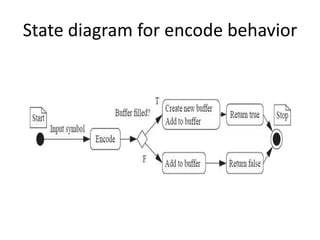
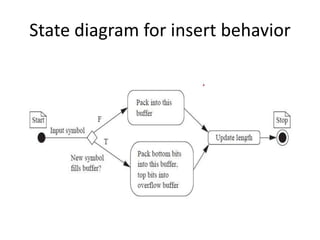
The document describes the architecture and requirements of a special purpose computing system data compressor, highlighting its process of encoding input symbols into variable-length output symbols using Huffman coding. It outlines the need for a new symbol table, methods for encoding and flushing buffers, and the class structures for managing data and symbols. Additionally, it addresses the complexity of decoding due to variable-length bit sequences and emphasizes the importance of encoding efficiency.