







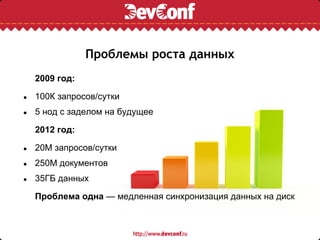



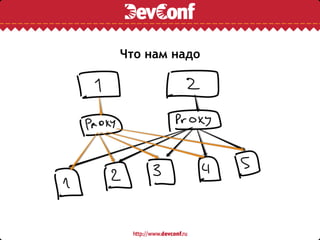











Документ описывает процесс решардинга Redis без даунтайма на примере проекта Avito, который обслуживает более 90 миллионов запросов в день. Основное внимание уделяется проблемам роста данных, медленной синхронизации и путям оптимизации системы с помощью прокси-решений и алгоритмов распределения ключей. В итоге, разработка новой архитектуры и корректировка кода потребовали двухнедельной работы в паре с администратором.



























































