Download to read offline




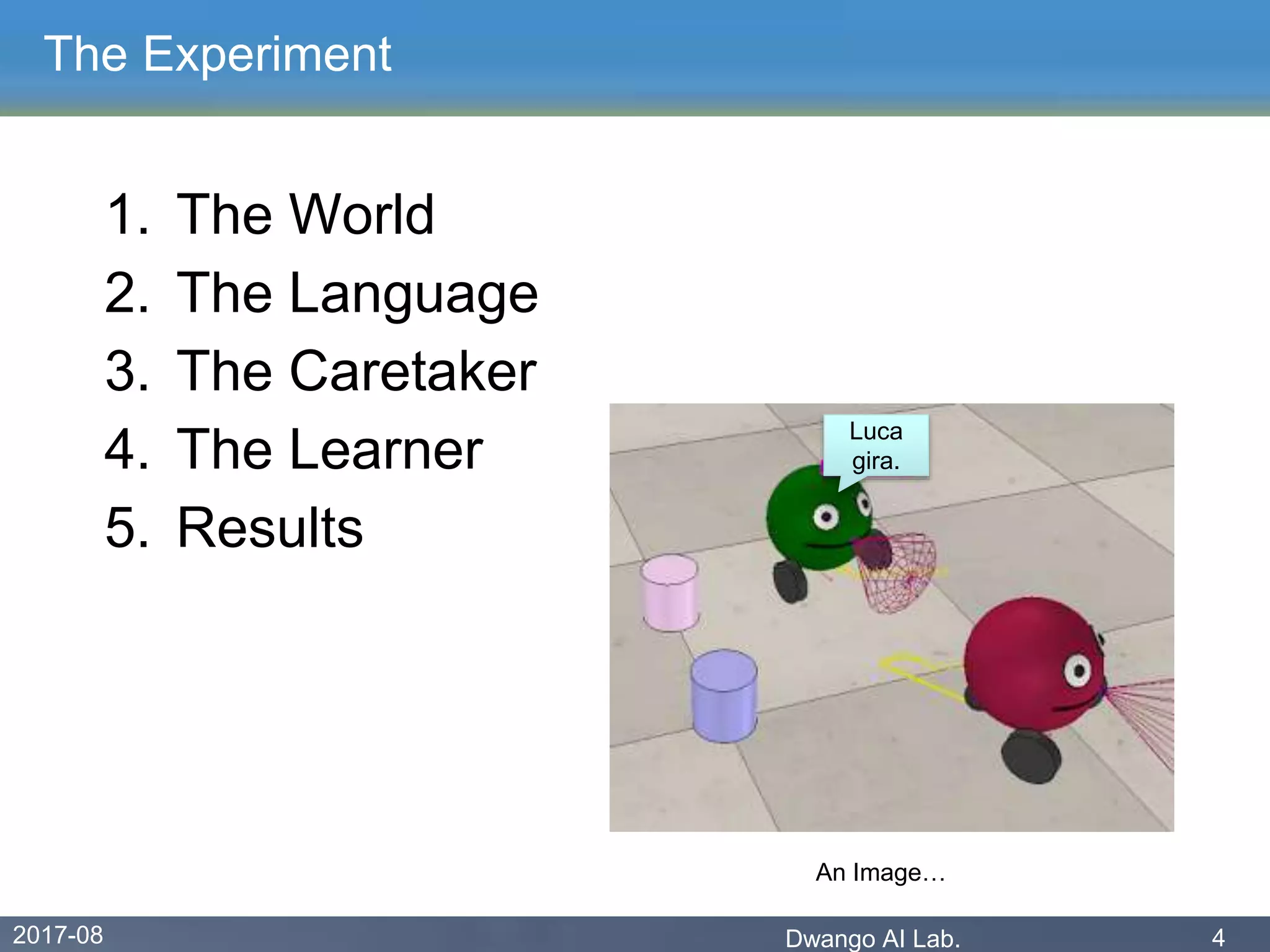



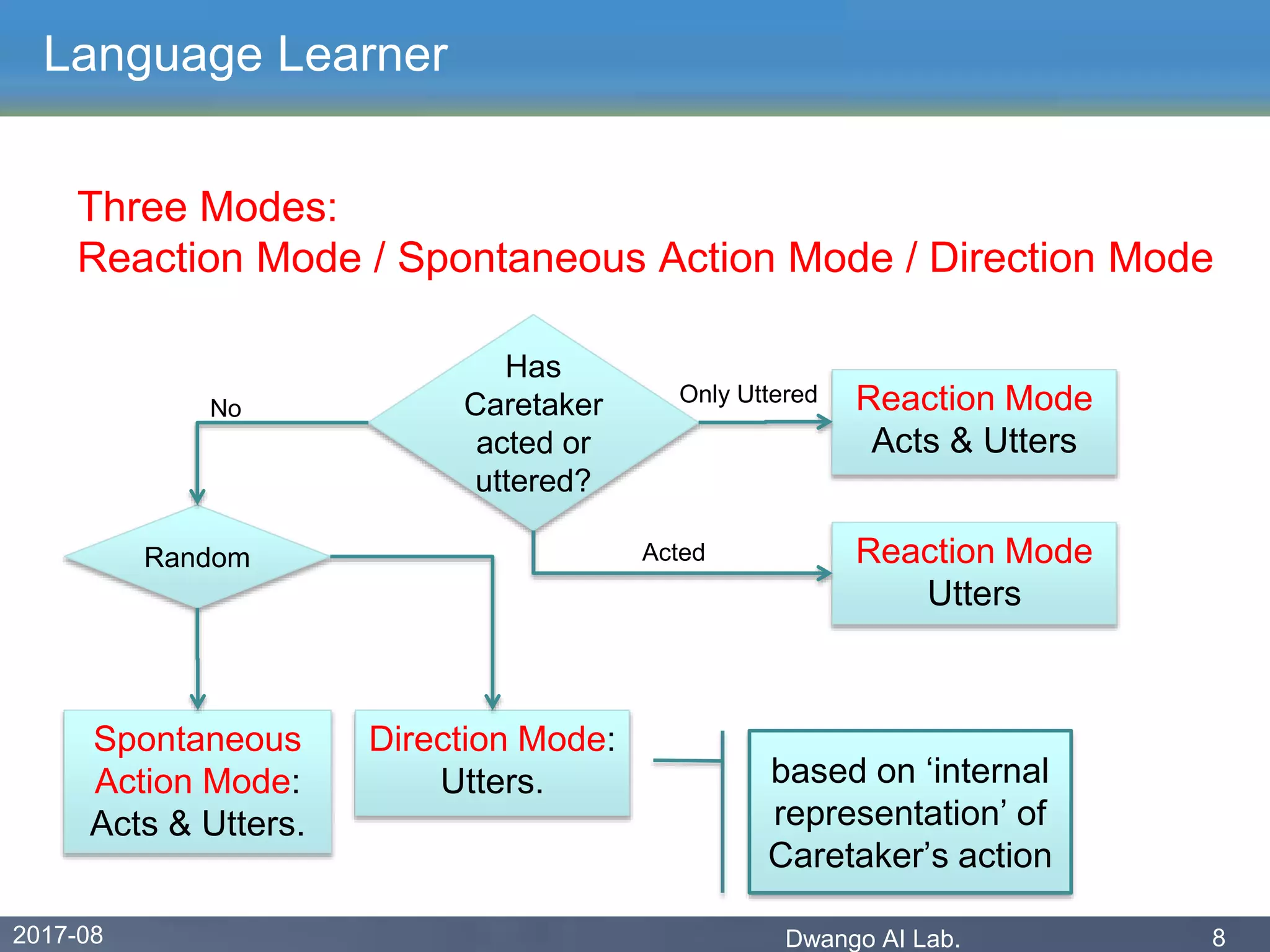


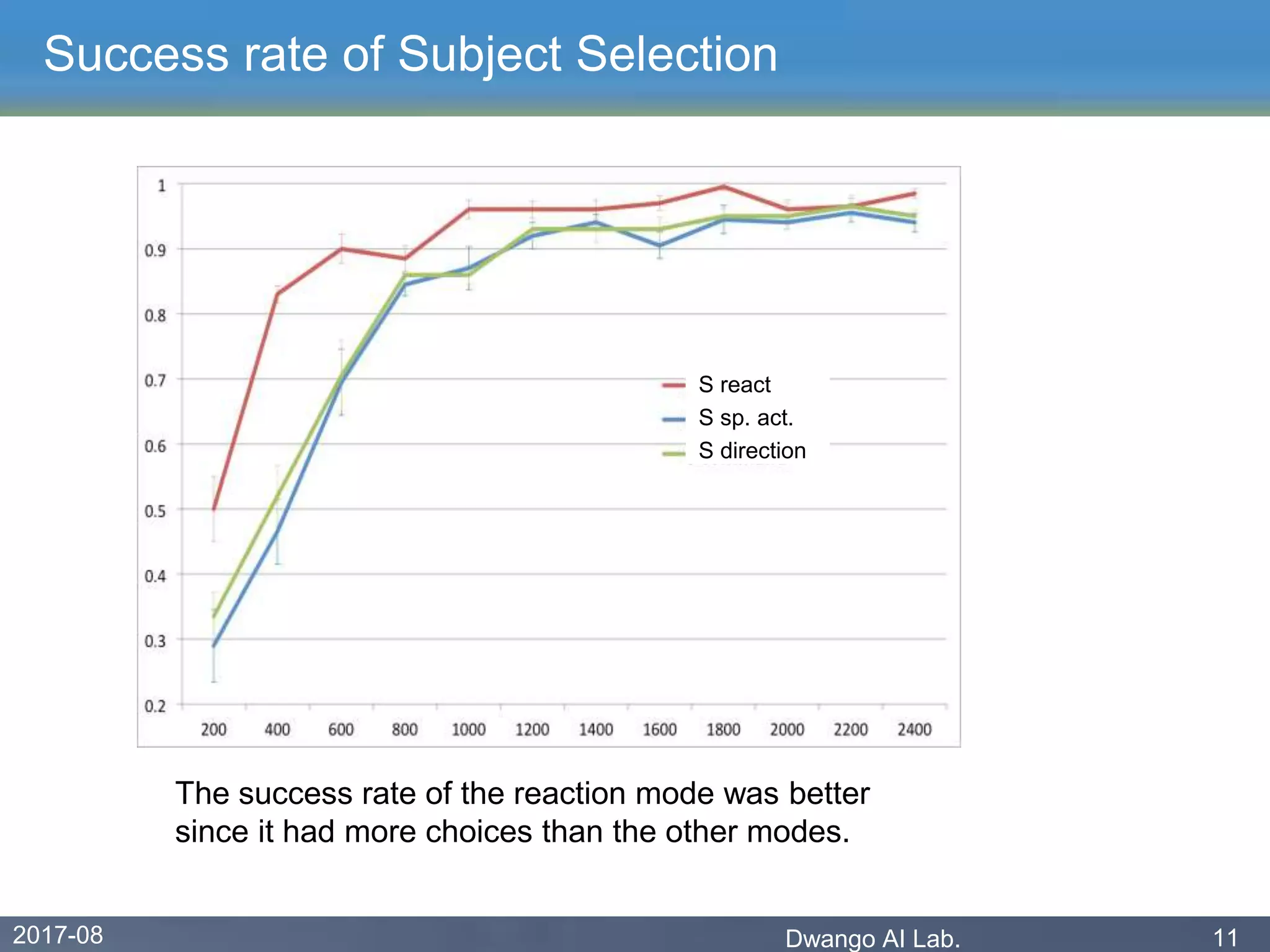
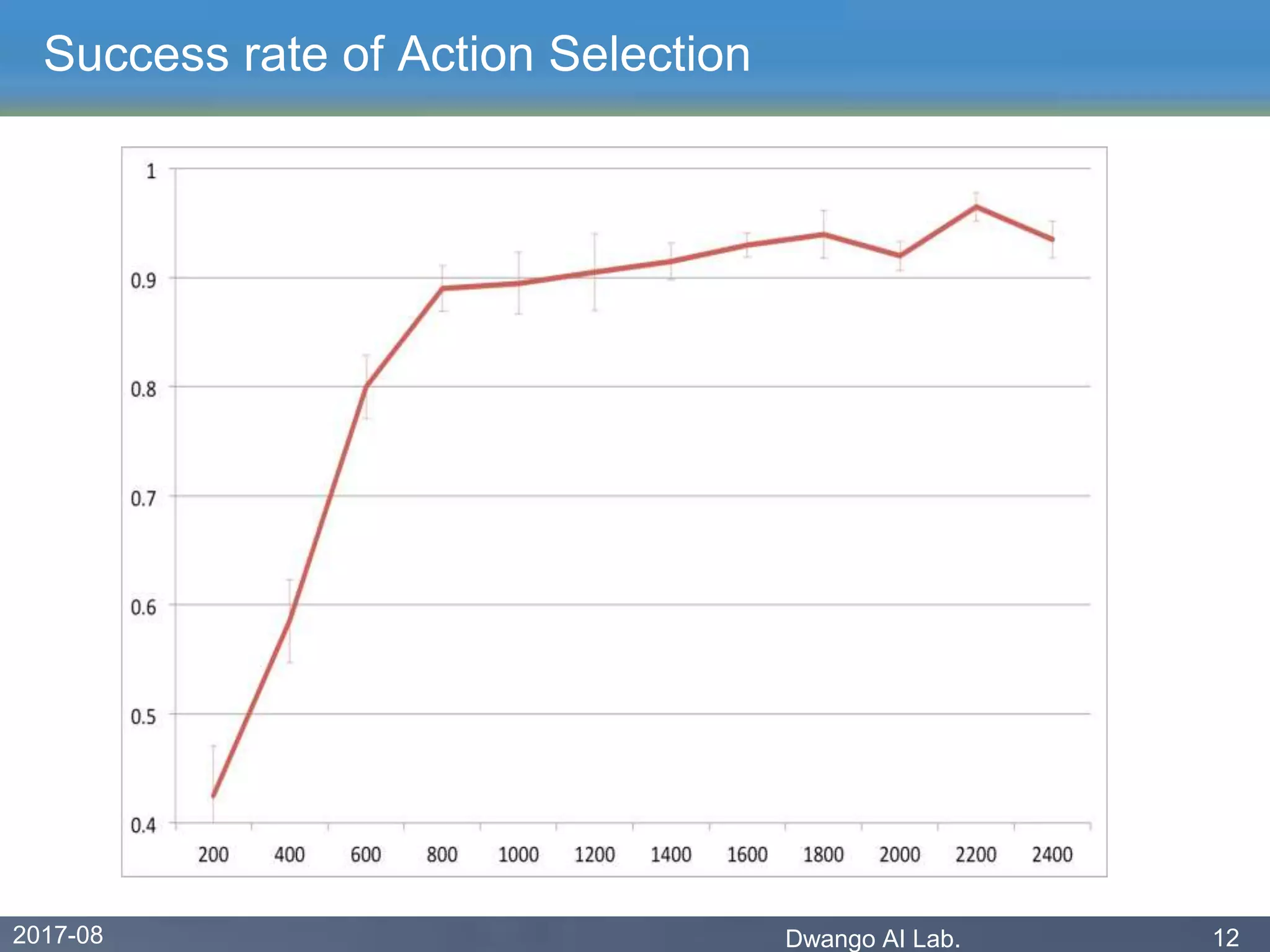







The document discusses an experiment conducted by the Dwango AI Laboratory to simulate language acquisition, specifically the learning of first and second-person pronouns in two-word sentences by a simplified agent interacting with a caretaker. Results showed that the learner could achieve a 90% correctness rate in uttering and acting after 1,200 interactions, indicating that language can be learned from a single caretaker without grounded concepts. The findings highlight the role of rewards, babbling, and various modes of action in the language learning process.





















































