程式分析流程
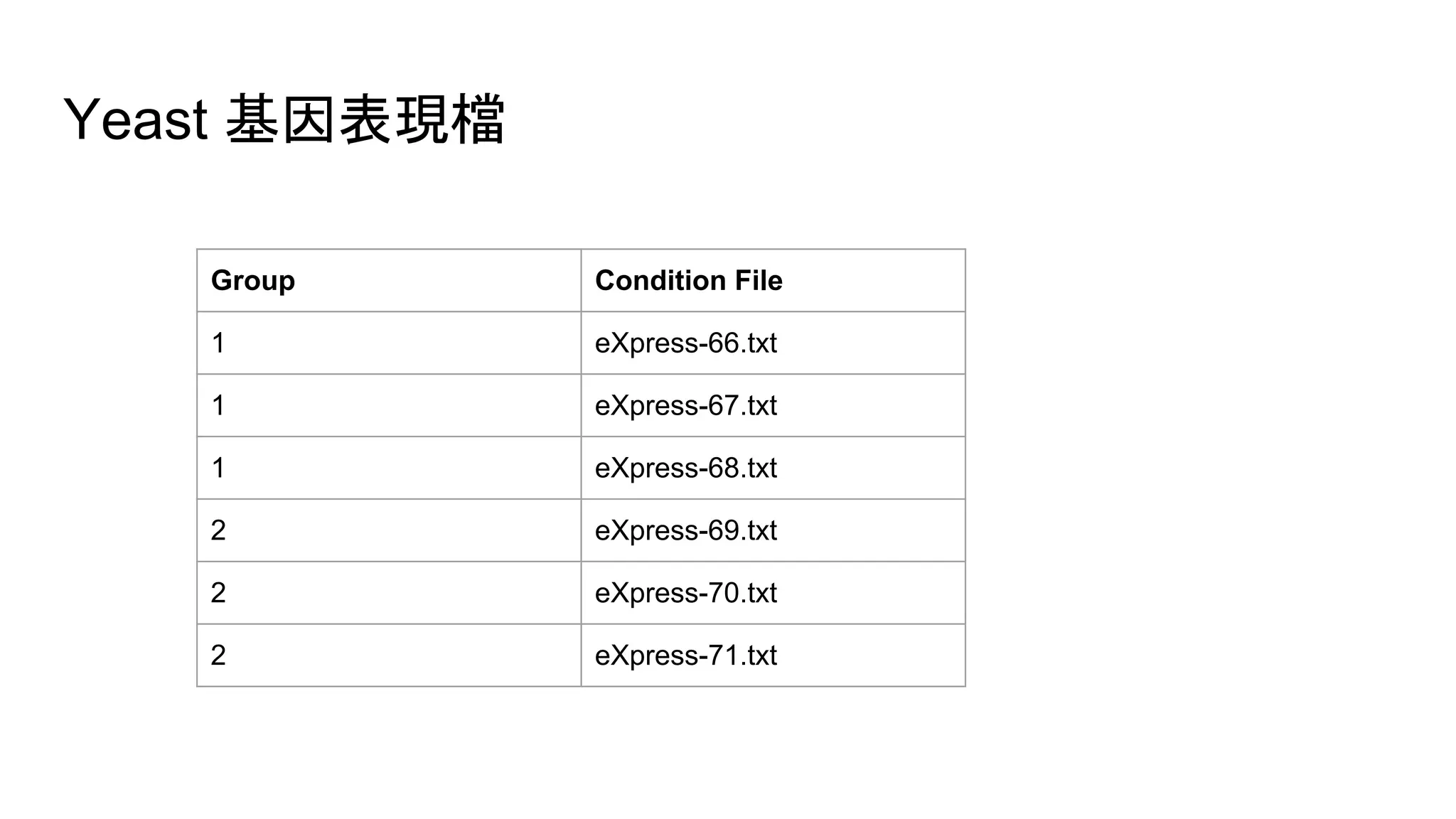
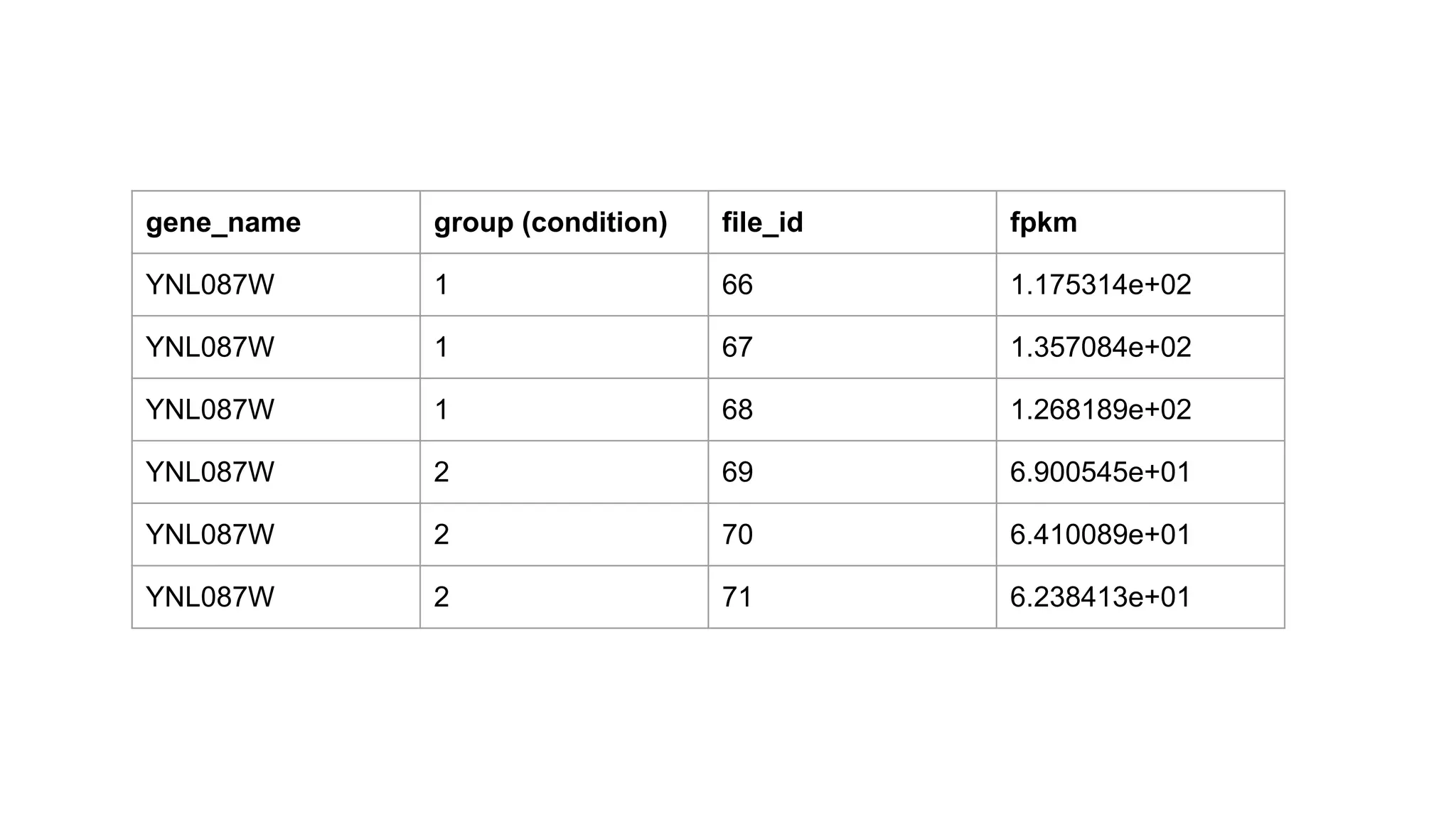
1. 建立 genename, group, condition 和 expression value 的對應表。
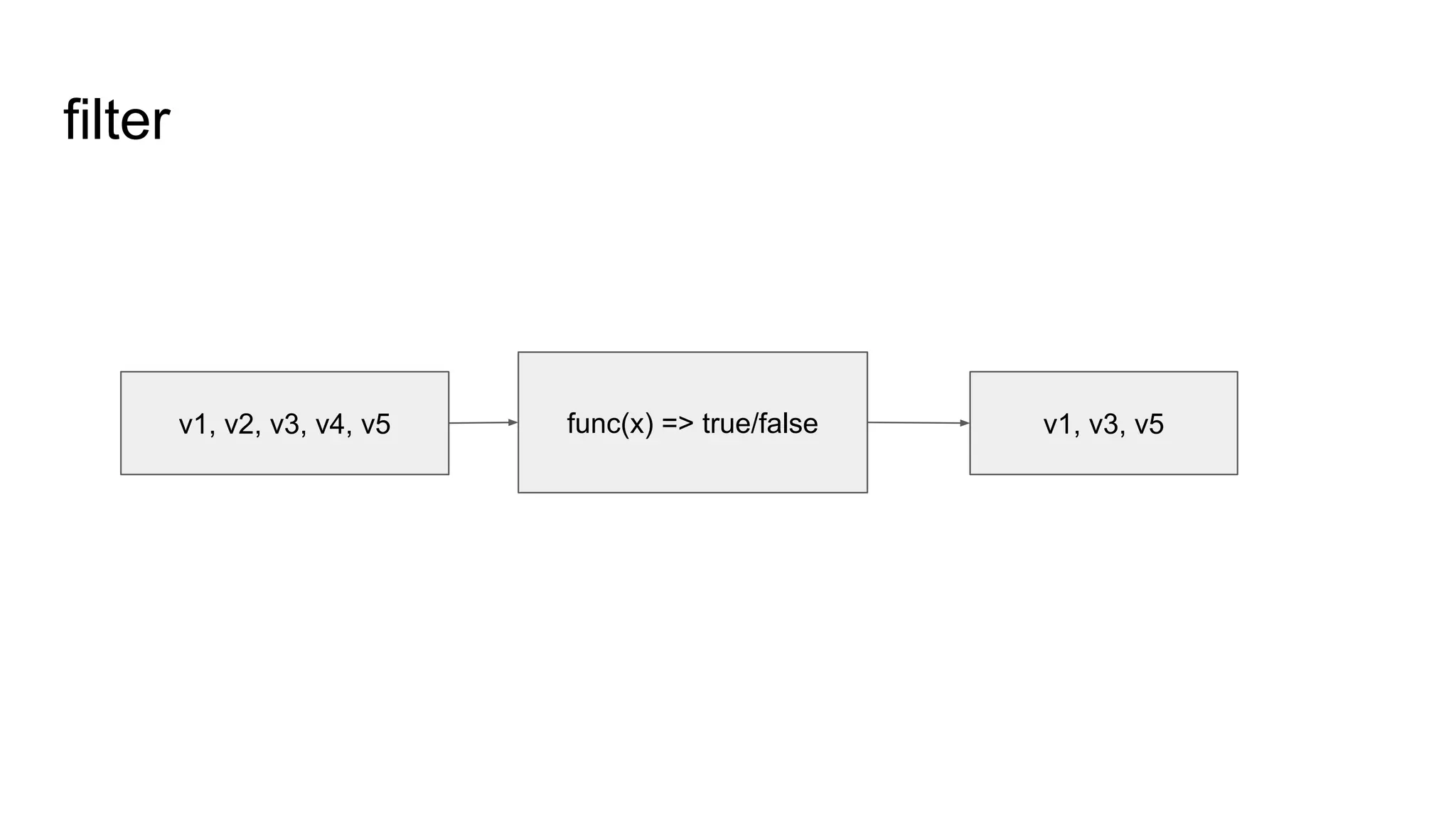
2. 根據每條 gene,計算:
a. c1 = merge(c1-1 to c1-3), c2 = merge(c2-1 to c2-3)
b. de = diff(c1, c2)
3. 輸出符合 de > t1 or de < t2 的 gene。
參考資料
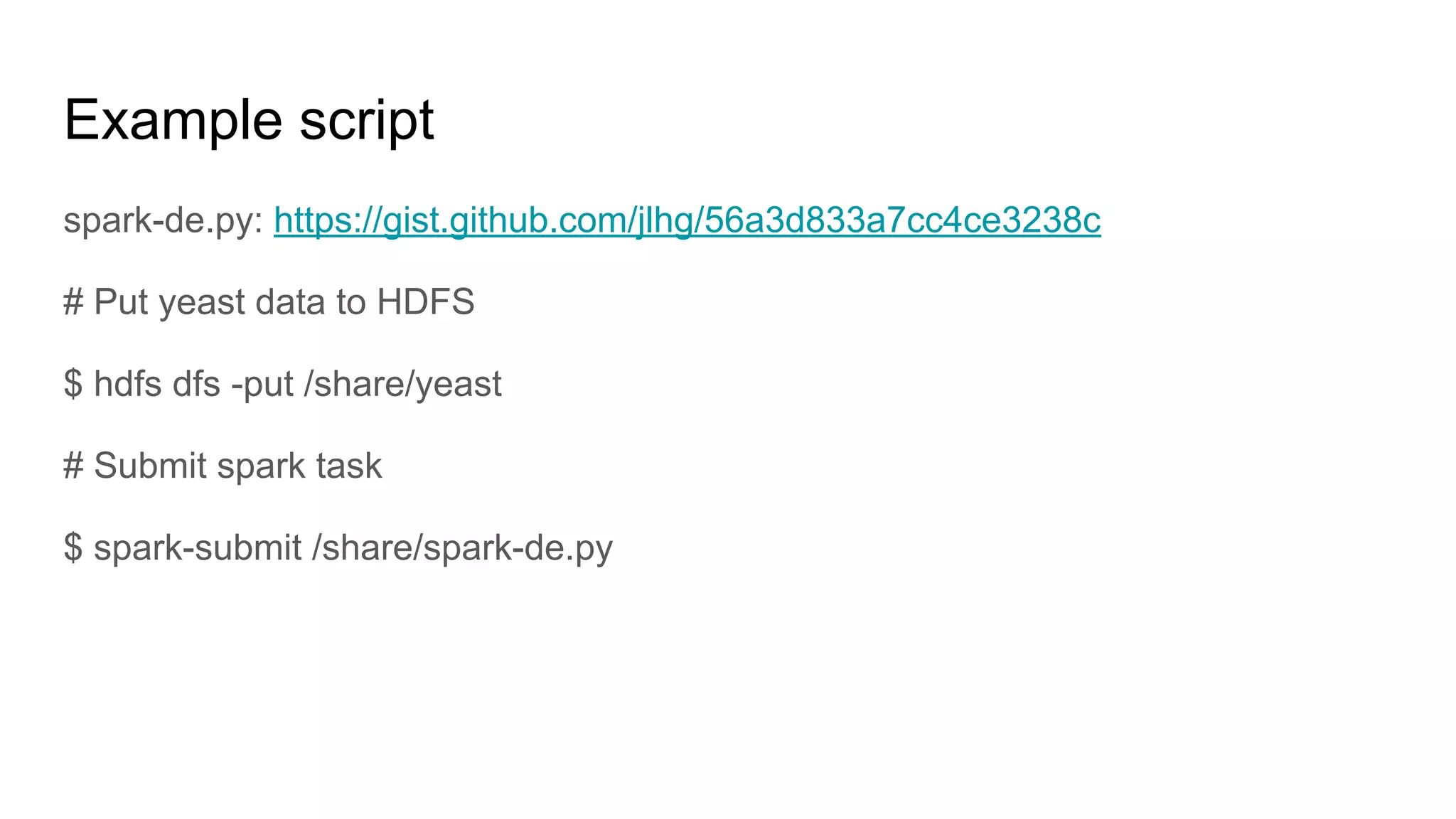
● Spark QuickStart (Official)
● Spark Programming Guide (Official)
● Spark 編程指南繁體中文版
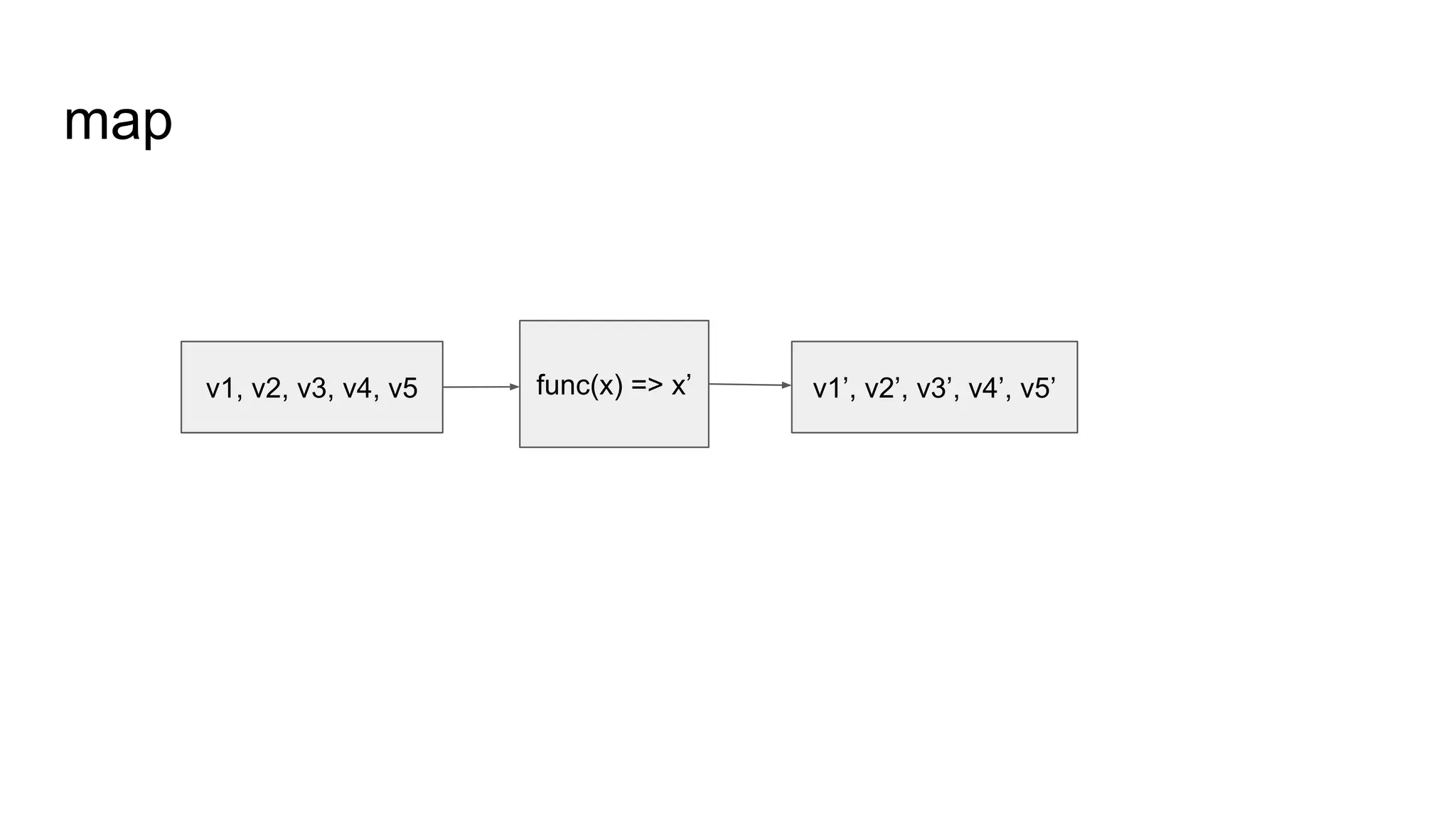
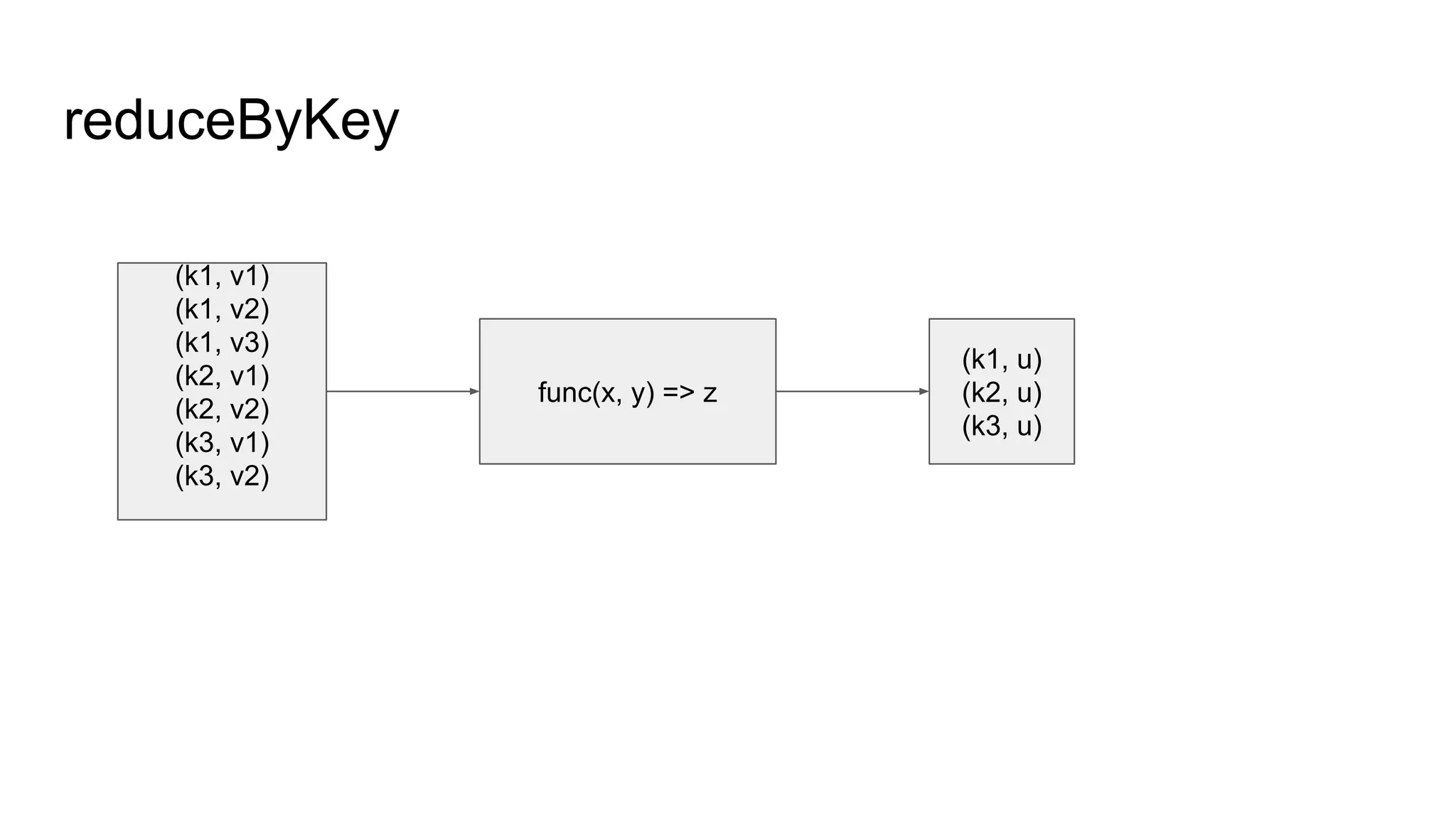
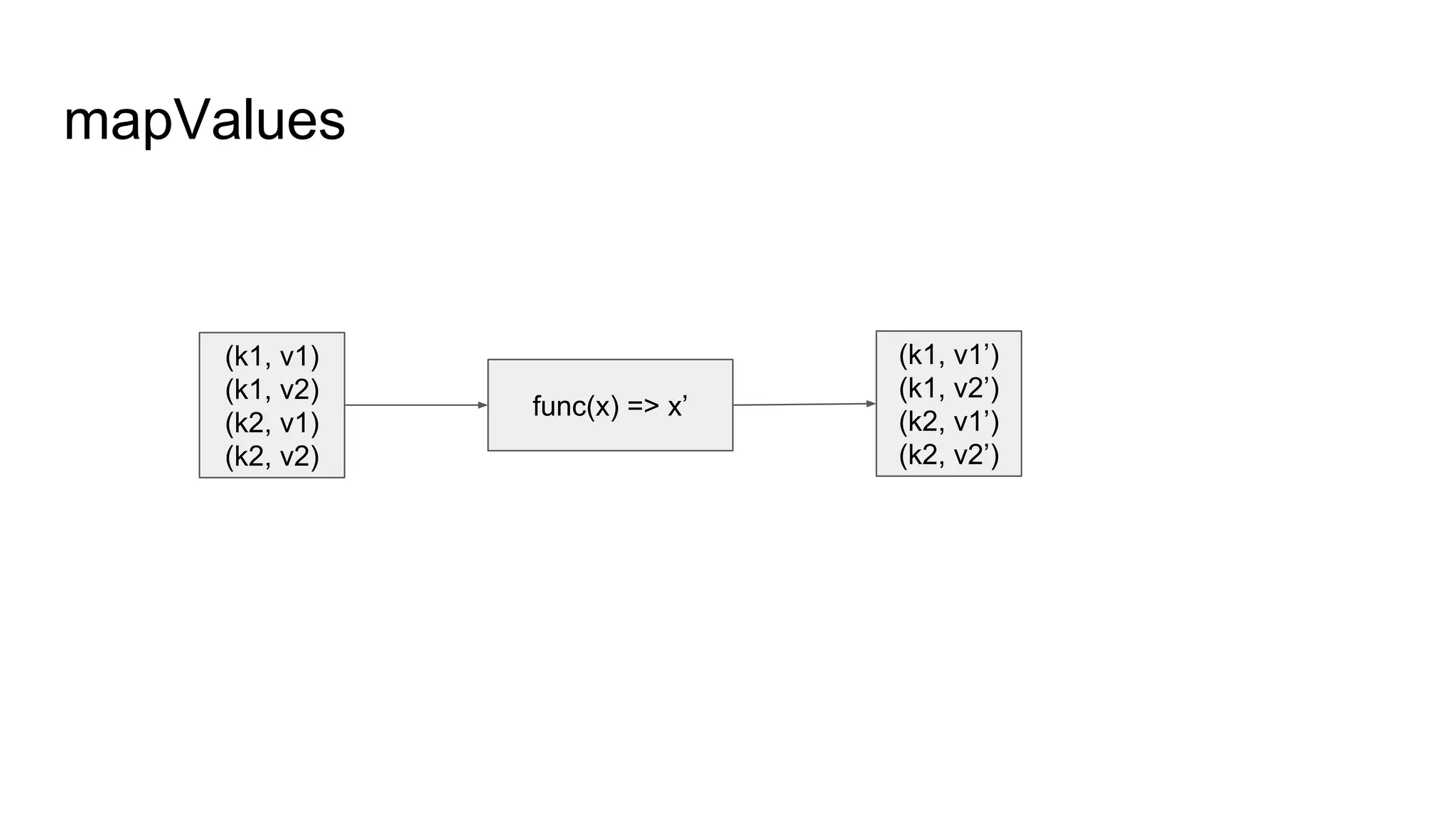
● Spark RDD API详解(一) Map和Reduce
● How to more efficiently calculate the averages for each KEY in a Pairwise (K,
V) RDD in Apache Spark with Python
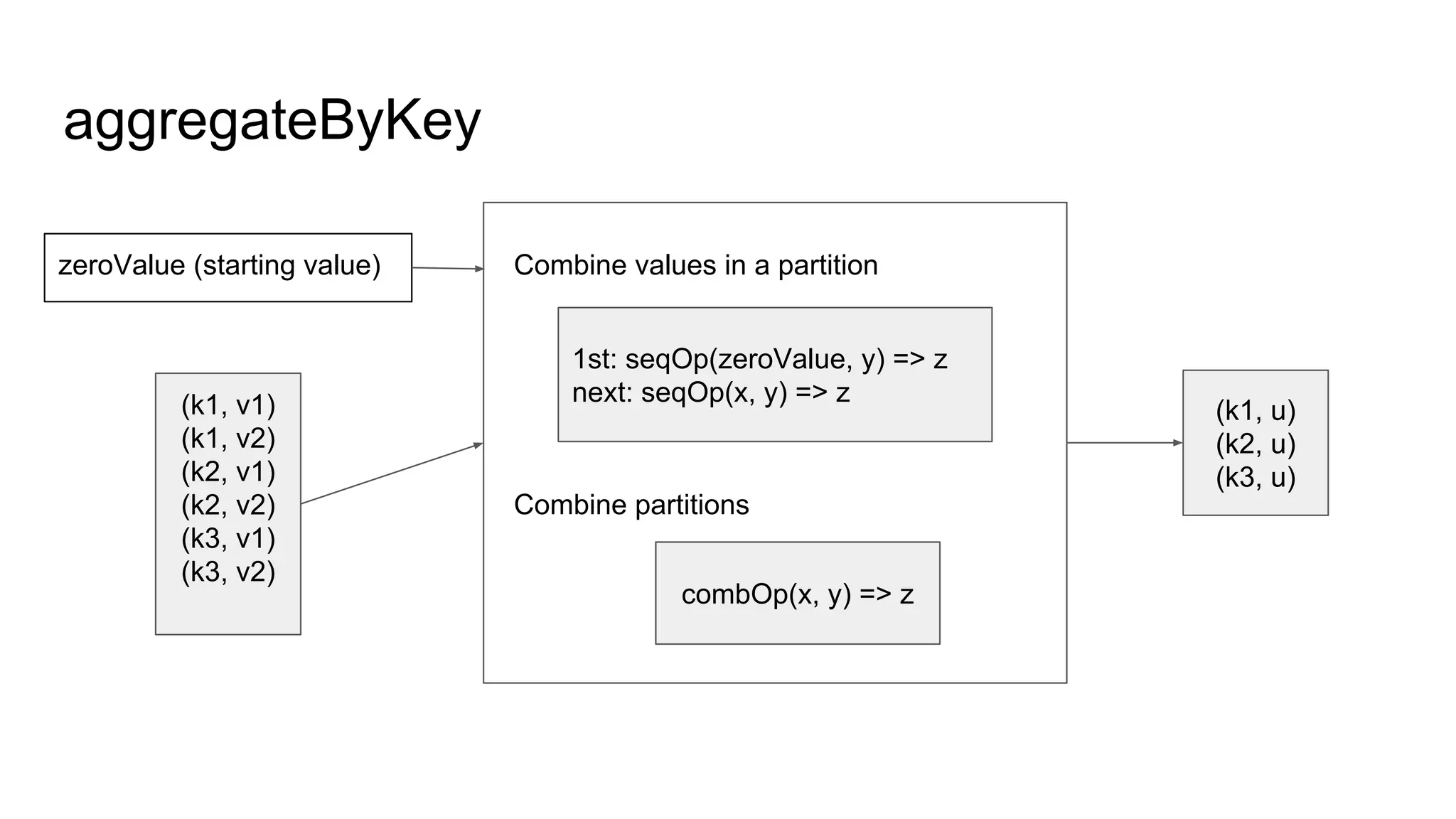
● Spark函数讲解:aggregateByKey
● 在Docker上用 IPython 開發 Spark的環境建置

![[分析] 同一個RNA序列檔,可任選其中兩個 conditions 進行 differential analysis (最
好能擴展成任選兩個 groups of conditions) 輸出 gene list。](https://image.slidesharecdn.com/sparkdifferentialexpression-151126090147-lva1-app6892/75/Spark-differential-expression-2-2048.jpg)






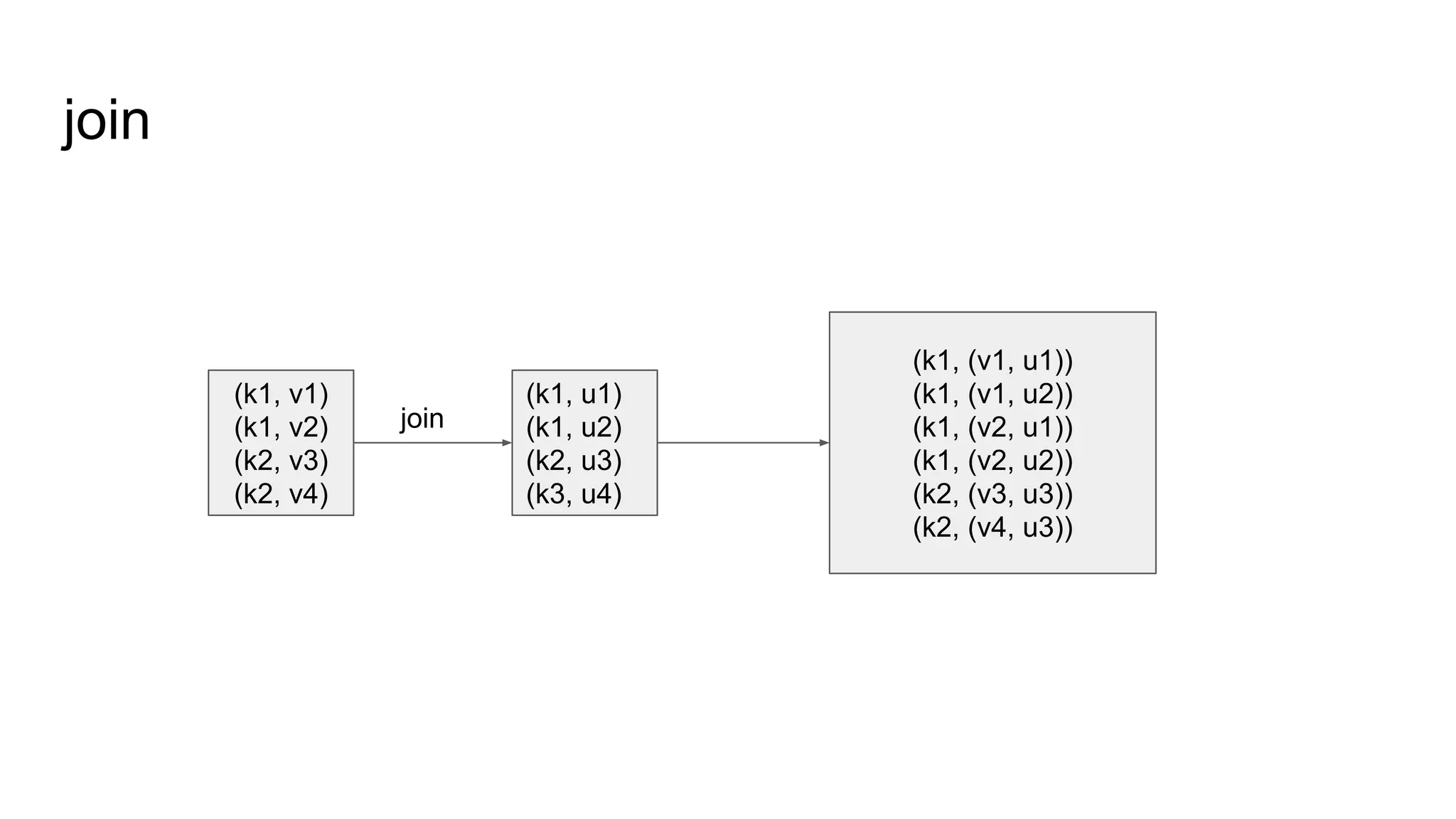

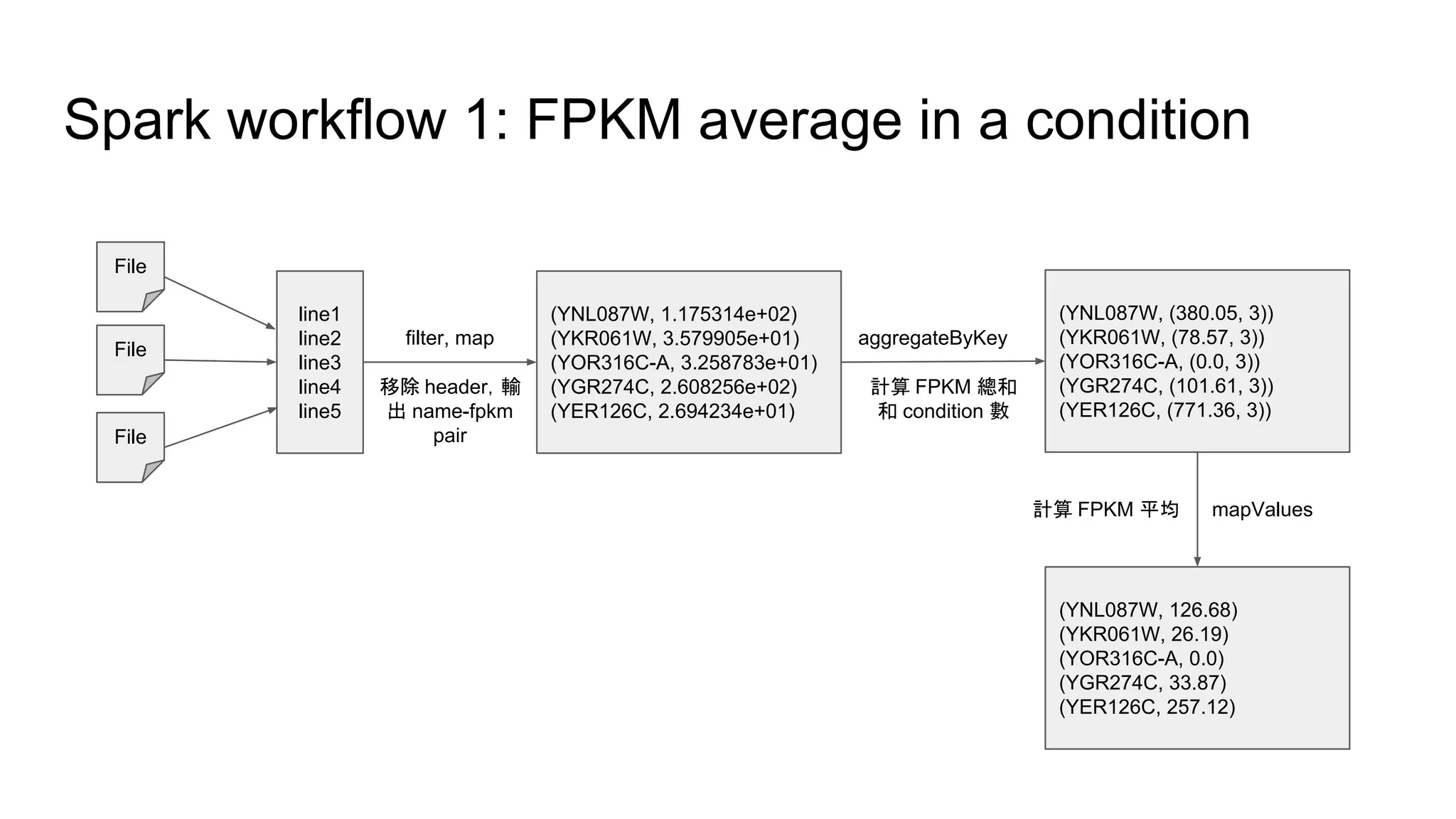
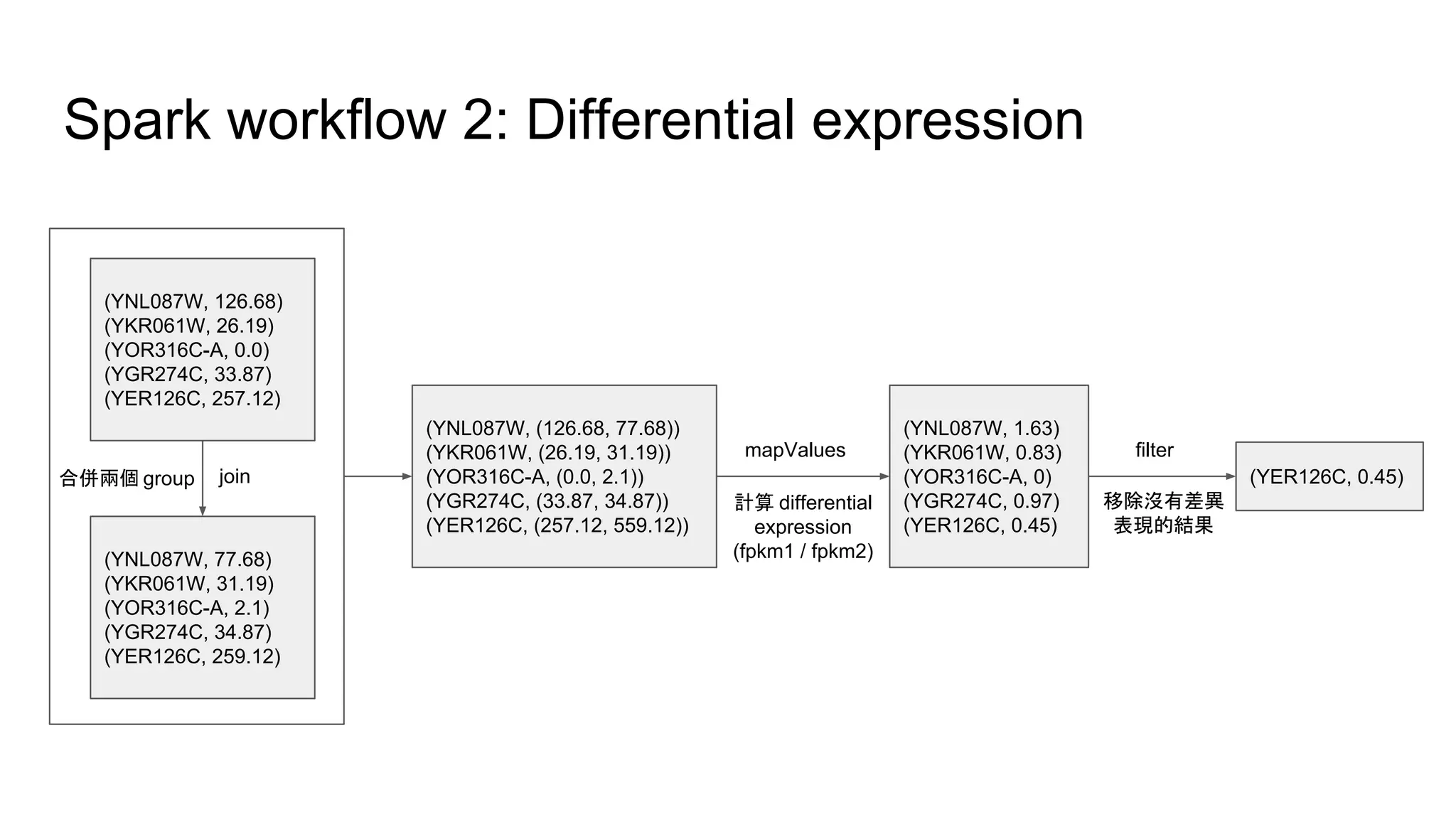
![安裝 Spark 和 IPython Notebook
● docker-spark
● docker run -it -p 8088:8088 -p 8042:8042 -p 8080:8080 -h mr-spark --name
mr-spark -v /home/jlhg/mapreduce:/share sequenceiq/spark:1.5.1 bash
● Container 內建 Python 版本為 2.6,用 pyenv 安裝 Python 2.7
● 安裝 IPython:pip install ipython[all]
● 啟動 IPython Notebook:IPYTHON_OPTS="notebook --ip=mr-spark --
port=8080" /usr/local/spark/bin/pyspark
● Web UI: http://<host_ip>:8080](https://image.slidesharecdn.com/sparkdifferentialexpression-151126090147-lva1-app6892/75/Spark-differential-expression-20-2048.jpg)