Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
SH
Uploaded by
Syuta Hashimoto
PDF, PPTX
8,527 views
Solrで日本語全文検索システムの構築と応用
2017年9月9日(土)10日(日)に行われましたOSC東京での発表スライドです。 全文検索の概要やRDBMSとの連携概要を紹介しています。
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 39
2
/ 39
3
/ 39
4
/ 39
5
/ 39
6
/ 39
7
/ 39
8
/ 39
9
/ 39
10
/ 39
11
/ 39
12
/ 39
13
/ 39
14
/ 39
15
/ 39
16
/ 39
17
/ 39
18
/ 39
19
/ 39
20
/ 39
21
/ 39
22
/ 39
23
/ 39
24
/ 39
25
/ 39
26
/ 39
27
/ 39
28
/ 39
29
/ 39
30
/ 39
31
/ 39
32
/ 39
33
/ 39
34
/ 39
35
/ 39
36
/ 39
37
/ 39
38
/ 39
39
/ 39
More Related Content
PPTX
Apache Solr 入門
by
順平 西本
PPTX
LIFULL HOME'SでのSolrの構成と運用の変遷
by
LIFULL Co., Ltd.
PDF
SolrとElasticsearchを比べてみよう
by
Shinsuke Sugaya
PDF
20210316 AWS Black Belt Online Seminar AWS DataSync
by
Amazon Web Services Japan
PDF
IAM Roles Anywhereのない世界とある世界(2022年のAWSアップデートを振り返ろう ~Season 4~ 発表資料)
by
NTT DATA Technology & Innovation
PDF
20190806 AWS Black Belt Online Seminar AWS Glue
by
Amazon Web Services Japan
PPTX
Amazon EKS への道 ~ EKS 再入門 ~
by
Hideaki Aoyagi
PDF
マイクロサービス時代の認証と認可 - AWS Dev Day Tokyo 2018 #AWSDevDay
by
都元ダイスケ Miyamoto
Apache Solr 入門
by
順平 西本
LIFULL HOME'SでのSolrの構成と運用の変遷
by
LIFULL Co., Ltd.
SolrとElasticsearchを比べてみよう
by
Shinsuke Sugaya
20210316 AWS Black Belt Online Seminar AWS DataSync
by
Amazon Web Services Japan
IAM Roles Anywhereのない世界とある世界(2022年のAWSアップデートを振り返ろう ~Season 4~ 発表資料)
by
NTT DATA Technology & Innovation
20190806 AWS Black Belt Online Seminar AWS Glue
by
Amazon Web Services Japan
Amazon EKS への道 ~ EKS 再入門 ~
by
Hideaki Aoyagi
マイクロサービス時代の認証と認可 - AWS Dev Day Tokyo 2018 #AWSDevDay
by
都元ダイスケ Miyamoto
What's hot
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
ODP
Guide To AGPL
by
Mikiya Okuno
PDF
AWS Black Belt Online Seminar Amazon Aurora
by
Amazon Web Services Japan
PDF
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
PDF
PHPからgoへの移行で分かったこと
by
gree_tech
PDF
これでAWSマスター!? 初心者向けAWS簡単講座
by
Serverworks Co.,Ltd.
PDF
AWSとオンプレミスを繋ぐときに知っておきたいルーティングの基礎知識(CCSI監修!)
by
Trainocate Japan, Ltd.
PDF
Elasticsearch の検索精度のチューニング 〜テストを作って高速かつ安全に〜
by
Takahiko Ito
PDF
AWSのログ管理ベストプラクティス
by
Akihiro Kuwano
PDF
20200630 AWS Black Belt Online Seminar Amazon Cognito
by
Amazon Web Services Japan
PDF
AWS Black Belt Techシリーズ Amazon CloudSearch
by
Amazon Web Services Japan
PDF
PostgreSQLの実行計画を読み解こう(OSC2015 Spring/Tokyo)
by
Satoshi Yamada
PDF
Use After Free 脆弱性攻撃を試す
by
monochrojazz
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PDF
[AKIBA.AWS] VPN接続とルーティングの基礎
by
Shuji Kikuchi
PDF
20190424 AWS Black Belt Online Seminar Amazon Aurora MySQL
by
Amazon Web Services Japan
PDF
20191023 AWS Black Belt Online Seminar Amazon EMR
by
Amazon Web Services Japan
PDF
20190410 AWS Black Belt Online Seminar Amazon Elastic Container Service for K...
by
Amazon Web Services Japan
PDF
Amazon Pinpoint を中心としたカスタマーエンゲージメントの全体像 / Customer Engagement On Amazon Pinpoint
by
Amazon Web Services Japan
PPTX
AWS Lambdaのテストで役立つ各種ツール
by
Masaki Suzuki
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Guide To AGPL
by
Mikiya Okuno
AWS Black Belt Online Seminar Amazon Aurora
by
Amazon Web Services Japan
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
PHPからgoへの移行で分かったこと
by
gree_tech
これでAWSマスター!? 初心者向けAWS簡単講座
by
Serverworks Co.,Ltd.
AWSとオンプレミスを繋ぐときに知っておきたいルーティングの基礎知識(CCSI監修!)
by
Trainocate Japan, Ltd.
Elasticsearch の検索精度のチューニング 〜テストを作って高速かつ安全に〜
by
Takahiko Ito
AWSのログ管理ベストプラクティス
by
Akihiro Kuwano
20200630 AWS Black Belt Online Seminar Amazon Cognito
by
Amazon Web Services Japan
AWS Black Belt Techシリーズ Amazon CloudSearch
by
Amazon Web Services Japan
PostgreSQLの実行計画を読み解こう(OSC2015 Spring/Tokyo)
by
Satoshi Yamada
Use After Free 脆弱性攻撃を試す
by
monochrojazz
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
[AKIBA.AWS] VPN接続とルーティングの基礎
by
Shuji Kikuchi
20190424 AWS Black Belt Online Seminar Amazon Aurora MySQL
by
Amazon Web Services Japan
20191023 AWS Black Belt Online Seminar Amazon EMR
by
Amazon Web Services Japan
20190410 AWS Black Belt Online Seminar Amazon Elastic Container Service for K...
by
Amazon Web Services Japan
Amazon Pinpoint を中心としたカスタマーエンゲージメントの全体像 / Customer Engagement On Amazon Pinpoint
by
Amazon Web Services Japan
AWS Lambdaのテストで役立つ各種ツール
by
Masaki Suzuki
Solrで日本語全文検索システムの構築と応用
1.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 Solrで日本語全文検索システムの構築と応用 ~ドキュメント検索からオンラインショッピングサイトへの応用まで~ 1 橋本 修太 日本
openSUSE ユーザ会
2.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 自己紹介 ・橋本 修太 @hashimotosyuta open系をベースとしたWeb関連の案件が経歴 (ECサイト、プロモーションサイト、CMS等) ・openSUSEとの付き合い ー
家庭用パソコンは4年程前からopenSUSEを使用 カメレオンかわいいがきっかけ ー openSUSE-jaに今年の6月から参加 ⇢ブラック企業案件管理能力の乏しい企業に居たため自分の時間が ほとんどなかったが、無事今年6月にホワイト企業へ転職成功。 空いた時間を楽しもうとopenSUSE-jaに参加。 ⇢「今年の秋に東京でopenSUSE.Asia Summitがあるんだけど、 参加しない?」との声かけを頂いて・・・・ ー openSUSE.Asia Summit実行委員やってます ⇢10月21日(土)、22日(日)は電通大に集まろう! 2
3.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 で、本題 講演の流れ 1 全文検索ってなに? 2 Solrってなに? 3 使ってみよう! 4 インデックスってなに? 5 構成や役割はこんな感じ 6 RDBMSからも検索できるよ! 7 件数取得はファセットが便利 8 ハイライトもお手の物 3 ※RDBMSの基礎知識を前提としています。ご了承下さい。
4.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 1 全文検索ってなに? Q:全文検索とは? A:全文章から検索します!(多分) それも複数のファイルの全文章から検索します!(本当) この、「複数のファイル」というワードが、一般に「全文検索」 「エンタープライズサーチ」といったものに対して重要になってきます。 ・ポイント1 全文検索は大体この二種類 ・シリアルスキャン型 ・インデックス型 ←今回の内容 4
5.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 1 全文検索ってなに? 全文検索その1 シリアルスキャン型 #
grep -r ‘hogehoge’ ⇢カレントディレクトリ以下のファイルから「hogehoge」って文字列の ある行を取り出してね ー 利点 ・手軽 ー 欠点 ・遅い ・テキストファイル以外は検索が難しい(Word等) ・検索ノイズが入る(後述) 5
6.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 1 全文検索ってなに? 全文検索その2 インデックス型 あらかじめ検索するであろう単語等の索引(インデックス)を作成し、 それを使って検索 ←ここを掘り下げていきます ー
利点 ・早い ・インデックス化できればWord等も検索可能 ・検索ノイズが減る(方法がある) ー 欠点 ・システムを構築する必要がある ・検索したいファイル等のインデックス化が必要 6
7.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 1 全文検索ってなに? まずは、ユースケース 7 こんな配置の資料から「openSUSE」で検索したい!
8.
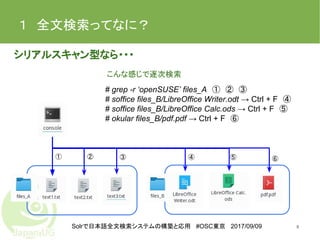
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 1 全文検索ってなに? シリアルスキャン型なら・・・ 8 #
grep -r ‘openSUSE’ files_A ① ② ③ # soffice files_B/LibreOffice Writer.odt → Ctrl + F ④ # soffice files_B/LibreOffice Calc.ods → Ctrl + F ⑤ # okular files_B/pdf.pdf → Ctrl + F ⑥ ① ② ③ ④ ⑤ ⑥ こんな感じで逐次検索
9.
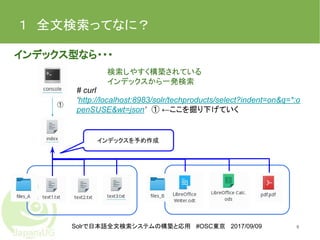
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 1 全文検索ってなに? インデックス型なら・・・ 9 #
curl ‘http://localhost:8983/solr/techproducts/select?indent=on&q=*:o penSUSE&wt=json’ ① ←ここを掘り下げていく ① インデックスを予め作成 検索しやすく構築されている インデックスから一発検索
10.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 2 Solrってなに? Solrとは ・インデックス型の全文検索システム ・読み方は そーらー (そらーと発音する人も多い) ・Apache
Lucene(アパッチ ルシーン)のサブプロジェクト。 →Apache Luceneは全文検索ライブラリ Solrはこれを利用している。なのでもちろんオープンソース ・javaベース solrjという、これから説明する事を実装できるjavaライブラリもある。 ・ただし、アクセスはWebAPIっぽく出来るので、 クライアントは何でもOK! ・Elasticsearch(エラスティックサーチ)という競合がある 比較等は先達がいらっしゃいますので、そちらの情報をご覧ください。 10
11.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 3 使ってみよう! さっそく構築!(ローカル検証用) 1 JVMをインストール
javaは1.8以降 (Leap 42.3なら既にインストール済) 2 Solrをダウンロード Solr公式ページのダウンロードより可能 現在バージョンは6.6.0 http://www.apache.org/dyn/closer.lua/lucene/solr/6.6.0 Zipファイルに一式入っています 3 2でダウンロードしたZipファイルをディレクトリに展開 # unzip solr-6.6.0.zip そして移動 # cd solr-6.6.0 11
12.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 3 使ってみよう! 12 起動、コア作成、インデックス化 4 #
bin/solr start ←まずはSolrを起動(コアもインデックスも無い) 5 # bin/solr create -c mycore ←「mycore」という名前でコア作成 6 # bin/post -c mycore /home/hashimoto/doc/* ←「mycore」にファイルをインデックス化 「bin/post」がインデックス化を自動処理してくれます ・ ・ ・ (だらだらとインデックス化ログが流れる) なんと 完 了 ※ちなみにSolrサイトには五分で始められるクイックスタートサンプル もあります。(いきなり分散冗長構成が体験できたりする)
13.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 3 使ってみよう! 重要な単語 ・コア RDBMSのスキーマに相当。インデックスのフォーマット定義や クエリーの設定等を保持。大雑把に言ってしまうと、検索エンジン そのもの。 ・スキーマ定義 Solrではインデックスのフォーマットをスキーマと呼びます。 RDBMSのテーブルのようなもの。 ・インデックス 検索対象用のファイルをスキーマ定義に従ってインデックス化した データ 13
14.
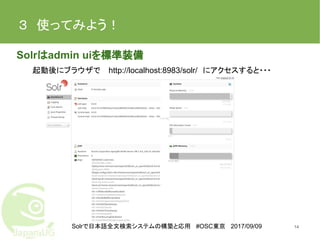
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 3 使ってみよう! Solrはadmin
uiを標準装備 起動後にブラウザで http://localhost:8983/solr/ にアクセスすると・・・ 14
15.
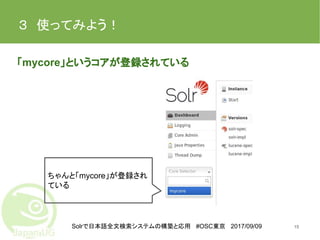
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 3 使ってみよう! 「mycore」というコアが登録されている 15 ちゃんと「mycore」が登録され ている
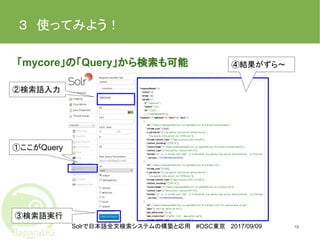
16.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 3 使ってみよう! 「mycore」の「Query」から検索も可能 16 ①ここがQuery ②検索語入力 ③検索語実行 ④結果がずら〜
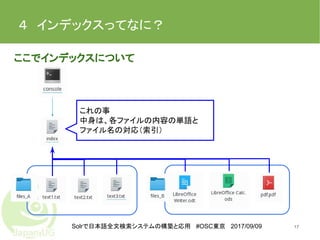
17.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 4 インデックスってなに? 17 ここでインデックスについて これの事 中身は、各ファイルの内容の単語と ファイル名の対応(索引)
18.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 4 インデックスってなに? 18 インデックスの中身 (インデックスのイメージ) なので、「openSUSE」で検索すると、すぐに「text1.txt」と「LibreOffice
Wirter.ods」にあ るよ、と返答がある 単語 単語のあるファイル openSUSE text1.txt LibreOffice Writer.ods カンファレンス text2.txt pdf.pdf ・・・ ・・・
19.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 4 インデックスってなに? 19 インデックスの定義=スキーマ 構成はスキーマと呼ばれています スキーマで定義する事は以下の通り ・フィールド RDBMSで言う所のカラム フィールドタイプも指定する この中に文章は単語に分解されたりして登録されていく ・フィールドタイプ フィールドの定義 数値だったり文章だったり、 形態素解析するしないを定義 ・ダイナミックフィールドや コピーフィールドとかも・・・・(今回は省略)
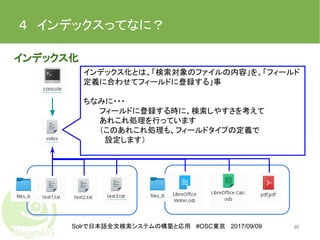
20.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 4 インデックスってなに? 20 インデックス化 インデックス化とは、「検索対象のファイルの内容」を、「フィールド 定義に合わせてフィールドに登録する」事 ちなみに・・・ フィールドに登録する時に、検索しやすさを考えて あれこれ処理を行っています (このあれこれ処理も、フィールドタイプの定義で 設定します)
21.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 4 インデックスってなに? 21 あれこれ処理? ・例えば英文なら、全部小文字に変換する、とか。 「linux」も「Linux」も「LINUX」も、「linux」で検索したい → 「linux」も「Linux」も「LINUX」も、「linux」と登録 しておけばOK。 検索時も同じで、「linux」も「Linux」も「LINUX」も、 「linux」として検索すればOK。 ・日本語なら、品詞基準で分割、とか。 「私は東京都で開催されるアジアサミットに行きます。」 →「私-は-東京-都-で-開催-さ-れる-アジア-サミット-に-行き-ます」 これならば、「東京」ならヒットするけれども「京都」で検索したら ヒットしない 大量ドキュメントから検索した時のノイズ(期待していない結果) が減る 形態素解析と言う、奥のふか〜〜い技術
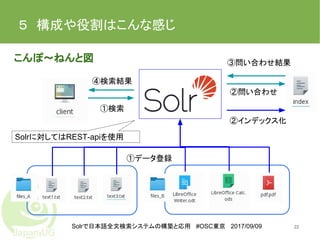
22.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 5 構成や役割はこんな感じ 22 こんぽ〜ねんと図 ①検索 ④検索結果 ①データ登録 ②インデックス化 ②問い合わせ ③問い合わせ結果 Solrに対してはREST-apiを使用
23.
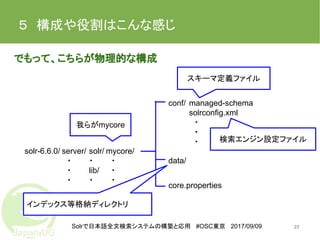
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 5 構成や役割はこんな感じ でもって、こちらが物理的な構成 23 solr-6.6.0/
server/ ・ ・ ・ solr/ ・ lib/ ・ conf/ mycore/ ・ ・ ・ data/ managed-schema solrconfig.xml ・ ・ ・ core.properties 我らがmycore スキーマ定義ファイル 検索エンジン設定ファイル インデックス等格納ディレクトリ
24.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 5 構成や役割はこんな感じ managed-schema ・スキーマ定義(フィールドやフィールドタイプ)が記述されている ファイル。なんと、フィールドはREST-apiで定義出来るため、この ファイルを編集する必要がない。というか、編集しないでね、と書か れている。(しかしフィールドタイプはまだREST-apiでは定義できず、 このファイルを直接編集する必要がある。) ・以前はスキーマ定義は<schema.xml>というファイルで管理されていて、 フィールドもフィールドタイプもこのファイルを直接編集していた。 (今でも直接編集に切り替えて使っている人はいます。) 物理的な構成と言えば・・・・ プロダクト用に<install_solr_service.sh>という、インストール用ス クリプトが添付。 /opt/solr/にエンジン、/var/solr/にデータを配置してくれたり、service のスクリプトをインストールしてくれたりする。 24
25.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 6 RDBMSからも検索できるよ! セットアップ完了!それでは良い検索ライフを!! 25 え?俺のショッピングサイト、 MySQLにデータ入ってんだけど・・・・ 商品説明のlike検索とか重いんだよね。 お、おう・・・
26.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 6 RDBMSからも検索できるよ! DataImportHandler 実は、SolrにはRDBMSやその他のデータソースから 検索出来るようにする(インデックス化する)仕組み が存在します。 「全文検索」という観点から言うと、オンラインショッピングサイトでの 商品検索、とか、そういう限られたイメージを持ってしまいますが、 これから説明する「ファセット検索」や「ハイライト」等の機能も使える のでかなり優秀です。 26
27.
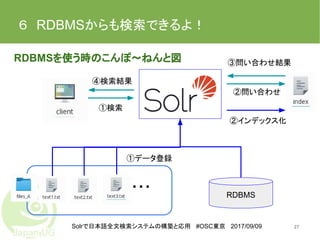
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 6 RDBMSからも検索できるよ! 27 RDBMSを使う時のこんぽ〜ねんと図 ①検索 ④検索結果 ①データ登録 ②インデックス化 ②問い合わせ ③問い合わせ結果 ・・・
RDBMS
28.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 6 RDBMSからも検索できるよ! 論理構成 2828 descriptionから 「geeko」を検索 検索結果 「nameが openSUSEのデー タにあるよ!」 スキーマのフィールドとRDBMSのカラムを対応 させてインデックス化 RDBMS スキーマ フィールド
名前=id フィールド 名前=name フィールド 名前=description id name description 1 openSUSE geekoがかわいい!
29.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 6 RDBMSからも検索できるよ! スキーマのフィールドとRDBMSのカラムを 対応させてインデックス化 ・RDBMSからのデータ抽出にはSQLを使用。 なので、正確にはスキーマのフィールドと「SELECTの結果」を 対応させてインデックス化。 ・対応させる時、名前は一致していなくても大丈夫。 設定ファイルで名前を指定出来ます。 つまり、好きなSQLの結果をフィールドに対応させられる(検索出来る) 29 夢が膨らむ!
30.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 6 RDBMSからも検索できるよ! 設定はちょっとだけ面倒 ●
RDBMSアクセス用コネクタを配置 →server/lib配下にJDBCコネクタを配置 ● フィールド定義 →次ページにて ● solrconfig.xml(コアの設定ファイル)に以下を設定 ・DataImportHandlerのライブラリ読み込み ・DataImportHandler使うよ宣言と、その時に使用する設定ファイル指定 *a ● DataImportHandler用設定ファイル(*aで指定したファイル) ・RDBMS接続設定 ・フィールドとSQLの対応 30 ここにインデックス用SQLや、 SELCET結果とフィールドの対応等を記述 概要となります。 具体的な設定の記述等は別途 資料を参照下さい。
31.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 6 RDBMSからも検索できるよ! フィールド定義 手っ取り早いのはadmin
uiでスキーマ定義 31 ①(みにくいです が) 「Schema」を選択 ②「Add Field」を選 択 ③各種設定 し、下部の 「Add Field」を クリック (フィールドタ イプはtext_ja 辺り)
32.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 6 RDBMSからも検索できるよ! 設定は完了! いざ、取り込み いつも通りREST-api http://localhost:8983/solr/mycore/dataimport?command=full-import 32 我らがmycore
余談 URI「/dataimport」はsolrconfig.xmlで requestHandlerを定義する時に指定 する これだけで、取り込みは完了!admin uiからの検索等が行える。 実運用に向けて、差分インポートの設定やインポートタイミングの設計 を行う。(定期的にインデックス化処理するか、DBアップデート時にイン デックス化処理するか、等々)
33.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 7 件数取得はファセットが便利 ファセット検索 グルーピングして件数を数える機能です。 例えば、こんな感じでtypeの件数取得 33 id
name description type 1 docker コンテナ型仮想環境 virtualization 2 emacs 多機能エディタ editor 3 vim 多機能エディタ editor 4 chrome ブラウザ browser 5 firefox ブラウザ browser 6 sleipnir ブラウザ browser "facet_counts":{ "facet_queries":{}, "facet_fields":{ "type":[ "virtualization",1, "editor",2 “browser”,3]}, "facet_ranges":{}, "facet_intervals":{}, "facet_heatmaps":{}}
34.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 7 件数取得はファセットが便利 ファセット検索のREST-api 方法は、ファセット検索用のフィールドがあるので、それを指定するだけでOK http://localhost:8983/solr/mycore/select?facet=on&facet.field=type&indent=on&q=* :*&wt=json 通常の検索と組み合わせれば、当然、通常の検索結果に対してファセット検索(件数取 得)が可能 範囲の指定等、ちょっと複雑な件数取得も可能 34 ・facet=on ファセット検索を有効に ・facet.field=type 「type」フィールドでグルーピング(件数取得)
35.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 8 ハイライトもお手の物 ハイライト 検索結果とは別に、ハイライト設定した結果を別途取得する事も出来ます。 例えばこんなデータで、desciptionから「オープンソース」で検索 35 id
name description 1 openSUSE openSUSE プロジェクトとは、あらゆる場所での Linux の利 用を目指す世界的な取り組みです。openSUSE は、世界的な フリー/オープンソースソフトウェアコミュニティの一部として、 オープンに、透明に、友好的に協力し合い、世界最高の Linux ディストリビューションの一つを創っています。
36.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 8 ハイライトもお手の物 ハイライト検索を実行すると 36 "highlighting":{ "1":{ "description":["openSUSE
プロジェクトとは、あらゆる場所での Linux の利用を目指す世界的な取り組みです。openSUSE は、世界的な フリー/<em>オープンソース</em>ソフトウェアコミュニティの一部"]}} openSUSE プロジェクトとは、あらゆる場所での Linux の利用を目指す世界的な取 り組みです。openSUSE は、世界的なフリー/オープンソースソフトウェアコミュニティ の一部として、オープンに、透明に、友好的に協力し合い、世界最高の Linux ディス トリビューションの一つを創っています。 「オープンソース」で検索すると<em>タグで囲われる また、ヒットした所の前後一定数で切り取りだす
37.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 8 ハイライトもお手の物 ハイライト検索のREST-api 検索はいつもどおりURLにパラメータ指定 http://localhost:8983/solr/mycore/select?hl=on&hl.fl=description&indent=on&q=des cription:%E3%82%AA%E3%83%BC%E3%83%97%E3%83%B3%E3%82%BD%E 3%83%BC%E3%82%B9&wt=json 37 ・hl=on ハイライトオン ・hl.fl=description
ハイライト用にdescriptionのフィールドを指定 「オープンソース」で検索 REST-apiなので、URLエンコードしてます
38.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 8 ハイライトもお手の物 ハイライトの設定 ・solrconfig.xmlに、「searchComponent」で設定されている ・フィールドに幾つか設定が必要 a
storedという、取得したデータを保持する項目をtrueに b フィールドタイプは解析を行うものを指定 ハイライトは幾つかの設定の組み合わせが可能。 初期設定でも有用ですが、設定をする事でより細かい制御が可能 hl.method hl.qparser hl.requireFieldMatch hl.usePhraseHighlighter ・ ・ ・ 38
39.
Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09 1 Solrはインデックス型全文検索システム 2 フィールド定義はスキーマと呼ばれる これがインデックスの構成を決める 3 RDBMSのデータも検索可能 4 ファセット検索、ハイライトも簡単 8 ハイラそれではよい検索ライフを!! Have
a lot of fun... 39 本日のまとめ
Download






















![Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09
7 件数取得はファセットが便利
ファセット検索
グルーピングして件数を数える機能です。
例えば、こんな感じでtypeの件数取得
33
id name description type
1 docker コンテナ型仮想環境 virtualization
2 emacs 多機能エディタ editor
3 vim 多機能エディタ editor
4 chrome ブラウザ browser
5 firefox ブラウザ browser
6 sleipnir ブラウザ browser
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"type":[
"virtualization",1,
"editor",2
“browser”,3]},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{}}](https://image.slidesharecdn.com/solr-170916113443/85/Solr-33-320.jpg)


![Solrで日本語全文検索システムの構築と応用 #OSC東京 2017/09/09
8 ハイライトもお手の物
ハイライト検索を実行すると
36
"highlighting":{
"1":{
"description":["openSUSE プロジェクトとは、あらゆる場所での
Linux の利用を目指す世界的な取り組みです。openSUSE は、世界的な
フリー/<em>オープンソース</em>ソフトウェアコミュニティの一部"]}}
openSUSE プロジェクトとは、あらゆる場所での Linux の利用を目指す世界的な取
り組みです。openSUSE は、世界的なフリー/オープンソースソフトウェアコミュニティ
の一部として、オープンに、透明に、友好的に協力し合い、世界最高の Linux ディス
トリビューションの一つを創っています。
「オープンソース」で検索すると<em>タグで囲われる
また、ヒットした所の前後一定数で切り取りだす](https://image.slidesharecdn.com/solr-170916113443/85/Solr-36-320.jpg)

























![[AKIBA.AWS] VPN接続とルーティングの基礎](https://cdn.slidesharecdn.com/ss_thumbnails/akibaaws6vpn-180510092054-thumbnail.jpg?width=640&height=640&fit=bounds)




