Downloaded 39 times




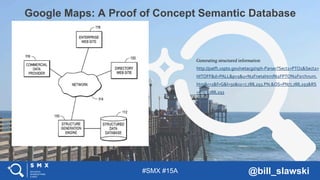









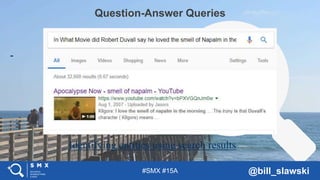







1. The document discusses Sergey Brin's early work on extracting structured data from unstructured sources like the world wide web through his DIPRE algorithm. 2. It then shows how projects at Google like Google Maps and WebTables have built upon this idea to generate structured data from various online sources. 3. Current initiatives at Google like schema markup, question answering, and crowdsourcing ontologies continue working to understand online information in a more semantic, structured way to improve search.



































































