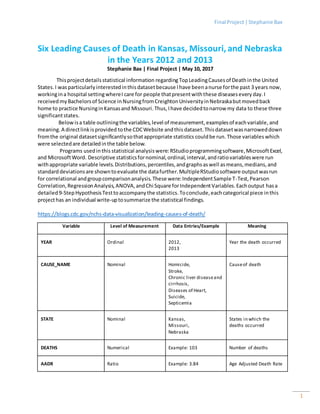
![Final Project|Stephanie Bax
2
For thisassignment,youwillneedtoidentifyadatasetof interesttoyou, conductanalysesonthe data
set,and thenprovide anAPA style write upof yourresults.The final projectshouldinclude:
1. Software output for descriptive statistics about
both nominal/ordinal and interval/ratio variables
- Each variables’measure issettothe appropriate level (i.e.nominal,ordinal,orscale) 10 pts.
Variables and Appropriate Levels
a. Importthe .csv file toRStudio,create a new RScriptandsave it as Final Project - done
b. Ensure all variablesare labeledcorrectly(nominal –is.factor,interval/ratio –is.numeric,
and ordinal – is.ordered).Use the strcommandto view datasetdetails.
> View(USADeathCauses)
> is.ordered(USADeathCauses$YEAR)
[1] FALSE
> is.factor(USADeathCauses$CAUSE_NAME)
[1] FALSE
> is.factor(USADeathCauses$STATE)
[1] FALSE
> is.numeric(USADeathCauses$DEATHS)
[1] TRUE
> is.numeric(USADeathCauses$AADR)
[1] TRUE
> USADeathCauses$YEAR = factor(USADeathCauses$YEAR, levels = c("2012", "2013"
), ordered = TRUE)
> is.ordered(USADeathCauses$YEAR)
[1] TRUE
> USADeathCauses$CAUSE_NAME = factor(USADeathCauses$CAUSE_NAME, levels = c("H
omicide", "Stroke", "Chronic liver disease and cirrhosis", "Diseases of Heart
", "Suicide", "Septicemia"), ordered = TRUE)
> is.factor(USADeathCauses$CAUSE_NAME)
[1] TRUE
> USADeathCauses$STATE = factor(USADeathCauses$STATE, levels = c("Kansas", "M
issouri", "Nebraska"), ordered = TRUE)
> is.factor(USADeathCauses$STATE)
[1] TRUE
> str(object = USADeathCauses)
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 36 obs. of 5 variables:
$ YEAR : Ord.factor w/ 2 levels "2012"<"2013": 1 1 1 1 1 1 1 1 1 1 ...
$ CAUSE_NAME: Ord.factor w/ 6 levels "Homicide"<"Stroke"<..: 1 1 1 2 2 2 3 3
3 4 ...
$ STATE : Ord.factor w/ 3 levels "Kansas"<"Missouri"<..: 1 2 3 1 2 3 1 2
3 1 ...
$ DEATHS : num 103 424 64 1343 2989 ...
$ AADR : num 3.84 7.32 3.53 39.36 42.22 ...](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
Recommended
Recommended
More Related Content
Similar to Six Leading Causes of Death in Kansas, Missouri, and Nebraska in the Years 2012 and 2013: A Statistical Analysis
Similar to Six Leading Causes of Death in Kansas, Missouri, and Nebraska in the Years 2012 and 2013: A Statistical Analysis (20)
Recently uploaded
Recently uploaded (20)
Six Leading Causes of Death in Kansas, Missouri, and Nebraska in the Years 2012 and 2013: A Statistical Analysis
- 1. Final Project|Stephanie Bax 1 Six Leading Causes of Death in Kansas, Missouri, and Nebraska in the Years 2012 and 2013 Stephanie Bax | Final Project | May 10, 2017 Thisprojectdetailsstatistical information regardingTopLeadingCausesof Deathinthe United States.I wasparticularlyinterestedinthisdatasetbecause Ihave beenanurse forthe past 3 years now, workingina hospital settingwhereI care for people thatpresentwiththese diseasesevery day.I receivedmyBachelorsof Science inNursingfromCreightonUniversityinNebraskabutmovedback home to practice NursinginKansasand Missouri.Thus,Ihave decidedtonarrow my data to these three significantstates. Belowisa table outliningthe variables,level of measurement, examplesof eachvariable,and meaning. A directlinkisprovided tothe CDCWebsite andthis dataset.Thisdatasetwasnarroweddown fromthe original datasetsignificantlysothatappropriate statistics couldbe run. Those variables which were selectedare detailedinthe table below. Programs usedinthis statistical analysiswere:RStudioprogrammingsoftware,MicrosoftExcel, and MicrosoftWord. Descriptive statisticsfornominal,ordinal,interval,andratiovariableswere run withappropriate variable levels.Distributions,percentiles,andgraphsaswell asmeans,medians,and standarddeviationsare showntoevaluate the datafurther.MultipleRStudiosoftware outputwasrun for correlational andgroupcomparisonanalysis.These were:IndependentSample T-Test,Pearson Correlation,RegressionAnalysis,ANOVA,andChi Square forIndependentVariables.Eachoutput hasa detailed9-StepHypothesisTesttoaccompanythe statistics.Toconclude,eachcategorical piece inthis projecthas an individual write-uptosummarize the statistical findings. https://blogs.cdc.gov/nchs-data-visualization/leading-causes-of-death/ Variable Level of Measurement Data Entries/Example Meaning YEAR Ordinal 2012, 2013 Year the death occurred CAUSE_NAME Nominal Homicide, Stroke, Chronic liver diseaseand cirrhosis, Diseases of Heart, Suicide, Septicemia Causeof death STATE Nominal Kansas, Missouri, Nebraska States in which the deaths occurred DEATHS Numerical Example: 103 Number of deaths AADR Ratio Example: 3.84 Age Adjusted Death Rate
- 2. Final Project|Stephanie Bax 2 For thisassignment,youwillneedtoidentifyadatasetof interesttoyou, conductanalysesonthe data set,and thenprovide anAPA style write upof yourresults.The final projectshouldinclude: 1. Software output for descriptive statistics about both nominal/ordinal and interval/ratio variables - Each variables’measure issettothe appropriate level (i.e.nominal,ordinal,orscale) 10 pts. Variables and Appropriate Levels a. Importthe .csv file toRStudio,create a new RScriptandsave it as Final Project - done b. Ensure all variablesare labeledcorrectly(nominal –is.factor,interval/ratio –is.numeric, and ordinal – is.ordered).Use the strcommandto view datasetdetails. > View(USADeathCauses) > is.ordered(USADeathCauses$YEAR) [1] FALSE > is.factor(USADeathCauses$CAUSE_NAME) [1] FALSE > is.factor(USADeathCauses$STATE) [1] FALSE > is.numeric(USADeathCauses$DEATHS) [1] TRUE > is.numeric(USADeathCauses$AADR) [1] TRUE > USADeathCauses$YEAR = factor(USADeathCauses$YEAR, levels = c("2012", "2013" ), ordered = TRUE) > is.ordered(USADeathCauses$YEAR) [1] TRUE > USADeathCauses$CAUSE_NAME = factor(USADeathCauses$CAUSE_NAME, levels = c("H omicide", "Stroke", "Chronic liver disease and cirrhosis", "Diseases of Heart ", "Suicide", "Septicemia"), ordered = TRUE) > is.factor(USADeathCauses$CAUSE_NAME) [1] TRUE > USADeathCauses$STATE = factor(USADeathCauses$STATE, levels = c("Kansas", "M issouri", "Nebraska"), ordered = TRUE) > is.factor(USADeathCauses$STATE) [1] TRUE > str(object = USADeathCauses) Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 36 obs. of 5 variables: $ YEAR : Ord.factor w/ 2 levels "2012"<"2013": 1 1 1 1 1 1 1 1 1 1 ... $ CAUSE_NAME: Ord.factor w/ 6 levels "Homicide"<"Stroke"<..: 1 1 1 2 2 2 3 3 3 4 ... $ STATE : Ord.factor w/ 3 levels "Kansas"<"Missouri"<..: 1 2 3 1 2 3 1 2 3 1 ... $ DEATHS : num 103 424 64 1343 2989 ... $ AADR : num 3.84 7.32 3.53 39.36 42.22 ...
- 3. Final Project|Stephanie Bax 3 Distributions, Percentiles, and Graphs c. Were there anyoutliersintermsof Deaths? Yes.There are outliersin the 1400 range of deaths. > boxplot(USADeathCauses$DEATHS) d. Provide ahistogramfor the AADR variable. > hist(USADeathCauses$AADR) e. What were the frequenciesandpercent’s forthe nominal andordinal variables? > statestable=table(USADeathCauses$STATE) > View(statestable) > Kansas= 12, Missouri = 12, Nebraska= 12 Variable Frequency Kansas 12 Missouri 12 Nebraska 12
- 4. Final Project|Stephanie Bax 4 > statespercent=prop.table(statestable) > View(statespercent) > Kansas= 33.33%, Missouri = 33.33%, Nebraska= 33.33% Variable Percent Kansas 0.33333 Missouri 0.33333 Nebraska 0.33333 > causestable = table(USADeathCauses$CAUSE_NAME) > View(causestable) > Homicide =6, Stroke = 6, Chronicliverdisease andcirrhosis=6, Diseasesof Heart= 6, Suicide =6, Sept icemia= 6 Variable Freq Homicide 6 Stroke 6 Chronic liverdisease and cirrhosis 6 Diseasesof Heart 6 Suicide 6 Septicemia 6 > causespercent=prop.table(causestable) > View(causespercent) > Homicide =17%, Stroke = 17%, Chronicliverdisease andcirrhosis=17%, Diseasesof Heart= 17%, Suicide =17%, Septicemia=17% Variable Percent Homicide .1667 Stroke .1667 Chronic liverdisease and cirrhosis .1667 Diseasesof Heart .1667 Suicide .1667 Septicemia .1667 > yeartable = table(USADeathCauses$YEAR) > View(yeartable) > 2012 = 18 and2013 = 18 Variable Freq 2012 18 2013 18 > yearpercent=prop.table(yeartable) > View(yearpercent) > 2012 = 50% and 2013 = 50% Variable Percent 2012 .5 2013 .5
- 5. Final Project|Stephanie Bax 5 f. Provide abar chart forthe statesvariable. > plot(USADeathCauses$STATE) g. Create a newvariable codedasNONMEDICALand MEDICAL thenprovide frequencies and percentagesforeachcategory. > make sure ‘car’ package isclicked > ie.NONMEDICALwouldbe considered –Homicide,Suicide > ie.MEDICAL wouldbe considered –Stroke,Chronicliverdisease andcirrhosis,Diseasesof Heart,Septicemia > library("car", lib.loc="~/R/win-library/3.3") > USADeathCauses$CAUSE_NAMELH=recode(USADeathCauses$CAUSE_NAME, "'Homicide'=' NONMEDICAL'; 'Suicide'='NONMEDICAL'; 'Stroke'='MEDICAL'; 'Chronic liver disea se and cirrhosis'='MEDICAL'; 'Diseases of Heart'='MEDICAL'; 'Septicemia'='MED ICAL'") > USADeathCauses$CAUSE_NAMELH = factor(USADeathCauses$CAUSE_NAMELH, levels = c("NONMEDICAL", "MEDICAL"), ordered = TRUE) > CAUSE_NAMELHtable=table(USADeathCauses$CAUSE_NAMELH) > View(CAUSE_NAMELHtable) Nonmedical:12,Medical:24 Variable Frequency NONMEDICAL 12 MEDICAL 24 > CAUSE_NAMELHpercent=prop.table(CAUSE_NAMELHtable) > View(CAUSE_NAMELHpercent) Nonmedical:33%,Medical:67% Variable Percent NONMEDICAL 0.333333 MEDICAL 0.666667
- 6. Final Project|Stephanie Bax 6 Measures of Central Tendency & Variability h. Obtainmeans,medians,andstandarddeviationsforthe appropriate variables (numerical variables- deaths,AADR) inyourfull datasetandrecord themina table. > DescFull=describe(USADeathCauses) > View(DescFull) Table All Variable Mean Standard Deviation Median Deaths 1790.03 3293.06 538.00 AADR 40.28 58.82 11.44 i. Subsetthe data forKansas onlyandthenobtainthe means,medians,andstandard deviationsforthe appropriate variablesandrecordthemina table. > attach(USADeathCauses) > Kansasonly=subset(USADeathCauses, STATE=="Kansas",select = DEATHS:AADR) > DescKansas = describe(Kansasonly) > View(DescKansas) > detach(USADeathCauses) Subset Table Kansas Only Variable Mean Standard Deviation Median Deaths 1313.75 1936.41 394.50 AADR 39.11 56.38 12.82 2. Software output for correlational and group comparison analyses - Correctstatisticsare run. 6 pts. ***Independent Samples T-Test*** Were there significant differences between the years 2012 and 2013 on number of deaths? a. Use the “t.test”command to investigate the following(Assessassumptionsforeach analysisandnote anypossible concerns): IndependentSampleT-Test- 9 StepHypothesisTesting: 1) H0: No significantdifferencesexistbetween the yearsonnumberof deaths. 2) H1: Significantdifferencesexistbetweenthe yearsonnumberof deaths. 3) Test: IndependentSamplesT-Test - Assumptions:1) Our dependentoroutcome variable isatleastinterval,2) Our twosamplesare independentof one another,3) Ourdependentoroutcome variable followsanormal curve,4) The variancesbetweenourtwogroupsare homogenousorsimilar. 4) Alpha:.05
- 7. Final Project|Stephanie Bax 7 > normalitydeaths = shapiro.test(USADeathCauses$DEATHS) > normalitydeaths Shapiro-Wilk normality test data: USADeathCauses$DEATHS W = 0.53738, p-value = 1.729e-09 The above is the resultsforour normalityassumptiontest.Since the p-value forthisisbeyondthe alpha value,we rejectthe null andconclude thatthe normalityassumptionisnotmet.But,because ourt-testi s robust, we continue withthe analysis. > hovdeaths = leveneTest(USADeathCauses$DEATHS, USADeathCauses$YEAR) > detach("package:psych", unload=TRUE) > library("car", lib.loc="~/R/win-library/3.3") > hovdeaths = leveneTest(USADeathCauses$DEATHS, USADeathCauses$YEAR) > hovdeaths Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 1 9e-04 0.9767 34 The above are the resultsforour homogeneityof variance assumptiontesting.Since ourpvalue is beyondouralphavalue of .05, we acceptthe null andnote that the HOV has beenmet.Since bothof these assumptionshave beenmet,we cancontinue ontorun our IndependentSample T-Test. > indepttest = t.test(USADeathCauses$DEATHS~USADeathCauses$YEAR, var.equal = TRUE) > indepttest Two Sample t-test data: USADeathCauses$DEATHS by USADeathCauses$YEAR t = -0.020901, df = 34, p-value = 0.9834 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -2286.599 2240.044 sample estimates: mean in group 2012 mean in group 2013 1778.389 1801.667 > detach("package:car", unload=TRUE) > library("psych", lib.loc="~/R/win-library/3.3") > describeBy(USADeathCauses$DEATHS, group = USADeathCauses$YEAR) $`2012` vars n mean sd median trimmed mad min max range skew kurtosi s X1 1 18 1778.39 3303.22 538 1137.81 547.82 64 13742 13678 2.66 6.6 7 se X1 778.58 $`2013` vars n mean sd median trimmed mad min max range skew kurtosi s X1 1 18 1801.67 3378.58 511.5 1141.25 530.77 75 14095 14020 2.69 6.8 4 se X1 796.34
- 8. Final Project|Stephanie Bax 8 attr(,"call") by.default(data = x, INDICES = group, FUN = describe, type = type) 5) df: 34 6) Critical Value:p> .05, (p= .98) 7) CalculatedValue:t= -0.02 8) Decision:Because the pvalue isnotbeyondthe alphavalue,we fail toreject the null,acceptnull H0. 9) Interpretation: Nosignificantdifferencesexistbetweenthe years2012 and 2013 on numberof deaths. ***Pearson Correlation*** Test the null hypothesis that no relationship between number of deaths (DEATHS) and Age Adjusted Death Rate (AADR). b. PearsonCorrelation - 9 StepHypothesisTesting: i. Assumptions:1) Measurement;Eachvariable isassociatedwithone case inour dataset2) Level of Measurement;Both variablesare atleastinterval innature. 3) Linearity;The variablesrelatetoeachother in a linearfashion (tobe evaluated). > attach(USADeathCauses) > plot(DEATHS, AADR) The above scatterplotdatawas providedtoevaluate the assumptionof linearity.Itisnotedthatthere are some outlierswithinthe datasetinregardstoAADRand Deaths. c. Create a matrix for calculatingbivariate correlations: > correlation = data.frame(DEATHS, AADR)
- 9. Final Project|Stephanie Bax 9 > correlationm = as.matrix(correlation) > library("Hmisc", lib.loc="~/R/win-library/3.3") > correlatem = rcorr(correlationm) > correlatem DEATHS AADR DEATHS 1.00 0.88 AADR 0.88 1.00 n= 36 P DEATHS AADR DEATHS 0 AADR 0 d. Create a table in yourdocumentthatdisplayseachvariable’smean,standarddeviation, and bivariate correlationcoefficients,starringthose thatare significant > describe(USADeathCauses) vars n mean sd median trimmed mad min max range YEAR* 1 36 1.50 0.51 1.50 1.50 0.74 1.00 2.0 1.00 CAUSE_NAME* 2 36 3.50 1.73 3.50 3.50 2.22 1.00 6.0 5.00 STATE* 3 36 2.00 0.83 2.00 2.00 1.48 1.00 3.0 2.00 DEATHS 4 36 1790.03 3293.06 538.00 1033.20 547.82 64.00 14095.0 140 31.00 AADR 5 36 40.28 58.82 11.44 29.74 8.55 3.53 194.7 1 91.17 CAUSE_NAMELH* 6 36 1.67 0.48 2.00 1.70 0.00 1.00 2.0 1.00 skew kurtosis se YEAR* 0.00 -2.05 0.08 CAUSE_NAME* 0.00 -1.36 0.29 STATE* 0.00 -1.58 0.14 DEATHS 2.80 7.34 548.84 AADR 1.66 1.13 9.80 CAUSE_NAMELH* -0.68 -1.58 0.08 Table PCorr Mean SD DEATHS AADR DEATHS 1790.03 3293.06 --- .88*** AADR 40.28 58.82 .88*** --- *significantatalphalevel .05 **significantatalphalevel .01 ***significantatalphalevel .001 To determine significance –goto pg 185 and view “Critical Valueof Pearsonsr”table.Since ourdf is 36 - 2 = 34, we use the df of 30 whichroundsupto our df of 34. We thenview the valuesunderTwo-Tailed or Nondirectionaltestfor.05 (.3494), .01 (.4487), and.001 (.5541). Whenplottedona normal curve,.88 fallstothe rightof these values,makingitsignificantatall three alphalevels.
- 10. Final Project|Stephanie Bax 10 e. PearsonCorrelation –9 StepHypothesisTesting: 1) H0: No significantrelationshipexistsbetweennumberof deaths(DEATHS) andAge AdjustedDeath Rates(AADR). 2) H1: A significantrelationshipexistsbetweennumberof deaths(DEATHS) andAge AdjustedDeath Rates(AADR). 3) Test: PearsonCorrelation 4) Alpha:.05 5) df: N-2=> 36 – 2 = 34 6) Critical Value:p< .001, p < .05 7) CalculatedValue:0.88 8) Decision:Since ourpvalue isbeyondouralphalevel,we rejectH0and acceptH1. 9) Interpretation:There wasasignificantpositive correlation(0.88) betweennumberof deaths (DEATHS) and Age AdjustedDeathRates(AADR). ***Regression Analysis*** Does number of deaths significantly predict AADR? > regDEATHSAADR = lm(USADeathCauses$DEATHS~USADeathCauses$AADR) > regDEATHSAADR Call: lm(formula = USADeathCauses$DEATHS ~ USADeathCauses$AADR) Coefficients: (Intercept) USADeathCauses$AADR -199.93 49.41 > summary(regDEATHSAADR) Call: lm(formula = USADeathCauses$DEATHS ~ USADeathCauses$AADR) Residuals: Min 1Q Median 3Q Max -3749.8 -166.2 58.3 366.9 4675.7 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -199.931 318.800 -0.627 0.535 USADeathCauses$AADR 49.406 4.515 10.943 1.1e-12*** (Intercept) USADeathCauses$AADR *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 1571 on 34 degrees of freedom Multiple R-squared: 0.7789, Adjusted R-squared: 0.7724 F-statistic: 119.8 on 1 and 34 DF, p-value: 1.103e-12***
- 11. Final Project|Stephanie Bax 11 *significantatalpha.05 **significantatalpha.01 ***significantatalpha.001 Our p value forthe F-testislessthanour alphavalue.Itis beyondouralphavalue.So,we reject the null and acceptH1. Since our F-testwassignificant,we evaluate ourpredictorviathe t-test. i. RegressionAnalysis –9 StepHypothesisTesting: 1) H0: Our regressionmodelwithnumberof deathsdoesnotsignificantly predictAADR. 2) H1: Our regressionmodelwithnumberof deathsdoessignificantlypredict AADR. 3) Test: Regression - Assumptionstobe aware of:Independence,Homogeneity,Normality,Linearity 4) Alpha:.05 5) df: 1, 34 6) Critical Value: F = p < .05, p < .001 (p= 1.103e-12 for F-test) and t = p < .05, p < .001 (p = 1.1e-12 fort-test) 7) CalculatedValue:F= 119.8, t = 10.943 8) Decision:Since ourp-value forourF-testandt-testwere significant,we reject the null forthe model andfornumberof deaths.We accept alternate H1. 9) Interpretation: Ourregressionmodelwassignificantandaccountedfor77% of the variance inAADR(AdjustedR^2= 0.772) AADR. Numberof deaths significantlyandpositivelypredictedAADR. ii. If numberof deathswas300, what isthe predicted AADR? - We knowthat Y’ = a + bX - Seeingabove thatouroutputgeneratedthe intercept(-199.93) andslope (49.41), we can predictthe AADRfor numberof deathsof 300 wouldbe 14623.07. > AADRy = -199.93 + 49.41*300 > AADRy [1] 14623.07 ***ANOVA*** Did causes of death (CAUSE_NAME) differ in terms of number of deaths (DEATHS)? f. Use the “lm” and then“anova”commandsto investigate the following: i. Did causesof death(CAUSE_NAME) differintermsof numberof deaths (deaths)? > causenameondeaths = lm(USADeathCauses$DEATHS~USADeathCauses$CAUSE_NAME) > causenameondeaths
- 12. Final Project|Stephanie Bax 12 Call: lm(formula = USADeathCauses$DEATHS ~ USADeathCauses$CAUSE_NAME) Coefficients: (Intercept) USADeathCauses$CAUSE_NAME.L 1790.0 583.8 USADeathCauses$CAUSE_NAME.Q USADeathCauses$CAUSE_NAME.C -3344.9 -1460.1 USADeathCauses$CAUSE_NAME^4 USADeathCauses$CAUSE_NAME^5 1826.1 4916.8 > causenameondeathsanova = anova(causenameondeaths) > causenameondeathsanova Analysis of Variance Table Response: USADeathCauses$DEATHS Df Sum Sq Mean Sq F value USADeathCauses$CAUSE_NAME 5 247027691 49405538 11.184 Residuals 30 132521116 4417371 Pr(>F) USADeathCauses$CAUSE_NAME 3.799e-06 *** Residuals --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 > describeBy(USADeathCauses$DEATHS, group = USADeathCauses$CAUSE_NAME) > library("psych", lib.loc="~/R/win-library/3.3") > describeBy(USADeathCauses$DEATHS, group = USADeathCauses$CAUSE_NAME) $Homicide vars n mean sd median trimmed mad min max range X1 1 6 195.83 165.74 110 195.83 60.05 64 424 360 skew kurtosis se X1 0.52 -1.94 67.66 $Stroke vars n mean sd median trimmed mad min max X1 1 6 1697.17 1008.64 1331.5 1697.17 790.97 776 2989 range skew kurtosis se X1 2213 0.41 -1.96 411.77 $`Chronic liver disease and cirrhosis` vars n mean sd median trimmed mad min max X1 1 6 337.67 195.12 249 337.67 105.26 175 598 range skew kurtosis se X1 423 0.48 -1.95 79.66 $`Diseases of Heart` vars n mean sd median trimmed mad min max X1 1 6 7542.5 5022.14 5365 7542.5 2996.33 3307 14095 range skew kurtosis se X1 10788 0.46 -1.96 2050.28 $Suicide vars n mean sd median trimmed mad min max X1 1 6 542.17 325.02 463.5 542.17 352.12 220 960 range skew kurtosis se X1 740 0.29 -1.96 132.69 $Septicemia vars n mean sd median trimmed mad min max X1 1 6 424.83 306.23 363.5 424.83 364.72 109 809 range skew kurtosis se
- 13. Final Project|Stephanie Bax 13 X1 700 0.24 -1.95 125.02 attr(,"call") by.default(data = x, INDICES = group, FUN = describe, type = type) g. Create an ANOVA table of the resultsinyourWordfile Variance SS df MS F-ratio BetweenGroups 247027691 5 49405538 11.184*** WithinGroups 132521116 30 4417371 --- Totals 379548807 35 --- --- *significantatalpha.05 **significantatalpha.01 ***significantatalpha.001 h. ANOVA –9 StepHypothesisTesting: 1) H0: There are nodifferencesbetweencauses of death(CAUSE_NAME) andnumberof deaths(DEATHS). 2) H1: There are differencesbetweencausesof death(CAUSE_NAME) andnumberof deaths(DEATHS). 3) Test: One-way,Fixed ANOVA - Assumptionstobe aware of:Independence,Normality,Homogeneity 4) Alpha:.05 5) df: 5, 30 6) Critical Value:F= p < .05, p < .001 7) CalculatedValue:F= 11.18 8) Decision:Since ourp-value forthe F-testisbeyondouralphavalue,we rejectthe null. 9) Interpretation:There weresignificantdifferencesbetweencausesof death (CAUSE_NAME) and numberof deaths(DEATHS). ***Chi Square for Independent Values*** Did the state (STATE) in which the death occurred depend on the cause of death? > indepstate = chisq.test(USADeathCauses$STATE, USADeathCauses$CAUSE_NAME) > indepstate Pearson's Chi-squared test data: USADeathCauses$STATE and USADeathCauses$CAUSE_NAME X-squared = 0, df = 10, p-value = 1 > indepstate$expected USADeathCauses$CAUSE_NAME USADeathCauses$STATE Homicide Stroke Chronic liver disease and cirrhosis Kansas 2 2 2
- 14. Final Project|Stephanie Bax 14 Missouri 2 2 2 Nebraska 2 2 2 USADeathCauses$CAUSE_NAME USADeathCauses$STATE Diseases of Heart Suicide Septicemia Kansas 2 2 2 Missouri 2 2 2 Nebraska 2 2 2 > indepstate$observed USADeathCauses$CAUSE_NAME USADeathCauses$STATE Homicide Stroke Chronic liver disease and cirrhosis Kansas 2 2 2 Missouri 2 2 2 Nebraska 2 2 2 USADeathCauses$CAUSE_NAME USADeathCauses$STATE Diseases of Heart Suicide Septicemia Kansas 2 2 2 Missouri 2 2 2 Nebraska 2 2 2 This was to conduct the continuity assumption. Here we see that no expected f requency was below 2. Chi Square – 9 StepHypothesisTesting: 1) H0: The cause of death(CAUSE_NAME) is notdependentonthe state (STATE). 2) H1: The cause of death(CAUSE_NAME) is dependentonthe state (STATE). 3) Test: Chi-Square forIndependence of Categorical Values 4) Alpha:.05 5) df: 10 6) Critical Value:1,p > .05 7) CalculatedValue:X^2= 0 8) Decision:Since ourp-value forthe Chi Square testisnotbeyondouralphavalue,we fail torejectthe null,acceptH0. 9) Interpretation:The cause of death(CAUSE_NAME) wasnotdependentonstate (STATE). 3. An APA write up of the descriptive, correlational, and group comparison analyses with supporting tables - Table outputiscorrect use of APA style foreach table includingindicatingthe variablesthat are significant.14pts. - Interpretationof analysesiscorrectandmeansand SDs are giveninthe write up. 10 pts. a. Distributions,Percentiles,andGraphs – Write Up i. There were six causesof deathevaluatedwithinthree statesovertwo years,makingup36 cases inthisFinal Project. The six causesof deathwere: Homicide,Stroke,Chronicliverdisease andcirrhosis,Diseasesof the Heart, Suicide,andSepticemia.The statesinwhichthese deathsoccurredwere Kansas, Missouri,andNebraska.These occurredovera periodof twoyearsin2012 and 2013.
- 15. Final Project|Stephanie Bax 15 Of these 36 cases,12 of themwere inKansas,12 of themwere in Missouri,and12 of themwere inNebraska.Thismade up 33% eachfor Kansas, Missouri,andNebraska. These occurredovertwoyearsof 2012 and 2013, with 18 (or 50%) of cases beingin2012 and18 (or50%) of casesbeingin2013. Additionally,of the 36 cases,6 (17%) were due toHomicide,6 (17%) were due to Stroke,6 (17%) were due toChronicliverdisease andcirrhosis, 6(17%) were due to Diseasesof Heart, 6 (17%) were due toSuicide,and6 (17%) were due to Septicemia. Of the 34 cases,12 (or 33%) were deemedNon-Medical,meaningdeath relatedtoeitherHomicide orSuicide.The other24 cases (or66%) were deemed Medicallyrelateddeathsdue toeitherDiseasesof the Heart,Stroke, Septicemia,orChronicliverdiseaseand cirrhosis. In thisFinal Project,the nominal andordinal variablesare:state (STATE),cause of death(CAUSE_NAME),and type of death(MEDICAL or NONMEDICAL). The interval andratiovariableswere:numberof deaths (DEATHS) and Age AdjustedDeathRate (AADR). b. Measuresof Central Tendency& Variability – Write Up i. We collecteddataaboutDeaths(M= 1790.03, SD = 3293.06) andAADR (M= 40.28, SD = 58.82). Descriptives forthe state of Kansasonlyspecificallywere: Deaths(M= 1313.75, SD 1936.41) and AADR (M= 39.11, SD = 56.38). c. IndependentSample T-Test– Write Up i. We assesseddifferencesinnumberof deathsbetween the twoyearswithan independentsamplest-test.Priortoconductingthe test,assumptionsfor normalityandhomogeneityof variance were assessedandwere bothmetand all otherassumptionswere supported. The ShapiroWilkstestfoundthatour differencesdidfollow anormal curve (p> .05). The resultof our t-test,t(34) = - 0.02, p > .05, suggeststhatno significantdifferencesexistbetweenthe years 2012 and 2013 on numberof deaths. d. Pearson Correlation– Write Up i. Means,standard deviations,andcorrelationsforourfull datasetare listed in Table PCorr above.All assumptionswereevaluatedandgenerallymet.Intesting our linearityassumption,alinearfashionof datapointswasnotedwithsome outlierswithinthe scatterplotshownabove,sothe resultsshouldbe interpretedwithsomecaution. We were particularlyinterestedinthe correlationbetweendeaths(M= 1790.03, SD = 3293.06) and AADR(M= 40.28, SD = 58.82) inour full dataset,andwe founda strong, positive correlation,r(34) = .88, p < .001, existed. e. Regression– Write Up i. Regressionanalysiswasusedtotestif numberof deaths(DEATHS) significantly predictedAge AdjustedDeathRates(AADR).The resultssuggestthe model did significantlypredictAADRwithalarge effectsize (R^2= .772, F(1,34) = 119.80, p < .001). Deaths(t(34) = 10.94, p < .001) was a significantpredictorof AADR witha 49.41 increase inAADRforeveryone unit increase innumberof deaths.
- 16. Final Project|Stephanie Bax 16 Coefficientof determination(R^2): Small effect=.01 to .09 Mediumeffect=.09 to .25 Large effect=> .25 f. ANOVA– Write Up i. A one-wayANOVAindicatedthatcause of deathwassignificantlydifferentin regardsto numberof deaths; F (5, 30) = 11.18, p < .05, p < .001. Diseasesof the Heart (M= 7542.5, SD = 5022.14) had the highestnumberof deathsof the six causesand Homicide (M= 195.83, SD = 165.74) had the lowestnumberof deathsof the six causes. g. Chi Square – Write Up i. A Chi-Square TestforIndependence wasperformedtodetermine if cause of death(CAUSE_NAME) wasdependent state inwhichthe death occurred (STATE).Assumptionsforthe chi square testwere met.Resultssuggestthat there were nosignificantdifferencesbetweenCAUSE_NAMEandSTATE, X^2 (10, N = 36) = 0, p > .05. The above three componentsshouldbe savedto a folderon your computer named "Final Project" (use the course analysis projectsas guidesfor thisprocess). Whencomplete,the foldershouldbe compressedand uploadedto this assignment.