





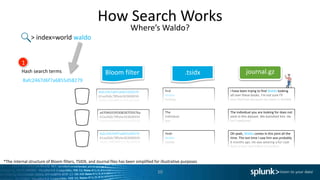
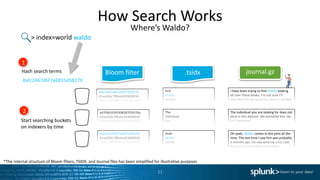
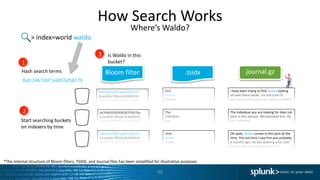
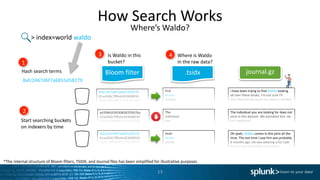




















![Command Abuse
Joins & Sub-searches
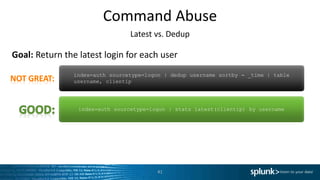
Goal: Return the latest JSESSIONID across two sourcetypes
42
sourcetype=access_combined OR sourcetype=applogs | stats latest(*) as *
by JSESSIONID
sourcetype=access_combined | join type=inner JSESSIONID [search
sourcetype=applogs | dedup JSESSIONID | table JSESSIONID,
clienip, othervalue]](https://image.slidesharecdn.com/searchperformance-150616192619-lva1-app6891/85/Splunk-Search-Optimization-42-320.jpg)








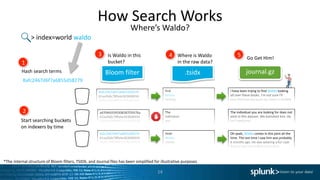
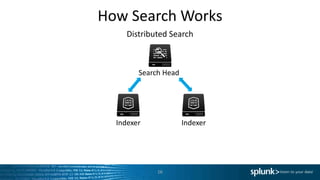
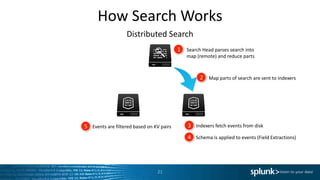
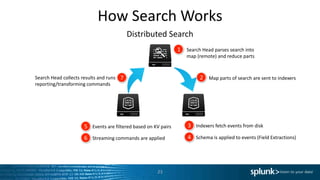
The document discusses search optimization techniques for Splunk, including an overview of its architecture, event storage, and search methodologies. It covers different types of searches, commands, and their implications on performance, alongside tips for efficient searching. The content is geared towards enhancing users' understanding of how to effectively leverage Splunk for data analysis.






















































































