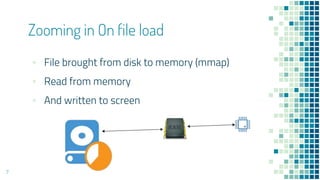
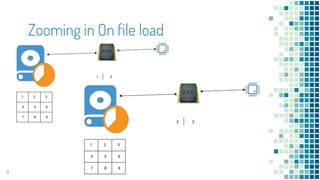
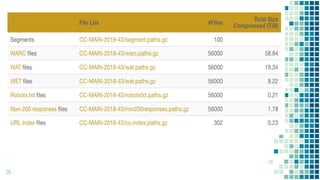
Spark is a framework for large-scale data processing across clusters of computers using an in-memory parallel processing technique called resilient distributed datasets (RDDs). It allows data to be processed in parallel using multiple CPU cores or multiple computers. Spark addresses limitations of single machine processing by enabling distributed, parallel data processing. It supports programming models like MapReduce that split jobs into independent tasks that can run in parallel on different nodes in a cluster.