺎﻨﺕ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻫﻲ )29.96 ,88.65( ، ﻴﻤﻜﻥ ﺍﻟﻭﺜﻭﻕ ﺒﺎﺩﻋﺎﺀ ﺍﻻﺴﺘﺎﺫ )ﻴﻜﻭﻥ ﺇﺩﻋﺎﺀ ﺍﻻﺴﺘﺎﺫ ﺼﺤﻴﺤﺎ( ﺒﻨﺴﺒﺔ 09% ﻷﻥ ﺍﻟﺭﻗﻡ 86 ﻭﻗﻊ ﻀﻤﻥ ﻫﺫﻩ ﹰ ﺍﻟﻔﺘﺭﺓ ﺍﻟﺘﻲ ﻤﻘﺩﺍﺭ ﺍﻟﺜﻘﺔ ﻓﻴﻬﺎ ﻫﻭ 09%، ﻭﻤﻥ ﺍﻟﺠﺩﻴﺭ ﺒﺎﻟﺫﻜﺭ ﺃﻥ ﺍﻻﺴﺘﺎﺫ ﻟﻭ ﺍﺩﻋﻰ ﺃﻱ ﻤﺘﻭﺴﻁ ﺨﺎﺭﺝ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻓﻠﻥ ﻨﺴﺘﻁﻴﻊ ﻗﺒﻭل ﺍﺩﻋﺎﺌﻪ ﻭﻴﻜﻭﻥ ﺍﺩﻋﺎﺌﻪ ﺨﺎﻁﺊ ﻭﻴﻜﻭﻥ ﻭﺜﻭﻗﻨﺎ ﻓﻲ ﻗﺭﺍﺭﻨﺎ ﺒﻨﺴﺒﺔ 09% ﺃﻴﻀﺎ. ﹰ ﺍﻟﻁﺭﻴﻘﺔ ﺍﻟﺜﺎﻨﻴﺔ: ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﺨﺘﺒﺎﺭ Tﻟﺩﺭﺍﺴﺔ ﻤﺘﻭﺴﻁ ﻋﻴﻨﺔ ﻭﺍﺤﺩﺓ. 1. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﻋﻤﻭﺩ ﻜﻤﺎ ﻓﻲ ﺍﻟﻤﺜﺎل ﺍﻟﺴﺎﺒﻕ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ).(Arabic 2. ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ )ﻤﻘﺎﺭﻨﺔ ﺍﻟﻤﺘﻭﺴﻁﺎﺕ( Compare Meansﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﻷﻤﺭ)ﺍﺨﺘﺒﺎﺭ Tﻟﻌﻴﻨﺔ ﻭﺍﺤﺩﺓ( One Sample T Testﻜﻤﺎ ﻴﻠﻲ: 43
35.
3. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ ﻻﺨﺘﺒﺎﺭ Tﻟﻌﻴﻨﺔ ﻭﺍﺤﺩﺓ 4. ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭ ) (Arabicﺇﻟﻰ ﺨﺎﻨﺔ Test Variablesﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺴﻬﻡ ﻭﻤﻥ ﺜﻡ ﻨﻜﺘﺏ ﻗﻴﻤﺔ ﺍﻟﻭﺴﻁ ﺍﻟﺫﻱ ﺴﻴﺘﻡ ﺍﻻﺨﺘﺒﺎﺭ ﺒﻨﺎﺀ ﻋﻠﻴﻪ ﻭﻫﻭ 86 ﻓﻲ ﺨﺎﻨﺔ Test Valueﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ً ﺍﻟﺘﺎﻟﻲ : 53
36.
2
1 5. ﻨﻀﻐﻁ ﻋﻠﻰ Optionﻟﻨﺨﺘﺎﺭ ﻤﺴﺘﻭﻯ ﺍﻟﺜﻘﺔ 09.0 = 01.0 − 1 = 1 − α 3 6. ﻨﻜﺘﺏ ﻤﺴﺘﻭﻯ ﺍﻟﺜﻘﺔ 09 ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ Continueﻓﻨﻌﻭﺩ ﻟﻠﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺴﺎﺒﻕ ﻭﻨﻀﻐﻁ Okﻟﺘﻅﻬﺭ ﺍﻟﻨﺘﺎﺌﺞ ﺍﻟﺘﺎﻟﻴﺔ: ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ Tﻟﻌﻴﻨﺔ ﻭﺍﺤﺩﺓ 63
37.
ﻴﺘﻜﻭﻥ ﻨﺎﺘﺞ ﺍﻻﺨﺘﺒﺎﺭ
ﻤﻥ ﺠﺩﻭﻟﻴﻥ، ﺍﻟﺠﺩﻭل ﺍﻷﻭل ﻴﻌﻁﻲ ﺒﻌﺽ ﺍﻟﻤﻌﻠﻭﻤﺎﺕ ﺍﻟﻭﺼﻔﻴﺔ ﻋﻥ ﻤﺘﻐﻴﺭ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻜﻌﺩﺩ ﺍﻟﺩﺭﺠﺎﺕ ﻭﻭﺴﻁﻬﺎ ﺍﻟﺤﺴﺎﺒﻲ ﻭﺍﻨﺤﺭﺍﻓﻬﺎ ﺍﻟﻤﻌﻴﺎﺭﻱ ﻭﺍﻟﺜﺎﻨﻲ ﻴﻌﻁﻲ ﻨﺎﺘﺞ ﺍﺨﺘﺒﺎﺭ Tﻟﻭﺴﻁ ﻋﻴﻨﺔ ﻭﺍﺤﺩﺓ. ﺍﻟﺠﺩﻭل ﺍﻷﻭل ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ ﺍﻻﻨﺤﺭﺍﻑ ﺍﻟﻤﻌﻴﺎﺭﻱ One-Sample Statistics .Std Std. Error N Mean Deviation Mean Arabic 03 04.36 120.12 838.3 ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺃﻥ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ 03 ﺩﺭﺠﺔ، ﺒﻤﺘﻭﺴﻁ ﺤﺴﺎﺒﻲ ﻗﺩﺭﻩ 4.36 ﺩﺭﺠﺔ، ﻭﺒﺎﻨﺤﺭﺍﻑ ﻤﻌﻴﺎﺭﻱ ﻗﺩﺭﻩ 120.12 . ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ: One-Sample Test 86 = Test Value 90% Confidence Interval of the Difference -2( .Sig Mean t df )tailed Difference Lower Upper 991.1- Arabic 92 042. 006.4- 21.11- 29.1 ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺩﺭﺠﺔ ﺍﻟﺤﺭﻴﺔ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ﺍﻟﻔﺭﻕ ﻓﻲ ﺍﻟﻭﺴﻁﻴﻥ ﻓﺘﺭﺓ ﺜﻘﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻭﻫﻭ ﺠﺩﻭل ﺍﺨﺘﺒﺎﺭ Tﺤﻴﺙ ﻴﺒﻴﻥ ﺃﻥ ﺍﻟﻘﻴﻤﺔ ﺍﻟﺘﻲ ﺘﻡ ﺍﻻﺨﺘﺒﺎﺭ ﺒﻨﺎﺀﺍ ﻋﻠﻴﻬﺎ ﻫﻲ 86 ﻭﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ T ﹰ ﻟﻭﺴﻁ ﻤﺠﺘﻤﻊ ﻫﻲ -991.1 ﺒﺩﺭﺠﺔ ﺤﺭﻴﺔ ﻤﻘﺩﺍﺭﻫﺎ 92 = 1 − 03 = 1 − ) nﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ ﻨﺎﻗﺼﺎ ﻭﺍﺤﺩ( ﹰ ﻭﺍﻥ ﺍﻟﻔﺭﻕ ﺒﻴﻥ ﻭﺴﻁ ﺍﻟﻌﻴﻨﺔ ﻭﺍﻟﻘﻴﻤﺔ ﺍﻟﻤﻔﺤﻭﺼﺔ ﻫﻭ -6.4 . ﻗﺒﻭل ﺃﻭ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻴﻤﻜﻥ ﻗﺒﻭل ﺃﻭ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺒﻁﺭﻴﻘﺘﻴﻥ ﻫﻤﺎ: 73
38.
ﺍﻷﻭﻟﻰ: ﻋﻥ ﻁﺭﻴﻕ
ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ 42.0= ) Sig.(2-tailesﻓﻬﻰ ﺘﺒﻴﻥ ﺃﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﺃﻱ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ﻟﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻫﻭ 42.0 ﻭﻫﻲ ﺃﻜﺒﺭ ﻤﻥ ﻗﻴﻤﺔ 01.0 = α ﺒﺎﻟﺘﺎﻟﻲ ﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺃﻱ ﺃﻥ ﺍﺩﻋﺎﺀ ﺍﻻﺴﺘﺎﺫ ﻤﻘﺒﻭل. ﺍﻟﺜﺎﻨﻴﺔ: ﻋﻥ ﻁﺭﻴﻕ ﻓﺘﺭﺓ ﺜﻘﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻥ ﻓﺘﺭﺓ ﺜﻘﺔ ﺍﻹﺨﺘﺒﺎﺭ )29.1,21.11−( ، ﻭﻫﻲ ﻨﻔﺴﻬﺎ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻟﻠﻔﺭﻕ ﺒﻴﻥ ﻭﺴﻁ ﺍﻟﻌﻴﻨﺔ ﻭ86، ﻭﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺇﺫﺍ ﻜﺎﻥ ﺍﻟﺼﻔﺭ ﻤﻭﺠﻭﺩ ﺩﺍﺨل ﻓﺘﺭﺓ ﺜﻘﺔ ﺍﻻﺨﺘﺒﺎﺭ ﺃﻱ ﺃﻥ ﺍﺩﻋﺎﺀ )1( . ﺍﻻﺴﺘﺎﺫ ﻤﻘﺒﻭل. ﺃﻤﺎ ﺇﺫﺍ ﻜﺎﻥ ﺍﻟﺼﻔﺭ ﻏﻴﺭ ﻤﻭﺠﻭﺩ ﻓﻲ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻓﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺇﺫﺍ ﻭﻀﻌﻨﺎ ﺍﻟﻘﻴﻤﺔ ﺼﻔﺭ ﻓﻲ ﺨﺎﻨﺔ Test Valueﺍﺜﻨﺎﺀ ﺍﺠﺭﺍﺀ ﺇﺨﺘﺒﺎﺭ Tﻟﻌﻴﻨﺔ ﻭﺍﺤﺩﺓ ﺒﺩل ﺍﻟﻘﻴﻤﺔ 86 ﺘﻜﻭﻥ ﻓﺘﺭﺓ ﺍﻻﺨﺘﺒﺎﺭ ﺍﻟﻨﺎﺘﺠﺔ ﻫﻲ ﻨﻔﺴﻬﺎ 1 ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻟﻠﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ ﻟﻠﻌﻴﻨﺔ ﺍﻟﺘﻲ ﺤﺼﻠﻨﺎ ﻋﻴﻬﺎ ﻤﻥ ﺨﻼل ﺍﻻﻤﺭ .Explore 83
39.
3. ﺘﻘﺩﻴﺭ ﺍﻟﻨﺴﺒﺔ
ﺍﻟﻤﺌﻭﻴﺔ ﺒﻨﻘﻁﺔ ﻭﻓﺘﺭﺓ ﺜﻘﺔ ﺘﻘﺩﻴﺭ ﺍﻟﻨﺴﺒﺔ ﺍﻟﻤﺌﻭﻴﺔ ﺒﻨﻘﻁﺔ أ. ﻤﺜﺎل 4: ﺇﺫﺍ ﺃﺭﺩﻨﺎ ﺘﻘﺩﻴﺭ ﻨﺴﺒﺔ ﺍﻟﻨﺎﺠﺤﻴﻥ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻓﺴﺤﺒﺕ ﻋﻴﻨﺔ ﻤﻥ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻤﻥ ﺍﻟﺫﻴﻥ ﺘﻘﺩﻤﻭﺍ ﻟﻼﻤﺘﺤﺎﻥ ﻭﻜﺎﻨﺕ ﺩﺭﺠﺎﺘﻬﻡ ﻫﻲ ﺍﻟﺩﺭﺠﺎﺕ ﺍﻟﺘﻲ ﻓﻲ ﺍﻟﻤﺜﺎل ﺭﻗﻡ )1( ﻓﻘﺩﺭ ﺍﻟﻨﺴﺒﺔ ﺍﻟﻤﺌﻭﻴﺔ ﻟﻠﻨﺎﺠﺤﻴﻥ. 1. ﻨﻌﺭﻑ ﺍﻟﻤﺘﻐﻴﺭ ) (Arabicﻭﻤﻥ ﺜﻡ ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﺍﻟﻌﻤﻭﺩ ﺍﻟﺨﺎﺹ ﻓﻴﻪ ﻜﻤﺎ ﻓﻲ ﺍﻟﻤﺜﺎل 1. 2. ﻨﻌﺭﻑ ﺍﻟﻤﺘﻐﻴﺭ ) (Codeﺒﺤﻴﺙ ﻴﻜﻭﻥ ﺭﻤﺯ ﺍﻟﻁﺎﻟﺏ ﺍﻟﻨﺎﺠﺢ ﻫﻭ 1 ﻭﺭﻤﺯ ﺍﻟﻁﺎﻟﺏ ﺍﻟﺭﺍﺴﺏ 0 ﻭﻤﻥ ﺜﻡ ﻨﺩﺨل ﺒﻴﺎﻨﺎﺘﻪ ﻜﻤﺎ ﻫﻭ ﻤﺒﻴﻥ ﻓﻲ ﺍﻟﺠﺩﻭل ﺍﻟﺘﺎﻟﻲ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ 08 56 57 58 03 05 59 08 54 52 03 33 44 25 55 1 1 1 1 1 1 0 0 0 0 0 1 1 1 0 59 77 09 88 87 78 48 84 25 55 75 04 06 57 27 1 1 1 1 1 1 1 0 1 1 1 0 1 1 1 ) (Codeﻜﻤﺎ ﻴﻠﻲ: 3. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﻋﻤﻭﺩﻴﻥ ﻤﺨﺘﻠﻔﻴﻥ ﺍﻷﻭل ) (Arabicﻭﺍﻟﺜﺎﻨﻲ 93
40.
4. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ )ﺍﻻﺤﺼﺎﺀ ﺍﻟﻭﺼﻔﻲ( Descriptive Statisticsﻭﻤﻥ ﺜﻡ ﻨﺨﺘﺎﺭ ﺍﻤﺭ ﺍﻟﺘﻜﺭﺍﺭﺍﺕ Frequencies 5. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺨﺎﺹ ﺒﺄﻤﺭ ﺍﻟﺘﻜﺭﺍﺭﺍﺕ Frequency 6. ﻨﺨﺘﺎﺭ ﺍﻟﻤﺘﻐﻴﺭ Codeﻭﻨﻨﻘﻠﻪ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺴﻬﻡ ﺇﻟﻰ ﻗﺎﺌﻤﺔ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ . Variables 04
41.
7. ﻨﻀﻐﻁ
Okﻓﻴﻅﻬﺭ ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲ ﺘﻘﺩﻴﺭ ﺍﻟﻨﺴﺒﺔ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺍﻟﺠﺩﻭل ﺍﻟﺘﻜﺭﺍﺭﻱ ﻟﻠﻤﺘﻐﻴﺭ Codeﻭﺃﻥ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ ﺍﻟﻤﺩﺨﻠﺔ 03 ﺩﺭﺠﺔ، ﻭﻴﺒﻴﻥ ﺃﻥ ﻋﺩﺩ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﺘﻲ ﻗﻴﻤﺘﻬﺎ 1 )ﺍﻟﻨﺎﺠﺤﻴﻥ( ﻫﻭ 22 ﺒﻨﺴﺒﺔ 3.37% ﻤﻥ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﻫﻭ ﺘﻘﺩﻴﺭ ﺍﻟﻨﺎﺠﺤﻴﻥ ﺒﻨﻘﻁﺔ، ﺃﻤﺎ ﺘﻘﺩﻴﺭ ﻨﺴﺒﺔ ﺍﻟﺭﺍﺴﺒﻴﻥ ﻓﻬﻭ 7.62%. ﺘﻘﺩﻴﺭ ﺍﻟﻨﺴﺒﺔ ﺒﻔﺘﺭﺓ ب. ﺇﻥ ﺒﺭﻨﺎﻤﺞ SPSSﻻ ﻴﻁﺒﻕ ﺤﺴﺎﺏ ﺘﻘﺩﻴﺭ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻟﻠﻨﺴﺒﺔ ﺍﻟﻤﺌﻭﻴﺔ، ﻭﻟﺤل ﻫﺫﻩ ﺍﻟﻤﺸﻜﻠﺔ ﺴﻨﻌﻤل ﻋﻠﻰ ﺘﺤﻭﻴل ﺃﻱ ﻤﺘﻐﻴﺭ ﺇﻟﻰ ﻤﺘﻐﻴﺭ ﺒﺭﻨﻭﻟﻲ ﻓﻤﺜﻼ ﻋﻤﻠﻴﺔ ﺍﻟﺘﺤﻭﻴل ﻓﻲ ﺍﻟﻤﺜﺎل ﺍﻟﺴﺎﺒﻕ ﻟﻤﺘﻐﻴﺭ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﺒﺎﻋﺎﺩﺓ ﺍﻟﺘﺭﻤﻴﺯ، ﺘﺤﻭل ﻤﺘﻐﻴﺭ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﻤﺜﺎل ﺍﻟﺴﺎﺒﻕ ﺇﻟﻰ ﻤﺘﻐﻴﺭ ﺒﺭﻨﻭﻟﻲ، ﻭﻫﺫﺍ 14
42.
ﺒﺩﻭﺭﻩ ﻴﺅﺩﻱ ﺇﻟﻰ
ﺘﺤﻭﻴل ﻤﻔﻬﻭﻡ ﺍﻟﻨﺴﺒﺔ ﺍﻟﻤﺌﻭﻴﺔ ﻜﺄﻨﻬﺎ ﻤﺘﻭﺴﻁ ﻤﺘﻐﻴﺭ ﺒﺭﻨﻭﻟﻲ ﻭﺘﻜﻭﻥ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻟﻠﻨﺴﺒﺔ )2( . ﻫﻲ ﻨﻔﺴﻬﺎ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻟﻤﺘﻭﺴﻁ ﺒﺭﻨﻭﻟﻲ ﻤﺜﺎل5: ﺇﺫﺍ ﺼﻤﻡ ﺒﺭﻨﺎﻤﺞ ﻻﻨﺘﺎﺝ ﺍﻻﺭﻗﺎﻡ ﻋﺸﻭﺍﺌﻴﺎ ﻓﺄﻨﺘﺞ ﺍﻷﺭﻗﺎﻡ ﺍﻟﺘﺎﻟﻲ ﹰ 87317518 69239276 11656665 48474323 78954653 ﻗﺩﺭ ﻨﺴﺒﺔ ﺍﻻﺭﻗﺎﻡ ﺍﻟﻔﺭﺩﻴﺔ ﺒﻔﺘﺭﺓ ﻤﻘﺩﺍﺭﻫﺎ 59% ؟ 1. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﻤﺘﻐﻴﺭ ﻨﺴﻤﻴﻪ ) (Numbersﻨﺩﺨل ﻓﻴﻪ ﺍﻷﺭﻗﺎﻡ ﺍﻟﺘﻲ ﻴﻨﺘﺠﻬﺎ ﺍﻟﻜﻤﺒﻴﻭﺘﺭ ﻭﻤﺘﻐﻴﺭ ﺁﺨﺭ ﻫﻭ ) (Codeﻨﺩﺨل ﻓﻴﻪ ﺭﻤﺯ ﺍﻟﺭﻗﻡ ﻓﺭﺩﻴﺎ ﺃﻭ ﺯﻭﺠﻴﺎ ﺒﺤﻴﺙ )0= ﺯﻭﺠﻲ، 1= ﹰ ﹰ )3( ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: ﻓﺭﺩﻱ( ﻫﺫﻩ ﺍﻟﻁﺭﻴﻘﺔ ﻤﻥ ﺍﻟﻨﺎﺤﻴﺔ ﺍﻟﻨﻅﺭﻴﺔ ﺼﺤﻴﺤﺔ، ﻭﻟﻜﻥ ﻓﻲ ﺒﺭﻨﺎﻤﺞ SPSSﻤﻥ ﺍﻟﻨﺎﺤﻴﺔ ﺼﺤﻴﺤﺔ ﻟﺤﺩ ﻤﺎ ﻭﺘﻜﻭﻥ ﺃﺩﻕ ﻋﻨﺩﻤﺎ ﺘﻜﻭﻥ ﺍﻟﻌﻴﻨﺎﺕ ﻜﺒﻴﺭﺓ 2 ﻭﻨﺴﺘﻁﻴﻊ ﺘﻘﺭﻴﺏ ﺘﻭﺯﻴﻊ Tﻟﺘﻭﺯﻴﻊ Zﺍﻟﻁﺒﻴﻌﻲ ﻓﺘﻜﻭﻥ ﺍﻟﻨﺘﺎﺌﺞ ﻤﺘﻘﺎﺭﺒﺔ ﺠﺩﺍ. ﹰ ﺒﻌﻤﻠﻴﺔ ﺍﻋﺎﺩﺓ ﺘﺭﻤﻴﺯ ﺍﻟﻤﺘﻐﻴﺭ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺭﻤﻭﺯ 0 ﻭ1 ﺘﻡ ﺘﺤﻭﻴل ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻌﺸﻭﺍﺌﻲ ﺍﻟﻰ ﻤﺘﻐﻴﺭ ﺒﺭﻨﻭﻟﻲ ﺍﻟﺫﻱ ﻤﺘﻭﺴﻁﻪ ﺍﻟﺤﺴﺎﺒﻲ ﻫﻭ 3 ﻭﻫﻲ ﻨﻔﺴﻬﺎ ﺘﻘﺩﻴﺭ ﺍﻟﻨﺴﺒﺔ ﺍﻟﻤﺌﻭﻴﺔ ﻟﻠﺭﺍﺴﺒﻴﻥ. E (X ) = p 24
43.
Descriptive Statistics
ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ 2. )ﺍﻻﺤﺼﺎﺀﺍﺕ ﺍﻟﻭﺼﻔﻴﺔ( ﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﻷﻤﺭ ﺍﺴﺘﻜﺸﻑ Exploreﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ ﺍﻟﺨﺎﺹ ﺒﺎﻷﻤﺭ . Explore 3. 2 1 34
44.
Dependent ﻟﺨﺎﻨﺔCode
ﻭﻤﻥ ﺜﻡ ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭStatistics 4. ﻨﻀﻊ ﻋﻼﻤﺔ ﻋﻠﻰ ﺨﺎﻨﺔ ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲStatistics ﻭﻤﻥ ﺜﻡ ﺒﺎﻟﻀﻐﻁ ﻋﻠﻰ ﺯﺭList 3 ﻟﻠﻌﻭﺩﺓ ﻟﻠﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺴﺎﺒﻕContinue 5. ﻨﻜﺘﺏ ﻤﻘﺩﺍﺭ ﺍﻟﺜﻘﺔ ﻭﻫﻭ 59% ﻭﻨﻀﻐﻁ ﻟﻴﻅﻬﺭ ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲOk 6. ﺍﻀﻐﻁ ﻋﻠﻰ Std. Statistic Error Code Mean .55 .080 95% Confidence Lower ﺍﻟﺤﺩ ﺍﻻﺩﻨﻰ ﻟﻠﻔﺘﺭﺓ Interval for Bound .39 Mean Upper .71 ﺍﻟﺤﺩ ﺍﻷﻋﻠﻰ ﻟﻠﻔﺘﺭﺓ Bound 5% Trimmed Mean .56 Median 1.00 Variance .254 Std. Deviation .504 Minimum 0 Maximum 1 Range 1 Interquartile Range 1 Skewness -.209 .374 Kurtosis -2.062 .733 44
45.
ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺍﻟﺴﺎﺒﻕ
ﺃﻥ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﺒﻤﻘﺩﺍﺭ 59% ﻟﻨﺴﺒﺔ ﺍﻷﻋﺩﺍﺩ ﺍﻟﻔﺭﺩﻴﺔ ﻫﻲ )17.0 ,93.0 ( )4(. 4.ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻟﻤﺘﻌﻠﻘﺔ ﻓﻲ ﻨﺴﺒﺔ ﻟﻤﺠﺘﻤﻊ ﻭﺍﺤﺩ: ﺃ. ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻟﻤﺘﻌﻠﻘﺔ ﻓﻲ ﻨﺴﺒﺔ ﻓﻲ ﺤﺎﻟﺔ ﺘﻘﺴﻴﻡ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺤﺴﺏ ﻗﻴﻤﺔ ﻤﻌﻴﻨﺔ: ﻤﺜﺎل6: ﺇﺫﺍ ﺇﺩﻋﻰ ﺍﺴﺘﺎﺫ ﻤﺎﺩﺓ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺃﻥ ﻨﺴﺒﺔ ﺍﻟﺭﺍﺴﺒﻴﻥ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺃﻗل ﻤﻥ 04% ﻓﺴﺤﺒﺕ ﻋﻴﻨﺔ ﻤﻥ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺍﻟﻤﺒﻴﻨﺔ ﻓﻲ ﺍﻟﻤﺜﺎل 1 ﻓﻬل ﺍﺩﻋﺎﺀ ﺍﻻﺴﺘﺎﺫ ﺼﺤﻴﺢ ﺃﻡ ﺨﺎﻁﺊ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = α؟ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ 08 58 57 56 54 52 03 33 44 25 55 08 59 05 03 59 88 09 77 25 55 75 04 06 57 27 84 48 78 87 ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻨﺴﺒﺔ ﺍﻟﻨﺎﺠﺤﻴﻥ ﻤﺴﺎﻭﻴﺔ 04%. ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ: ﻨﺴﺒﺔ ﺍﻟﻨﺎﺠﺤﻴﻥ ﺃﻗل ﻤﻥ 04%. 1. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﻋﻤﻭﺩ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ) (Arabicﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: ﺒﻌﻤﻠﻴﺔ ﺍﻋﺎﺩﺓ ﺘﺭﻤﻴﺯ ﺍﻟﻤﺘﻐﻴﺭ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺭﻤﻭﺯ 0 ﻭ1 ﺘﻡ ﺘﺤﻭﻴل ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻌﺸﻭﺍﺌﻲ ﺍﻟﻰ ﻤﺘﻐﻴﺭ ﺒﺭﻨﻭﻟﻲ ﺍﻟﺫﻱ ﻤﺘﻭﺴﻁﻪ ﺍﻟﺤﺴﺎﺒﻲ ﻫﻭ 4 ﻭﻫﻲ ﻨﻔﺴﻬﺎ ﺘﻘﺩﻴﺭ ﺍﻟﻨﺴﺒﺔ ﺍﻟﻤﺌﻭﻴﺔ ﻟﻸﺭﻗﺎﻡ ﺍﻟﻔﺭﺩﻴﺔ ﻭﺘﻜﻭﻥ ﺒﺫﻟﻙ ﺘﻘﺩﻴﺭ ﻨﺴﺒﺔ ﻟﻸﺭﻗﺎﻡ ﺍﻟﻔﺭﺩﻴﺔ ﺒﻨﻘﻁﺔ ﻫﻲ 55.0 . E (X ) = p 54
46.
2. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ )ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ( Nonparametric Testsﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﻷﻤﺭ )ﺍﺨﺘﺒﺎﺭ ﺫﺍﺕ ﺍﻟﺤﺩﻴﻥ( Binomial Test ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 3. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ: 64
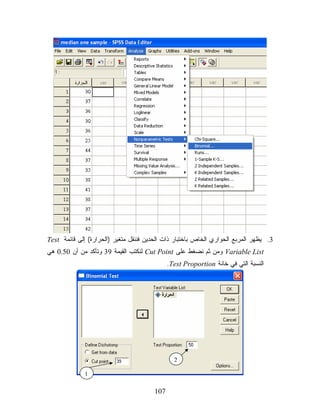
47.
4. ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭ
Arabicﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺴﻬﻡ ﺇﻟﻰ ﺨﺎﻨﺔ Test Variables Listﻭﻤﻥ ﺜﻡ ﻨﻌﻠﻡ ﻋﻠﻰ ﺍﻻﺨﺘﻴﺎﺭ Cut pointﻟﻨﻜﺘﺏ ﺍﻟﻘﻴﻤﺔ 94 ﻟﺘﺩل ﻋﻠﻰ ﺃﻥ 94 ﻫﻲ ﺍﻟﻨﻘﻁﺔ ﺍﻟﻔﺎﺼﻠﺔ ﺒﻴﻥ ﺍﻟﻨﺎﺠﺤﻴﻥ ﻭﺍﻟﺭﺍﺴﺒﻴﻥ ﺤﻴﺙ ﺃﻜﺒﺭ ﻗﻴﻤﺔ ﻟﻠﺭﺍﺴﺒﻴﻥ ﻫﻲ 94، ﻭﺃﺼﻐﺭ ﻗﻴﻤﺔ ﻟﻠﻨﺎﺠﺤﻴﻥ 05، ﻭﻤﻥ ﺜﻡ ﻨﻜﺘﺏ ﺍﻟﻨﺴﺒﺔ ﺍﻟﻤﺌﻭﻴﺔ ﺍﻟﺘﻲ ﻨﺭﻴﺩ ﺍﺨﺘﺒﺎﺭﻫﺎ ﻭﻫﻲ 04.0 ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 2 1 5. ﻨﻀﻐﻁ Okﻟﺘﻅﻬﺭ ﺍﻟﻨﺘﺎﺌﺞ ﺍﻟﺘﺎﻟﻴﺔ ﺍﻟﻨﺘﺎﺌﺞ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺃﻥ ﻋﺩﺩ ﺍﻟﺭﺍﺴﺒﻴﻥ ﻫﻭ 8 ﺃﺸﺨﺎﺹ ) ﺍﻟﺤﺎﺼﻠﻴﻥ ﻋﻠﻰ ﺩﺭﺠﺔ ﺃﻗل ﻤﻥ ﺃﻭ ﻴﺴﺎﻭﻱ 94( ﺒﻨﺴﺒﺔ ﻤﺌﻭﻴﺔ 72.0 ﻭﺃﻥ ﻋﺩﺩ ﺍﻟﻨﺎﺠﺤﻴﻥ ﻫﻭ 22 ﺒﻭﺍﻗﻊ ﻨﺴﺒﺔ ﻤﺌﻭﻴﺔ 37.0 ﺍﻟﻘﻴﻤﺔ ﺍﻟﺘﻲ ﻨﺭﻴﺩ ﻤﻘﺎﺭﻨﺔ ﺍﻟﻨﺴﺒﺔ ﻤﻌﻬﺎ ﻫﻲ 4.0 . 74
48.
• ﻗﺒﻭل ﺃﻭ
ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻤﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼ ﻴﺘﺒﻴﻥ ﺃﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ 490.0= ) Asymp. Sig. (1-tailedﻭﻫﻲ ﺃﻜﺒﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. ﻻﺤﻅ ﺍﻥ ﻓﻭﻕ ﺍﻟﺭﻗﻡ 490.0 ﻴﻭﺠﺩ ﺍﻟﺭﻤﺯﻴﻥ aﻭ bﻓﻴﺩل ﺍﻟﺭﻤﺯ aﻋﻠﻰ ﺃﻥ ﻨﺴﺒﺔ ﺍﻟﺭﺍﺴﺒﻴﻥ ﺃﻗل ﻤﻥ 4.0 ﻭﻴﺩل ﺍﻟﺭﻤﺯ bﻋﻠﻰ ﺃﻨﻪ ﺘﻡ ﺍﺴﺘﺨﺩﺍﻡ ﺘﻘﺭﻴﺏ Zﻟﺤﺴﺎﺏ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﻭﻗﻴﻤﺔ ﺍﻻﺨﺘﺒﺎﺭ. ﺏ. ﺍﺨﺘﺒﺎﺭ ﺍﻟﻨﺴﺒﺔ ﺤﺴﺏ ﺸﺭﻁ ﻤﻌﻴﻥ ﻤﺜﺎل 7: ﻓﻲ ﺍﻟﻤﺜﺎل ﺭﻗﻡ 5 ﺍﺨﺘﺒﺭ ﻫل ﻤﻤﻜﻥ ﺍﻋﺘﺒﺎﺭ ﻨﺴﺒﺔ ﺍﻻﻋﺩﺍﺩ ﺍﻟﻔﺭﺩﻴﺔ ﺍﻟﺘﻲ ﻴﻨﺘﺠﻬﺎ ﺍﻟﻜﻤﺒﻴﻭﺘﺭ 05%. 1. ﻨﻘﻭﻡ ﺒﺎﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻜﻤﺎ ﻓﻲ ﺍﻟﻤﺜﺎل ﺭﻗﻡ 5 ﻭﻨﺩﺨل ﺍﻟﻤﺘﻐﻴﺭﻴﻥ Numberﻭ=0) Code ﺯﻭﺠﻲ، 1= ﻓﺭﺩﻱ( 2. ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ )ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ( Nonparametric Testsﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﻷﻤﺭ )ﺍﺨﺘﺒﺎﺭ ﺫﺍﺕ ﺍﻟﺤﺩﻴﻥ( Binomial Test 3. ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭ Codeﺍﻟﻰ ﺨﺎﻨﺔ Test Variablesﻭﻨﺘﺄﻜﺩ ﺃﻥ ﺍﻟﻨﺴﺒﺔ ﺍﻟﻤﻭﺠﻭﺩﺓ ﻓﻲ ﺨﺎﻨﺔ Test Proportionﻫﻲ 05.0 ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ Ok 1 2 4. ﻴﻅﻬﺭ ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲ 84
49.
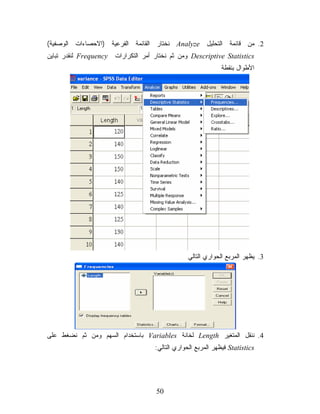
ﻤﻥ ﺍﻟﻨﺎﺘﺞ ﻴﺘﺒﻥ
ﺃﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻭﻫﻲ 636.0=)Asymp. Sig. (2-tailed ﻭﻫﻲ ﺍﻜﺒﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 50.0 = αﺒﺎﻟﺘﺎﻟﻲ ﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. 5. ﺍﻟﻔﺭﻀﻴﺎﺕ ﻭﻓﺘﺭﺍﺕ ﺍﻟﺜﻘﺔ ﺤﻭل ﺘﺒﺎﻴﻥ ﻤﺠﺘﻤﻊ ﻭﺍﺤﺩ ﻤﺜﺎل 8: ﺇﺫﺍ ﻜﺎﻨﺕ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﺘﺎﻟﻴﺔ 051 041 021051 041 521 041 031 521 041 ﺘﻤﺜل ﺃﻁﻭﺍل ﻗﻁﻊ ﻤﻌﻴﻨﺔ ﻤﻥ ﺍﻟﻘﻤﺎﺵ ﺍﻟﺫﻱ ﻴﻨﺘﺠﻪ ﻤﺼﻨﻊ ﻓﺎﻭﺠﺩ ﻓﺘﺭﺓ 09% ﺜﻘﺔ ﻟﺘﺒﺎﻴﻥ ﺍﻷﻁﻭﺍل ﻭﻤﻥ ﺜﻡ ﺍﺨﺘﺒﺭ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺍﻟﺘﻲ ﺘﻘﻭل ﺃﻥ ﺘﺒﺎﻴﻥ ﺃﻁﻭﺍل ﺍﻷﻗﻤﺸﺔ 003. ﺃﻭﻻ: ﻨﻘﺩﺭ ﺍﻟﺘﺒﺎﻴﻥ ﺒﻨﻘﻁﺔ ﹰ 1. ﻨﺩﺨل ﺒﻴﺎﻨﺎﺕ ﺍﻷﻁﻭﺍل ﻓﻲ ﻤﺘﻐﻴﺭ ﻨﺴﻤﻴﻪ .Length 94
50.
2. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ )ﺍﻻﺤﺼﺎﺀﺍﺕ ﺍﻟﻭﺼﻔﻴﺔ( Descriptive Statisticsﻭﻤﻥ ﺜﻡ ﻨﺨﺘﺎﺭ ﺃﻤﺭ ﺍﻟﺘﻜﺭﺍﺭﺍﺕ Frequencyﻟﻨﻘﺩﺭ ﺘﺒﺎﻴﻥ ﺍﻷﻁﻭﺍل ﺒﻨﻘﻁﺔ 3. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 4. ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭ Lengthﻟﺨﺎﻨﺔ Variablesﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺴﻬﻡ ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ Statisticsﻓﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ: 05
51.
ﻨﺨﺘﺎﺭ ﺤﺴﺎﺏ ﺍﻟﺘﺒﺎﻴﻥ
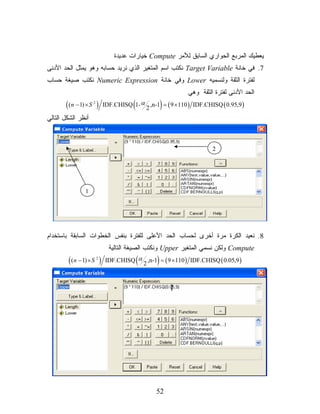
ﻤﻥ ﺨﻼل Varianceﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ Continueﻟﻠﻌﻭﺩﺓ ﻟﻠﻤﺭﺒﻊ 5. ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺴﺎﺒﻕ ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ Okﻟﻠﺤﺼﻭل ﻋﻠﻰ ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲ ﻴﺒﻴﻥ ﺍﻟﻨﺎﺘﺞ ﺃﻥ ﺘﻘﺩﻴﺭ ﺍﻟﺘﺒﺎﻴﻥ ﺒﻨﻘﻁﺔ ﻫﻭ 011. ﺜﺎﻨﻴﺎ: ﺍﻴﺠﺎﺩ ﺘﻘﺩﻴﺭ ﺍﻟﺘﺒﺎﻴﻥ ﺒﻔﺘﺭﺓ 09% ﹰ 6. ﻤﻥ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ Transformﻨﺨﺘﺎﺭ ﺃﻤﺭ ﺍﻟﺤﺴﺎﺏ Computeﻓﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ 15
52.
ﻴﻌﻁﻴﻙ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ
ﺍﻟﺴﺎﺒﻕ ﻟﻸﻤﺭ Computeﺨﻴﺎﺭﺍﺕ ﻋﺩﻴﺩﺓ 7. ﻓﻲ ﺨﺎﻨﺔ Target Variableﻨﻜﺘﺏ ﺍﺴﻡ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺫﻱ ﻨﺭﻴﺩ ﺤﺴﺎﺒﻪ ﻭﻫﻭ ﻴﻤﺜل ﺍﻟﺤﺩ ﺍﻷﺩﻨﻰ ﻟﻔﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻭﻟﻨﺴﻤﻴﻪ Lowerﻭﻓﻲ ﺨﺎﻨﺔ Numeric Expressionﻨﻜﺘﺏ ﺼﻴﻐﺔ ﺤﺴﺎﺏ ﺍﻟﺤﺩ ﺍﻷﺩﻨﻰ ﻟﻔﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻭﻫﻲ ) ( (n − 1) × S 2 ( ) ) 9,59.0 ( IDF.CHISQ 1- α ,n-1 = ( 9 × 110 ) IDF.CHISQ 2 ﺃﻨﻅﺭ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 2 1 8. ﻨﻌﻴﺩ ﺍﻟﻜﺭﺓ ﻤﺭﺓ ﺃﺨﺭﻯ ﻟﺤﺴﺎﺏ ﺍﻟﺤﺩ ﺍﻷﻋﻠﻰ ﻟﻠﻔﺘﺭﺓ ﺒﻨﻔﺱ ﺍﻟﺨﻁﻭﺍﺕ ﺍﻟﺴﺎﺒﻘﺔ ﺒﺎﺴﺘﺨﺩﺍﻡ Computeﻭﻟﻜﻥ ﻨﺴﻤﻲ ﺍﻟﻤﺘﻐﻴﺭ Upperﻭﻨﻜﺘﺏ ﺍﻟﺼﻴﻐﺔ ﺍﻟﺘﺎﻟﻴﺔ ) ( (n − 1) × S 2 ( ) ) 9,50.0 ( IDF.CHISQ α ,n-1 = ( 9 × 110 ) IDF.CHISQ 2 25
53.
9. ﻓﻲ ﺸﺎﺸﺔ
ﺍﻟﺒﻴﺎﻨﺎﺕ ﻨﻼﺤﻅ ﻅﻬﻭﺭ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ ﺃﻭ ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲ: 5 ﺘﻜﻭﻥ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﺒﻤﻘﺩﺍﺭ 09% ﻫﻲ )37.792 ,15.85 ( ﺜﺎﻟﺜﺎ: ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ ﹰ 003 = 2 H 0 : σ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ : ﺘﺒﺎﻴﻥ ﺃﻁﻭﺍل ﺍﻷﻗﻤﺸﺔ 003. 003 ≠ 2 H a : σ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ: ﺘﺒﺎﻴﻥ ﺃﻁﻭﺍل ﺍﻷﻗﻤﺸﺔ ﻴﺨﺘﻠﻑ ﻋﻥ 003 ﻤﻥ ﺍﻟﻭﺍﻀﺢ ﺃﻥ )37.792 ,15.85 ( ∉ 003 ﻭﺒﺎﻟﺘﺎﻟﻲ ﺘﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. ﻭﻫﻨﺎﻙ ﻁﺭﻴﻘﺔ ﺃﺨﺭﻯ ﻟﻺﺠﺎﺒﺔ ﻋﻠﻰ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻤﻥ ﺨﻼل ﻜﺘﺎﺒﺔ ﺍﻟﺼﻴﻐﺔ ﺍﻟﺘﺎﻟﻴﺔ ﻓﻲ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ Compute ( ) 159.0 = ) 9, ) 003 011 × )1 − 01( ( ( SIG.CHISQ ( (n − 1) × S 2 σ 0 ) ,n-1 = SIG.CHISQ 2 ﺇﺫﺍ ﻜﺎﻥ ﺍﻟﺘﺒﺎﻴﻥ ﻤﻌﻁﻰ ﻓﻲ ﺍﻟﻤﺜﺎل ﻤﺒﺎﺸﺭﺓ ﻻ ﻨﺤﺘﺎﺝ ﺃﻤﺭ ﺍﻟﺘﻜﺭﺍﺭﺍﺕ Frequencyﻟﺤﺴﺎﺏ ﺍﻟﺘﺒﺎﻴﻥ. 5 35
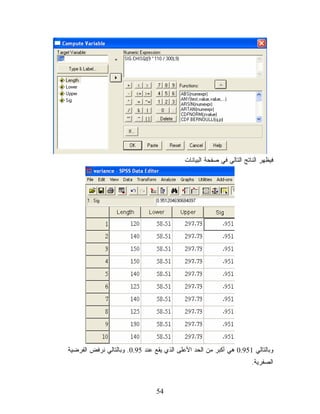
54.
ﻓﻴﻅﻬﺭ ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲ
ﻓﻲ ﺼﻔﺤﺔ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﺒﺎﻟﺘﺎﻟﻲ 159.0 ﻫﻲ ﺃﻜﺒﺭ ﻤﻥ ﺍﻟﺤﺩ ﺍﻷﻋﻠﻰ ﺍﻟﺫﻱ ﻴﻘﻊ ﻋﻨﺩ 59.0. ﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. 45
55.
ﺍﻟﻭﺤﺩﺓ ﺍﻟﺜﺎﻨﻴﺔ ﺍﻻﺴﺘﺩﻻل ﺍﻻﺤﺼﺎﺌﻲ ﺤﻭل
ﺘﺒﺎﻴﻥ ﻤﺠﺘﻤﻌﻴﻥ 55
56.
ﺍﻟﻭﺤﺩﺓ ﺍﻟﺜﺎﻨﻴﺔ: ﺍﻻﺴﺘﺩﻻل
ﺍﻻﺤﺼﺎﺌﻲ ﺤﻭل ﺘﺒﺎﻴﻥ ﻤﺠﺘﻤﻌﻴﻥ ﻟﻘﺩ ﺘﻌﺭﻀﺕ ﻋﺯﻴﺯﻱ ﺍﻟﺩﺍﺭﺱ ﻓﻲ ﺍﻟﻭﺤﺩﺓ ﺍﻷﻭﻟﻰ ﺇﻟﻰ ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻟﻤﺘﻌﻠﻘﺔ ﺒﻤﺘﻭﺴﻁ ﻭﻨﺴﺒﺔ ﻭﺘﺒﺎﻴﻥ ﻤﺠﺘﻤﻊ ﻭﺍﺤﺩ، ﻭﻗﺩ ﺘﻌﺭﻓﺕ ﻋﻠﻰ ﻜﻴﻔﻴﺔ ﺍﺠﺭﺍﺀ ﻫﺫﻩ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ، ﻭﺍﻟﺘﻘﺩﻴﺭ ﻤﻥ ﺨﻼل ﺒﺭﻨﺎﻤﺞ .SPSSﻭﻻ ﺒﺩ ﺃﻨﻙ ﻻﺤﻅﺕ ﺃﻥ ﺒﺭﻨﺎﻤﺞ SPSSﻴﺘﻌﺎﻤل ﻤﻊ ﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ ﻭﻴﻌﻤل ﺠﻤﻴﻊ ﺍﺨﺘﺒﺎﺭﺍﺘﻪ ﻋﻠﻰ ﺍﺴﺎﺱ ﺘﻘﺩﻴﺭ ﻤﻌﺎﻟﻡ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ. 1. ﻓﺘﺭﺍﺕ ﺍﻟﺜﻘﺔ ﻭﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻭﻕ ﺒﻴﻥ ﻤﺘﻭﺴﻁ ﻤﺠﺘﻤﻌﻴﻥ ﻤﺴﺘﻘﻠﻴﻥ. ﻴﻨﻘﺴﻡ ﺍﻟﻤﻘﺭﺭ ﺍﻟﻨﻅﺭﻱ ﻓﻲ ﻫﺫﺍ ﺍﻟﻤﻭﻀﻭﻉ، ﻭﻫﻭ ﺘﻘﺩﻴﺭ ﻓﺘﺭﺍﺕ ﺜﻘﺔ ﻟﻠﻔﺭﻕ ﺒﻴﻥ ﻤﺘﻭﺴﻁ ﻤﺠﺘﻤﻌﻴﻥ ﻭﺍﺠﺭﺍﺀ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﻟﻬﺫﻩ ﺍﻟﻔﺭﻭﻕ ﻓﻲ ﺜﻼﺜﺔ ﺤﺎﻻﺕ ﻫﻲ ﻤﻌﻠﻭﻤﺘﺎﻥ.2 σ1,σ 1. ﻋﻨﺩﻤﺎ 2 σ1,σﻤﺠﻬﻭﻟﺘﺎﻥ ﻭﺤﺠﻡ ﺍﻟﻌﻴﻨﺎﺕ ﻜﺒﻴﺭﺓ. 2. ﻋﻨﺩﻤﺎ 2 σ1,σﻤﺠﻬﻭﻟﺘﺎﻥ ﻭﺤﺠﻡ ﺍﻟﻌﻴﻨﺎﺕ ﺼﻐﻴﺭﺓ. 3. ﻋﻨﺩﻤﺎ ﻭﻫﻨﺎ ﻻ ﺒﺩ ﻤﻥ ﺍﻻﺸﺎﺭﺓ ﺇﻟﻰ ﺃﻥ ﺒﺭﻨﺎﻤﺞ SPSSﻜﻤﺎ ﺃﺴﻠﻔﻨﺎ ﺍﻟﺫﻜﺭ ﻴﺘﻌﺎﻤل ﻤﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ، ﻭﺍﻟﺘﻲ ﻤﻥ ﺨﻼﻟﻬﺎ ﻴﻘﺩﺭ ﻤﻌﺎﻟﻡ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ، ﻭﻤﻨﻬﺎ ﺍﻟﺘﺒﺎﻴﻥ، ﻓﻬﻭ ﻻ ﻴﻘﻭﻡ ﺒﺎﻻﺨﺘﺒﺎﺭﺍﺕ ﺃﻭ ﻓﺘﺭﺍﺕ ﺍﻟﺜﻘﺔ ﻓﻲ ﺍﻟﺤﺎﻟﺔ ﺍﻷﻭﻟﻰ ﺃﻋﻼﻩ، ﻭﺇﺫﺍ ﺍﻀﻁﺭﺭﻨﺎ ﻟﻌﻤل ﺍﻟﺨﻁﻭﺓ ﺍﻷﻭﻟﻰ ﺴﺘﻜﻭﻥ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻷﻤﺭ Computeﺍﻟﺫﻱ ﺘﻌﺭﻀﻨﺎ ﻟﻪ ﻓﻲ ﺍﻟﺴﺎﺒﻕ ﻭﻟﻜﻨﻨﺎ ﻟﻥ ﻨﺘﻌﺭﺽ ﻟﺫﻟﻙ ﻷﻥ ﺍﻟﻘﻴﺎﻡ ﺒﺫﻟﻙ ﻤﺜل ﺍﻟﻘﻴﺎﻡ ﺒﻪ ﻴﺩﻭﻴﹰ، ﻟﺫﻟﻙ ﻻ ﺠﺩﻭﻯ ﺎ ﻤﻥ ﺍﺴﺘﺨﺩﺍﻡ ﺍﻟﺤﺎﺴﻭﺏ، ﻭﻫﺫﺍ ﺍﻻﻤﺭ ﻻ ﻴﻨﻁﺒﻕ ﻓﻘﻁ ﻋﻠﻰ ﺒﺭﻨﺎﻤﺞ SPSSﻭﻟﻜﻥ ﻋﻠﻰ ﺠﻤﻴﻊ ﺍﻟﺒﺭﺍﻤﺞ ﺍﻻﺤﺼﺎﺌﻴﺔ. ﻤﺜﺎل 1: ﺇﺫﺍ ﻜﺎﻨﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﻁﺭﻕ ﺍﻻﺤﺼﺎﺀ ﺒﺎﻟﺤﺎﺴﻭﺏ ﺤﺴﺏ ﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ ﻤﻭﺯﻋﺔ ﻜﻤﺎ ﻴﻠﻲ: ﺩﺭﺠﺎﺕ ﺍﻻﻨﺎﺙ ﺃﻭﻻ: ﹰ 08 58 57 56 55 25 44 33 03 52 54 05 59 08 03 59 88 09 77 27 57 06 04 75 55 25 78 48 84 87 37 77 57 ﺩﺭﺠﺎﺕ ﺍﻟﺫﻜﻭﺭ ﺜﺎﻨﻴﺎ: ﹰ 77 03 52 03 44 04 56 44 77 57 97 54 48 83 58 67 26 44 24 77 66 56 89 59 63 84 59 16 06 58 07 39 89 08 57 65
57.
ﻓﺎﻭﺠﺩ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ
ﻟﻠﻔﺭﻕ ﺒﻴﻥ ﻭﺴﻁ ﺩﺭﺠﺎﺕ ﺍﻟﺫﻜﻭﺭ ﻭﺍﻻﻨﺎﺙ ﺒﻤﻘﺩﺍﺭ 59% ﻭﻤﻥ ﺜﻡ ﺒﻴﻥ ﻫل ﺘﻭﺠﺩ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﺒﻴﻥ ﻤﺘﻭﺴﻁ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ )ﺍﻟﺫﻜﻭﺭ ﻭﺍﻻﻨﺎﺙ( ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = α؟ ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻻﻴﻭﺠﺩ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﺍﻟﺫﻜﻭﺭ ﻭﺍﻻﻨﺎﺙ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ : ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﺍﻟﺫﻜﻭﺭ ﻭﺍﻻﻨﺎﺙ. 1. ﻨﻌﺭﻑ ﻤﺘﻐﻴﺭ )ﺍﻟﺩﺭﺠﺔ( ﻭﻤﺘﻐﻴﺭ )ﺍﻟﺠﻨﺱ( ﻓﻲ ﺸﺎﺸﺔ ﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻭﻟﻴﻜﻥ ﺍﻟﻜﻭﺩ ﺍﻟﻤﺘﺒﻊ ﻟﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ )ﺫﻜﺭ=1، ﻭﺃﻨﺜﻰ=2(. 2. ﻨﺩﺨل ﺒﻴﺎﻨﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﺘﻐﻴﺭ )ﺍﻟﺩﺭﺠﺔ( ﻭﻨﺩﺨل ﺒﻴﺎﻨﺎﺕ ﺠﻨﺱ ﺍﻟﻁﺎﻟﺏ ﻓﻲ ﻤﺘﻐﻴﺭ )ﺍﻟﺠﻨﺱ( ﺍﻟﺫﻱ ﻴﺒﻴﻥ ﺼﺎﺤﺏ ﺍﻟﺩﺭﺠﺔ ﺇﻥ ﻜﺎﻥ ﺫﻜﺭﺍ ﺃﻡ ﺃﻨﺜﻰ ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: ﹰ 75
58.
3. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﻤﻘﺎﺭﻨﺔ ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ ) (Compare meanﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﺨﺘﺒﺎﺭ Tﻟﻠﻌﻴﻨﺎﺕ ﺍﻟﻤﺴﺘﻘﻠﺔ ) (Independent –Samples T-testﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 4. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 85
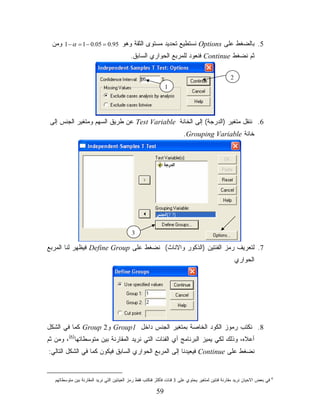
59.
5. ﺒﺎﻟﻀﻐﻁ ﻋﻠﻰ
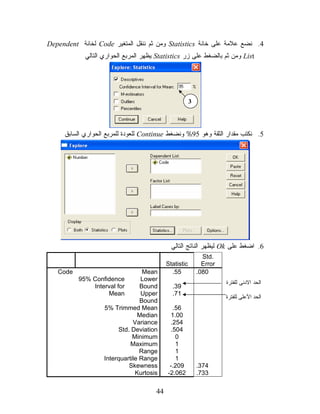
Optionsﻨﺴﺘﻁﻴﻊ ﺘﺤﺩﻴﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺜﻘﺔ ﻭﻫﻭ 59.0 = 50.0 − 1 = 1 − αﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ Continueﻓﻨﻌﻭﺩ ﻟﻠﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺴﺎﺒﻕ. 2 1 6. ﻨﻨﻘل ﻤﺘﻐﻴﺭ )ﺍﻟﺩﺭﺠﺔ( ﺇﻟﻰ ﺍﻟﺨﺎﻨﺔ Test Variableﻋﻥ ﻁﺭﻴﻕ ﺍﻟﺴﻬﻡ ﻭﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ ﺇﻟﻰ ﺨﺎﻨﺔ .Grouping Variable 3 7. ﻟﺘﻌﺭﻴﻑ ﺭﻤﺯ ﺍﻟﻔﺌﺘﻴﻥ )ﺍﻟﺫﻜﻭﺭ ﻭﺍﻻﻨﺎﺙ( ﻨﻀﻐﻁ ﻋﻠﻰ Define Groupﻓﻴﻅﻬﺭ ﻟﻨﺎ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ 8. ﻨﻜﺘﺏ ﺭﻤﻭﺯ ﺍﻟﻜﻭﺩ ﺍﻟﺨﺎﺼﺔ ﺒﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ ﺩﺍﺨل 1 Groupﻭ2 Groupﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺃﻋﻼﻩ، ﻭﺫﻟﻙ ﻟﻜﻲ ﻴﻤﻴﺯ ﺍﻟﺒﺭﻨﺎﻤﺞ ﺃﻱ ﺍﻟﻔﺌﺎﺕ ﺍﻟﺘﻲ ﻨﺭﻴﺩ ﺍﻟﻤﻘﺎﺭﻨﺔ ﺒﻴﻥ ﻤﺘﻭﺴﻁﺎﺘﻬﺎ)6(، ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ Continueﻓﻴﻌﻴﺩﻨﺎ ﺇﻟﻰ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺴﺎﺒﻕ ﻓﻴﻜﻭﻥ ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: ﻓﻲ ﺒﻌﺽ ﺍﻻﺤﻴﺎﻥ ﻨﺭﻴﺩ ﻤﻘﺎﺭﻨﺔ ﻓﺌﺘﻴﻥ ﻟﻤﺘﻐﻴﺭ ﻴﺤﺘﻭﻱ ﻋﻠﻰ 3 ﻓﺌﺎﺕ ﻓﺄﻜﺜﺭ ﻓﻨﻜﺘﺏ ﻓﻘﻁ ﺭﻤﺯ ﺍﻟﻌﻴﻨﺘﻴﻥ ﺍﻟﺘﻲ ﻨﺭﻴﺩ ﺍﻟﻤﻘﺎﺭﻨﺔ ﺒﻴﻥ ﻤﺘﻭﺴﻁﺎﺘﻬﻡ 6 95
60.
9. ﻭﻤﻥ ﺜﻡ
ﻨﻀﻐﻁ ﻋﻠﻰ .Okﻟﺘﻅﻬﺭ ﻨﺘﺎﺌﺞ ﺍﻻﺨﺘﺒﺎﺭ. ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ Tﻟﻠﻌﻴﻨﺎﺕ ﺍﻟﻤﺴﺘﻘﻠﺔ ﻴﺒﻴﻥ ﺍﻟﺸﻜل ﺃﻋﻼﻩ ﻨﺎﺘﺞ ﺘﻁﺒﻴﻕ ﺍﺨﺘﺒﺎﺭ Tﻟﻠﻌﻴﻨﺎﺕ ﺍﻟﻤﺴﺘﻘﻠﺔ، ﻭﻴﺘﻜﻭﻥ ﺍﻟﻨﺎﺘﺞ ﻤﻥ ﺠﺩﻭﻟﻴﻥ، ﺍﻷﻭل Group Statisticsﻭﻫﻭ ﺠﺩﻭل ﻴﺼﻑ ﺍﻟﻌﻴﻨﺎﺕ ﻤﻥ ﺤﻴﺙ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ ﻭﻭﺴﻁﻬﺎ ﺍﻟﺤﺴﺎﺒﻲ ﻭﺍﻨﺤﺭﺍﻓﻬﺎ ﺍﻟﻤﻌﻴﺎﺭﻱ، ﺃﻤﺎ ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ Independent Samples Testﻓﻴﺒﻴﻥ ﻨﺘﻴﺠﺔ ﺘﻁﺒﻴﻕ ﺍﺨﺘﺒﺎﺭ .(7) T ﻤﻥ ﺍﻟﺠﺩﻴﺭ ﺒﺎﻟﺫﻜﺭ ﺍﻥ ﺒﺭﻨﺎﻤﺞ SPSSﻴﺤﺴﺏ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺍﻟﻤﻘﺎﺭﻨﺔ ﺒﻴﻥ ﻤﺘﻭﺴﻁﺎﺕ ﻤﺠﺘﻤﻌﻴﻥ ﻤﻥ ﻋﻴﻨﺎﺕ ﻤﺴﺘﻘﻠﺔ ﺘﻠﻘﺎﺌﻴﺎ ﺒﻐﺽ ﺍﻟﻨﻅﺭ ﻋﻥ ﹰ 7 ﻜﻭﻥ ﺍﻟﻌﻴﻨﺎﺕ ﻜﺒﻴﺭﺓ ﺃﻭ ﺼﻐﻴﺭﺓ ﻭﻴﻜﻭﻥ ﺍﻟﺘﺒﺎﻴﻥ ﻏﻴﺭ ﻤﻌﺭﻭﻓﺎ ﻷﻥ ﺒﺭﻨﺎﻤﺞ SPSSﻴﻘﺩﺭﻩ ﺒﺄﺴﻠﻭﺏ ﺍﻟﻨﻘﻁﺔ، ﻓﻔﻲ ﺤﺎﻟﺔ ﺘﺴﺎﻭﻱ ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺎﺕ ﻨﺄﺨﺫ ﻨﺘﺎﺌﺞ ﺍﻟﺴﻁﺭ ﺍﻷﻭل ﻭﻓﻲ ﺤﺎﻟﺔ ﻋﺩﻡ ﺘﺴﺎﻭﻱ ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺘﻴﻥ ﻨﺄﺨﺫ ﺍﻟﺴﻁﺭ ﺍﻟﺜﺎﻨﻲ ﻤﻥ ﺠﺩﻭل ﺍﻟﻨﺘﺎﺌﺞ. 06
61.
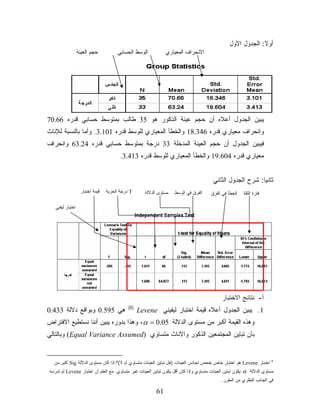
ﺃﻭﻻ: ﺍﻟﺠﺩﻭل ﺍﻷﻭل
ﹰ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ ﺍﻻﻨﺤﺭﺍﻑ ﺍﻟﻤﻌﻴﺎﺭﻱ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺃﻥ ﺤﺠﻡ ﻋﻴﻨﺔ ﺍﻟﺫﻜﻭﺭ ﻫﻭ 53 ﻁﺎﻟﺏ ﺒﻤﺘﻭﺴﻁ ﺤﺴﺎﺒﻲ ﻗﺩﺭﻩ 66.07 ﻭﺍﻨﺤﺭﺍﻑ ﻤﻌﻴﺎﺭﻱ ﻗﺩﺭﻩ 643.81 ﻭﺍﻟﺨﻁﺄ ﺍﻟﻤﻌﻴﺎﺭﻱ ﻟﻠﻭﺴﻁ ﻗﺩﺭﻩ 101.3. ﻭﺃﻤﺎ ﺒﺎﻟﻨﺴﺒﺔ ﻟﻺﻨﺎﺙ ﻓﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻥ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ ﺍﻟﻤﺩﺨﻠﺔ 33 ﺩﺭﺠﺔ ﺒﻤﺘﻭﺴﻁ ﺤﺴﺎﺒﻲ ﻗﺩﺭﻩ 42.36 ﻭﺍﻨﺤﺭﺍﻑ ﻤﻌﻴﺎﺭﻱ ﻗﺩﺭﻩ 406.91 ﻭﺍﻟﺨﻁﺄ ﺍﻟﻤﻌﻴﺎﺭﻱ ﻟﻠﻭﺴﻁ ﻗﺩﺭﻩ 314.3. ﺜﺎﻨﻴﺎ: ﺸﺭﺡ ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ ﹰ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ Tﺩﺭﺠﺔ ﺍﻟﺤﺭﻴﺔ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ﺍﻟﻔﺭﻕ ﻓﻲ ﺍﻟﻭﺴﻁ ﺍﻟﺨﻁﺄ ﻓﻲ ﺍﻟﻔﺭﻕ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﺍﺨﺘﺒﺎﺭ ﻟﻴﻔﻨﻲ ﺃ- ﻨﺘﺎﺌﺞ ﺍﻻﺨﺘﺒﺎﺭ )8( ﻫﻲ 595.0 ﻭﺒﻭﺍﻗﻊ ﺩﻻﻟﺔ 334.0 1. ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻟﻴﻔﻴﻨﻲ Levene ﻭﻫﺫﻩ ﺍﻟﻘﻴﻤﺔ ﺃﻜﺒﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = ، αﻭﻫﺫﺍ ﺒﺩﻭﺭﻩ ﻴﺒﻴﻥ ﺃﻨﻨﺎ ﻨﺴﺘﻁﻴﻊ ﺍﻻﻓﺘﺭﺍﺽ ﺒﺄﻥ ﺘﺒﺎﻴﻥ ﺍﻟﻤﺠﺘﻤﻌﻴﻥ ﺍﻟﺫﻜﻭﺭ ﻭﺍﻻﻨﺎﺙ ﻤﺘﺴﺎﻭﻱ ) (Equal Variance Assumedﻭﺒﺎﻟﺘﺎﻟﻲ ﺍﺨﻨﺒﺎﺭ Leveneﻫﻭ ﺍﺨﺘﺒﺎﺭ ﺨﺎﺹ ﺒﻔﺤﺹ ﺘﺠﺎﻨﺱ ﺍﻟﻌﻴﻨﺎﺕ )ﻫل ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺎﺕ ﻤﺘﺴﺎﻭﻱ ﺃﻡ ﻻ(؟ ﺇﺫﺍ ﻜﺎﻥ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ Sigﺃﻜﺒﺭ ﻤﻥ 8 ﻴﻜﻭﻥ ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺎﺕ ﻤﺘﺴﺎﻭﻱ ﻭﺇﺫﺍ ﻜﺎﻥ ﺃﻗل ﻴﻜﻭﻥ ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺎﺕ ﻏﻴﺭ ﻤﺘﺴﺎﻭﻱ. ﻤﻊ ﺍﻟﻌﻠﻡ ﺃﻥ ﺍﺨﺘﺒﺎﺭ Leveneﻟﻡ ﻨﺩﺭﺴﻪ α ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ﻓﻲ ﺍﻟﺠﺎﻨﺏ ﺍﻟﻨﻅﺭﻱ ﻤﻥ ﺍﻟﻤﻘﺭﺭ. 16
62.
ﺴﻨﻌﺘﻤﺩ ﺍﻟﻨﺘﺎﺌﺞ ﺍﻟﻤﻭﺠﻭﺩﺓ
ﻓﻲ ﺍﻟﺴﻁﺭ ﺍﻷﻭل ﺍﻟﺫﻱ ﻓﻲ ﺒﺩﺍﻴﺘﻪ Equality of Variance )9( . Assumedﻤﻥ ﺍﻟﺠﺩﻭل 2. ﻴﺒﻴﻥ ﺍﻟﺠﺯﺀ ﺍﻟﺜﺎﻨﻲ ﻤﻥ ﺍﻟﺠﺩﻭل ﻨﺎﺘﺞ ﺘﻁﺒﻴﻕ ﺍﺨﺘﺒﺎﺭ (T-Test for Equality of T ) Meanﻭﺒﺎﻟﺘﺤﺩﻴﺩ ﺍﻟﻨﺘﺎﺌﺞ ﺍﻟﻤﻭﺠﻭﺩﺓ ﻓﻲ ﺍﻟﺴﻁﺭ ﺍﻷﻭل ﻤﻥ ﺍﻟﺠﺩﻭل ﻭﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ Tﻫﻲ ﻭﺃﻥ ﻭﺒﺩﺭﺠﺔ ﺤﺭﻴﺔ ﻤﻘﺩﺍﺭﻫﺎ 66 ﺃﻱ 66 = 2 − 33 + 53 = 2 − 2 d .f . = n1 + n 116.1 ﺍﻟﻔﺭﻕ ﺒﻴﻥ ﻤﺘﻭﺴﻁﻲ ﺍﻟﻌﻴﻨﺘﻴﻥ ﺍﻟﺫﻜﻭﺭ ﻭﺍﻻﻨﺎﺙ Mean Differenceﻫﻭ 514.7 ﻭﺃﻥ ﺍﻟﺨﻁﺄ ﺍﻟﻤﻌﻴﺎﺭﻱ ﻓﻲ ﻫﺫﺍ ﺍﻟﻔﺭﻕ ﻫﻭ 206.4 . ﺏ- ﻗﺒﻭل ﺃﻭ ﺭﻓﺽ ﻟﻠﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. ﻫﻨﺎﻙ ﻁﺭﻴﻘﺘﻴﻥ ﻟﺭﻓﺽ ﺃﻭ ﻋﺩﻡ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻫﻤﺎ: -2( Sig 1. ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ) : Sig (2- tailedﻨﻼﺤﻅ ﻤﻥ ﺍﻟﺠﺩﻭل ﺃﻥ ﺃﻥ ﻗﻴﻤﺔ 211.0=) tailedﻭﻫﻲ ﺃﻜﺒﺭ ﻤﻥ ﻗﻴﻤﺔ 50.0 = αﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. 2. ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻟﻠﻔﺭﻕ ﺒﻴﻥ ﻭﺴﻁ ﺍﻟﻌﻴﻨﺘﻴﻥ )(Confidence Interval of the Difference ﻭﺘﺘﻜﻭﻥ ﺃﻱ ﻓﺘﺭﺓ ﺜﻘﺔ ﻤﻥ ﺭﻗﻤﻴﻥ ﻫﻤﺎ ﺍﻟﺤﺩ ﺍﻻﺩﻨﻰ Lowerﻭﺍﻟﺤﺩ ﺍﻻﻋﻠﻰ Upperﻭﻤﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﻓﺈﻥ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻟﻠﻔﺭﻕ ﺒﻴﻥ ﻭﺴﻁﻴﻥ ﺍﻟﻌﻴﻨﺘﻴﻥ ﻫﻲ )306.61,477.1− ( ، ﻭﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺇﺫﺍ ﻜﺎﻥ ﺍﻟﺼﻔﺭ ﻤﻭﺠﻭﺩ ﺩﺍﺨل ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ، ﻭﻜﻤﺎ ﻓﻲ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﻓﺎﻟﺼﻔﺭ ﻤﻭﺠﻭﺩ ﺒﻔﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻭﺒﺎﻟﺘﺎﻟﻲ ﻻ ﻨﺴﺘﻁﻴﻊ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. ﻭﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻓﻲ ﺤﺎﻟﺔ ﻋﺩﻡ ﻭﺠﻭﺩ ﺍﻟﺼﻔﺭ ﺩﺍﺨل ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ. ﻭﻨﺴﺘﻁﻴﻊ ﺍﻻﺴﺘﻨﺘﺎﺝ ﻤﻥ ﺍﻟﻤﺜﺎل ﺍﻟﺴﺎﺒﻕ ﺃﻥ ﺠﻨﺱ ﺍﻟﻁﺎﻟﺏ ﻻ ﻴﺅﺜﺭ ﻋﻠﻰ ﺩﺭﺠﺎﺘﻪ. ﻤﻥ ﺍﻟﻤﻌﺭﻭﻑ ﺃﻥ ﻤﻥ ﺃﻫﻡ ﺸﺭﻭﻁ ﺘﻁﺒﻴﻕ ﺍﺨﺘﺒﺎﺭ Tﻫﻭ ﺃﻥ ﻴﻜﻭﻥ ﺘﻭﺯﻴﻊ ﺍﻟﻤﺠﺘﻤﻌﻴﻥ ﺍﻟﻤﺴﺘﻘﻠﻴﻥ ﻁﺒﻴﻌﻲ ﻭﺃﻥ ﻴﻜﻭﻥ ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺘﻴﻥ ﻤﺘﺴﺎﻭﻱ 9 ﺍﺤﺼﺎﺌﻴﹰ، ﻭﺴﻨﺘﻌﺭﺽ ﻻﺤﻘﺎ ﻻﺨﺘﺒﺎﺭ ﻤﻘﺎﺭﻨﺔ ﺘﺒﺎﻴﻥ ﻤﺠﺘﻤﻌﻴﻥ ﺘﻔﺼﻴﻠﻴﺎ. ﹰ ﹰ ﺎ 26
63.
2.ﻓﺘﺭﺍﺕ ﺍﻟﺜﻘﺔ ﻭﺍﺨﺘﺒﺎﺭ
ﺍﻟﻔﺭﻭﻕ ﺒﻴﻥ ﻤﺘﻭﺴﻁﻲ ﻤﺠﺘﻤﻌﻴﻥ ﻤﺭﺘﺒﻁﻴﻥ: ﻤﺜﺎل 2: ﺇﺫﺍ ﻜﺎﻨﺕ ﺩﺭﺠﺎﺕ 02 ﻁﺎﻟﺏ ﻓﻲ ﻤﻘﺭﺭﻱ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻭﺍﻻﻨﺠﻠﻴﺯﻴﺔ ﻜﻤﺎ ﻓﻲ ﺍﻟﺠﺩﻭل ﺍﻟﺘﺎﻟﻲ: 1 ﺭﻗﻡ ﺍﻟﻁﺎﻟﺏ 2 3 4 5 6 7 8 9 01 ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ 58 08 05 58 04 08 09 08 06 06 ﺍﻟﻠﻐﺔ ﺍﻻﻨﺠﻠﻴﺯﻴﺔ 08 05 05 56 05 09 59 48 04 03 ﺭﻗﻡ ﺍﻟﻁﺎﻟﺏ 11 21 31 41 51 61 71 81 91 02 ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ 78 08 58 09 57 07 06 55 08 58 ﺍﻟﻠﻐﺔ ﺍﻻﻨﺠﻠﻴﺯﻴﺔ 08 57 56 07 57 06 04 07 09 57 ﻭﺍﻟﻤﻁﻠﻭﺏ ﺍﻴﺠﺎﺩ ﻓﺘﺭﺓ ﺜﻘﺔ ﻟﻠﻔﺭﻕ ﺒﻴﻥ ﻭﺴﻁﻴﻥ ﺍﻟﻤﻘﺭﺭﻴﻥ ﻭﻤﻥ ﺜﻡ ﺍﺠﺭﺍﺀ ﺍﺨﺘﺒﺎﺭ ﻤﺎ ﺇﺫﺍ ﻜﺎﻥ ﻫﻨﺎﻙ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﺒﻴﻥ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﻤﻘﺭﺭﻴﻥ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 01.0 = α؟ ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻻﻴﻭﺠﺩ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﻤﻘﺭﺭﻴﻥ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ : ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﻤﻘﺭﺭﻴﻥ. 1. ﻨﺩﺨل ﺒﻴﺎﻨﺎﺕ ﺩﺭﺠﺎﺕ ﻜل ﻤﻘﺭﺭ ﻓﻲ ﻤﺘﻐﻴﺭ )ﻋﻤﻭﺩ( ﻜل ﻋﻠﻰ ﺤﺩﺓ، ﻨﺴﻤﻲ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻻﻭل )ﺍﻟﻌﺭﺒﻲ( ﻭﺍﻟﺜﺎﻨﻲ )ﺍﻻﻨﺠﻠﻴﺯﻱ( ﻟﻴﺩﻻﻥ ﻋﻠﻰ ﺩﺭﺠﺎﺕ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻭﺍﻻﻨﺠﻠﻴﺯﻴﺔ ﻋﻠﻰ ﺍﻟﺘﻭﺍﻟﻲ 36
64.
2. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﻤﻘﺎﺭﻨﺔ ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ ) (Compare meanﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﺨﺘﺒﺎﺭ Tﻟﻠﻌﻴﻨﺎﺕ ﺍﻟﻤﺭﺘﺒﻁﺔ ).(Paired-Sample T-test 46
65.
3. ﻓﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ: 4. ﻨﺨﺘﺎﺭ ﻤﺘﻐﻴﺭﻴﻥ )ﺍﻟﻌﺭﺒﻲ( ﻭ)ﺍﻻﻨﺠﻠﻴﺯﻱ( ﻤﻌﺎ ﺒﺎﻟﻤﺎﻭﺱ ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ ﺍﻟﺴﻬﻡ ﻟﻼﻨﺘﻘﺎل ﹰ ﺇﻟﻰ ﺨﺎﻨﺔ . Paired Variablesﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 1 56
66.
5. ﺒﺎﻟﻀﻐﻁ ﻋﻠﻰ
Optionﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ ﺍﻟﺫﻱ ﻨﻜﺘﺏ ﻓﻴﻪ ﻤﻘﺩﺍﺭ ﻤﺴﺘﻭﻯ ﺍﻟﺜﻘﺔ )ﺘﺤﺩﻴﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ( ﻭﻫﻭ 9.0 = 1.0 − 1 2 6. ﺒﺎﻟﻀﻐﻁ ﻋﻠﻰ .Continueﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺴﺎﺒﻕ ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ Okﻤﺭﺓ ﺃﺨﺭﻯ ﻟﻠﺤﺼﻭل ﻋﻠﻰ ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲ. ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ Tﻟﻠﻌﻴﻨﺎﺕ ﺍﻟﻤﺭﺘﺒﻁﺔ ﻴﺘﻜﻭﻥ ﻨﺎﺘﺞ ﺍﺨﺘﺒﺎﺭ Tﻟﻤﻘﺎﺭﻨﺔ ﻤﺘﻭﺴﻁﺎﺕ ﻋﻴﻨﺘﻴﻥ ﻤﺭﺘﺒﻁﻴﻥ ﻤﻥ 3 ﺠﺩﺍﻭل، ﺍﻻﻭل ﻴﺼﻑ ﺍﺤﺼﺎﺀﺍﺕ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ ) (Paired Samples Statisticsﻭﺍﻟﺜﺎﻨﻲ ﻴﺤﺴﺏ ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﻭﻴﺼﻑ ﺍﻟﻌﻼﻗﺔ ﺍﻟﺨﻁﻴﺔ ﺒﻴﻥ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ ) (Paired Sample Correlationﻭﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻟﺙ ﻫﻭ ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ T ﻟﻠﻌﻴﻨﺎﺕ ﺍﻟﻤﺭﺘﺒﻁﺔ ).(Paired Samples Test 66
67.
ﺸﺭﺡ ﺍﻟﺠﺩﻭل ﺍﻷﻭل
ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ ﺍﻻﻨﺤﺭﺍﻑ ﺍﻟﻤﻌﻴﺎﺭﻱ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻥ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ ﺍﻟﻤﺩﺨﻠﺔ ﻓﻲ ﻜل ﻤﺘﻐﻴﺭ )ﺍﻟﻌﺭﺒﻲ ﻭﺍﻻﻨﺠﻠﻴﺯﻱ( ﻫﻭ 02، ﻭﺃﻥ ﻤﺘﻭﺴﻁ ﺩﺭﺠﺎﺕ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ 58.37 ﺒﺎﻨﺤﺭﺍﻑ ﻤﻌﻴﺎﺭﻱ ﻗﺩﺭﻩ 685.41 ﻭﺨﻁﺄ ﻤﻌﻴﺎﺭﻱ ﻓﻲ ﺍﻟﻭﺴﻁ ﺒﺎﻨﺤﺭﺍﻑ ﻤﻌﻴﺎﺭﻱ ﻗﺩﺭﻩ ﻤﻘﺩﺍﺭﻩ 262.3، ﺃﻤﺎ ﺍﻟﻠﻐﺔ ﺍﻻﻨﺠﻠﻴﺯﻴﺔ ﻓﻤﺘﻭﺴﻁ ﺍﻟﺩﺭﺠﺎﺕ 07.66 493.81 ﻭﺨﻁﺄ ﻤﻌﻴﺎﺭﻱ ﻓﻲ ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ ﻫﻭ 311.4. ﺸﺭﺡ ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ ﻴﺤﺴﺏ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﺍﻟﺨﻁﻲ ﺒﻴﺭﺴﻭﻥ ﻭﺍﻟﺫﻱ ﻗﻴﻤﺘﻪ 76.0 ﻭﻫﺫﻩ ﺍﻟﻌﻼﻗﺔ ﺍﻟﺨﻁﻴﺔ ﺩﺍﻟﺔ ﺍﺤﺼﺎﺌﻴﺎ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 100.0 ﻭﺴﻨﻘﻭﻡ ﺒﺸﺭﺡ ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﺘﻔﺼﻴﻠﻴﺎ ﻓﻲ ﺍﻟﻭﺤﺩﺓ ﹰ ﹰ ﺍﻟﺜﺎﻟﺜﺔ. 76
68.
ﺸﺭﺡ ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻟﺙ
ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻤﺘﻭﺴﻁ ﺍﻟﻔﺭﻕ ﺍﻻﻨﺤﺭﺍﻑ ﺍﻟﻤﻌﻴﺎﺭﻱ ﻟﻠﻔﺭﻕ Tﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ Paired Samples Test Paired Differences )(2-tailed 90%Confidenc Deviation .Sig Mean e Interval of Error .Std .Std t df the Difference Mean Lower Upper ﺍﻻﻨﺠﻠﻴﺯﻱ ﺍﻟﻌﺭﺒﻲ - 1 Pair 051.7 684.31 690.3 076.0 36.31 91 230. ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ﺩﺭﺠﺔ ﺍﻟﺤﺭﻴﺔ ﺃ- ﻨﺘﺎﺌﺞ ﺍﻟﺠﺩﻭل: ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺃﻥ ﻤﺘﻭﺴﻁ ﺍﻟﻔﺭﻕ ﺒﻴﻥ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ )ﺍﻟﻌﺭﺒﻲ –ﺍﻻﻨﺠﻠﻴﺯﻱ( ﻓﻲ ﺍﻟﻤﻘﺭﺭﻴﻥ ﻫﻭ 051.7 ﺒﺎﻨﺤﺭﺍﻑ ﻤﻌﻴﺎﺭﻱ ﻗﺩﺭﻩ 684.31 ﻭﺒﺨﻁﺄ ﻤﻌﻴﺎﺭﻱ ﻓﻲ ﺍﻟﻭﺴﻁ 690.3 ﻭﺃﻥ ﺩﺭﺠﺔ ﺍﻟﺤﺭﻴﺔ ﻫﻲ 91 = 1 − 02 = 1 − d . f . = nﻭﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ Tﻟﻠﻌﻴﻨﺎﺕ ﺍﻟﻤﺭﺘﺒﻁﺔ ﻫﻲ 903.2. ﺏ- ﻗﺒﻭل ﻭﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻫﻨﺎﻙ ﻁﺭﻴﻘﺘﻴﻥ ﻟﻠﻘﺒﻭل ﺃﻭ ﻟﻠﺭﻓﺽ ﻫﻤﺎ: 1. ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ) : Sig. (2- tailedﻤﻥ ﺍﻟﺠﺩﻭل ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ 230.0 =) Sig. (2- tailedﺃﻗل ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ )01(. (Confidence Interval of the 2. ﺒﺎﺴﺘﺨﺩﺍﻡ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻟﻠﻔﺭﻕ ﺒﻴﻥ ﺍﻟﻭﺴﻁﻴﻥ ) Differenceﺃﻭ ﻤﺎ ﺘﺴﻤﻰ ﺒﻔﺘﺭﺓ ﺜﻘﺔ ﺍﻻﺨﺘﺒﺎﺭ. ﻜﻤﺎ ﻓﻲ ﺍﻻﺨﺘﺒﺎﺭ ﺍﻟﺴﺎﺒﻕ ﻻﺤﻅ ﺃﻥ ﺍﻟﺼﻔﺭ ﻏﻴﺭ ﻤﻭﺠﻭﺩ ﻓﻲ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ )36.31,76.0 ( ﻭﻋﻠﻴﻪ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ، ﺃﻤﺎ ﺇﺫﺍ ﻜﺎﻥ ﺍﻟﺼﻔﺭ ﻤﻭﺠﻭﺩ ﻓﻲ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻓﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. ﺇﺫﺍ ﻜﺎﻨﺕ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ 2 H 0 : µ1 > µﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = . α 01 86
69.
ﻭﻨﺴﺘﻁﻴﻊ ﺍﻻﺴﺘﻨﺘﺎﺝ ﻤﻥ
ﺃﻥ ﻫﻨﺎﻙ ﻓﺭﻭﻕ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭﻱ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻭﺍﻻﻨﺠﻠﻴﺯﻴﺔ. 3.ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ ﻭﻓﺘﺭﺍﺕ ﺍﻟﺜﻘﺔ ﺤﻭل ﺍﻟﻨﺴﺒﺔ ﺒﻴﻥ ﺘﺒﺎﻴﻥ ﻤﺠﺘﻤﻌﻴﻥ. ﻤﺜﺎل 3: ﻓﻲ ﺩﺭﺍﺴﺔ ﻷﻋﻤﺎﺭ ﺍﻟﻤﺭﻀﻰ ﺍﻟﺫﻴﻥ ﻴﻌﺎﻨﻭﻥ ﻤﻥ ﺍﻟﺠﻠﻁﺔ ﺍﻟﺩﻤﻭﻴﺔ ﺴﺤﺒﺕ ﻋﻴﻨﺔ ﻤﻥ ﺍﻟﻤﺭﻀﻰ ﺍﻟﺫﻜﻭﺭ ﻭﺍﻻﻨﺎﺙ ﻭﻜﺎﻨﺕ ﻜﻤﺎ ﻴﻠﻲ: ﺍﻹﻨﺎﺙ 05 55 25 56 53 04 55 06 07 86 27 57 84 25 06 07 ﺍﻟﺫﻜﻭﺭ 04 54 04 55 24 65 85 06 06 26 53 04 05 55 ﺃﻭﺠﺩ ﻓﺘﺭﺓ ﺜﻘﺔ ﺒﻤﻘﺩﺍﺭ 09% ﻟﻠﻨﺴﺒﺔ ﺒﻴﻥ ﺘﺒﺎﻴﻥ ﺍﻟﺫﻜﻭﺭ ﻭﺍﻻﻨﺎﺙ ﻭﺒﻴﻥ ﻫل ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺘﺘﻴﻥ ﻤﺨﺘﻠﻔﻴﻥ ﺃﻡ ﻻ. ﺍﻟﺤل: ﺃﻭﻻ: ﻨﺠﺩ ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺘﻴﻥ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺃﻤﺭ ﺍﻟﺘﻜﺭﺍﺭﺍﺕ .Frequency ﹰ 1. ﻨﺩﺨل ﺃﻋﻤﺎﺭ ﻋﻴﻨﺔ ﺍﻟﺫﻜﻭﺭ ﻓﻲ ﻤﺘﻐﻴﺭ )ﺍﻟﺫﻜﻭﺭ( ﻭﺃﻋﻤﺎﺭ ﻋﻴﻨﺔ ﺍﻻﻨﺎﺙ ﻓﻲ ﻤﺘﻐﻴﺭ )ﺍﻻﻨﺎﺙ( ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 96
70.
2. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ )ﺍﻻﺤﺼﺎﺀﺍﺕ ﺍﻟﻭﺼﻔﻴﺔ( Descriptive Statisticsﻭﻤﻥ ﺨﻼل ﺃﻤﺭ ﺍﻟﺘﻜﺭﺍﺭﺍﺕ Frequenciesﻨﺤﺴﺏ ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺘﻴﻥ ﻜﻤﺎ ﻴﻠﻲ: 1 3. ﺒﺎﻟﻀﻐﻁ ﻋﻠﻰ Statisticsﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ ﻭﻨﺨﺘﺎﺭ ﻤﻨﻪ ﺤﺴﺏ ﺍﻟﺘﺒﺎﻴﻥ Variance 3 4. ﺒﺎﻟﻀﻐﻁ ﻋﻠﻰ Continueﻭﻤﻥ ﺜﻡ Okﻴﻅﻬﺭ ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲ 2 07
71.
5. ﻤﻥ ﺍﻟﻨﺎﺘﺞ
ﺃﻋﻼﻩ ﻴﺘﺒﻴﻥ ﺃﻥ ﺤﺠﻡ ﻋﻴﻨﺔ ﺍﻹﻨﺎﺙ ﻫﻭ 61 ﺒﺘﻴﺎﻴﻥ 697.531 ﺃﻤﺎ ﺍﻟﺫﻜﻭﺭ ﻓﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ 41 ﻭﻗﻴﻤﺔ ﺍﻟﺘﺒﺎﻴﻥ 902.58. 6. ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻭﻴل Transformﻨﺨﺘﺎﺭ ﺍﻤﺭ ﺍﻟﺤﺴﺎﺏ Computeﻟﺤﺴﺎﺏ ﺍﻟﺤﺩ ﺍﻷﺩﻨﻰ Lowerﻭﺍﻟﺤﺩ ﺍﻷﺩﻨﻰ Upperﻜﻤﺎ ﻓﻲ ﺍﻟﺴﺎﺒﻕ ﺍﻟﺼﻴﻐﺔ ﺍﻟﻌﺎﻤﺔ ﻟﻠﺤﺩ ﺍﻷﺩﻨﻰ : ( ) )31,51,50.0 ( (11) (S12 /S2 )*IDF.F α 2 ,15,13 = (135.796/85.209 ) *IDF.F 2 7. ﺍﻟﺼﻴﻐﺔ ﺍﻟﻌﺎﻤﺔ ﻟﺤﺴﺎﺏ ﺍﻟﺤﺩ ﺍﻷﻋﻠﻰ ﻤﺭﺓ ﺍﺨﺭﻯ ﻨﺤﺴﺏ ﺍﻟﻤﺘﻐﻴﺭ : Upper 2 2 ( 2 ) )31,51,59.0 ( (S1 /S2 )*IDF.F 1 − α ,15,13 = (135.796/85.209 ) *IDF.F )2 IDF.F(P,df1,dfﻫﻲ ﺩﺍﻟﺔ ﻤﻭﺠﻭﺩﺓ ﺩﺍﺨل .Function 11 17
72.
8. ﻴﻅﻬﺭ ﺍﻟﻨﺎﺘﺞ
ﺍﻟﺘﺎﻟﻲ ﻓﻲ ﺼﻔﺤﺔ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻤﻥ ﺍﻟﻨﺎﺘﺞ ﻓﺈﻥ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ 09% ﻫﻲ ) 730.4 ,156.0 ( 27
73.
ﺃﻤﺎ ﻟﻺﺠﺎﺒﺔ ﻋﻠﻰ
ﺍﻟﻔﺭﻀﻴﺎﺕ: 21 σ : 0H 1= ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻨﺴﺒﺔ ﺘﺒﺎﻴﻥ ﺍﻟﻤﺠﺘﻤﻌﻴﻥ ﻭﺍﺤﺩ 2σ 2 2σ 1 ≠ 21 : H a ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ: ﻨﺴﺒﺔ ﺘﺒﺎﻴﻥ ﺍﻟﻤﺠﺘﻤﻌﻴﻥ ﻻ ﺘﺴﺎﻭﻱ ﻭﺍﺤﺩ 2σ ﺍﻟﻁﺭﻴﻘﺔ ﺍﻷﻭﻟﻰ: ﺒﺎﺴﺘﺨﺩﺍﻡ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﺍﻟﺴﺎﺒﻘﺔ ﻻﺤﻅ ﺃﻥ ﻨﺴﺒﺔ ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺘﻴﻥ ﻫﻲ ) 730.4 ,536.0 ( ∈ 1 ﻭﺒﺎﻟﺘﺎﻟﻲ ﻻ ﻨﺴﺘﻁﻴﻊ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺃﻤﺎ ﺇﺫﺍ ﻜﺎﻥ ﺍﻟﻭﺍﺤﺩ ﻏﻴﺭ ﻤﻭﺠﻭﺩ ﻓﻲ ﻓﺘﺭﺓ ﺍﻟﺜﻘﺔ ﻓﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. ﺍﻟﻁﺭﻴﻘﺔ ﺍﻟﺜﺎﻨﻴﺔ: ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻭﻴل Transformﻨﺨﺘﺎﺭ ﺍﻤﺭ ﺍﻟﺤﺴﺎﺏ Computeﻟﺤﺴﺎﺏ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ Sig ﺍﻟﺼﻴﻐﺔ ﺍﻟﻌﺎﻤﺔ ﻟﺤﺴﺎﺏ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ Sigﺃﻨﻅﺭ ﺍﻟﺘﺎﻟﻲ )31,51,902.58 / 697.531(SIG.F(S1 / S2 ,n-1,m-1)=SIG.F 2 2 ﺤﻴﺙ mﻫﻲ ﺩﺭﺠﺔ ﺤﺭﻴﺔ ﺍﻟﺒﺴﻁ ﻭ nﻫﻲ ﺩﺭﺠﺔ ﺤﺭﻴﺔ ﺍﻟﻤﻘﺎﻡ ﻴﻅﻬﺭ ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲ ﻓﻲ ﺼﻔﺤﺔ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﻤﺘﻐﻴﺭ Sig 37
74.
ﻴﺘﺒﻴﻥ ﺃﻥ ﻤﺴﺘﻭﻯ
ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ 202.0 ﻭﻫﻲ ﺃﻜﺒﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 01.0 = αﻭﺒﺎﻟﺘﺎﻟﻲ ﺘﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. 47
75.
ﺍﻟﻭﺤﺩﺓ ﺍﻟﺜﺎﻟﺜﺔ ﺍﻻﻨﺤﺩﺍﺭ ﻭﺍﻻﺭﺘﺒﺎﻁ
57
76.
ﺍﻟﻭﺤﺩﺓ ﺍﻟﺜﺎﻟﺜﺔ:ﺍﻻﻨﺤﺩﺍﺭ ﻭﺍﻻﺭﺘﺒﺎﻁ
1. ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻟﻤﺘﻌﻠﻘﺔ ﺒﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻭﻤﻘﻁﻌﻪ ﻭﻫﻨﺎ ﻨﺭﻴﺩ ﺍﻻﺠﺎﺒﺔ ﻋﻠﻰ ﺍﻟﺴﺅﺍل ﺍﻻﺴﺎﺴﻲ "ﻫل ﺘﻭﺠﺩ ﻋﻼﻗﺔ ﺨﻁﻴﺔ ﺒﻴﻥ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺘﺎﺒﻊ Yﻭﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻘل ." Xﻓﻤﻥ ﺍﻟﻤﻌﺭﻭﻑ ﺃﻥ ﺍﻟﻌﻼﻗﺔ ﺍﻟﺨﻁﻴﺔ ﺇﺫﺍ ﻭﺠﺩﺕ ﺴﺘﻜﻭﻥ ﻋﻠﻰ ﺍﻟﺸﻜل Y = B 0 + B 1X ﺤﻴﺙ 0 Bﻫﻭ ﻤﻘﻁﻊ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭﻤﻥ ﻤﺤﻭﺭ yﻭ 1 Bﻫﻭ ﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ. ﻭﻟﻭ ﻜﺎﻨﺕ ﺍﻟﻌﻼﻗﺔ ﺨﻁﻴﺔ ﻭﺘﻡ ﺭﺴﻡ ﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ Xﻭ Yﻓﻲ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺩﻴﻜﺎﺭﺘﻲ ﻓﺴﻴﻜﻭﻥ ﺭﺴﻡ ﻫﺫﻩ ﺍﻟﻌﻼﻗﺔ ﻋﻠﻰ ﺸﻜل ﺨﻁ ﻤﺴﺘﻘﻴﻡ ﻴﺼل ﺒﻴﻥ ﻤﻌﻅﻡ ﺍﻟﻨﻘﺎﻁ )ﺃﻭ ﻴﻜﻭﻥ ﻤﺠﻤﻭﻉ ﻤﺭﺒﻊ ﺍﻟﻤﺴﺎﻓﺎﺕ ﺒﻴﻨﻪ ﻭﺒﻴﻥ ﺍﻟﻨﻘﺎﻁ ﻫﻲ ﺃﻗل ﻤﺎ ﻴﻤﻜﻥ( ﻜﻤﺎ ﺩﺭﺴﺕ ﺫﻟﻙ ﺴﺎﺒﻘﺎ ﻓﻲ ﻁﺭﻴﻘﺔ ﺍﻟﻤﺭﺒﻌﺎﺕ ﺍﻟﺼﻐﺭﻯ ﻓﻲ ﻤﻘﺭﺭ ﻤﺒﺎﺩﺉ ﺍﻻﺤﺼﺎﺀ. ﹰ ﺍﻟﻘﻴﻡ ﺍﻟﺤﻘﻴﻘﺔ )ﺍﻟﻤﺸﺎﻫﺩﺍﺕ( ﺍﻟﺨﻁﺄ ﻓﻲ ﺍﻟﺘﻘﺩﻴﺭ ﺍﻟﻘﻴﻤﺔ ﺍﻟﺘﻘﺩﻴﺭﻴﺔ ﺨﻁ ﻤﻌﺎﺩﻟﺔ ﺍﻻﻨﺤﺩﺍﺭ ﻭﻴﻨﺠﻡ ﻋﻥ ﺘﻘﺭﻴﺏ ﺍﻟﻌﻼﻗﺔ ﺒﻴﻥ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ Xﻭ Yﺒﻌﻼﻗﺔ ﺨﻁ ﻤﺴﺘﻘﻴﻡ )ﺨﻁ ﺍﻨﺤﺩﺍﺭ( ﻨﻭﻋﻴﻥ ﻤﻥ ﺍﻟﻘﻴﻡ ﺍﻟﺤﻘﻴﻘﻴﺔ )ﺍﻟﻤﺸﺎﻫﺩﺍﺕ( ﻭﺍﻟﻘﻴﻡ ﺍﻟﺘﻘﺩﻴﺭﻴﺔ ﺍﻟﺘﻲ ﻨﻘﺩﺭﻫﺎ ﺒﺎﺴﺘﺨﺩﺍﻡ ﻤﻌﺎﺩﻟﺔ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻭﺍﻟﻔﺭﻕ ﺒﻴﻥ ﺍﻟﻘﻴﻤﺔ ﺍﻟﺤﻘﻴﻘﻴﺔ ﻭﺍﻟﻘﻴﻤﺔ ﺍﻟﺘﻘﺩﻴﺭﻴﺔ ﻫﻭ ﻤﺎ ﻴﺴﻤﻰ ﺒﺎﻟﺨﻁﺄ ﻓﻲ ﺍﻟﺘﻘﺩﻴﺭ ﻭﺍﻟﻤﻭﻀﺢ ﻓﻲ ﺍﻟﺸﻜل ﺃﻋﻼﻩ. 67
77.
• ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ
ﺍﻟﻤﺘﻌﻠﻘﺔ ﺒﻤﻴل ﻭﻤﻘﻁﻊ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ. ﻤﺜﺎل 1: ﺇﺫﺍ ﻜﺎﻥ ﺩﺭﺠﺎﺕ 21 ﻁﺎﻟﺏ ﻓﻲ ﻤﻘﺭﺭﻱ ﺍﻟﺤﺎﺴﻭﺏ ﻭﺍﻟﺭﻴﺎﻀﻴﺎﺕ ﻜﺎﻨﺕ ﻜﻤﺎ ﻓﻲ ﺍﻟﺠﺩﻭل ﺍﻟﺘﺎﻟﻲ : ﺍﻟﺭﻴﺎﻀﻴﺎﺕ ﺍﻟﺤﺎﺴﻭﺏ ﺭﻗﻡ ﺍﻟﻁﺎﻟﺏ 15 47 1. 86 07 2. 27 88 3. 79 39 4. 55 76 5. 37 37 6. 59 99 7. 47 37 8. 02 33 9. 19 19 01. 47 08 11. 08 68 21. ﺒﺎﻋﺘﺒﺎﺭ ﺃﻥ ﺩﺭﺠﺔ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﺭﻴﺎﻀﻴﺎﺕ ﻫﻲ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻘل ﻭﺩﺭﺠﺔ ﺍﻟﺤﺎﺴﻭﺏ ﻫﻲ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺘﺎﺒﻊ، ﻓﺎﻭﺠﺩ ﺍﻟﻌﻼﻗﺔ ﺍﻟﺨﻁﻴﺔ ﺒﻴﻥ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﻤﻘﺭﺭﻴﻥ )ﻤﻌﺎﺩﻟﺔ ﺍﻻﻨﺤﺩﺍﺭ( ﻭﻤﻥ ﺜﻡ ﺒﻴﻥ ﻫل ﻫﺫﻩ ﺍﻟﻌﻼﻗﺔ ﺩﺍﻟﺔ ﺍﺤﺼﺎﺌﻴﺎ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = αﻭﻤﺩﻯ ﺍﻟﺩﻗﺔ ﻓﻲ ﹰ ﺍﻟﺘﻘﺩﻴﺭ ﺒﻨﺎﺀ ﻋﻠﻰ ﻫﺫﻩ ﺍﻟﻌﻼﻗﺔ. ﺍﻟﺤل: ﺃﻭﻻ: ﺘﻨﻔﻴﺫ ﺍﻻﺨﺘﺒﺎﺭ ﹰ 1. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﺒﺤﻴﺙ ﻨﺩﺨل ﺩﺭﺠﺔ ﻤﻘﺭﺭ ﺍﻟﺭﻴﺎﻀﻴﺎﺕ ﻓﻲ ﻤﺘﻐﻴﺭ )ﺍﻟﺭﻴﺎﻀﻴﺎﺕ( ﻭﺒﻴﺎﻨﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﺤﺎﺴﻭﺏ ﻓﻲ ﻤﺘﻐﻴﺭ )ﺍﻟﺤﺎﺴﻭﺏ( ﻜﻤﺎ ﻓﻲ ﻴﻠﻲ: 77
78.
2. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ ﻟﻺﻨﺤﺩﺍﺭ Regressionﻭﻤﻥ ﺜﻡ ﻨﺨﺘﺎﺭ Linearﻟﺩﺭﺍﺴﺔ ﺍﻻﻨﺤﺩﺍﺭ ﺍﻟﺨﻁﻲ. ﻜﻤﺎ ﻴﻠﻲ: 87
79.
3. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 97
80.
4. ﺒﻤﺎ ﺃﻥ
ﻤﺘﻐﻴﺭ )ﺍﻟﺭﻴﺎﻀﻴﺎﺕ( ﻫﻭ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻘل ﻨﻨﻘﻠﻪ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺴﻬﻡ ﻟﺨﺎﻨﺔ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﻤﺴﺘﻘﻠﺔ Independentsﻭﻨﻨﻘل ﻤﺘﻐﻴﺭ )ﺍﻟﺤﺎﺴﻭﺏ( ﻟﺨﺎﻨﺔ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺘﺎﺒﻌﺔ Dependent . 08
81.
5. ﻨﻀﻐﻁ
Okﻟﻠﺤﺼﻭل ﻋﻠﻰ ﺍﻟﻨﺘﺎﺌﺞ. ﻨﺘﺎﺌﺞ ﺘﺤﻠﻴل ﺍﻻﻨﺤﺩﺍﺭ ﺍﻟﺨﻁﻲ 18
82.
ﺸﺭﺡ ﺍﻟﻨﺘﺎﺌﺞ
ﺍﻟﺠﺩﻭل ﺍﻻﻭل )ﺠﺩﻭل ﻨﻭﻉ ﺍﻟﻁﺭﻴﻘﺔ( ﻭﻫﻭ ﻴﺒﻴﻥ ﺃﻥ ﻁﺭﻴﻘﺔ ﺍﻟﻤﺭﺒﻌﺎﺕ ﺍﻟﺼﻐﺭﻯ ﻫﻲ ﺍﻟﻤﺘﺒﻌﺔ ﻓﻲ ﺘﺤﻠﻴل ﺍﻻﻨﺤﺩﺍﺭ ﺍﻟﺨﻁﻲ ﻭﺃﻥ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻘل ﻫﻭ ﺍﻟﺭﻴﺎﻀﻴﺎﺕ ﻭﺃﻥ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺘﺎﺒﻊ ﻫﻭ ﺍﻟﺤﺎﺴﻭﺏ . ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ )ﺠﺩﻭل ﺍﻻﺭﺘﺒﺎﻁ ﺍﻟﺨﻁﻲ( ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﻤﻌﺎﻤل ﺍﻟﺘﺤﺩﻴﺩ 28
83.
ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺍﻟﺴﺎﺒﻕ
ﻨﺘﻴﺠﺔ ﺤﺴﺎﺏ ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ Rﻭﻤﻌﺎﻤل ﺍﻟﺘﺤﺩﻴﺩ 2 ،(12) Rﻭﻜﺫﻟﻙ ﻴﺒﻴﻥ ﺃﻥ ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﺍﻟﺨﻁﻲ ﺒﻴﻥ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﺭﻴﺎﻀﻴﺎﺕ ﻭﺍﻟﺤﺎﺴﻭﺏ ﻫﻭ 539.0 ﻭﺃﻥ ﻤﺩﻯ ﺍﻟﺩﻗﺔ ﻓﻲ ﺘﻘﺩﻴﺭ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺘﺎﺒﻊ )ﺩﺭﺠﺔ ﺍﻟﺤﺎﺴﻭﺏ( ﻫﻭ 4.78%. ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻟﺙ: )ﺠﺩﻭل ﺘﺤﻠﻴل ﺘﺒﺎﻴﻥ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ( ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﻫﻭ ﺠﺩﻭل ﺘﺤﻠﻴل ﺘﺒﺎﻴﻥ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﺤﻴﺙ ﻴﺩﺭﺱ ﻤﺩﻯ ﻤﻼﺌﻤﺔ ﺨﻁﺔ ﺍﻻﻨﺤﺩﺍﺭ ﻟﻠﺒﻴﺎﻨﺎﺕ ﻭﻓﺭﻀﻴﺘﻪ ﺍﻟﺼﻔﺭﻴﺔ ﺍﻟﺘﻲ ﺘﻨﺹ ﻋﻠﻰ "ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻻ ﻴﻼﺌﻡ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﻌﻁﺎﺓ" ، ﻭﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺍﻟﺘﺎﻟﻲ ﺃﻥ: 1. ﻤﺠﻤﻭﻉ ﻤﺭﺒﻌﺎﺕ ﺍﻻﻨﺤﺩﺍﺭ ﻫﻭ 081.1682 ﻭﻤﺠﻤﻭﻉ ﻤﺭﺒﻌﺎﺕ ﺍﻟﺒﻭﺍﻗﻲ ﻫﻭ 070.114 ﻭﻤﺠﻤﻭﻉ ﺍﻟﻤﺭﺒﻌﺎﺕ ﺍﻟﻜﻠﻲ ﻫﻭ 52.2723. 2. ﺩﺭﺠﺔ ﺤﺭﻴﺔ ﺍﻻﻨﺤﺩﺍﺭ ﻫﻲ 1 ﻭﺩﺭﺠﺔ ﺤﺭﻴﺔ ﺍﻟﺒﻭﺍﻗﻲ ﻫﻲ 01. 3. ﻤﻌﺩل ﻤﺭﻋﺎﺕ ﺍﻻﻨﺤﺩﺍﺭ ﻫﻭ 81.1682 ﻭﻤﻌﺩل ﻤﺭﺒﻌﺎﺕ ﺍﻟﺒﻭﺍﻗﻲ ﻫﻭ 701.14. 4. ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﻟﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻫﻲ 306.96 . 5. ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ 000.0 ﺃﻗل ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 50.0 ﻓﻨﺭﻓﻀﻬﺎ، )31( . ﺒﺎﻟﺘﺎﻟﻲ ﻓﺈﻥ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻴﻼﺌﻡ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﺠﺩﻭل ﺍﻟﺭﺍﺒﻊ )ﺠﺩﻭل ﺍﻟﻤﻌﺎﻤﻼﺕ( ﻭﻫﺫﺍ ﺍﻟﺠﺩﻭل ﻴﺒﻴﻥ ﻋﺩﺓ ﻨﺘﺎﺌﺞ ﺃﻭﻟﻬﺎ ﻗﻴﻡ ﻤﻴل ﻭﻤﻘﻁﻊ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﺒﺎﻻﻀﺎﻓﺔ ﺃﻨﻪ ﻴﺠﻴﺏ ﻋﻠﻰ ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻟﻤﺘﻌﻠﻘﺔ ﺒﻤﻴل ﻭﻤﻘﻁﻊ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻤﻌﺎﻤل ﺍﻟﺘﺤﺩﻴﺩ ﻫﻭ ﻤﺭﺒﻊ ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﻭﻫﻭ ﻴﺒﻴﻥ ﻤﺩﻯ ﺩﻗﺔ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻓﻲ ﺘﻘﺩﻴﺭ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺘﺎﺒﻊ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻘل ﺃﻭ ﺒﺼﻴﻐﺔ 21 ﺃﺨﺭﻯ ﻤﺩﻯ ﻓﻌﺎﻟﻴﺔ ﺍﺴﺘﺨﺩﺍﻡ ﻤﻌﺎﺩﻟﺔ ﺍﻻﻨﺤﺩﺍﺭ ﻟﻠﺘﻨﺒﺅ ﻓﻲ ﻗﻴﻡ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺘﺎﺒﻊ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻻ ﻴﻼﺌﻡ ﺍﻟﺒﻴﺎﻨﺎﺕ. 31 38
84.
ﻤﻘﻁﻊ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ
ﻗﻴﻤﺔ ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﻟﻠﻤﻌﺎﻤﻼﺕ Tﻗﻴﻡ ﺍﺨﺘﺒﺎﺭ Tﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﺨﺘﺒﺎﺭ ﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ 1. ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﻨﺘﻴﺠﺔ ﺍﺠﺭﺍﺀ ﺍﺨﺘﺒﺎﺭ Tﻋﻠﻰ ﻓﺭﻀﻴﺎﺕ ﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻭﻤﻘﻁﻊ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ، ﻓﺎﻟﺴﻁﺭ ﺍﻷﻭل ﻤﻥ ﺍﻟﺠﺩﻭل ﻴﺒﻴﻥ ﻨﺘﻴﺠﺔ ﺘﻁﺒﻴﻕ ﺍﺨﺘﺒﺎﺭ Tﻋﻠﻰ ﻓﺭﻀﻴﺎﺕ ﻤﻘﻁﻊ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ، ﻭﺍﻟﺴﻁﺭ ﺍﻟﺜﺎﻨﻲ ﻤﻥ ﺍﻟﺠﺩﻭل ﺒﻴﺒﻴﻥ ﻨﺘﻴﺠﺔ ﺍﺨﺘﺒﺎﺭ Tﻋﻠﻰ ﻓﺭﻀﻴﺎﺕ ﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ. ﺤﻴﺙ ﺃﻥ ﻁﻭل ﻤﻘﻁﻊ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻫﻭ 387.32 ﻭﺃﻥ ﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻫﻭ 557.0 ﻭﺒﺎﻟﺘﺎﻟﻲ ﺘﻜﻭﻥ ﻤﻌﺎﺩﻟﺔ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻫﻲ Y = 23.783 + 0.755 Xﺤﻴﺙ Yﻫﻭ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺘﺎﺒﻊ )ﺍﻟﺤﺎﺴﻭﺏ( ﻭﺍﻟﻤﺴﺘﻘل Xﻭﻫﻭ )ﺍﻟﺭﻴﺎﻀﻴﺎﺕ(. 2. ﻓﺭﻀﻴﺎﺕ ﻤﻘﻁﻊ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ : ﻤﻘﻁﻊ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻤﺴﺎﻭﻱ ﻟﻠﺼﻔﺭ 0 H 0 = 0H 0 : B : ﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻤﺨﺘﻠﻑ ﻋﻥ ﺍﻟﺼﻔﺭ H a 0 ≠ 0H a : B ﻭﻫﻲ ﻫﻲ 565.3 ﻭﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ 500.0Tﻴﺘﺒﻴﻥ ﻤﻥ ﺍﻟﺠﺩﻭل ﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ 50.0 = αﺃﻗل ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺃﻱ ﺃﻗل ﻤﻥ ﻗﻴﻤﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻭﺘﻜﻭﻥ ﻗﻴﻤﺔ ﻤﻘﻁﻊ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ 387.32 ﻫﻲ ﺩﺍﻟﺔ ﺍﺤﺼﺎﺌﻴﺎ. ﹰ 3. ﺒﺎﻟﻨﺴﺒﺔ ﻟﻔﺭﻀﻴﺎﺕ ﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ 0 = 1 : H 0 : Bﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻤﺴﺎﻭﻱ ﻟﻠﺼﻔﺭ 0 H 0 ≠ 1 : H a : Bﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ ﻤﺨﺘﻠﻑ ﻋﻥ ﻟﻠﺼﻔﺭ H a ﻴﺘﺒﻴﻥ ﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ Tﻫﻲ 343.8 ﻭﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ 000.0 ﻭﻫﻲ ﺃﻗل ﻤﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = αﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻭﺘﻜﻭﻥ ﻗﻴﻤﺔ ﻤﻴل ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ 557.0 ﻫﻲ ﺩﺍﻟﺔ ﺍﺤﺼﺎﺌﻴﺎ. ﹰ 48
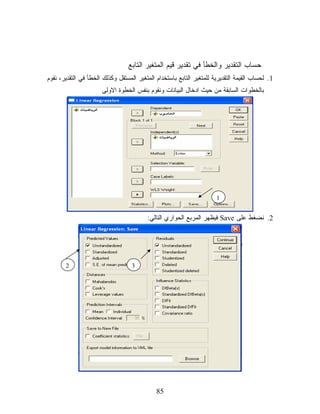
85.
ﺤﺴﺎﺏ ﺍﻟﺘﻘﺩﻴﺭ ﻭﺍﻟﺨﻁﺄ
ﻓﻲ ﺘﻘﺩﻴﺭ ﻗﻴﻡ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺘﺎﺒﻊ 1. ﻟﺤﺴﺎﺏ ﺍﻟﻘﻴﻤﺔ ﺍﻟﺘﻘﺩﻴﺭﻴﺔ ﻟﻠﻤﺘﻐﻴﺭ ﺍﻟﺘﺎﺒﻊ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻘل ﻭﻜﺫﻟﻙ ﺍﻟﺨﻁﺄ ﻓﻲ ﺍﻟﺘﻘﺩﻴﺭ، ﻨﻘﻭﻡ ﺒﺎﻟﺨﻁﻭﺍﺕ ﺍﻟﺴﺎﺒﻘﺔ ﻤﻥ ﺤﻴﺙ ﺍﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﻨﻘﻭﻡ ﺒﻨﻔﺱ ﺍﻟﺨﻁﻭﺓ ﺍﻻﻭﻟﻰ 1 2. ﻨﻀﻐﻁ ﻋﻠﻰ Saveﻓﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ: 2 3 58
86.
ﻨﻀﻊ ﻋﻼﻤﺔ ﻋﻠﻰ
ﺨﺎﻨﺎﺕ Un Standardizedﺘﺤﺕ ﺍﻟﺒﻭﺍﻗﻲ Residualsﻭﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻘل 3. Predicted Valuesﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺴﺎﺒﻕ ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ Continueﻟﻺﺴﺘﻤﺭﺍﺭ ﻭﺍﻟﻌﻭﺩﺓ ﻟﻠﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻻﺼﻠﻲ. ﺍﻟﻨﺘﺎﺌﺞ: ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ ﻴﺘﺒﻴﻥ ﺃﻥ ﺒﺭﻨﺎﻤﺞ SPSSﻗﺩ ﺍﻀﺎﻑ ﻋﻤﻭﺩﻴﻥ )ﻤﺘﻐﻴﺭﻴﻥ( ﻜﻤﺎ ﻫﻭ ﻤﺒﻴﻥ ﻓﻲ ﺍﻟﻠﻭﻥ ﺍﻟﻐﺎﻤﻕ ﻟﺼﻔﺤﺔ ﺍﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﻫﻤﺎ ﺍﻟﺘﻘﺩﻴﺭ 1_ Preﻭﺍﻟﺨﻁﺄ ﻓﻲ ﺍﻟﺘﻘﺩﻴﺭ 1_.Res ﻭﻨﺴﺘﻁﻴﻊ ﻗﺭﺍﺀﺓ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻜﺎﻟﺘﺎﻟﻲ: ﺍﻟﻁﺎﻟﺏ ﺍﻷﻭل ﺍﻟﺫﻱ ﺤﺼل ﻋﻠﻰ ﺩﺭﺠﺔ 15 ﻓﻲ ﺍﻟﺭﻴﺎﻀﻴﺎﺕ ﻭ47 ﻓﻲ ﺍﻟﺤﺎﺴﻭﺏ، ﻓﺒﺎﺴﺘﺨﺩﺍﻡ ﻤﻌﺎﺩﻟﺔ )41( ﻓﺈﻥ ﺍﻟﻌﻼﻤﺔ ﺍﻟﺘﻘﺩﻴﺭﻴﺔ ﻟﻪ ﻓﻲ ﺍﻟﺤﺎﺴﻭﺏ ﻫﻲ 22972.26 ﻭﻴﻜﻭﻥ ﺒﺫﻟﻙ ﺨﻁ ﺍﻻﻨﺤﺩﺍﺭ )ﺍﻟﺘﻘﺩﻴﺭﻴﺔ( ﺍﻟﺨﻁﺄ ﻓﻲ ﺍﻟﺘﻘﺩﻴﺭ 87027.11. ﻭﻫﻜﺫﺍ ﺒﺎﻟﻨﺴﺒﺔ ﻟﻠﻁﺎﻟﺏ ﺍﻟﺜﺎﻨﻲ ﻭﺍﻟﺜﺎﻟﺙ ... . Y = 23.785 + 0.755X 41 68
87.
2.ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻟﻤﺘﻌﻠﻘﺔ
ﺒﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ )ﺒﻴﺭﺴﻭﻥ(. ﻴﻌﻤل ﻤﻌﺎﻤل ﺍﺭﺘﺒﺎﻁ ﺒﻴﺭﺴﻭﻥ ﻋﻠﻰ ﻗﻴﺎﺱ ﻁﺒﻴﻌﺔ ﻭﻗﻭﺓ ﺍﻟﻌﻼﻗﺔ ﺍﻟﺨﻁﻴﺔ ﺒﻴﻥ ﻗﻴﻡ ﻤﺘﻐﻴﺭﻴﻥ ﻤﺜﺎل 2: ﻓﻲ ﺍﻟﻤﺜﺎل ﺍﻟﺴﺎﺒﻕ ﻨﺭﻴﺩ ﺘﻁﺒﻴﻕ ﺍﺨﺘﺒﺎﺭ ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﻟﺘﺤﺩﻴﺩ ﻁﺒﻴﻌﺔ ﺍﻟﻌﻼﻗﺔ ﺒﻴﻥ ﻤﺘﻐﻴﺭ ﺩﺭﺠﺎﺕ ﺍﻟﻁﺎﻟﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﺭﻴﺎﻀﻴﺎﺕ ﻭﺍﻟﺤﺎﺴﻭﺏ. ﺍﻟﺤل: ﺘﻜﻭﻥ ﺍﻟﻔﺭﻀﻴﺎﺕ ﻜﻤﺎ ﻴﻠﻲ: 0 : Hﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﻤﺴﺎﻭﻱ ﻟﻠﺼﻔﺭ ) 0 = 0( H 0 : ρ : H aﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﻏﻴﺭ ﺼﻔﺭﻱ ) 0 ≠ 0( H 0 : ρ 1. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻜﻤﺎ ﻓﻲ ﺍﻟﻤﺜﺎل ﺍﻟﺴﺎﺒﻕ 2. ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ ﻟﻺﺭﺘﺒﺎﻁ Correlationﻭﻤﻥ ﺜﻡ ﻨﺨﺘﺎﺭ Bivariateﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 78
88.
3. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ: 1 2 3 4. ﻨﺨﺘﺎﺭ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ )ﺍﻟﺭﻴﺎﻀﻴﺎﺕ ﻭﺍﻟﺤﺎﺴﻭﺏ( ﻭﻨﻨﻘﻠﻬﻡ ﻟﺨﺎﻨﺔ Variablesﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺴﻬﻡ، ﻭﻨﺨﺘﺎﺭ ﻁﺭﻴﻘﺔ ﺤﺴﺎﺏ ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ )ﻤﻌﺎﻤل ﺍﺭﺘﺒﺎﻁ ﺒﻴﺭﺴﻭﻥ( ﻭﺜﻡ ﻨﻀﻊ ﻋﻼﻤﺔ ﻋﻠﻰ ﺍﻻﺨﺘﻴﺎﺭ Flag Significant Correlationsﻟﻴﻌﻁﻴﻨﺎ ﺍﻟﻘﻴﻡ ﺍﻟﺘﻲ ﺘﻜﻭﻥ ﻋﻨﺩﻫﺎ ﺍﻟﻌﻼﻗﺔ ﺩﺍﻟﺔ 88
89.
ﻭﻫﻲ ﺍﺤﺩﻯ ﺍﻟﻘﻴﻡ
ﺍﻟﺘﺎﻟﻴﺔ )000.0 ,500.0 ,10.0 ,5.0 ,1.0( ﻭﻓﻲ ﺍﻟﻨﻬﺎﻴﺔ ﺘﻅﻬﺭ ﺍﻟﻨﺘﺎﺌﺞ ﺍﻟﺘﺎﻟﻴﺔ. ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺭﺘﺒﺎﻁ )ﻤﻌﺎﻤل ﺍﺭﺘﺒﺎﻁ ﺒﻴﺭﺴﻭﻥ( ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻓﻲ ﺤﺎﻟﺔ ﻋﺩﻡ ﺍﻟﺘﺴﺎﻭﻱ ﻓﻲ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ 5. ﻴﺴﻤﻰ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﻤﺼﻔﻭﻓﺔ ﺍﻻﺭﺘﺒﺎﻁ ﺤﻴﺙ ﺘﺘﻜﻭﻥ ﻜل ﺨﻠﻴﺔ ﻤﻥ 3 ﺃﺭﻗﺎﻡ، ﺍﻷﻭل ﻫﻭ ﻗﻴﻤﺔ ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﺒﻴﻥ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ ﻭﺍﻟﺜﺎﻨﻲ 000.0 ﻫﻲ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻭﺍﻟﺜﺎﻟﺙ ﻫﻭ ﻋﺩﺩ ﺍﻟﺒﻴﺎﻨﺎﺕ )ﺍﻻﺯﻭﺍﺝ ﺍﻟﻤﺭﺘﻴﺔ ﻟﻘﻴﻡ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ( ﺍﻟﻤﺩﺨﻠﺔ ﻭﺍﻟﻤﺴﺘﺨﺩﻤﺔ ﻓﻲ ﻋﻤﻠﻴﺔ ﺍﻟﺤﺴﺎﺏ. ﻭﺘﺒﻴﻥ ﻤﺼﻔﻭﻓﺔ ﺍﻻﺭﺘﺒﺎﻁ ﺃﻥ ﻤﻌﺎﻤل ﺍﻻﺭﺘﺒﺎﻁ ﺒﻴﻥ ﺩﺭﺠﺎﺕ ﺍﻟﺭﻴﺎﻀﻴﺎﺕ ﻭﺍﻟﺤﺎﺴﻭﺏ ﻫﻭ 539.0 ﻭﺃﻥ ﻫﺫﻩ ﺍﻟﻌﻼﻗﺔ ﺩﺍﻟﺔ ﺍﺤﺼﺎﺌﻴﹰ، ﻭﺃﻥ ﻋﺩﺩ ﺍﻷﺯﻭﺍﺝ ﺍﻟﻤﺭﺘﺒﺔ ﻫﻭ 21. ﺎ ﻤﻼﺤﻅﺔ: ﻓﻲ ﺤﺎﻟﺔ ﻜﻭﻥ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ 0 > 0 H 0 : ρﺃﻭ 0 < 0 H 0 : ρﻓﻨﺨﺘﺎﺭ ﺍﻻﺨﺘﻴﺎﺭ One .Tailed 98
90.
ﺍﻟﻭﺤﺩﺓ ﺍﻟﺭﺍﺒﻌﺔ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ
ﺍﻷﺤﺎﺩﻱ ﻭﺍﻟﺜﻨﺎﺌﻲ 09
91.
ﺍﻟﻭﺤﺩﺓ ﺍﻟﺭﺍﺒﻌﺔ: ﺘﺤﻠﻴل
ﺍﻟﺘﺒﺎﻴﻥ ﺍﻷﺤﺎﺩﻱ ﻭﺍﻟﺜﻨﺎﺌﻲ 1. ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ ﻟﻘﺩ ﺘﻌﺭﻀﻨﺎ ﻟﻤﻭﻀﻭﻉ ﻤﻘﺎﺭﻨﺔ ﻤﺘﻭﺴﻁﺎﺕ ﻤﺠﺘﻤﻌﻴﻥ ﻓﻲ ﺍﻟﺒﻨﻭﺩ ﺍﻟﺴﺎﺒﻘﺔ، ﻭﺴﺘﺩﺭﺱ ﻓـﻲ ﻫـﺫﺍ ﺍﻟﺒﻨـﺩ ﺍﺨﺘﺒﺎﺭ ﻓﺭﻀﻴﺎﺕ ﺤﻭل ﻤﻘﺎﺭﻨﺔ ﻋﺩﺓ ﻤﺘﻭﺴﻁﺎﺕ ﻷﻜﺜﺭ ﻤﻥ ﻤﺠﺘﻤﻌﻴﻥ، ﻭﺍﻻﺴﻠﻭﺏ ﺍﻟﻤﺘﺒﻊ ﻓﻲ ﺫﻟﻙ ﻴﻘﻴﺱ ﺍﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻷﺤﺎﺩﻱ ﺘﺄﺜﻴﺭ ﻋﺎﻤل ﻭﺍﺤﺩ ﻤﻜﻭﻥ ﻤﻥ ﻋﺩﺓ ﻤﺴﺘﻭﻴﺎﺕ )ﻤﺘﻐﻴﺭ ﻫﻭ ﺍﺴﻠﻭﺏ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ. )51( ﻓﻠـﻭ ﺃﺭﺩﻨـﺎ ﻤﺴﺘﻘل ﻨﻭﻋﻲ ﻓﻴﻪ ﻤﻜﻭﻥ ﻤﻥ 3 ﻓﺌﺎﺕ ﻓﺄﻜﺜﺭ( ﻋﻠﻰ ﻋﺎﻤل ﺃﺨﺭ )ﻤﺘﻐﻴﺭ ﺘﺎﺒﻊ ﻤﺘﺼل( ﻤﻘﺎﺭﻨﺔ ﻤﺘﻭﺴﻁﺎﺕ 3 ﻤﺠﺘﻤﻌﺎﺕ ﻓﺄﻜﺜﺭ ﻨﻔﺱ ﺍﻟﻤﺘﻭﺴﻁ ﺍﻡ ﻻ ﻓﻬﺫﺍ ﻴﻌﻨﻲ ﺃﻨﻨﺎ ﻨﺭﻴﺩ ﺇﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀـﻴﺎﺕ ﺍﻟﺘﺎﻟﻴﺔ: ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻻ ﻴﻭﺠﺩ ﻓﺭﻕ ﻤﻌﻨﻭﻱ )ﺤﻘﻴﻘﻲ( ﺒﻴﻥ ﻤﺘﻭﺴﻁ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ. ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ: ﻴﻭﺠﺩ ﻓﺭﻕ ﻤﻌﻨﻭﻱ ﺒﻴﻥ ﻤﺘﻭﺴﻁ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ )ﺃﻱ ﺃﻨﻪ ﻴﻭﺠـﺩ ﺍﺨـﺘﻼﻑ ﺒـﻴﻥ ﻤﺘﻭﺴﻁ ﻤﺠﺘﻤﻌﻴﻥ ﻋﻠﻰ ﺍﻷﻗل(. ﺃﻱ ﻨﺭﻴﺩ ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺍﻟﺘﺎﻟﻴﺔ H 0 : µ 1 = µ 2 = µ 3 = ......µ n ﻭﻟﻠﻘﻴﺎﻡ ﺒﺎﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻷﺤﺎﺩﻱ ﻴﺠﺏ ﺘﺤﻘﻴﻕ ﺍﻟﺸﺭﻭﻁ ﺍﻟﺘﺎﻟﻴﺔ ﻗﺒل ﺇﺠﺭﺍﺅﻩ: • ﻜل ﻓﺌﺔ ﻤﻥ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻨﻭﻋﻲ ﺤﺴﺏ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﻤﺘﺼل ﻟﻬﺎ ﺘﻭﺯﻴﻊ ﻁﺒﻴﻌﻲ. • ﻓﺌﺎﺕ ﺍﻟﻤﺠﺘﻤﻊ ﺍﻟﻤﺨﺘﻠﻔﺔ ﻤﺘﺠﺎﻨﺴﺔ ﺃﻱ ﺃﻥ ﺘﺒﺎﻴﻨﻬﺎ ﻤﺘﺴﺎﻭﻱ. • ﺍﻟﻤﺸﺎﻫﺩﺍﺕ ﺃﻭ ﺍﻟﻘﻴﻡ ﻤﺴﺘﻘﻠﺔ. ﻭﻨﺤﻥ ﻟﺴﻨﺎ ﺒﺼﺩﺩ ﺍﻵﻥ ﺩﺭﺍﺴﺔ ﻫﺫﻩ ﺍﻟﺸﺭﻭﻁ ﻟﺫﺍ ﺴﻨﻌﺘﺒﺭ ﺃﻥ ﺍﻟﺸﺭﻭﻁ ﺍﻟﺴﺎﺒﻘﺔ ﻤﺘﺤﻘﻘﺔ. ﻤﺜﺎل 1: ﺇﺫﺍ ﻜﺎﻥ ﻟﺩﻴﻙ ﺍﻟﺠﺩﻭل ﺍﻟﺘﺎﻟﻲ ﺍﻟﺫﻱ ﻴﻤﺜل ﺘﻭﺯﻴﻊ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺤﺴﺏ ﺍﻟﺴﻨﺔ )ﺍﻟﻤﺴﺘﻭﻯ( ﺍﻟﺩﺭﺍﺴﻲ. ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺜﺎﻨﻲ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺜﺎﻟﺙ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺭﺍﺒﻊ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻷﻭل 07 55 04 03 66 57 07 08 06 55 04 05 04 09 58 08 04 05 03 04 09 28 58 57 24 07 56 07 56 67 57 58 03 05 55 06 06 05 03 04 59 08 54 34 88 76 36 26 24 77 09 08 03 58 04 06 44 53 03 06 05 ﻭﻨﺭﻴﺩ ﻤﻘﺎﺭﻨﺔ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻠﺒﺔ ﻓﻲ ﻤﺎﺩﺓ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ Arabicﺤﺴﺏ ﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺩﺭﺍﺴﻲ Levelﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = α؟ 51ﻨﺴﺘﻁﻴﻊ ﺘﻁﺒﻴﻕ ﺍﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ ﺒﺎﺴﺘﺨﺩﺍﻡ ﻤﺘﻐﻴﺭ ﺫﻭ ﻓﺌﺘﻴﻥ ﻟﻜﻥ ﺘﻜﻭﻥ ﻨﺘﻴﺠﺔ ﺍﺨﺘﺒﺎﺭ Tﻓﻲ ﻫﺫﻩ ﺍﻟﺤﺎﻟﺔ ﺃﻓﻀل. 19
92.
ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻻ
ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺤﺴﺏ ﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺩﺭﺍﺴﻲ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = α؟ ﻭﻟﻺﺠﺎﺒﺔ ﻋﻠﻰ ﺍﻟﻔﺭﻀﻴﺔ ﻨﻘﻭﻡ ﺒﺎﻟﺨﻁﻭﺍﺕ ﺍﻟﺘﺎﻟﻴﺔ. 1. ﻨﻌﺭﻑ ﻤﺘﻐﻴﺭﻴﻥ ) (Arabicﻭ ) (Levelﺒﺤﻴﺙ ﻴﻜﻭﻥ ﻜﻭﺩ ﻤﺘﻐﻴﺭ Levelﻫﻭ ) 1= ﺍﻟﻤﺴﺘﻭﻯ ﺍﻻﻭل، 2=ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺜﺎﻨﻲ، 3= ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺜﺎﻟﺙ، 4= ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺭﺍﺒﻊ( . 2. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﺒﺤﻴﺙ ﺘﻜﻭﻥ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﺘﻐﻴﺭ ) (Arabicﻓﻲ ﻋﻤﻭﺩ ﻤﺴﺘﻘل ﻭﻤﻥ ﺜﻡ ﻨﺩﺨل ﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﻤﻴﺯ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ) (Levelﺒﺤﻴﺙ ﻴﻜﻭﻥ ﻜل ﺩﺭﺠﺔ ﻭﻤﺼﺩﺭﻫﺎ ﻓﻲ ﻨﻔﺱ ﺍﻟﺴﻁﺭ ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 3. ﻤﻥ ﺨﻼل ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﺍﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ )ﻤﻘﺎﺭﻨﺔ ﺍﻟﻤﺘﻭﺴﻁﺎﺕ( Compare Meanﻭﻤﻥ ﺜﻡ ﺍﺨﺘﺎﺭ )ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ( ،One Way ANOVA ﻓﺴﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ: 29
93.
4. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ ﻨﻨﻘل ﻤﺘﻐﻴﺭ ﺍﻟﺩﺭﺠﺎﺕ ) (Arabicﺇﻟﻰ ﺨﺎﻨﺔ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺘﺎﺒﻊ Dependent Listﻭ ﺍﻟﻤﺘﻐﻴﺭ 5. ) (Levelﺇﻟﻰ ﺨﺎﻨﺔ . Factor 39
94.
6. ﺍﻵﻥ ﺍﺼﺒﺤﻨﺎ
ﺠﺎﻫﺯﻴﻥ ﻟﺘﻨﻔﻴﺫ ﺍﻻﺨﺘﺒﺎﺭ ﻓﻨﻀﻐﻁ ﻋﻠﻰ ،Okﻟﻴﻅﻬﺭ ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲ: ﻨﺎﺘﺞ ﺍﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ ﺩﺭﺠﺔ ﺍﻟﺤﺭﻴﺔ ﻤﺠﻤﻭﻉ ﺍﻟﻤﺭﺒﻌﺎﺕ ﻤﻌﺩل ﺍﻟﻤﺭﺒﻌﺎﺕ ﻗﻴﻤﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ﺍﻟﻨﺘﺎﺌﺞ: ﻴﺘﻜﻭﻥ ﻨﺎﺘﺞ ﺠﺩﻭل ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ ﻤﻥ ﺠﺩﻭل ﻭﺍﺤﺩ ﻓﻘﻁ ﻭﻫﻭ ﺠﺩﻭل ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ ﻭﻫﻭ ﻤﺸﺎﺒﻪ ﺘﻤﺎﻤﺎ ﻟﻠﺠﺩﻭل ﺍﻟﺫﻱ ﺩﺭﺴﻨﺎﻩ ﻓﻲ ﺍﻟﺠﺎﻨﺏ ﺍﻟﻨﻅﺭﻱ ﻤﻥ ﺍﻟﻤﻘﺭﺭ. ﹰ ﻓﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﻤﺎ ﻴﻠﻲ: - ﻤﺠﻤﻭﻉ ﺍﻟﻤﺭﺒﻌﺎﺕ: ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺃﻥ ﻤﺠﻤﻭﻉ ﻤﺭﺒﻌﺎﺕ ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ ﻫﻲ 633.2773 ﻭﺃﻥ ﻤﺠﻤﻭﻉ ﻤﺭﺒﻌﺎﺕ ﺍﻟﺨﻁﺄ 168.50181 ﻭﺃﻥ ﻤﺠﻤﻭﻉ ﺍﻟﻤﺭﺒﻌﺎﺕ ﺍﻟﻜﻠﻲ ﻫﻭ 791.87812. - ﺩﺭﺠﺎﺕ ﺍﻟﺤﺭﻴﺔ: ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻥ ﺩﺭﺠﺔ ﺤﺭﻴﺔ ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ ﻫﻲ 3 )ﻋﺩﺩ ﺍﻟﻌﻴﻨﺎﺕ ﻨﺎﻗﺼﺎ 1( ﻭ ﺍﻥ ﺩﺭﺠﺔ ﺤﺭﻴﺔ ﺍﻟﺨﻁﺄ ﻫﻲ 75 ﻭ ﻤﺠﻤﻭﻉ ﺩﺭﺠﺎﺕ ﺍﻟﺤﺭﻴﺔ ﻫﻲ 06. ﹰ 49
95.
- ﻤﻌﺩل ﺍﻟﻤﺭﺒﻌﺎﺕ:
ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺃﻥ ﻤﻌﺩل ﻤﺭﺒﻌﺎﺕ ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ ﻭ ﺍﻟﺨﻁﺄ ﻋﻠﻰ ﺍﻟﺘﻭﺍﻟﻲ ﻫﻭ 544.7521 ﻭ 746.713. - ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ ﻫﻲ 959.3 . - ﻭﺃﺨﻴﺭ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ 210.0=. Sigﻫﻲ ﺃﻗل ً ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 50.0 = αﻭ ﺒﺎﻟﺘﺎﻟﻲ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ، ﻭﻨﺴﺘﻨﺘﺞ ﺃﻥ ﻫﻨﺎﻙ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﺒﻴﻥ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﺤﺴﺏ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺩﺭﺍﺴﻲ ﺃﻱ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. 7. ﻤﻼﺤﻅﺔ: ﻤﻥ ﺃﻫﻡ ﺸﺭﻭﻁ ﺘﻁﺒﻴﻕ ﺍﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ ﻫﻭ ﺘﺠﺎﻨﺱ ﺍﻟﻌﻴﻨﺎﺕ )ﺃﻥ ﻴﻜﻭﻥ ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺎﺕ ﻤﺘﺴﺎﻭﻱ ﺍﺤﺼﺎﺌﻴﺎ( ﻭ ﻟﻠﻘﻴﺎﻡ ﺒﺫﻟﻙ ﻤﻥ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﻟﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﹰ ﺍﻻﺤﺎﺩﻱ ﻨﻀﻐﻁ ﻋﻠﻰ Optionsﻟﻔﺤﺹ ﺘﺠﺎﻨﺱ ﺍﻟﻌﻴﻨﺎﺕ. ﻓﻨﻀﻊ ﻋﻼﻤﺔ ﻋﻠﻰ ﺨﺎﻨﺔ Homogeneity of Variance testﻓﻲ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﻻﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ ﺍﻟﺴﺎﺒﻕ ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ Continueﻟﻠﻌﻭﺩﺓ ﻟﻠﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺨﺎﺹ ﺒﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﻓﻨﻀﻐﻁ Okﻟﻴﻅﻬﺭ ﺠﺩﻭل ﺠﺩﻴﺩ ﺒﺎﻻﻀﺎﻓﺔ ﻟﺠﺩﻭل ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ ﻭﻫﻭ ﻨﺎﺘﺞ ﺘﻁﺒﻴﻕ ﺍﺨﺘﺒﺎﺭ Leveneﻟﺘﺠﺎﻨﺱ ﺍﻟﻌﻴﻨﺎﺕ ﻭﻫﻭ ﻜﻤﺎ ﻴﻠﻲ: 59
96.
ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ
ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻟﻴﻔﻴﻨﻲ ﻟﻠﺘﺠﺎﻨﺱ ﻭﻫﻲ 587.0 ﺒﻭﺍﻗﻊ ﺩﻻﻟﺔ 705.0 ﻭﻫﻲ ﺃﻜﺒﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 50.0 = αﻭﺒﺎﻟﺘﺎﻟﻲ ﻻ ﻨﺴﺘﻁﻴﻊ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ )61( . ﺃﻱ ﺃﻥ ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺎﺕ ﻤﺘﺴﺎﻭﻱ 61ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﺘﺒﺎﻴﻥ ﺍﻟﻌﻴﻨﺎﺕ ﻤﺘﺴﺎﻭﻱ )ﺍﻟﻌﻴﻨﺎﺕ ﻤﺘﺠﺎﻨﺴﺔ( 69
97.
2. ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ
ﺍﻟﺜﻨﺎﺌﻲ ﻓﻲ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ ﺩﺭﺴﻨﺎ ﺘﺄﺜﻴﺭ )ﻋﺎﻤل ﻭﺍﺤﺩ( ﻤﻜﻭﻥ ﻤﻥ ﻋﺩﺓ ﻤﺴﺘﻭﻴﺎﺕ )ﻤﺘﻐﻴﺭ ﻨﻭﻋﻲ ﻓﻴﻪ ﻤﻜﻭﻥ ﻤﻥ 3 ﻓﺌﺎﺕ ﻓﺄﻜﺜﺭ( ﻋﻠﻰ ﻤﺘﻐﻴﺭ ﺁﺨﺭ )ﻤﺘﻐﻴﺭ ﻤﺘﺼل(، ﺃﻤﺎ ﻓﻲ ﺍﺴﻠﻭﺏ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﺜﻨﺎﺌﻲ ﺴﻨﺩﺭﺱ ﺘﺄﺜﻴﺭ ﻤﺘﻐﻴﺭﻴﻥ ﻤﺴﺘﻘﻠﻴﻥ ﻤﻜﻭﻨﻴﻥ ﻤﻥ ﻋﺩﺓ ﻤﺴﺘﻭﻴﺎﺕ )ﻤﺘﻐﻴﺭﻴﻥ ﻨﻭﻋﻴﻴﻥ( ﻋﻠﻰ ﻋﺎﻤل ﺁﺨﺭ )ﻤﺘﻐﻴﺭ ﻤﺘﺼل(. ﻓﻤﺜﻼ ﻟﻭ ﺃﺭﺩﻨﺎ ﺩﺭﺍﺴﺔ ﻫل ﻴﻭﺠﺩ ﺘﺄﺜﻴﺭ ﻟﻌﺎﻤل ﺍﻟﺠﻨﺱ ﻭﺍﻟﺤﺎﻟﺔ ﺍﻻﺠﺘﻤﺎﻋﻴﺔ ﻋﻠﻰ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﻤﺎ، ﻓﻬﻨﺎ ﻻ ﺒﺩ ﻟﻨﺎ ﻤﻥ ﺍﺴﺘﺨﺩﺍﻡ ﺍﺴﻠﻭﺏ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﺜﻨﺎﺌﻲ. ﻭﻴﻘﻴﺱ ﺍﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﺜﻨﺎﺌﻲ ﻤﺩﻯ ﺘﺄﺜﻴﺭ ﺍﻟﻌﺎﻤل ﺍﻷﻭل ﻋﻠﻰ ﺤﺩﺓ، ﻭﻤﻥ ﺜﻡ ﻤﺩﻯ ﺘﺄﺜﻴﺭ ﺍﻟﻌﺎﻤل ﺍﻟﺜﺎﻨﻲ ﻋﻠﻰ ﺤﺩﺓ، ﻭﻓﻲ ﺍﻟﻨﻬﺎﻴﺔ ﻴﻘﻴﺱ ﻤﺩﻯ ﺘﺄﺜﻴﺭ ﺘﻔﺎﻋل ﺍﻟﻌﺎﻤﻠﻴﻥ ﻤﻌﺎ ﻋﻠﻰ ﺍﻟﻤﺘﻐﻴﺭ ﺍﻟﺘﺎﺒﻊ، ﻓﻬﻭ ﻴﺠﻴﺏ ﹰ ﻋﻠﻰ 3 ﺃﺴﺌﻠﺔ ﻓﻲ ﻨﻔﺱ ﺍﻟﻭﻗﺕ 1. ﻫل ﻴﻭﺠﺩ ﻓﺭﻕ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﻤﺴﺘﻭﻴﺎﺕ ﺍﻟﻌﺎﻤل ﺍﻷﻭل . 2. ﻫل ﻴﻭﺠﺩ ﻓﺭﻕ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺍﻟﻌﺎﻤل ﺍﻟﺜﺎﻨﻲ. 3. ﻫل ﻴﻭﺠﺩ ﺘﻔﺎﻋل ﺒﻴﻥ ﺍﻟﻌﺎﻤﻠﻴﻥ ﺃﻡ ﺃﻥ ﺍﻟﻌﺎﻤﻠﻴﻥ ﻤﺴﺘﻘﻠﻴﻥ ﻓﻲ ﺍﻟﺘﺄﺜﻴﺭ. ﻤﺜﺎل 2: ﻓﻲ ﺍﻟﻤﺜﺎل ﺍﻟﺴﺎﺒﻕ ﻟﻭ ﻭﺯﻋﻨﺎ ﺒﻴﺎﻨﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ) (Arabicﺤﺴﺏ ﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺩﺭﺍﺴﻲ ) (Levelﻭ ﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ ) (Genderﻜﻤﺎ ﻓﻲ ﺍﻟﺠﺩﻭل ﺍﻟﺘﺎﻟﻲ: ﺍﻟﺠﻨﺱ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺭﺍﺒﻊ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺜﺎﻟﺙ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺜﺎﻨﻲ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻷﻭل ﺫﻜﺭ 06 55 04 05 66 57 07 08 07 55 04 03 04 09 58 08 07 56 07 09 28 58 57 05 03 04 56 67 57 58 ﺃﻨﺜﻰ 08 54 34 24 06 05 03 04 05 55 06 04 88 76 36 26 58 04 06 59 24 77 09 08 03 44 53 03 03 06 05 ﺍﻟﻤﻁﻠﻭﺏ: ﺃ- ﻜﻭﻥ ﺠﺩﻭل ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﺜﻨﺎﺌﻲ. ﺏ- ﻜﻭﻥ ﻓﺭﻀﻴﺎﺕ ﺠﺩﻭل ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﺜﻨﺎﺌﻲ ﻭﺒﻴﻥ ﻫل ﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺎﺕ. ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺎﺕ: 1. ﻻ ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺤﺴﺏ ﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺩﺭﺍﺴﻲ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = α 79
98.
2. ﻻ ﻴﻭﺠﺩ
ﻓﺭﻭﻕ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺤﺴﺏ ﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = α 3. ﻻ ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺤﺴﺏ ﺍﻟﺘﻔﺎﻋل ﺒﻴﻥ ﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺩﺭﺍﺴﻲ ﻭ ﺍﻟﺠﻨﺱ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = . α ﺘﻨﻔﻴﺫ ﺍﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﺜﻨﺎﺌﻲ 1. ﻨﻌﺭﻑ 3 ﻤﺘﻐﻴﺭﺍﺕ ) (Arabicﻭ ) (Levelﻭ ) (Genderﺒﺤﻴﺙ ﻴﻜﻭﻥ ﻜﻭﺩ ﻤﺘﻐﻴﺭ Level ﻫﻭ ) 1= ﺍﻟﻤﺴﺘﻭﻯ ﺍﻻﻭل، 2=ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺜﺎﻨﻲ، 3 = ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺜﺎﻟﺙ، 4 = ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺭﺍﺒﻊ(، ﻭﺒﺎﻟﻨﺴﺒﺔ ﻟﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ ) (Genderﻨﻌﺭﻑ ﺍﻟﻜﻭﺩ )1=ﺫﻜﺭ، 2=ﺃﻨﺜﻰ(. 2. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 89
99.
3. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﺍﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ )General Linear Model(GLM ﻭﻤﻥ ﺜﻡ ﺍﺨﺘﺎﺭ ،Univariateﻓﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 4. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺨﺎﺹ ﺒﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﺜﻨﺎﺌﻲ ﺍﻟﺘﺎﻟﻲ: 99
100.
5. ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭ
) (Arabicﻟﺨﺎﻨﺔ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺘﺎﺒﻌﺔ Dependent Variableﻭﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭﻴﻥ ) (Levelﻭ ) (Genderﻟﺨﺎﻨﺔ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﻤﺴﺘﻘﻠﺔ Fixed Factorsﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 6. ﻨﻀﻐﻁ ﻋﻠﻰ Okﻟﻠﺤﺼﻭل ﻋﻠﻰ ﺍﻟﻨﺘﺎﺌﺞ. 001
101.
ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل
ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﺜﻨﺎﺌﻲ ﻴﺘﻜﻭﻥ ﻨﺎﺘﺞ ﺠﺩﻭل ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﻤﻥ ﺠﺩﻭﻟﻴﻥ ﺍﻻﻭل ﻴﺼﻑ ﺍﻟﻌﻴﻨﺎﺕ ﻭﺘﻭﺯﻴﻌﻬﺎ ﻭﺍﻟﺜﺎﻨﻲ ﻫﻭ ﺠﺩﻭل ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﺜﻨﺎﺌﻲ. 101
102.
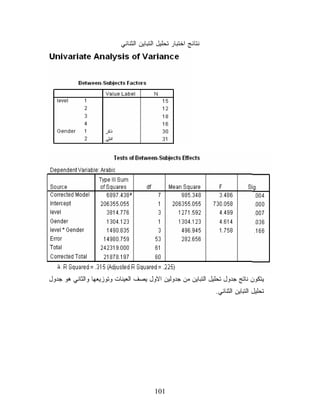
ﺍﻟﺠﺩﻭل ﺍﻷﻭل
ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺘﻭﺯﻴﻊ ﺍﻟﻌﻴﻨﺎﺕ )51 ﻤﻥ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻷﻭل، 21 ﻤﻥ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺜﺎﻨﻲ، 81 ﻤﻥ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺜﺎﻟﺙ، 61 ﻤﻥ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺭﺍﺒﻊ، 03 ﺫﻜﻭﺭ ﻭ 13 ﺍﻨﺎﺙ(. ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ ﻤﺼﺩﺭ ﺍﻟﺘﺒﺎﻴﻥ ﺩﺭﺠﺔ ﺍﻟﺤﺭﻴﺔ ﻤﺠﻤﻭﻉ ﺍﻟﻤﺭﺒﻌﺎﺕ ﻤﻌﺩل ﺍﻟﻤﺭﺒﻌﺎﺕ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ﻗﻴﻤﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻟﻔﻬﻡ ﺍﻟﺠﺩﻭل ﺍﻟﻤﺒﻴﻥ ﺃﻋﻼﻩ ﻭﺍﻟﻨﺎﺘﺞ ﻋﻥ ﺒﺭﻨﺎﻤﺞ SPSSﻴﺠﺏ ﺃﻥ ﻨﻜﻭﻥ ﻋﻠﻰ ﺩﺭﺍﻴﺔ ﺒﺎﻻﺴﺎﺱ ﺍﻟﻨﻅﺭﻱ ﻟﻠﻤﻘﺭﺭ، ﻓﻴﻭﺠﺩ ﺍﺨﺘﻼﻑ ﻁﻔﻴﻑ ﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺍﻟﺫﻱ ﺩﺭﺴﻨﺎﻩ ﻓﻲ ﺍﻟﺠﺎﻨﺏ ﺍﻟﻨﻅﺭﻱ ﻭﺍﻟﻨﺎﺘﺞ ﻋﻥ SPSSﻭﺫﻟﻙ ﻷﻨﻨﺎ ﻟﻡ ﻨﺩﺭﺱ ﻓﻲ ﺍﻟﺠﺎﻨﺏ ﺍﻟﻨﻅﺭﻱ ﻟﺠﻤﻴﻊ ﺘﻁﺒﻴﻘﺎﺕ ﻭﺃﺸﻜﺎل ﻭﻁﺭﻕ ﺤﺴﺎﺏ ﺠﺩﻭل ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﺜﻨﺎﺌﻲ ،ﻟﺫﻟﻙ ﺴﻨﺩﺭﺱ ﻓﻘﻁ ﻜﻴﻔﻴﺔ ﺍﻴﺠﺎﺩ ﺍﻟﻤﺘﻁﻠﺒﺎﺕ ﺍﻟﺘﻲ ﻴﺘﻁﻠﺒﻬﺎ ﺍﻟﺠﺎﻨﺏ ﺍﻟﻨﻅﺭﻱ ﻤﻥ ﺍﻟﻤﻘﺭﺭ ﻓﻤﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﻨﺴﺘﻁﻴﻊ ﺍﻻﺴﺘﻨﺘﺎﺝ ﺃﻥ. 201
103.
- ﻤﺠﻤﻭﻉ ﺍﻟﻤﺭﺒﻌﺎﺕ:
ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻥ ﻤﺠﻤﻭﻉ ﻤﺭﺒﻌﺎﺕ ﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻭﻯ 677.4183 ﻭﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ 321.4031 ﻭﺍﻟﺘﻔﺎﻋل ﺒﻴﻥ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ 538.0941 ﻭﻤﺠﻤﻭﻉ ﻤﺭﺒﻌﺎﺕ ﺍﻟﺨﻁﺄ 957.08941 ﻭﺃﻥ ﻤﺠﻤﻭﻉ ﺍﻟﻤﺭﺒﻌﺎﺕ ﺍﻟﻜﻠﻲ 791.87812. - ﺩﺭﺠﺎﺕ ﺍﻟﺤﺭﻴﺔ ﻋﻠﻰ ﺍﻟﺘﻭﺍﻟﻲ ) 3 ﻟﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻭﻯ، 1 ﻟﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ، 3 ﻟﻠﺘﻔﺎﻟﻌل ﺒﻴﻥ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ، 35 ﻟﻠﺨﻁﺄ، ﻭ ﻤﺠﻤﻭﻉ ﺩﺭﺠﺎﺕ ﺍﻟﺤﺭﻴﺔ ﻫﻭ 06(. - ﻤﻌﺩل ﺍﻟﻤﺭﺒﻌﺎﺕ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﻋﻠﻰ ﺍﻟﺘﻭﺍﻟﻲ ) 295.1721 ﻟﻠﻤﺴﺘﻭﻯ، 321.4031 ﻟﻠﺠﻨﺱ، ﻭ 549.694 ﻟﻠﺘﻔﺎﻋل ﺒﻴﻥ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ، ﻭ 656.282 ﻟﻠﺨﻁﺄ(. - ﻗﻴﻤﺔ Fﺍﻟﻤﺤﺴﻭﺒﺔ ﻟﻠﻤﺘﻐﻴﺭﺍﺕ ﻋﻠﻰ ﺍﻟﺘﻭﺍﻟﻲ )994.4 ﻟﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻭﻯ، 416.4 ﻟﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ، 857.1 ﻟﻠﺘﻔﺎﻋل ﺒﻴﻨﻬﻤﺎ(. ﻭﺒﻨﺎﺀ ﻋﻠﻰ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ً • ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺍﻟﺨﺎﺼﺔ ﺒﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺩﺭﺍﺴﻲ ﻷﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻟﻠﻤﺘﻐﻴﺭ 700.0= . Sigﺃﻗل ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 50.0 = αﻓﺒﺎﻟﺘﺎﻟﻲ ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﺤﺴﺏ ﻤﺘﻐﻴﺭ ﺍﻟﻤﺴﺘﻭﻯ ﺍﻟﺩﺭﺍﺴﻲ. ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺍﻟﺨﺎﺼﺔ ﺒﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ ﻷﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻟﻤﺘﻐﻴﺭ • ﺍﻟﺠﻨﺱ 630.0= . Sigﺃﻗل ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 50.0 = αﻓﺒﺎﻟﺘﺎﻟﻲ ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﺤﺴﺏ ﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ. • ﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺍﻟﺨﺎﺼﺔ ﺒﺘﻔﺎﻋل ﺍﻟﻤﺘﻐﻴﺭﻴﻥ ﻷﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻟﻠﺘﻔﺎﻋل ﺒﻴﻥ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ 661.0= . Sigﺃﻜﺒﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 50.0 = αﻓﺒﺎﻟﺘﺎﻟﻲ ﻻ ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﻓﻲ ﺍﻟﻤﺘﻭﺴﻁﺎﺕ. 301
104.
ﺍﻟﻭﺤﺩﺓ ﺍﻟﺨﺎﻤﺴﺔ ﻁﺭﻕ ﻏﻴﺭ
ﻤﻌﻠﻤﻴﺔ 401
105.
ﺍﻟﻭﺤﺩﺓ ﺍﻟﺨﺎﻤﺴﺔ:ﻁﺭﻕ ﻏﻴﺭ
ﻤﻌﻠﻤﻴﺔ ﺍﻥ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﺘﻲ ﺩﺭﺴﺘﻬﺎ ﻓﻲ ﺍﻟﻭﺤﺩﺓ ﺍﻟﺜﺎﻟﺜﺔ ﻭﺍﻟﺭﺍﺒﻌﺔ ﻫﻲ ﺍﺨﺘﺒﺎﺭﺍﺕ ﻤﻌﻠﻤﻴﺔ ﻷﻨﻬﺎ ﺘﺘﻌﺎﻤل ﻤﻊ ﺨﺼﺎﺌﺹ ﺍﻟﻤﺠﺘﻤﻊ ﺃﻭ ﻤﺎ ﻴﺴﻤﻰ ﻤﻌﺎﻟﻤﻪ، ﻭﻫﺫﻩ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻤﻌﻠﻤﻴﺔ ﻻ ﻴﻤﻜﻥ ﺘﻁﺒﻴﻘﻬﺎ ﺇﻻ ﻓﻲ ﺤﺎﻟﺔ ﺘﻭﺍﻓﺭ ﺸﺭﻭﻁ ﻤﻌﻴﻨﺔ ﻤﺜل ﺃﻥ ﻴﻜﻭﻥ ﺘﻭﺯﻴﻊ ﺍﻟﻤﺠﺘﻤﻊ ﻁﺒﻴﻌﻴﺎ ﺃﻭ ﺃﻥ ﻴﻜﻭﻥ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ ﻜﺒﻴﺭ ﺃﻭ ﺼﻐﻴﺭ ﹰ ﺃﻭ ﺃﻥ ﺘﻜﻭﻥ ﻫﻨﺎﻙ ﺸﺭﻭﻁﺎ ﺨﺎﺼﺔ ﻓﻴﻪ ﻟﻠﺘﺒﺎﻴﻥ ﻭﻏﻴﺭﻫﺎ ﻤﻥ ﺍﻟﺸﺭﻭﻁ. ﻭﻋﻨﺩ ﻋﺩﻡ ﺘﻭﻓﺭ ﺸﺭﻭﻁ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻤﻌﻠﻤﻴﺔ ﻓﺈﻨﻨﺎ ﻻ ﻨﺴﺘﻁﻴﻊ ﺘﻁﺒﻴﻘﻬﺎ، ﻭﺒﺎﻟﺘﺎﻟﻲ ﻓﺈﻨﻨﺎ ﺴﻨﺤﺘﺎﺝ ﻟﺒﺩﻴل ﻭﻫﺫﺍ ﺍﻟﺒﺩﻴل ﻫﻭ ﺍﻹﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ)71(، ﻭﺘﺘﻤﻴﺯ ﻫﺫﻩ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ ﺒﺄﻨﻬﺎ ﺴﻬﻠﺔ ﺍﻟﺤﺴﺎﺏ ﻭﻻ ﻴﻭﺠﺩ ﺸﺭﻭﻁ ﻤﻌﻴﻨﺔ ﻟﺘﻨﻔﻴﺫﻫﺎ ﻭﻤﻥ ﺍﻟﺠﺩﻴﺭ ﺒﺎﻟﺫﻜﺭ ﺃﻥ ﻫﻨﺎﻙ ﺍﻟﻜﺜﻴﺭ ﻤﻥ ﺍﻟﺘﺴﺎﺅﻻﺕ ﺍﻟﺘﻲ ﻻ ﺘﺠﻴﺏ ﻋﻠﻴﻬﺎ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻤﻌﻠﻤﻴﺔ ﻤﺜل ﺍﻻﺴﺌﻠﺔ ﺍﻟﺘﻲ ﺘﺘﻌﻠﻕ ﺒﺘﺭﺘﻴﺏ ﻗﻴﻡ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﻟﻴﺱ ﺍﻟﻘﻴﻡ ﻨﻔﺴﻬﺎ. 1. ﻤﻘﺎﺭﻨﺔ ﻭﺴﻴﻁ ﻤﺠﺘﻤﻊ ﺒﻭﺴﻴﻁ ﺍﻟﻌﻴﻨﺔ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ ﻓﻲ ﺤﺎﻟﺔ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﺼﻐﻴﺭﺓ 1.1. ﻤﺜﺎل 1: ﺘﻤﺜل ﺍﻷﺭﻗﺎﻡ ﺍﻟﺘﺎﻟﻴﺔ ﺩﺭﺠﺎﺕ ﺍﻟﺤﺭﺍﺭﺓ ﻓﻲ ﻤﻜﺔ ﺍﻟﻤﻜﺭﻤﺔ ﻓﻲ 81 ﻴﻭﻤﺎ ﻓﻲ ﺸﻬﺭ ﺃﻴﺎﺭ 24 43 73 83 14 83 53 73 93 44 52 93 63 93 03 63 73 03 ﺍﺨﺘﺒﺭ ﺍﻟﻔﺭﻀﻴﺔ ﺃﻥ ﻭﺴﻴﻁ ﺩﺭﺠﺎﺕ ﺍﻟﺤﺭﺍﺭﺓ ﻫﻭ 93 ﻋﻠﻰ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 1.0 = α؟ ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﺍﻟﻭﺴﻴﻁ ﻴﺴﺎﻭﻱ 93 1 93 = H 0 : M =P 2 ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ: ﺍﻟﻭﺴﻴﻁ ﻻ ﻴﺴﺎﻭﻱ 93 1 93 ≠ H a : M ≠P 2 1. ﻨﺤﺫﻑ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺴﺎﻭﻴﺔ ﻟﻠﺭﻗﻡ 93 ﻭﻤﻥ ﺜﻡ ﻨﺩﺨل ﺒﺎﻗﻲ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﻤﺘﻐﻴﺭ )ﺍﻟﺤﺭﺍﺭﺓ( ﺃﻨﻅﺭ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: ﺇﺫﺍ ﺘﻭﺍﻓﺭﺕ ﺸﺭﻭﻁ ﺘﻁﺒﻴﻕ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻤﻌﻠﻤﻴﺔ ﺘﻜﻭﻥ ﻨﺘﺎﺌﺠﻬﺎ ﺃﺩﻕ ﻭﺃﻓﻀل ﻭﺃﻜﺜﺭ ﻗﻭﺓ ﻤﻥ ﻨﺘﺎﺌﺞ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ. 71 501
106.
Non
2. ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ ﻟﻺﺤﺼﺎﺀﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ Parametric Testﻭﻤﻥ ﺜﻡ ﻨﺨﺘﺎﺭ ﺍﺨﺘﺒﺎﺭ ﺫﺍﺕ ﺍﻟﺤﺩﻴﻥ Binomialﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 601
107.
3. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺨﺎﺹ ﺒﺎﺨﺘﺒﺎﺭ ﺫﺍﺕ ﺍﻟﺤﺩﻴﻥ ﻓﻨﻨﻘل ﻤﺘﻐﻴﺭ )ﺍﻟﺤﺭﺍﺭﺓ( ﺇﻟﻰ ﻗﺎﺌﻤﺔ Test Variable Listﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ Cut Pointﻟﻨﻜﺘﺏ ﺍﻟﻘﻴﻤﺔ 93 ﻭﺘﺄﻜﺩ ﻤﻥ ﺃﻥ 05.0 ﻫﻲ ﺍﻟﻨﺴﺒﺔ ﺍﻟﺘﻲ ﻓﻲ ﺨﺎﻨﺔ .Test Proportion 2 1 701
108.
ﻨﻀﻐﻁ Okﻟﻴﻅﻬﺭ
ﺍﻟﻨﺎﺘﺞ ﺍﻟﺘﺎﻟﻲ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ ﺍﻟﻨﺘﺎﺌﺞ: ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﻫﻭ ﻨﺎﺘﺞ ﺍﺨﺘﺒﺎﺭ ﺫﺍﺕ ﺍﻟﺤﺩﻴﻥ ﺤﻴﺙ ﻴﺒﻴﻥ ﺃﻥ ﻗﻴﻤﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ 3 ﻭﺃﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ 530.0=) Exact Sig. (2-tailedﻭﻫﻲ ﺃﻗل ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 50.0 = ، αﺒﺎﻟﺘﺎﻟﻲ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺃﻱ ﺃﻥ ﺍﻟﻭﺴﻴﻁ ﻻ ﻴﺴﺎﻭﻱ 93. ﻓﻲ ﺤﺎﻟﺔ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﻜﺒﻴﺭﺓ 2.1. ﻤﺜﺎل 2: ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﺘﺎﻟﻴﺔ ﺘﻤﺜل ﺍﻟﺩﺨل ﺍﻟﻴﻭﻤﻲ ﻟﻤﺠﻤﻭﻋﺔ ﻤﻥ ﺍﻟﻤﻭﺍﻁﻨﻴﻥ ﺒﺎﻟﺸﻴﻜل 52 52 94 03 03 03 03 33 63 83 04 04 24 44 44 94 44 44 54 54 84 84 05 25 94 25 55 55 75 06 06 16 26 56 56 56 66 94 07 27 37 57 57 57 ﺸﻴﻜل ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = . α ﻫﻭ 04 ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻬل ﻨﺴﺘﻁﻴﻊ ﺍﻟﻘﻭل ﺃﻥ ﻭﺴﻴﻁ ﻫﺫﻩ ﺍﻟﺤل: 04 = H 0 : M 04 ≠ H a : M ﻨﻘﻭﻡ ﺒﺈﺩﺨﺎل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﻤﺘﻐﻴﺭ ) (incomeﺒﻌﺩ ﺤﺫﻑ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺴﺎﻭﻴﺔ ﻟﻠﺭﻗﻡ 04 ﻭﻨﻘﻭﻡ ﺒﻨﻔﺱ ﺍﻟﺨﻁﻭﺍﺕ ﺍﻟﺴﺎﺒﻘﺔ ﻓﻲ ﺍﻟﻤﺜﺎل ﺍﻟﺴﺎﺒﻕ ﻟﻨﺤﺼل ﻋﻠﻰ ﺍﻟﻨﺘﻴﺠﺔ ﺍﻟﺘﺎﻟﻴﺔ : 801
109.
ﻨﻼﺤﻅ ﺃﻥ ﻋﺩﺩ
ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺩﺨﻠﺔ ﻫﻭ 24 ﻭ ﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ ﻫﻲ 33 ﻭﺃﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ 000.0=) Exact Sig. (2-tailedﻭﻫﻲ ﺃﻗل ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ 50.0 ﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ، ﻟﻜﻥ ﻻﺤﻅ ﺍﻥ ﺍﻻﺨﺘﺒﺎﺭ ﺘﻡ ﺤﺴﺎﺒﻪ ﺒﺘﻘﺭﻴﺒﻪ ﻻﺨﺘﺒﺎﺭ Zﻜﻤﺎ ﻫﻭ ﻤﺒﻴﻥ ﻓﻲ ﺠﺩﻭل ﺍﻟﻨﺘﺎﺌﺞ ﺃﻋﻼﻩ. 2. ﺍﻟﻤﻘﺎﺭﻨﺔ ﺒﻴﻥ ﻭﺴﻴﻁ )ﺘﻭﺯﻴﻊ( ﻤﺠﺘﻤﻌﻴﻥ ﻤﺭﺘﺒﻁﻴﻥ. ﻤﻘﺎﺭﻨﺔ ﻭﺴﻴﻁ ﻋﻴﻨﺘﻴﻥ ﻤﺭﺘﺒﻁﺘﻴﻥ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ أ. ﻴﻌﻤل ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ ﻭﺍﺨﺘﺒﺎﺭ ﻭﻟﻜﺴﻜﻥ ﻋﻠﻰ ﻤﻘﺎﺭﻨﺔ ﻭﺴﻴﻁ ﺃﻭ ﺘﻭﺯﻴﻊ ﻤﺠﺘﻤﻌﻴﻥ ﻤﺭﺘﺒﻁﻴﻥ ﺃﻱ ﺒﻤﻌﻨﻰ ﺁﺨﺭ ﻫل ﻴﻭﺠﺩ ﺍﺨﺘﻼﻑ ﻓﻲ ﺘﻭﺯﻴﻊ )ﻭﺴﻴﻁ( ﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺠﺘﻤﻌﻴﻥ ﺃﻡ ﻻ. ﻤﺜﺎل 3: ﺇﺫﺍ ﻜﺎﻨﺕ ﺩﺭﺠﺎﺕ 02 ﻁﺎﻟﺏ ﻓﻲ ﻤﻘﺭﺭﻱ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻭﺍﻻﻨﺠﻠﻴﺯﻴﺔ ﻜﻤﺎ ﻓﻲ ﺍﻟﺠﺩﻭل ﺍﻟﺘﺎﻟﻲ: 1 ﺭﻗﻡ ﺍﻟﻁﺎﻟﺏ 2 3 4 5 6 7 8 9 01 ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ 58 08 05 58 04 08 09 08 06 05 ﺍﻟﻠﻐﺔ ﺍﻻﻨﺠﻠﻴﺯﻴﺔ 08 05 05 56 05 09 59 48 04 03 ﺭﻗﻡ ﺍﻟﻁﺎﻟﺏ 11 21 31 41 51 61 71 81 91 02 ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ 78 08 58 09 57 04 03 55 08 54 ﺍﻟﻠﻐﺔ ﺍﻻﻨﺠﻠﻴﺯﻴﺔ 08 57 56 07 57 06 04 07 09 57 ﻭﺍﻟﻤﻁﻠﻭﺏ ﻤﻌﺭﻓﺔ ﻤﺎ ﺇﺫﺍ ﻜﺎﻥ ﻫﻨﺎﻙ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﺒﻴﻥ ﻭﺴﻴﻁ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﻤﻘﺭﺭﻴﻥ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = α؟ 901
110.
ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻻ
ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﻓﻲ ﻭﺴﻴﻁ )ﺘﻭﺯﻴﻊ( ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻻﺨﺘﺒﺎﺭﻴﻥ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ : ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﻓﻲ ﻭﺴﻴﻁ )ﺘﻭﺯﻴﻊ( ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻻﺨﺘﺒﺎﺭﻴﻥ. 1. ﻨﻌﺭﻑ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ ) (Arabicﻭ ﺍﻟﻤﺘﻐﻴﺭ ) (Englishﻓﻲ ﺸﺎﺸﺔ ﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ 2. ﻨﺩﺨل ﺒﻴﺎﻨﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻓﻲ ﻋﻤﻭﺩ ) (Arabicﻭﺒﻴﺎﻨﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﺍﻟﻠﻐﺔ ﺍﻻﻨﺠﻠﻴﺯﻴﺔ ﻓﻲ ﻋﻤﻭﺩ ) (Englishﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ : ) Non-Parametric ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ 3. ﻤﻥ (Statisticsﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﺨﺘﺒﺎﺭ ﻋﻴﻨﺘﻴﻥ ﻤﺭﺘﺒﻁﺘﻴﻥ )(2 Related Samples 011
111.
4. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 5. ﻨﺨﺘﺎﺭ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ ) (Arabicﻭ) (Englishﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ ﺍﻟﺴﻬﻡ ﻟﻴﻨﺘﻘﻼ ﺇﻟﻰ ﺨﺎﻨﺔ Test ﺃﻤﺎﻡ ﺨﺎﻨﺔ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ Signﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ Ok Pairs Listﻭﻤﻥ ﺜﻡ ﻨﻀﻊ ﻋﻼﻤﺔ 111
112.
ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ ﻴﻅﻬﺭ
ﺍﻟﻨﺎﺘﺞ ﺍﻋﻼﻩ ﻨﻭﺍﺘﺞ ﺘﻁﺒﻴﻕ ﺍﻻﺨﺘﺒﺎﺭ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻲ ) (NPar=Non-Parametricﻭﻴﺘﻜﻭﻥ ﻤﻥ ﺠﺩﻭﻟﻴﻥ ﻭﻫﻤﺎ ﺠﺩﻭل ﺍﻟﺘﻜﺭﺍﺭﺍﺕ ﺍﻟﻤﻌﻨﻭﻥ ﺒﻜﻠﻤﺔ Frequenciesﻭﺠﺩﻭل ﻨﺘﻴﺠﺔ ﺍﻻﺨﺘﺒﺎﺭ ﺍﻟﻤﻌﻨﻭﻥ ﺒـ Statistics Testﻭﻫﻤﺎ ﻜﺎﻟﺘﺎﻟﻲ ﺍﻟﺠﺩﻭل ﺍﻻﻭل ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ ﻭﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺍﻟﺴﺎﺒﻕ ﺃﻥ 01 ﺤﺎﻻﺕ ﻜﺎﻥ ﻓﻴﻬﺎ ﺩﺭﺠﺎﺕ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﺃﻜﺒﺭ ﻤﻥ ﺩﺭﺠﺎﺕ ﺍﻟﻠﻐﺔ ﺍﻻﻨﺠﻠﻴﺯﻴﺔ ﻭﻴﺭﻤﺯ ﻟﺫﻟﻙ ﺒﺎﻟﺭﻤﺯ ) (a. English<Arabicﺃﻭ Negative Differencesﻭﺃﻥ 8 211
113.
.(b
ﺤﺎﻻﺕ ﻜﺎﻨﺕ ﻓﻴﻬﺎ ﺩﺭﺠﺎﺕ ﺍﻟﻠﻐﺔ ﺍﻻﻨﺠﻠﻴﺯﻴﺔ ﺃﻜﺒﺭ ﻤﻥ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻭﺭﻤﺯ ﺫﻟﻙ ) English>Arabicﺃﻭ Positive Differencesﻭﻫﻲ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ ﻭﺃﻥ ﺤﺎﻟﺘﻴﻥ ﻓﻘﻁ ﻜﺎﻨﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻤﺎﺩﺘﻴﻥ ﻤﺘﺴﺎﻭﻴﺘﻴﻥ ﻭﺭﻤﺯ ﺫﻟﻙ ) (c. English=Arabicﺃﻭ .Ties ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ )Test Statistics (b English - Arabic )Exact Sig. (2-tailed ).815(a .a Binomial distribution used b Sign Test ﻭﻴﺒﻥ ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ ﺃﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ 518.0=) Exact Sig. (2-tailedﻭﻫﻲ ﺃﻜﺒﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﻟﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ 50.0 = αﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. ﺃﻱ ﺒﻤﻌﻨﻰ ﺃﻨﻪ ﻻ ﻴﻭﺠﺩ ﻓﺭﻕ ﺒﻴﻥ ﻭﺴﻴﻁ ﺍﻟﻤﺠﺘﻤﻌﻴﻥ ﺃﻭ ﺃﻥ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭﻱ ﺍﻟﻠﻐﺔ ﺍﻟﻌﺭﺒﻴﺔ ﻭﺍﻻﻨﺠﻠﻴﺯﻴﺔ ﻟﻬﻤﺎ ﻨﻔﺱ ﺍﻟﺘﻭﺯﻴﻊ. ﻤﻘﺎﺭﻨﺔ ﻤﻘﺎﻴﻴﺱ ﺍﻟﻨﺯﻋﺔ ﺍﻟﻤﺭﻜﺯﻴﺔ ﻟﻌﻴﻨﺘﻴﻥ ﻤﺭﺘﺒﻁﺘﻴﻥ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﺨﺘﺒﺎﺭ ب. ﻭﻟﻜﻜﺴﻥ ﻴﻌﺘﺒﺭ ﺍﺨﺘﺒﺎﺭ ﻭﻟﻜﻜﺴﻥ ﺍﻗﻭﻯ ﻤﻥ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ ﻓﻲ ﺘﻭﻀﻴﺢ ﻭﺘﺒﻴﺎﻥ ﺍﻟﻔﺭﻭﻕ ﺒﻴﻥ ﺘﻭﺯﻴﻊ ﺍﻟﻌﻴﻨﺎﺕ ﻭﺫﻟﻙ ﻷﻨﻪ ﻴﻌﺘﻤﺩ ﻋﻠﻰ ﺘﺭﺘﻴﺏ ﺍﻟﻔﺭﻭﻕ ﺒﻴﻥ ﺍﻟﻌﻴﻨﺘﻴﻥ . ﻤﺜﺎل 4: ﻴﻌﻁﻲ ﺍﻟﺠﺩﻭل ﺍﻟﺘﺎﻟﻲ ﻋﺩﺩ ﺍﻷﻤﻴﺎل ﺍﻟﺘﻲ ﺘﻘﻁﻌﻬﺎ ﻜل ﻤﻥ 21 ﺴﻴﺎﺭﺓ ﺒﺎﺴﺘﺨﺩﺍﻡ ﻨﻭﻋﻴﻥ ﻤﻥ ﺍﻟﻭﻗﻭﺩ Aﻭ.B 9.4 27.3 12.6 12.9 30.1 22.1 8.3 32.5 16.5 15.8 10.3 26.4 A 8.6 25.5 11.6 13.1 28.6 22.4 7.9 30.5 17.2 16.9 9.8 24.3 B ﻓﻬل ﻤﺘﻭﺴﻁ ﺍﻷﻤﻴﺎل ﺍﻟﺘﻲ ﺘﻘﻁﻌﻬﺎ ﺍﻟﺴﻴﺎﺭﺓ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﻭﻗﻭﺩ Aﺘﺴﺎﻭﻱ ﺍﻟﻤﺘﻭﺴﻁ ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﻭﻗﻭﺩ B ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = α؟ ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻻ ﻴﻭﺠﺩ ﻓﺭﻕ ﺒﻴﻥ ﻤﺘﻭﺴﻁ Aﻭ.B ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ: ﻴﻭﺠﺩ ﻓﺭﻕ ﺒﻴﻥ ﻤﺘﻭﺴﻁﺎﺕ Aﻭ.B 311
114.
1. ﻨﺩﺨل ﺒﻴﺎﻨﺎﺕ
ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﻤﻘﺭﺭﻴﻥ ﻓﻲ ﻋﻤﻭﺩﻴﻥ )ﻤﺘﻐﻴﺭﻴﻥ( ﻤﺨﺘﻠﻔﻴﻥ ﻨﺴﻤﻲ ﺍﻻﻭل ) (Aﻭﺍﻟﺜﺎﻨﻲ ) (Bﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 2. ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ ) Non-Parametric (Statisticsﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﺨﺘﺒﺎﺭ ﻋﻴﻨﺘﻴﻥ ﻤﺭﺘﺒﻁﺘﻴﻥ )(2 Related Samples 411
115.
3. ﻨﺨﺘﺎﺭ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ
) (Aﻭ) (Bﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ ﺍﻟﺴﻬﻡ ﻟﻴﻨﺘﻘﻼ ﺇﻟﻰ ﺨﺎﻨﺔ Test Pairs ﺃﻤﺎﻡ ﺨﺎﻨﺔ ﺍﺨﺘﺒﺎﺭ ﻭﻟﻜﻜﺴﻥ Listﺃﻱ ﻗﺎﺌﻤﺔ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﻤﺨﺘﺒﺭﺓ ﻭﻤﻥ ﺜﻡ ﻨﻀﻊ ﻋﻼﻤﺔ Wilcoxon 4. ﻨﻀﻐﻁ ﻋﻠﻰ Okﻟﺘﻅﻬﺭ ﻨﺎﺘﺞ ﺍﻻﺨﺘﺒﺎﺭ 511
116.
ﺍﻟﻨﺘﺎﺌﺞ: ﺘﺘﻜﻭﻥ ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ
ﻭﻟﻜﻜﺴﻥ ﻤﻥ ﺠﺩﻭﻟﻴﻥ، ﺍﻷﻭل ﻴﺒﻴﻥ ﻤﻭﺍﺼﻔﺎﺕ ﺍﺨﺘﺒﺎﺭ ﻭﻟﻜﻜﺴﻥ ﻭﺍﻟﺜﺎﻨﻲ ﻴﺼﻑ ﻗﻴﻤﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻓﻲ ﺤﺎﻟﺔ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﻜﺒﻴﺭﺓ ﻭﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ. ﺍﻟﺠﺩﻭل ﺍﻷﻭل: ﻤﺘﻭﺴﻁ ﺍﻟﺭﺘﺏ ﻋﺩﺩ ﺍﻟﺤﺎﻻﺕ ﻤﺠﻤﻭﻉ ﺍﻟﺭﺘﺏ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻭﻟﻜﻜﺴﻥ 611
117.
ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ
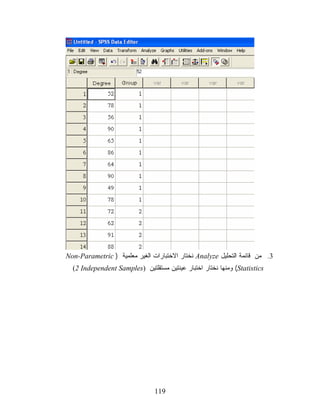
ﺃﻥ ﻋﺩﺩ ﺍﻟﺤﺎﻻﺕ ﺍﻟﻜﻠﻲ ﻫﻭ 21 ﻤﻨﻬﻡ 8 ﺤﺎﻻﺕ ﻜﺎﻥ ﻓﻴﻬﺎ ﺭﺘﺏ ﻗﻴﻡ ﺍﻟﻤﺘﻐﻴﺭ B ﺃﻗل ﻤﻥ ﺭﺘﺏ ﻗﻴﻡ Aﻭﻜﺎﻥ ﻤﺘﻭﺴﻁ ﺭﺘﺏ ﻫﺫﻩ ﺍﻟﺤﺎﻻﺕ ﻫﻭ 57.7 ﺒﻤﺠﻤﻭﻉ ﺭﺘﺏ 26 ﻭﻴﺭﻤﺯ ﻟﺫﻟﻙ ﺒﺎﻟﺭﻤﺯ ) (a. B<Aﺃﻭ ،Negative Ranksﻭﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻴﻀﺎ ﺃﻥ ﻫﻨﺎﻙ 4 ﺤﺎﻻﺕ ﻜﺎﻨﺕ ﻓﻴﻬﺎ ﺭﺘﺏ ﻗﻴﻡ ﺍﻟﻤﺘﻐﻴﺭ Bﺃﻜﺒﺭ ﻤﻥ ، Aﻭﻤﺘﻭﺴﻁ ﺘﻠﻙ ﺍﻟﺭﺘﺏ 4 ﻭﺒﻤﺠﻤﻭﻉ ﺍﻟﺭﺘﺏ ﻫﻭ 61 ﻭﺭﻤﺯ ﺫﻟﻙ ﻓﻲ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ) (b. B>Aﺃﻭ Positive Ranksﻭﺃﻨﻪ ﻻ ﺘﻭﺠﺩ ﺤﺎﻻﺕ ﻜﺎﻨﺕ ﺭﺘﺏ ﻗﻴﻡ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ ﻤﺘﺴﺎﻭﻴﺔ ﻭﺭﻤﺯ ﺫﻟﻙ ) (c. A=Bﺃﻭ .Ties ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ: ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﻜﺒﻴﺭﺓ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻭﻟﻜﻜﺴﻥ ﻓﻲ ﺤﺎﻟﺔ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﻜﺒﻴﺭﺓ ﻤﻌﺘﻤﺩﺍ ﻋﻠﻰ ﺘﻘﺭﻴﺏ ﺍﺨﺘﺒﺎﺭ Z ﹰ ﺍﻟﻁﺒﻴﻌﻲ ﻭﻫﻲ -408.1 ﻭ ﻓﻲ ﺍﻟﻨﻬﺎﻴﺔ ﻻﺤﻅ ﺃﻥ ﺃﻗل ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ .Asymp 170.0=) Sig. (2- tailedﻭﻫﻲ ﺃﻜﺒﺭ ﻤﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 50.0 = α ﻭﺒﺎﻟﺘﺎﻟﻲ ﻻ ﻨﺴﺘﻁﻴﻊ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. 711
118.
3. ﺍﺨﺘﺒﺎﺭ ﻤﺎﻥ-ﻭﻴﺘﻨﻲ
ﻟﻠﻤﻘﺎﺭﻨﺔ ﺒﻴﻥ ﻭﺴﻴﻁ ﻤﺠﺘﻤﻌﻴﻥ ﻤﺴﺘﻘﻠﻴﻥ. Mann Whitney Test ﻴﺴﺘﺨﺩﻡ ﻫﺫﺍ ﺍﻻﺨﺘﺒﺎﺭ ﻋﻨﺩﻤﺎ ﻻ ﺘﺘﻭﺍﻓﺭ ﺸﺭﻭﻁ ﺍﺴﺘﺨﺩﺍﻡ ﺍﺨﺘﺒﺎﺭ Tﻟﻠﻌﻴﻨﺎﺕ ﺍﻟﻤﺴﺘﻘﻠﺔ، ﺃﻱ ﺃﻥ ﻴﻜﻭﻥ ﺘﻭﺯﻴﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺘﻭﺯﻴﻌﺎ ﻁﺒﻴﻌﻴﺎ ﺃﻭ ﺃﻥ ﺘﻜﻭﻥ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺘﻭﻓﺭﺓ ﻫﻲ ﺭﺘﺏ ﺍﻟﻘﻴﻡ ﻭﻟﻴﺴﺕ ﻗﻴﻤﻬﺎ، ﻭﻋﻠﻴﻪ ﹰ ﹰ ﻓﺈﻥ ﺍﺨﺘﺒﺎﺭ Tﻻ ﻴﻌﻤل ﻓﻲ ﻫﻜﺫﺍ ﺤﺎﻻﺕ ﻤﻤﺎ ﺘﻀﻁﺭ ﻻﺴﺘﺨﺩﺍﻡ ﺍﺨﺘﺒﺎﺭ ﻤﺎﻥ ﻭﻴﺘﻨﻲ، ﺤﻴﺙ ﺃﻨﻪ ﻴﻌﺘﻤﺩ ﻓﻲ ﻋﻤﻠﻪ ﻋﻠﻰ ﺭﺘﺏ ﺍﻟﻘﻴﻡ. ﻤﺜﺎل 5: ﻻﺠﺭﺍﺀ ﺍﺨﺘﺒﺎﺭ ﻟﻤﺠﻤﻭﻋﺔ ﻜﺒﻴﺭﺓ ﻤﻥ ﺍﻟﻁﻠﺒﺔ، ﻗﺎﻡ ﺍﻟﻤﺩﺭﺱ ﺒﻭﻀﻊ ﻤﺠﻤﻭﻋﺘﻴﻥ ﻤﻥ ﺍﻻﺴﺌﻠﺔ ﺃﻋﻁﻰ ﺍﻟﻤﺠﻤﻭﻋﺔ ﻟﻠﻁﻠﺒﺔ ﺍﻷﻭﻟﻰ ﺍﻟﺫﻴﻥ ﻴﺠﻠﺴﻭﻥ ﻋﻠﻰ ﺍﻟﻤﻘﺎﻋﺩ ﺫﺍﺕ ﺍﻻﺭﻗﺎﻡ ﺍﻟﻔﺭﺩﻴﺔ، ﻭﺍﻟﻤﺠﻤﻭﻋﺔ ﺍﻟﺜﺎﻨﻴﺔ ﻟﻠﻁﻠﺒﺔ ﺍﻟﺫﻴﻥ ﻴﺠﻠﺴﻭﻥ ﻋﻠﻰ ﺍﻟﻤﻘﺎﻋﺩ ﺫﺍﺕ ﺍﻻﺭﻗﺎﻡ ﺍﻟﺯﻭﺠﻴﺔ. ﻫل ﻤﺠﻤﻭﻋﺘﺎ ﺍﻻﺴﺌﻠﺔ ﻤﺘﻜﺎﻓﺌﺔ ﺃﻡ ﻻ؟ ﻭﻻﺨﺘﺒﺎﺭ ﻫﺫﻩ ﺍﻟﻔﺭﻀﻴﺔ، ﻗﺎﻡ ﺍﻟﻤﺩﺭﺱ ﺒﺭﺼﺩ ﺒﻌﺽ ﺍﻟﻌﻼﻤﺎﺕ ﻤﻥ ﻜل ﻤﻥ ﺍﻟﻤﺠﻤﻭﻋﺘﻴﻥ ﻭﻜﺎﻨﺕ ﺍﻟﻌﻼﻤﺎﺕ ﻜﻤﺎ ﻴﻠﻲ: ﺍﻟﻤﺠﻤﻭﻋﺔ ﺍﻟﺜﺎﻨﻴﺔ ﺍﻟﻤﺠﻤﻭﻋﺔ ﺍﻷﻭﻟﻰ 27 25 26 87 19 65 88 09 09 56 47 68 89 46 08 09 18 94 17 87 ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻻ ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﺒﻴﻥ ﻤﺠﻤﻭﻋﺘﻲ ﺍﻻﺴﺌﻠﺔ. ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ : ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﺫﺍﺕ ﺩﻻﻟﺔ ﺍﺤﺼﺎﺌﻴﺔ ﻓﻲ ﺒﻴﻥ ﻤﺠﻤﻭﻋﺘﻲ ﺍﻻﺴﺌﻠﺔ. ﻋﻠﻰ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 1.0 = α 1. ﻨﻌﺭﻑ ﺍﻟﻤﺘﻐﻴﺭ) (Degreeﻟﺒﻴﺎﻨﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻭﺍﻟﻤﺘﻐﻴﺭ ) (Groupﻜﻤﺘﻐﻴﺭ ﻨﻭﻋﻲ ﻭﻟﻴﻜﻥ ﺍﻟﻜﻭﺩ ﻫﻭ ) ﺍﻟﻤﺠﻤﻭﻋﺔ ﺍﻻﻭﻟﻰ=1، ﺍﻟﻤﺠﻤﻭﻋﺔ ﺍﻟﺜﺎﻨﻴﺔ=2(. 2. ﻨﺩﺨل ﺒﻴﺎﻨﺎﺕ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ) (Degreeﺼﺎﺤﺏ ﺍﻟﺩﺭﺠﺔ ﻤﻥ ﺃﻱ ﺍﻟﻤﺠﻤﻭﻋﺎﺕ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ) (Groupﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ. 811
119.
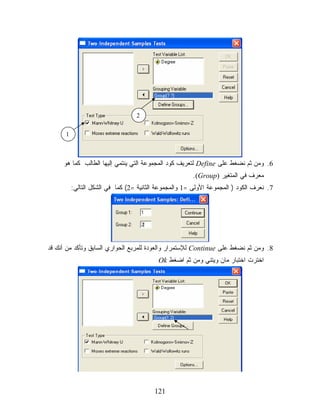
3. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ ) Non-Parametric (Statisticsﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﺨﺘﺒﺎﺭ ﻋﻴﻨﺘﻴﻥ ﻤﺴﺘﻘﻠﺘﻴﻥ )(2 Independent Samples 911
120.
4. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 5. ﻨﻨﻘل ﻋﺒﺭ ﺍﻟﺴﻬﻡ ﻤﺘﻐﻴﺭ ﺍﻟﺩﺭﺠﺎﺕ ) (Degreeﺇﻟﻰ ﺨﺎﻨﺔ Test Variable Listﻭﻤﺘﻐﻴﺭ ﺍﻟﻤﺠﻤﻭﻋﺔ ) (Groupﻟﻠﺨﺎﻨﺔ .Grouping Variable 021
121.
2
1 6. ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ Defineﻟﺘﻌﺭﻴﻑ ﻜﻭﺩ ﺍﻟﻤﺠﻤﻭﻋﺔ ﺍﻟﺘﻲ ﻴﻨﺘﻤﻲ ﺇﻟﻴﻬﺎ ﺍﻟﻁﺎﻟﺏ ﻜﻤﺎ ﻫﻭ ﻤﻌﺭﻑ ﻓﻲ ﺍﻟﻤﺘﻐﻴﺭ ).(Group 7. ﻨﻌﺭﻑ ﺍﻟﻜﻭﺩ ) ﺍﻟﻤﺠﻤﻭﻋﺔ ﺍﻷﻭﻟﻰ =1 ﻭﺍﻟﻤﺠﻤﻭﻋﺔ ﺍﻟﺜﺎﻨﻴﺔ =2( ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 8. ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ Continueﻟﻺﺴﺘﻤﺭﺍﺭ ﻭﺍﻟﻌﻭﺩﺓ ﻟﻠﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺴﺎﺒﻕ ﻭﺘﺄﻜﺩ ﻤﻥ ﺃﻨﻙ ﻗﺩ ﺍﺨﺘﺭﺕ ﺍﺨﺘﺒﺎﺭ ﻤﺎﻥ ﻭﻴﺘﻨﻲ ﻭﻤﻥ ﺜﻡ ﺍﻀﻐﻁ Ok 121
122.
ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ ﻤﺎﻥ-
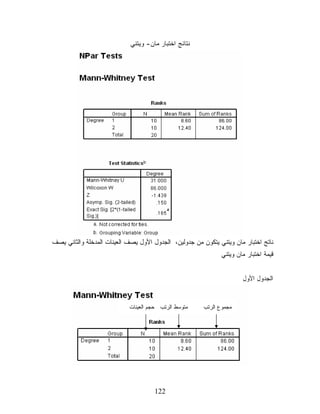
ﻭﻴﺘﻨﻲ ﻨﺎﺘﺞ ﺍﺨﺘﺒﺎﺭ ﻤﺎﻥ ﻭﻴﺘﻨﻲ ﻴﺘﻜﻭﻥ ﻤﻥ ﺠﺩﻭﻟﻴﻥ، ﺍﻟﺠﺩﻭل ﺍﻷﻭل ﻴﺼﻑ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﻤﺩﺨﻠﺔ ﻭﺍﻟﺜﺎﻨﻲ ﻴﺼﻑ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻤﺎﻥ ﻭﻴﺘﻨﻲ ﺍﻟﺠﺩﻭل ﺍﻷﻭل ﻤﺘﻭﺴﻁ ﺍﻟﺭﺘﺏ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺎﺕ ﻤﺠﻤﻭﻉ ﺍﻟﺭﺘﺏ 221
123.
ﻴﺼﻑ ﺍﻟﺠﺩﻭل ﺍﻷﻭل
ﺍﻟﻌﻴﻨﺘﻴﻥ ﺤﻴﺙ ﻴﻅﻬﺭ ﻟﻨﺎ ﺃﻥ ﺤﺠﻡ ﻋﻴﻨﺔ ﺍﻟﻤﺠﻤﻭﻋﺔ ﺍﻷﻭﻟﻰ 01 ﻭﻤﺘﻭﺴﻁ ﺭﺘﺒﻬﻡ 6.8 ﻭﻤﺠﻤﻭﻉ ﻫﺫﻩ ﺍﻟﺭﺘﺏ 68، ﺃﻤﺎ ﺒﺎﻟﻨﺴﺒﺔ ﻟﻠﻤﺠﻤﻭﻋﺔ ﺍﻟﺜﺎﻨﻴﺔ ﻓﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ 01 ﻭﻤﺘﻭﺴﻁ ﺍﻟﺭﺘﺏ 4.21 ﺒﻤﺠﻤﻭﻉ ﻗﺩﺭﻩ 421 ﻭﺃﻥ ﺍﻟﻌﻴﻨﺔ ﺍﻟﻜﻠﻴﺔ 02. ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻤﺎﻥ ﻭﻴﺘﻨﻲ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻤﺎﻥ ﻭﻴﺘﻨﻲ ﻫﻲ 13. ﻭﺃﺨﻴﺭﺍ ﺒﺎﻟﻨﺴﺒﺔ ﻟﻘﺒﻭل ﺃﻭ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﹰ ﺍﻟﺼﻔﺭﻴﺔ ﻓﻤﻥ ﺍﻟﻭﺍﻀﺢ ﺃﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ 051.0= )Asymp. Sig. (2-tailed ﻭﻫﻲ ﺍﻜﺒﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 50.0 = αﻭﺒﺎﻟﺘﺎﻟﻲ ﻻ ﻨﺴﺘﻁﻴﻊ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ. 321
124.
4. ﺍﺨﺘﺒﺎﺭ ﻜﺭﻭﺴﻜﺎل-ﻭﺍﻻﺱ
ﻟﻤﻘﺎﺭﻨﺔ ﺘﻭﺯﻴﻊ ﻋﺩﺓ ﻤﺠﺘﻤﻌﺎﺕ ﻤﺴﺘﻘﻠﺔ -Kruskal Wallis ﻴﻌﺘﺒﺭ ﺍﺨﺘﺒﺎﺭ ﻜﺭﻭﺴﻜﺎل ﻭﺍﻻﺱ ﺘﻌﻤﻴﻡ ﻻﺨﺘﺒﺎﺭ ﻤﺎﻥ ﻭﻴﺘﻨﻲ ﻭﻫﻭ ﻴﺴﺘﺨﺩﻡ ﻟﻤﻘﺎﺭﻨﺔ ﺘﻭﺯﻴﻊ 3 ﻋﻴﻨﺎﺕ ﻓﺄﻜﺜﺭ ﻤﻥ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ ﺍﻟﻤﺴﺘﻘﻠﺔ، ﻭﻋﺎﺩﺓ ﻤﺎ ﻴﻁﺒﻕ ﻋﻨﺩﻤﺎ ﻻ ﺘﺘﻭﺍﻓﺭ ﺸﺭﻭﻁ ﺘﻁﺒﻴﻕ ﺍﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻻﺤﺎﺩﻱ ﺃﻭ ﻋﻨﺩﻤﺎ ﺘﻜﻭﻥ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺘﻭﺍﻓﺭﺓ ﻫﻲ ﺒﻴﺎﻨﺎﺕ ﺘﺭﺘﻴﺒﻴﺔ ﻭﻫﻭ ﻴﻌﻤل ﻋﻠﻰ: 1. ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻭﻕ ﺒﻴﻥ ﻭﺴﻴﻁ 3 ﻋﻴﻨﺎﺕ ﻓﺄﻜﺜﺭ. 2. ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻭﻕ ﻓﻲ ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ. 3. ﺍﺨﺘﺒﺎﺭ ﻫل ﺍﻟﻤﺠﺘﻤﻌﺎﺕ ﻗﻴﺩ ﺍﻟﺩﺭﺍﺴﺔ ﻟﻬﺎ ﻨﻔﺱ ﺍﻟﺘﻭﺯﻴﻊ. 4. ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻭﻕ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ )ﺍﻥ ﺘﻌﺫﺭ ﺍﺴﺘﺨﺩﺍﻡ ﺍﻟﻁﺭﻕ ﺍﻟﻤﻌﻠﻤﻴﺔ(. ﻭﺘﻜﻭﻥ ﺍﻟﻔﺭﻀﻴﺎﺕ ﻜﻤﺎ ﻴﻠﻲ: 0 : Hﻻ ﻴﻭﺠﺩ ﻓﺭﻕ ﻓﻲ )ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ، ﻭﺴﻴﻁ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ، ﺘﻭﺯﻴﻊ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ(. : H aﻴﻭﺠﺩ ﻓﺭﻕ ﻓﻲ )ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ، ﻭﺴﻴﻁ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ، ﺘﻭﺯﻴﻊ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ(. ﻤﺜﺎل 6: ﻓﻲ ﺩﺭﺍﺴﺔ ﻟﻤﻘﺎﺭﻨﺔ ﻫل ﺘﻌﺘﻤﺩ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻋﻠﻰ ﺍﻟﺘﺨﺼﺹ ﻓﻲ ﻤﻘﺭﺭ ﻤﺒﺎﺩﺉ ﺍﻻﺤﺼﺎﺀ ﻗﺎﻡ ﻤﺩﺭﺱ ﺒﺎﻋﻁﺎﺀ ﺍﻤﺘﺤﺎﻥ ﻟﻤﺠﻤﻭﻋﺔ ﻤﻥ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﻤﻘﺭﺭ ﻭﻤﻥ ﺜﻡ ﺭﺼﺩ ﻤﺠﻤﻭﻋﺔ ﻤﻥ ﺍﻟﺩﺭﺠﺎﺕ ﻭﻜﺎﻨﺕ ﺍﻟﺩﺭﺠﺎﺕ ﺤﺴﺏ ﺍﻟﺘﺨﺼﺹ ﻜﻤﺎ ﻴﻠﻲ: ﺍﻟﺘﻨﻤﻴﺔ ﺍﻟﺘﺭﺒﻴﺔ ﺍﻟﺤﺎﺴﻭﺏ 08 09 05 07 56 07 57 55 56 13 04 04 04 57 08 53 03 54 59 58 24 07 55 53 09 08 56 56 57 89 54 55 56 26 06 56 57 09 58 87 47 03 86 58 04 77 88 28 09 59 ﻭﺍﻟﻤﻁﻠﻭﺏ ﺩﺭﺍﺴﺔ ﻤﺎ ﺇﺫﺍ ﺘﻭﺠﺩ ﻓﺭﻭﻕ ﺒﻴﻥ ﺘﻭﺯﻴﻊ ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﺍﻟﺘﺨﺼﺼﺎﺕ ﺍﻟﺜﻼﺜﺔ ﺃﻋﻼﻩ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = α؟ 0 : Hﻻ ﻴﻭﺠﺩ ﻓﺭﻭﻕ ﻓﻲ ﻭﺴﻴﻁ )ﺘﻭﺯﻴﻊ( ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﻡ. ﺍﻻﺤﺼﺎﺀ : H aﻴﻭﺠﺩ ﻓﺭﻭﻕ ﻓﻲ ﻭﺴﻴﻁ )ﺘﻭﺯﻴﻊ( ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﻓﻲ ﻤﻘﺭﺭ ﻡ. ﺍﻻﺤﺼﺎﺀ ﻭﻟﻠﻘﻴﺎﻡ ﺒﺫﻟﻙ ﺴﻨﻘﻭﻡ ﺒﺎﺨﺘﺒﺎﺭ ﻜﺭﻭﺴﻜﺎل-ﻭﻻﺱ ﻭﻴﺘﻤﺜل ﺫﻟﻙ ﺒﺎﻟﺨﻁﻭﺍﺕ ﺍﻟﺘﺎﻟﻴﺔ 421
125.
1. ﻨﺩﺨل ﺒﻴﺎﻨﺎﺕ
ﺩﺭﺠﺎﺕ ﺍﻟﻁﻼﺏ ﺒﻤﺘﻐﻴﺭ )ﺍﻟﺩﺭﺠﺔ( ﻭﻭﻤﺘﻐﻴﺭ )ﺍﻟﺘﺨﺼﺹ( ﻟﻴﺩل ﻋﻠﻰ ﻤﺼﺩﺭ ﺍﻟﺩﺭﺠﺔ ﻭﻟﻴﻜﻥ ﺍﻟﻜﻭﺩ ﻫﻭ ) ﺤﺎﺴﻭﺏ=1، ﺘﺭﺒﻴﺔ=2، ﺘﻨﻤﻴﺔ=3( ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ ﻤﻥ ﺃﻱ ﺍﻟﺘﺨﺼﺼﺎﺕ، ﻭﺫﻟﻙ ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 2. ﻤﻥ ﻗﺎﺌﻤﺔ ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ ) Non-Parametric (Statisticsﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﺨﺘﺒﺎﺭ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﻤﺴﺘﻘﻠﺔ )(k Independent Samples 521
126.
3. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 4. ﻭﻨﻨﻘل ﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺴﻬﻡ ﺍﻟﻤﺘﻐﻴﺭ )ﺍﻟﺩﺭﺠﺔ( ﺇﻟﻰ ﺨﺎﻨﺔ Test Variable Listﻭﻤﺘﻐﻴﺭ )ﺍﻟﺘﺨﺼﺹ( ﻟﻠﺨﺎﻨﺔ .Grouping Variable 621
127.
2
1 5. ﻨﻀﻊ ﻋﻼﻤﺔ ﻋﻠﻰ ﺨﺎﻨﺔ Kruskal-Wallis Hﺇﺫﺍ ﻟﻡ ﺘﻜﻥ ﻓﻲ ﺨﺎﻨﺘﻬﺎ ﻋﻼﻤﺔ،ﻭﻨﻀﻐﻁ ﻋﻠﻰ Defineﻟﺘﻌﺭﻴﻑ ﻤﺩﻯ ﻜﻭﺩ ﻤﺘﻐﻴﺭ )ﺍﻟﺘﺨﺼﺹ( ﻓﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ: 6. ﻨﻀﻊ ﺃﺼﻐﺭ ﻗﻴﻤﺔ ﻟﻜﻭﺩ ﻤﺘﻐﻴﺭ )ﺍﻟﺘﺨﺼﺹ( ﻭﻫﻲ 1 ﻭﺃﻋﻠﻰ ﻗﻴﻤﺔ ﻭﻫﻲ 3 ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺃﻋﻼﻩ ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ Continueﻟﻠﻌﻭﺩﺓ ﻟﻠﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺴﺎﺒﻕ ﻓﻴﺘﻐﻴﺭ ﺍﻟﺸﻜل ﻋﻠﻰ ﺍﻟﻨﺤﻭ ﺍﻟﺘﺎﻟﻲ: 7. ﻨﻼﺤﻅ ﻅﻬﻭﺭ ﺍﻻﺭﻗﺎﻡ 1 ﻭ3 ﺒﺠﺎﻨﺏ ﺍﻟﻤﺘﻐﻴﺭ )ﺍﻟﺘﺨﺼﺹ( ﻭﺫﻟﻙ ﺒﻨﺎﺀ ﻋﻠﻰ ﺍﻟﺘﻌﺭﻴﻑ ﺍﻟﺴﺎﺒﻕ ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ Okﻟﻴﻅﻬﺭ ﻨﺎﺘﺞ ﺍﻻﺨﺘﺒﺎﺭ ﻋﻠﻰ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 721
128.
ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ ﻜﺭﻭﺴﻜﺎل-
ﻭﺍﻻﺱ ﻴﺘﻜﻭﻥ ﺍﻟﻨﺎﺘﺞ ﻤﻥ ﺠﺩﻭﻟﻴﻥ ﺍﻻﻭل ﻭﻫﻭ ﺍﻟﺨﺎﺹ ﺒﻭﺼﻑ ﻨﺘﺎﺌﺞ ﺍﻟﻌﻴﻨﺎﺕ ﻭﺍﻟﺜﺎﻨﻲ ﻴﺤﺴﺏ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻜﺭﻭﺴﻜﺎل– ﻭﺍﻻﺱ ﺍﻟﺠﺩﻭل ﺍﻷﻭل )ﻭﺼﻑ ﺍﻟﻌﻴﻨﺎﺕ( ﺤﺠﻡ ﺍﻟﻌﻴﻨﺎﺕ ﻤﺘﻭﺴﻁ ﺍﻟﺭﺘﺏ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺍﻷﻭل ﻭﻫﻭ ﺍﻟﻤﻌﻨﻭﻥ Ranksﺤﺠﻡ ﺍﻟﻌﻴﻨﺎﺕ ﻭﻤﺘﻭﺴﻁ ﺭﺘﺏ ﻜل ﻋﻴﻨﺔ ﺤﻴﺙ ﻴﺒﻴﻥ ﺃﻥ ﺤﺠﻡ ﻋﻴﻨﺔ ﺍﻟﺤﺎﺴﻭﺏ ﻫﻭ 02 ﻭﻤﺘﻭﺴﻁ ﺭﺘﺏ ﺩﺭﺠﺎﺘﻬﻡ 57.03 ﺍﻤﺎ ﺤﺠﻡ ﻋﻴﻨﺎﺕ ﺍﻟﺘﺭﺒﻴﺔ ﻭﺍﻟﺘﻨﻤﻴﺔ ﻋﻠﻰ 821
129.
ﺍﻟﺘﻭﺍﻟﻲ ﻫﻡ 71
ﻭ31( ﺒﻤﺘﻭﺴﻁ ﺭﺘﺏ ﻗﺩﺭﻩ )14.22، 64.12( ﻭﻓﻲ ﺍﻟﻨﻬﺎﻴﺔ ﻤﺠﻤﻭﻉ ﺤﺠﻭﻡ ﺍﻟﻌﻴﻨﺎﺕ ﻫﻭ 05 ﺩﺭﺠﺔ. ﺜﺎﻨﻴﺎ: ﺠﺩﻭل ﺍﻟﻨﺘﺎﺌﺞ ﹰ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻜﺭﻭﺴﻜﺎل ﺩﺭﺠﺔ ﺤﺭﻴﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻴﺒﻴﻥ ﺠﺩﻭل ﺍﻟﻨﺘﺎﺌﺞ ﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻜﺭﻭﺴﻜﺎل-ﻭﺍﻻﺱ ﻫﻲ 473.4 ﺒﺩﺭﺠﺔ ﺤﺭﻴﺔ 2 )ﻋﺩﺩ ﺍﻟﻌﻴﻨﺎﺕ ﻨﺎﻗﺼﺎ 1( ﻭﺃﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ 211.0= . Asymp. Sigﺃﻱ ﺃﻜﺒﺭ ﻤﻥ ﻗﻴﻤﺔ ﹰ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ 50.0 = αﻭﺒﺎﻟﺘﺎﻟﻲ ﻻ ﺘﻭﺠﺩ ﻓﺭﻭﻕ ﻓﻲ ﺘﻭﺯﻴﻊ ﺩﺭﺠﺎﺕ ﺍﻟﺘﺨﺼﺼﺎﺕ ﺍﻟﺜﻼﺜﺔ. 921
130.
5. ﺍﺨﺘﺒﺎﺭ ﺍﻻﺴﺘﻘﻼﻟﻴﺔ ﻤﺜﺎل
7: ﻓﻲ ﺩﺭﺍﺴﺔ ﻟﻠﻌﻼﻗﺔ ﺒﻴﻥ ﺍﻟﺘﻘﺩﻴﺭ ﺍﻟﺫﻱ ﻴﺤﺼل ﻋﻠﻴﻪ ﺍﻟﻁﺎﻟﺏ ﻓﻲ ﺍﻟﺠﺎﻤﻌﺔ ﻭﺠﻨﺴﻪ ﺃﺨﺫﺕ ﻋﻴﻨﺔ ﻤﻥ ﻨﺘﺎﺌﺞ ﺍﻟﻁﻼﺏ ﺍﻟﺫﻜﻭﺭ ﻭ ﺍﻻﻨﺎﺙ ﻭﻜﺎﻨﺕ ﻜﻤﺎ ﻴﻠﻲ: ﺃﻭﻻ: ﺍﻻﻨﺎﺙ ﹰ ﻤﻤﺘﺎﺯ ﻤﻘﺒﻭل ﻤﻤﺘﺎﺯ ﺠﻴﺩ ﺠﺩﺍ ﺭﺍﺴﺏ ﺭﺍﺴﺏ ﺭﺍﺴﺏ ﺭﺍﺴﺏ ﺭﺍﺴﺏ ﻤﻘﺒﻭل ﻤﻘﺒﻭل ﻤﻘﺒﻭل ﺠﻴﺩ ﺠﻴﺩ ﺠﺩﺍ ﺠﻴﺩ ﺠﺩﺍ ﺠﻴﺩ ﺠﻴﺩ ﺠﺩﺍ ﺠﻴﺩ ﺠﺩﺍ ﺭﺍﺴﺏ ﻤﻘﺒﻭل ﻤﻘﺒﻭل ﻤﻘﺒﻭل ﺭﺍﺴﺏ ﻤﻘﺒﻭل ﺠﻴﺩ ﺠﻴﺩ ﺠﻴﺩ ﻤﻤﺘﺎﺯ ﺠﻴﺩ ﺠﺩﺍ ﻤﻤﺘﺎﺯ ﺠﻴﺩ ﺠﻴﺩ ﺠﻴﺩ ﻤﻤﺘﺎﺯ ﺠﻴﺩ ﺠﺩﺍ ﺜﺎﻨﻴﺎ: ﺍﻟﺫﻜﻭﺭ ﹰ ﺠﻴﺩ ﺠﺩﺍ ﺭﺍﺴﺏ ﺠﻴﺩ ﺠﺩﺍ ﺭﺍﺴﺏ ﺠﻴﺩ ﺠﻴﺩ ﺠﻴﺩ ﺭﺍﺴﺏ ﻤﻘﺒﻭل ﺭﺍﺴﺏ ﺭﺍﺴﺏ ﺭﺍﺴﺏ ﺭﺍﺴﺏ ﺭﺍﺴﺏ ﺠﻴﺩ ﺠﻴﺩ ﺠﺩﺍ ﻤﻤﺘﺎﺯ ﻤﻘﺒﻭل ﻤﻘﺒﻭل ﺭﺍﺴﺏ ﺭﺍﺴﺏ ﻤﻤﺘﺎﺯ ﻤﻤﺘﺎﺯ ﻤﻘﺒﻭل ﺠﻴﺩ ﺠﻴﺩ ﺭﺍﺴﺏ ﺭﺍﺴﺏ ﻤﻘﺒﻭل ﺠﻴﺩ ﺠﻴﺩ ﻤﻤﺘﺎﺯ ﻤﻤﺘﺎﺯ ﺠﻴﺩ ﺠﺩﺍ ﺠﻴﺩ ﻤﻤﺘﺎﺯ ﺠﻴﺩ ﺠﺩﺍ ﻭﺍﻟﻤﻁﻠﻭﺏ ﻫل ﺘﻭﺤﺩ ﻋﻼﻗﺔ ﺒﻴﻥ ﺘﻘﺩﻴﺭ ﺍﻟﻁﺎﻟﺏ ﻭﺠﻨﺴﻪ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = α؟ ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﺘﻘﺩﻴﺭ ﺍﻟﻁﺎﻟﺏ ﻻ ﻴﻌﺘﻤﺩ ﻋﻠﻰ ﺠﻨﺴﻪ )ﻤﺘﻐﻴﺭ ﺍﻟﺠﻨﺱ ﻭﺍﻟﺘﻘﺩﻴﺭ ﻤﺴﺘﻘﻼﻥ( ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ: ﺘﻘﺩﻴﺭ ﺍﻟﻁﺎﻟﺏ ﻴﻌﺘﻤﺩ ﻋﻠﻰ ﺠﻨﺴﻪ )ﺘﻭﺠﺩ ﻋﻼﻗﺔ ﺒﻴﻥ ﺠﻨﺱ ﺍﻟﻁﺎﻟﺏ ﻭﺘﻘﺩﻴﺭﻩ( 1. ﻨﻌﺭﻑ ﻤﺘﻐﻴﺭﻴﻥ ﻨﻭﻋﻴﻴﻥ ﻫﻤﺎ ) (Resultﻭ ) (Genderﻓﻲ ﺸﺎﺸﺔ ﺘﻌﺭﻴﻑ ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺒﺤﻴﺙ ﻴﻜﻭﻥ ﻜﻭﺩ ﻤﺘﻐﻴﺭ ) (Resultﻫﻭ )0= ﺭﺍﺴﺏ، 1=ﻤﻘﺒﻭل، 2=ﺠﻴﺩ، 3 ﺠﻴﺩ ﺠﺩﹰ، 4=ﻤﻤﺘﺎﺯ( ﺍ ﻭﻜﻭﺩ ﺍﻟﻤﺘﻐﻴﺭ ) (Genderﻫﻭ )1=ﺫﻜﺭ، 2=ﺍﻨﺜﻰ( 2. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 031
131.
3. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ ﻟﻺﺤﺼﺎﺀﺍﺕ ﺍﻟﻭﺼﻔﻴﺔ Descriptive Statisticsﻭﻤﻥ ﺜﻡ ﻨﺨﺘﺎﺭ ﺍﻷﻤﺭ Cross tabsﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ : 131
132.
4. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 2 1 5. ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭ Resultﻟﺨﺎﻨﺔ ﺍﻟﺼﻔﻭﻑ Rowsﻭﺍﻟﻤﺘﻐﻴﺭ Genderﻟﺨﺎﻨﺔ ﺍﻷﻋﻤﺩﺓ Columnsﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻷﺴﻬﻡ . 231
133.
6. ﻭﻤﻥ ﺜﻡ
ﻨﻀﻐﻁ ﻋﻠﻰ Statisticsﻟﻠﺤﺼﻭل ﻋﻠﻰ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 2 7. ﻨﻀﻊ ﻋﻼﻤﺔ ﻋﻠﻰ ﺨﺎﻨﺔ ﺍﺨﺘﺒﺎﺭ ﻤﺭﺒﻊ ﻜﺎﻱ Chi-Squareﻟﺤﺴﺎﺏ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺴﺘﻘﻼﻟﻴﺔ ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ ﻋﻠﻰ Continueﻟﻠﻌﻭﺩﺓ ﻟﻠﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺴﺎﺒﻕ 331
134.
8. ﻻﻅﻬﺎﺭ ﺠﺩﻭل
ﺍﻟﺘﻭﻗﻌﺎﺕ ﻨﻀﻐﻁ ﻋﻠﻰ ﺯﺭ Cellﻟﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 4 9. ﻨﺨﺘﺎﺭ ﺍﻟﺨﻴﺎﺭ Expectedﺠﺩﻭل ﺘﻭﻗﻌﺎﺕ ﻅﻬﻭﺭ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﻤﻥ ﺜﻡ ﻨﻀﻐﻁ Continue ﻟﻠﻌﻭﺩﺓ ﻟﻠﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺴﺎﺒﻕ. 431
135.
ﻨﻀﻐﻁ ﻋﻠﻰ
Okﻟﻠﺤﺼﻭل ﻋﻠﻰ ﺍﻟﻨﺘﺎﺌﺞ. 01. 531
136.
ﺍﻟﻨﺘﺎﺌﺞ 631
137.
ﺘﺘﻜﻭﻥ ﻨﺘﺎﺌﺞ ﺍﻷﻤﺭ
Cross tabulationﻤﻥ ﺜﻼﺜﺔ ﺠﺩﺍﻭل، ﺍﻷﻭل ﻴﺼﻑ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﻤﺩﺨﻠﺔ ﻭﻨﺴﺏ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﻔﻘﻭﺩﺓ، ﻭﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ ﻴﺒﻴﻥ ﺠﺩﻭل ﺘﻭﺯﻴﻊ ﺍﻟﻌﻴﻨﺔ ﺤﺴﺏ ﺍﻟﻤﺘﻐﻴﺭﻴﻥ ﻭﺍﻟﻘﻴﻡ ﺍﻟﻤﺘﻭﻗﻌﺔ ﺤﺴﺏ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺴﺘﻘﻼﻟﻴﺔ ﻭﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻟﺙ ﻴﺒﻴﻥ ﻨﺘﻴﺠﺔ ﺍﺨﺘﺒﺎﺭ ﻤﺭﺒﻊ ﻜﺎﻱ. ﻋﺩﺩ ﺍﻟﺫﻜﻭﺭ ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ: ﺍﻟﺭﺍﺴﺒﻴﻥ ﺘﻭﻗﻊ ﺍﻟﺫﻜﻭﺭ ﺍﻟﺭﺍﺴﺒﻴﻥ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺃﻥ ﻋﺩﺩ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺩﺨﻠﺔ 27، ﻋﺩﺩ ﺍﻟﺫﻜﻭﺭ 73 ) ﻤﻨﻬﻡ 21 ﺭﺍﺴﺏ ﻭﻗﻴﻤﺘﻬﺎ ﺍﻟﻤﺘﻭﻗﻌﺔ 67.9، 5 ﻤﻘﺒﻭل ﻭﻗﻴﻤﺘﻬﺎ ﺍﻟﻤﺘﻭﻗﻌﺔ 86.6، 9 ﺠﻴﺩ ﻭﻗﻴﻤﺘﻬﺎ ﺍﻟﻤﺘﻭﻗﻌﺔ 47.8، 5 ﺠﻴﺩﺠﺩﺍ ﻭﻗﻴﻤﺘﻬﺎ ﺍﻟﻤﺘﻭﻗﻌﺔ71.6 ، ﻭ6 ﻤﻤﺘﺎﺯ ﻭﻗﻴﻤﺘﻬﺎ ﺍﻟﻤﺘﻭﻗﻌﺔ56.5 ( ﻭﺍﻻﻨﺎﺙ 53 ) ﻤﻨﻬﻡ 7 ﺭﺍﺴﺏ ﻭﻗﻴﻤﺘﻬﺎ ﺍﻟﻤﺘﻭﻗﻌﺔ42.9 ، 8 ﻤﻘﺒﻭل ﻭﻗﻴﻤﺘﻬﺎ ﺍﻟﻤﺘﻭﻗﻌﺔ 23.6، 8 ﺠﻴﺩ ﻭﻗﻴﻤﺘﻬﺎ ﺍﻟﻤﺘﻭﻗﻌﺔ 62.8، 7 ﺠﻴﺩﺠﺩﺍ ﻭﻗﻴﻤﺘﻬﺎ ﺍﻟﻤﺘﻭﻗﻌﺔ 38.5، ﻭ5 ﻤﻤﺘﺎﺯ ﻭﻗﻴﻤﺘﻬﺎ ﺍﻟﻤﺘﻭﻗﻌﺔ53.5(. ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻟﺙ: ﺩﺭﺠﺔ ﺍﻟﺤﺭﻴﺔ ﻗﻴﻤﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ 731
138.
ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ
ﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻤﺭﺒﻊ ﻜﺎﻱ ﻫﻲ 734.2 ﺒﺩﺭﺠﺔ ﺤﺭﻴﺔ ﻤﻘﺎﺩﺭﻫﺎ 4 ﻗﺒﻭل ﻭﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺎﺕ ﻤﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼ ﻴﺘﺒﻴﻥ ﺃﻥ ﺃﻗل ﻗﻴﻤﺔ ﻟﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ﻫﻲ 656.0= )Asymp. Sig. (2-sided ﻭﻫﻲ ﺍﻜﺒﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 500.0 = αﻭﺒﺎﻟﺘﺎﻟﻲ ﻻ ﻨﺴﺘﻁﻴﻊ ﺭﻓﺹ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺃﻱ ﺃﻥ ﺘﻘﺩﻴﺭ ﺍﻟﻁﺎﻟﺏ ﻻ ﻴﻌﺘﻤﺩ ﻋﻠﻰ ﺠﻨﺴﻪ. 6. ﺍﺨﺘﺒﺎﺭ ﺠﻭﺩﺓ ﺍﻟﻤﻁﺎﺒﻘﺔ Goodness of Fit ﻴﻌﻁﻴﻙ ﺒﺭﻨﺎﻤﺞ SPSSﺍﻤﻜﺎﻨﻴﺔ ﻤﻘﺎﺭﻨﺔ ﺘﻭﺯﻴﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻤﻊ ﻋﺩﺓ ﺘﻭﺯﻴﻌﺎﺕ ﺍﻻﺤﺘﻤﺎﻟﻴﺔ ﻭﻫﻲ ﺍﻟﺘﻭﺯﻴﻊ ﺍﻟﻁﺒﻴﻌﻲ ﻭﺘﻭﺯﻴﻊ ﺒﻭﺍﺴﻭﻥ ﻭﺘﻭﺯﻴﻊ ﺍﻻﺴﻲ ﻭﺍﻟﻤﻨﺘﻅﻡ، ﺤﻴﺙ ﻴﻌﻤل ﻋﻠﻰ ﺩﺭﺍﺴﺔ ﺍﻟﻔﺭﻭﻕ ﺒﻴﻥ ﺘﻭﺯﻴﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﺩﺍﻟﺔ ﺍﻟﻜﺜﺎﻓﺔ ﺍﻻﺤﺘﻤﺎﻟﻴﺔ ﻟﻠﺘﻭﺯﻴﻌﺎﺕ ﺍﻷﺭﺒﻌﺔ ﺍﻟﻤﺨﺘﻠﻔﺔ. ﻤﺜﺎل 8: ﺘﻤﺜل ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﺘﺎﻟﻴﺔ ﻋﺩﺩ ﺍﻻﺸﺨﺎﺹ ﺍﻟﺫﻴﻥ ﺘﻨﺎﻭﻟﻭﺍ ﻁﻌﺎﻡ ﺍﻟﻌﺸﺎﺀ ﻓﻲ ﻤﻁﻌﻡ ﺼﻐﻴﺭ ﻋﻠﻰ ﻤﺩﻯ 05 ﻴﻭﻤﺎ: ﹰ 02 21 61 91 42 6 01 1 51 32 8 03 52 7 01 8 61 42 22 8 21 01 5 41 72 02 12 61 81 21 61 32 02 4 71 72 91 61 8 6 9 7 21 41 91 22 02 61 41 51 ﻴﺘﺒﻊ ﺍﻟﺘﻭﺯﻴﻊ ﺍﻟﻁﺒﻴﻌﻲ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺘﻨﺎﻭﻟﻭﺍ ﺍﻟﻌﺸﺎﺀ ﻓﻲ ﺍﻟﻤﻁﻌﻡ ﻓﻬل ﻤﺘﻐﻴﺭ ﻋﺩﺩ ﺍﻻﺸﺨﺎﺹ ﺍﻟﺫﻴﻥ ﺍﻟﺩﻻﻟﺔ 50.0 = α؟ ﺍﻟﺤل: ﺍﻟﻔﺭﻀﻴﺎﺕ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ: ﻤﺘﻐﻴﺭ ﻋﺩﺩ ﻋﺩﺩ ﺍﻻﺸﺨﺎﺹ ﺍﻟﺫﻴﻥ ﺘﻨﺎﻭﻟﻭﺍ ﺍﻟﻌﺸﺎﺀ ﻓﻲ ﺍﻟﻤﻁﻌﻡ ﻴﺘﺒﻊ ﺍﻟﺘﻭﺯﻴﻊ ﺍﻟﻁﺒﻴﻌﻲ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺒﺩﻴﻠﺔ: ﻋﺩﺩ ﺍﻻﺸﺨﺎﺹ ﺍﻟﺫﻴﻥ ﺘﻨﺎﻭﻟﻭﺍ ﺍﻟﻌﺸﺎﺀ ﻓﻲ ﺍﻟﻤﻁﻌﻡ ﻻ ﻴﺘﺒﻊ ﺍﻟﺘﻭﺯﻴﻊ ﺍﻟﻁﺒﻴﻌﻲ. 1. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﻤﺘﻐﻴﺭ ﻨﺴﻤﻴﻪ Dinnerﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 831
139.
2. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻟﻘﺎﺌﻤﺔ ﺍﻟﻔﺭﻋﻴﺔ ﺍﻻﺤﺼﺎﺀﺍﺕ ﺍﻟﻐﻴﺭ ﺒﺎﺭﺍﻤﺘﺭﻴﺔ -Non Parametric Testﻭﻤﻥ ﺜﻡ ﻨﺨﺘﺎﺭ ﺍﻷﻤﺭ 1-Sample K-S 931
140.
3. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 4. ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭ Dinnerﻟﺨﺎﻨﺔ Test Variable Listﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺴﻬﻡ ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 5. ﻴﻤﻜﻨﻙ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺃﻋﻼﻩ ﻤﻥ ﺍﺨﺘﻴﺎﺭ ﺍﻟﺘﻭﺯﻴﻊ ﺍﻟﺫﻱ ﺘﺭﻴﺩ ﺍﺨﺘﺒﺎﺭﻩ ﻫل ﻫﻭ ﺘﻭﺯﻴﻊ ﻁﺒﻴﻌﻲ Normalﺃﻭ ﺒﻭﺍﺴﻭﻥ Poissonﺃﻭ ﻤﻨﺘﻅﻡ Uniformﺃﻭ ﺃﺴﻲ Exponential ﻓﻨﺨﺘﺎﺭ ﺍﻟﺘﻭﺯﻴﻊ ﺍﻟﻁﺒﻴﻌﻲ ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺃﻋﻼﻩ ﻭﻨﻀﻐﻁ Okﻟﻠﺤﺼﻭل ﻋﻠﻰ ﺍﻟﻨﺘﺎﺌﺞ ﺍﻟﺘﺎﻟﻴﺔ : 041
141.
ﺍﻟﻨﺘﺎﺌﺞ: NPar Tests
ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ ﻤﺘﻭﺴﻁ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻻﻨﺤﺭﺍﻑ ﺍﻟﻤﻌﻴﺎﺭﻱ ﻟﻠﺒﻴﺎﻨﺎﺕ ﺃﻜﺒﺭ ﻓﺭﻕ ﺒﻴﻥ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﺩﺍﻟﺔ ﺍﻟﺘﻭﺯﻴﻊ ﺍﻻﺤﺘﻤﺎﻟﻴﺔ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺠﻭﺩﺓ ﺍﻟﻤﻁﺎﺒﻘﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﺘﺒﻴﻥ ﺍﻟﻨﺘﺎﺌﺞ ﺃﻋﻼﻩ ﺃﻥ ﻤﺘﻭﺴﻁ ﻋﺩﺩ ﺍﻟﺯﺒﺎﺌﻥ ﻫﻭ 62.51 ﺒﺎﻨﺤﺭﺍﻑ ﻤﻌﻴﺎﺭﻱ ﻗﺩﺭﻩ 287.6 ﻭﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺠﻭﺩﺓ ﺍﻟﻤﻁﺎﺒﻘﺔ ﻫﻭ 375.0. ﺍﻟﻘﺒﻭل ﻭﺍﻟﺭﻓﺽ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺍﻟﺴﺎﺒﻕ ﺃﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ 898.0= )Asymp. Sig. (2-tailed ﻭﻫﻲ ﺍﻜﺒﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ 50.0 = ، αﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ، ﺃﻱ ﺃﻥ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺘﺘﺒﻊ ﺍﻟﺘﻭﺯﻴﻊ ﺍﻟﻁﺒﻴﻌﻲ ﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﺴﺘﻨﺘﺞ ﺍﻥ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺘﺘﺒﻊ ﺍﻟﺘﻭﺯﻴﻊ ﺍﻟﻁﺒﻴﻌﻲ ﺒﻤﺘﻭﺴﻁ ﻗﺩﺭﻩ 62.51 ﻭﺍﻨﺤﺭﺍﻑ ﻤﻌﻴﺎﺭﻱ 287.6 ﺃﻱ ) 287.6 ,62.51( . X : N ﻤﺜﺎل 9: ﺍﺨﺘﺒﺭ ﻫل ﺘﻭﺯﻴﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﺍﻟﻤﺜﺎل ﺍﻟﺴﺎﺒﻕ ﻫﻭ ﺘﻭﺯﻴﻊ )ﺒﻭﺍﺴﻭﻥ، ﺍﺴﻲ( ﻨﻘﻭﻡ ﺒﺎﻟﺨﻁﻭﺍﺕ ﺍﻟﺴﺎﺒﻘﺔ ﻟﻜﻥ ﻨﺨﺘﺎﺭ ﺍﺨﺘﺒﺎﺭ ﺒﻭﺍﺴﻭﻥ Poisonﻭﺍﻻﺴﻲ Exponentialﻟﻨﺤﺼل ﻋﻠﻰ ﺍﻟﻨﺘﺎﺌﺞ ﺍﻟﺘﺎﻟﻴﺔ : 141
142.
ﺸﺭﺡ: ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ
ﺍﻥ ﻜﺎﻥ ﺘﻭﺯﻴﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻫﻭ ﺘﻭﺯﻴﻊ ﺒﻭﺍﺴﻭﻥ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ )ﻤﻌﺩل ﺒﻭﺍﺴﻭﻥ( ﺒﻨﺎﺀﺍ ﻋﻠﻰ ﺍﻟﺒﻴﺎﻨﺎﺕ ﹰ ﺃﻜﺒﺭ ﻓﺭﻕ ﺒﻴﻥ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﺩﺍﻟﺔ ﺍﻟﺘﻭﺯﻴﻊ ﺍﻻﺤﺘﻤﺎﻟﻴﺔ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺠﻭﺩﺓ ﺍﻟﻤﻁﺎﺒﻘﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻤﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﻴﺘﺒﻴﻥ ﺃﻥ ﻤﺘﻭﺴﻁ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻫﻭ 62.51 ﻭﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺠﻭﺩﺓ ﺍﻟﻤﻁﺎﺒﻘﺔ ﻫﻭ 963.1 ﻭﺃﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻭ 740.0 ﺃﺼﻐﺭ ﻤﻥ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ 50.0 = α ﺒﺎﻟﺘﺎﻟﻲ ﻨﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﺴﺘﻨﺘﺞ ﺍﻥ ﺘﻭﺯﻴﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻟﻴﺱ ﺘﻭﺯﻴﻊ ﺒﻭﺍﺴﻭﻥ. ﺸﺭﺡ: ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ ﺍﻥ ﻜﺎﻥ ﺘﻭﺯﻴﻊ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻫﻭ ﺘﻭﺯﻴﻊ ﺃﺴﻲ ﺤﺠﻡ ﺍﻟﻌﻴﻨﺔ )ﻤﻌﺩل ﺒﻭﺍﺴﻭﻥ(ﺒﻨﺎﺀﺍ ﻋﻠﻰ ﺍﻟﺒﻴﺎﻨﺎﺕ ﹰ ﺃﻜﺒﺭ ﻓﺭﻕ ﺒﻴﻥ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻭﺩﺍﻟﺔ ﺍﻟﺘﻭﺯﻴﻊ ﺍﻻﺤﺘﻤﺎﻟﻴﺔ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺠﻭﺩﺓ ﺍﻟﻤﻁﺎﺒﻘﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ 241
143.
7. ﺍﺨﺘﺒﺎﺭ ﺍﻟﻌﺸﻭﺍﺌﻴﺔ
Run Test ﻓﻲ ﻜﺜﻴﺭ ﻤﻥ ﺍﻻﺤﻴﺎﻥ ﻨﺤﺘﺎﺝ ﻟﺩﺭﺍﺴﺔ ﻜﻭﻥ ﺤﺩﻭﺙ ﻅﺎﻫﺭﺓ ﻤﻌﻴﻨﺔ ﻋﺸﻭﺍﺌﻴﺎ ﺍﻡ ﻻ؟ ﺃﻭ ﺍﻟﺒﺩﻴل ﻟﺫﻟﻙ ﻫل ﹰ ﺍﻟﻅﺎﻫﺭﺓ ﺘﺴﻴﺭ ﻭﻓﻕ ﻨﻅﺎﻡ ﻤﻌﻴﻥ، ﻭﻤﻥ ﺃﺠل ﺍﻟﻘﻴﺎﻡ ﺒﺫﻟﻙ ﻨﻁﺒﻕ ﻤﺎ ﻴﺴﻤﻰ ﺒﺎﺨﺘﺒﺎﺭ ﺍﻟﻌﺸﻭﺍﺌﻴﺔ. ﻤﺜﺎل 9: ﻟﻨﻔﺭﺽ ﺃﻥ ﻜﻤﺒﻴﻭﺘﺭ ﻴﻨﺘﺞ ﺃﺭﻗﺎﻡ ﻤﺨﺘﻠﻔﺔ، ﻭﻨﺭﻴﺩ ﻤﻌﺭﻓﺔ ﻫل ﺍﻨﺘﺎﺝ ﺍﻟﻜﻤﺒﻴﻭﺘﺭ ﻟﻸﺭﻗﻠﻡ ﺍﻟﺯﻭﺠﻴﺔ ﺃﻭ ﺍﻟﻔﺭﺩﻴﺔ ﻋﺸﻭﺍﺌﻴﺎ ﺃﻡ ﻻ، ﻓﺈﺫﺍ ﺒﺩﺃ ﺒﺭﻨﺎﻤﺞ ﺍﻟﻜﻤﺒﻴﻭﺘﺭ ﺒﺎﻟﻌﻤل ﻓﺎﻨﺘﺞ ﺍﻻﺭﻗﺎﻡ ﺍﻟﺘﺎﻟﻴﺔ: ﹰ 66656923927 87317518 78954653484743231165 ﻓﻬل ﺍﻨﺘﺎﺝ ﺍﻻﺭﻗﺎﻡ ﺍﻟﻔﺭﺩﻴﺔ ﺃﻡ ﻻ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = α؟ : H aﺍﻨﺘﺎﺝ ﺍﻻﺭﻗﺎﻡ ﺍﻟﻔﺭﺩﻴﺔ ﻤﻨﺘﻅﻡ 0 : Hﺍﻨﺘﺎﺝ ﺍﻻﺭﻗﺎﻡ ﺍﻟﻔﺭﺩﻴﺔ ﻋﺸﻭﺍﺌﻲ 1. ﻨﺩﺨل ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﻤﺘﻐﻴﺭ ﺍﺴﻤﻪ ). (Number 2. ﻨﻀﻊ ﺭﻤﺯ ﺍﻟﺒﻴﺎﻨﺎﺕ ﻓﻲ ﻤﺘﻐﻴﺭ Randomﺒﺤﻴﺙ ﻨﺭﻤﺯ ﻟﻸﺭﻗﺎﻡ ﺍﻟﻔﺭﺩﻴﺔ ﺒﺎﻟﺭﻤﺯ 1 ﻭﺍﻻﺭﻗﺎﻡ ﺍﻟﺯﻭﺠﻴﺔ ﺒﺎﻟﺭﻤﺯ 3 ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ 341
144.
3. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ ) Non-Parametric (Statisticsﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﺨﺘﺒﺎﺭ ﺍﻟﻌﺸﻭﺍﺌﻴﺔ Runsﻜﻤﺎ ﻴﻠﻲ: 4. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ 441
145.
5. ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭ
Randomﺇﻟﻰ ﺨﺎﻨﺔ Test Variable Listﻭﻤﻥ ﺜﻡ ﻨﻠﻐﻲ ﺍﻟﻌﻼﻤﺔ ﺍﻟﻤﻭﺠﻭﺩﺓ ﻓﻲ ﺨﺎﻨﺔ ﺍﻟﻭﺴﻴﻁ Medianﻭﻤﻥ ﺜﻡ ﻨﻀﻊ ﻋﻼﻤﺔ ﻓﻲ ﺨﺎﻨﺔ Customﻭﻓﻲ ﺍﻟﺨﺎﻨﺔ ﺍﻟﺘﻲ ﺒﺠﺎﻨﺒﻬﺎ ﻨﻀﻊ ﺭﻗﻡ 2 ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 2 1 ﻴﻌﻁﻴﻙ ﺍﻟﻤﺭﺒﻊ ﺍﻟﺤﻭﺍﺭﻱ ﺃﻋﻼﻩ ﺃﻥ ﺘﺩﺭﺱ ﻋﺸﻭﺍﺌﻴﺔ ﺍﻟﻅﺎﻫﺭﺓ ﺒﻘﻴﻡ ﺃﻜﺒﺭ ﻤﻥ ﺃﻭ ﺃﺼﻐﺭ ﻤﻥ )ﺍﻟﻭﺴﻴﻁ ﺍﻭ ﺍﻟﻭﺴﻁ ﺍﻟﺤﺴﺎﺒﻲ ﺃﻭ ﺍﻟﻤﻨﻭﺍل( ﻓﻨﺤﻥ ﺍﺨﺘﺭﻨﺎ ﻫﻨﺎ ﺍﻟﻁﺭﻴﻘﺔ ﺍﻻﺨﺘﻴﺎﺭﻴﺔ ﻭﻫﻲ ﺍﻻﻜﺜﺭ ﺍﺴﺘﺨﺩﺍﻤﺎ. ﹰ 6. ﻨﻀﻐﻁ ﻋﻠﻰ Okﻟﺘﻅﻬﺭ ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ ﺍﻟﺘﺎﻟﻴﺔ: ﻋﺩﺩ ﺍﻟﻤﺘﺘﺎﺒﻌﺎﺕ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ Zﻓﻲ ﺤﺎﻟﺔ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﻜﺒﻴﺭﺓ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺃﻥ ﻋﺩﺩ ﺍﻟﺤﺎﻻﺕ ﺍﻟﻤﺩﺨﻠﺔ ﻫﻭ 04 ﻭﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﺍﻟﻌﺸﻭﺍﺌﻴﺔ ﻓﻲ ﺤﺎﻟﺔ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﺼﻐﻴﺭﺓ )ﻋﺩﺩ ﺍﻟﻤﺘﺘﺎﺒﻌﺎﺕ( ﻫﻭ 42 ﻭﺃﻥ ﻗﻴﻤﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻓﻲ ﺤﺎﻟﺔ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﻜﺒﻴﺭﺓ ﻫﻭ 478.0 ﻭﺃﻥ ﺃﻗل ﻗﻴﻤﺔ ﻟﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻫﻭ 283.0 ﻭﻫﻭ ﺃﻜﺒﺭ ﻤﻥ 50.0 = αﻭﺒﺎﻟﺘﺎﻟﻲ ﻨﻘﺒل ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻭﻫﻲ ﺃﻥ ﺍﻟﻅﺎﻫﺭﺓ ﻋﺸﻭﺍﺌﻴﺔ. 541
146.
8. ﺍﺨﺘﺒﺎﺭ ﻓﺭﻴﺩﻤﺎﻥ
ﻟﻠﻤﻘﺎﺭﻨﺔ ﺒﻴﻥ ﻭﺴﻴﻁ ﻋﺩﺓ ﻤﺠﺘﻤﻌﺎﺕ ﻤﺭﺘﺒﻁﺔ Friedman Test ﻫﻭ ﺘﻌﻤﻴﻡ ﻻﺨﺘﺒﺎﺭ ﺍﻻﺸﺎﺭﺓ ﻟﻠﻌﻴﻨﺎﺕ ﺍﻟﻤﺭﺘﺒﻁﺔ ﻭﻫﻭ ﻤﺸﺎﺒﻪ ﻻﺨﺘﺒﺎﺭ ﺘﺤﻠﻴل ﺍﻟﺘﺒﺎﻴﻥ ﺍﻟﻤﻌﻠﻤﻲ ﻤﻥ ﺍﻟﻨﻭﻉ Repeated Measure Designﻭﻴﻁﺒﻕ ﻓﻲ ﺤﺎﻟﺔ ﻋﺩﻡ ﺘﻭﻓﺭ ﺸﺭﻭﻁ ﺘﻁﺒﻴﻕ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻤﻌﻠﻤﻴﺔ ﻭﻫﻭ ﻴﻌﻤل ﻋﻠﻰ ﺍﻟﻤﻘﺎﺭﻨﺔ ﻤﻥ ﺤﻴﺙ: 1. ﺍﻟﻔﺭﻭﻕ ﻓﻲ ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ. 2. ﻫل ﺍﻟﻤﺠﺘﻤﻌﺎﺕ ﻗﻴﺩ ﺍﻟﺩﺭﺍﺴﺔ ﻟﻬﺎ ﻨﻔﺱ ﺍﻟﺘﻭﺯﻴﻊ. 3. ﺍﺨﺘﺒﺎﺭ ﺍﻟﻔﺭﻭﻕ ﻓﻲ ﻤﺘﻭﺴﻁﺎﺕ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ. ﻭﺘﻜﻭﻥ ﺍﻟﻔﺭﻀﻴﺎﺕ ﻜﻤﺎ ﻴﻠﻲ: 0 : Hﻻ ﻴﻭﺠﺩ ﻓﺭﻕ ﻓﻲ ﺘﻭﺯﻴﻊ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ. : H aﻴﻭﺠﺩ ﻓﺭﻕ ﻓﻲ )ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ، ﻭﺴﻁ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ، ﺘﻭﺯﻴﻊ ﺍﻟﻤﺠﺘﻤﻌﺎﺕ(. ﻤﺜﺎل 01: ﻟﻨﻔﺭﺽ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﺘﺎﻟﻴﺔ ﺍﻟﺭﻗﻡ 1T 2T 3T .1 01 81 7 .2 21 91 8 .3 51 71 61 .4 31 41 21 .5 51 02 71 .6 21 51 01 .7 11 7 6 .8 31 81 11 .9 51 91 11 .01 7 31 21 .11 21 31 81 .21 01 8 5 ﺃﻋﻼﻩ ﻋﻨﺩ 50.0 = α؟ ﺍﺨﺘﺒﺭ ﻫل ﻴﻭﺠﺩ ﻓﺭﻕ ﻓﻲ ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ ﺍﻟﻤﺒﻴﻨﺔ ﻓﻲ ﺍﻟﺠﺩﻭل ﺍﻟﺤل: 0 : Hﻻ ﻴﻭﺠﺩ ﻓﺭﻕ ﻓﻲ ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ. : H aﻴﻭﺠﺩ ﻓﺭﻕ ﻓﻲ ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ. 1. ﻨﺩﺨل ﺒﻴﺎﻨﺎﺕ ﻜل ﻁﺭﻴﻘﺔ ﻤﻌﺎﻟﺠﺔ ﻓﻲ ﻤﺘﻐﻴﺭ ﺃﻭ ﻋﻤﻭﺩ ﻤﺴﺘﻘل، ﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 641
147.
2. ﻤﻥ ﻗﺎﺌﻤﺔ
ﺍﻟﺘﺤﻠﻴل Analyzeﻨﺨﺘﺎﺭ ﺍﻻﺨﺘﺒﺎﺭﺍﺕ ﺍﻟﻐﻴﺭ ﻤﻌﻠﻤﻴﺔ ) Non-Parametric (Statisticsﻭﻤﻨﻬﺎ ﻨﺨﺘﺎﺭ ﺍﺨﺘﺒﺎﺭ ﺍﻟﻌﻴﻨﺎﺕ ﺍﻟﻤﺭﺘﺒﻁﺔ )(k Related Samples 741
148.
3. ﻴﻅﻬﺭ ﺍﻟﻤﺭﺒﻊ
ﺍﻟﺤﻭﺍﺭﻱ ﺍﻟﺘﺎﻟﻲ : 4. ﻨﻨﻘل ﺍﻟﻤﺘﻐﻴﺭﺍﺕ ﺍﻟﺜﻼﺜﺔ ﺇﻟﻰ ﺍﻟﺨﺎﻨﺔ ﺨﺎﻨﺔ Test Variablesﺒﺎﺴﺘﺨﺩﺍﻡ ﺍﻟﺴﻬﻡ ﻭﻨﻀﻊ ﻋﻼﻤﺔ ﻋﻠﻰ ﺍﺨﺘﺒﺎﺭ Friedmanﻜﻤﺎ ﻓﻲ ﺍﻟﺸﻜل ﺍﻟﺘﺎﻟﻲ: 5. ﺒﺎﻟﻀﻐﻁ ﻋﻠﻰ Okﺘﻅﻬﺭ ﺠﺩﺍﻭل ﺍﻟﻨﺘﺎﺌﺞ ﺍﻟﺘﺎﻟﻴﺔ: 841
149.
ﻨﺘﺎﺌﺞ ﺍﺨﺘﺒﺎﺭ ﻓﺭﻴﺩﻤﺎﻥ
ﺸﺭﺡ ﺍﻟﻨﺘﺎﺌﺞ ﻴﺘﻜﻭﻥ ﻨﺎﺘﺞ ﺍﺨﺘﺒﺎﺭ ﻓﺭﻴﺩﻤﺎﻥ ﻤﻥ ﺠﺩﻭﻟﻴﻥ ﺍﻻﻭل ﻴﺒﻴﻥ ﺍﻟﻌﻴﻨﺔ ﻭﻤﺘﻭﺴﻁ ﺭﺘﺒﻬﺎ ﺍﻟﺠﺩﻭل ﺍﻻﻭل Friedman Test ﻁﺭﻕ ﺍﻟﻤﻌﺎﻟﺠﺔ ﻤﺘﻭﺴﻁ ﺭﺘﺏ ﺍﻟﻌﻴﻨﺎﺕ Ranks Mean Rank 1T 38.1 2T 57.2 3T 24.1 ﻴﺒﻴﻥ ﺍﻟﺠﺩﻭل ﺃﻋﻼﻩ ﺃﻥ ﻤﺘﻭﺴﻁ ﺭﺘﺒﺔ ﺍﻟﻌﻴﻨﺔ ﺍﻷﻭﻟﻰ ﻫﻭ 38.1 ﻭﺍﻟﺜﺎﻨﻴﺔ 57.2 ﻭﺍﻟﺜﺎﻟﺜﺔ 24.1 . 941
150.
ﺍﻟﺠﺩﻭل ﺍﻟﺜﺎﻨﻲ )Test Statistics
(a N 21 ﺤﺠﻡ ﺃﻱ ﻋﻴﻨﺔ Chi-Square 761.11 ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻓﺭﻴﺩﻤﺎﻥ df 2 ﺩﺭﺠﺔ ﺍﻟﺤﺭﻴﺔ .Asymp. Sig 400. ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ a Friedman Test ﻴﺒﻴﻥ ﺃﻥ ﻋﺩﺩ ﺍﻟﺒﻴﺎﻨﺎﺕ ﺍﻟﻤﺩﺨﻠﺔ ﻓﻲ ﻜل ﻋﻴﻨﺔ ﻫﻭ 21، ﻭﺃﻥ ﺩﺭﺠﺔ ﺍﻟﺤﺭﻴﺔ ﻫﻲ 2 )ﻋﺩﺩ ﺍﻟﻌﻴﻨﺎﺕ ﻨﺎﻗﺼﺎ ﻭﺍﺤﺩ(، ﻭﺃﻥ ﻗﻴﻤﺔ ﺍﺨﺘﺒﺎﺭ ﻓﺭﻴﺩﻤﺎﻥ ﻫﻲ 761.11، ﻭﺃﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻻﺨﺘﺒﺎﺭ ﻫﻲ ﹰ 400.0= . Asymp. Sigﻭﻫﻲ ﺃﺼﻐﺭ ﻤﻥ ﻗﻴﻤﺔ ﻤﺴﺘﻭﻯ ﺩﻻﻟﺔ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﺒﺎﻟﺘﺎﻟﻲ ﻨﺴﺘﻁﻴﻊ ﺭﻓﺽ ﺍﻟﻔﺭﻀﻴﺔ ﺍﻟﺼﻔﺭﻴﺔ ﻋﻨﺩ ﻤﺴﺘﻭﻯ ﺍﻟﺩﻻﻟﺔ 50.0 = . α 051
Download