

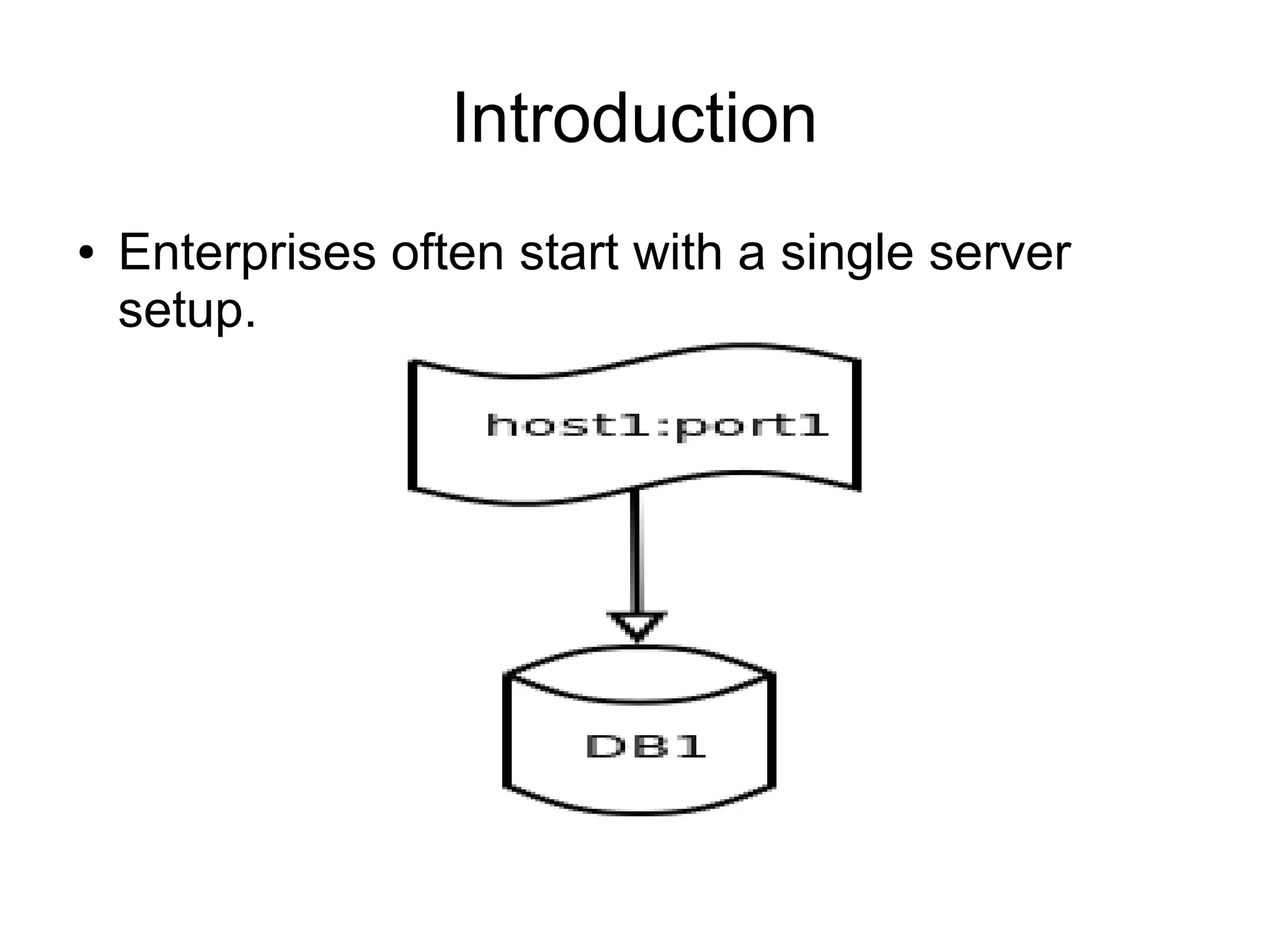











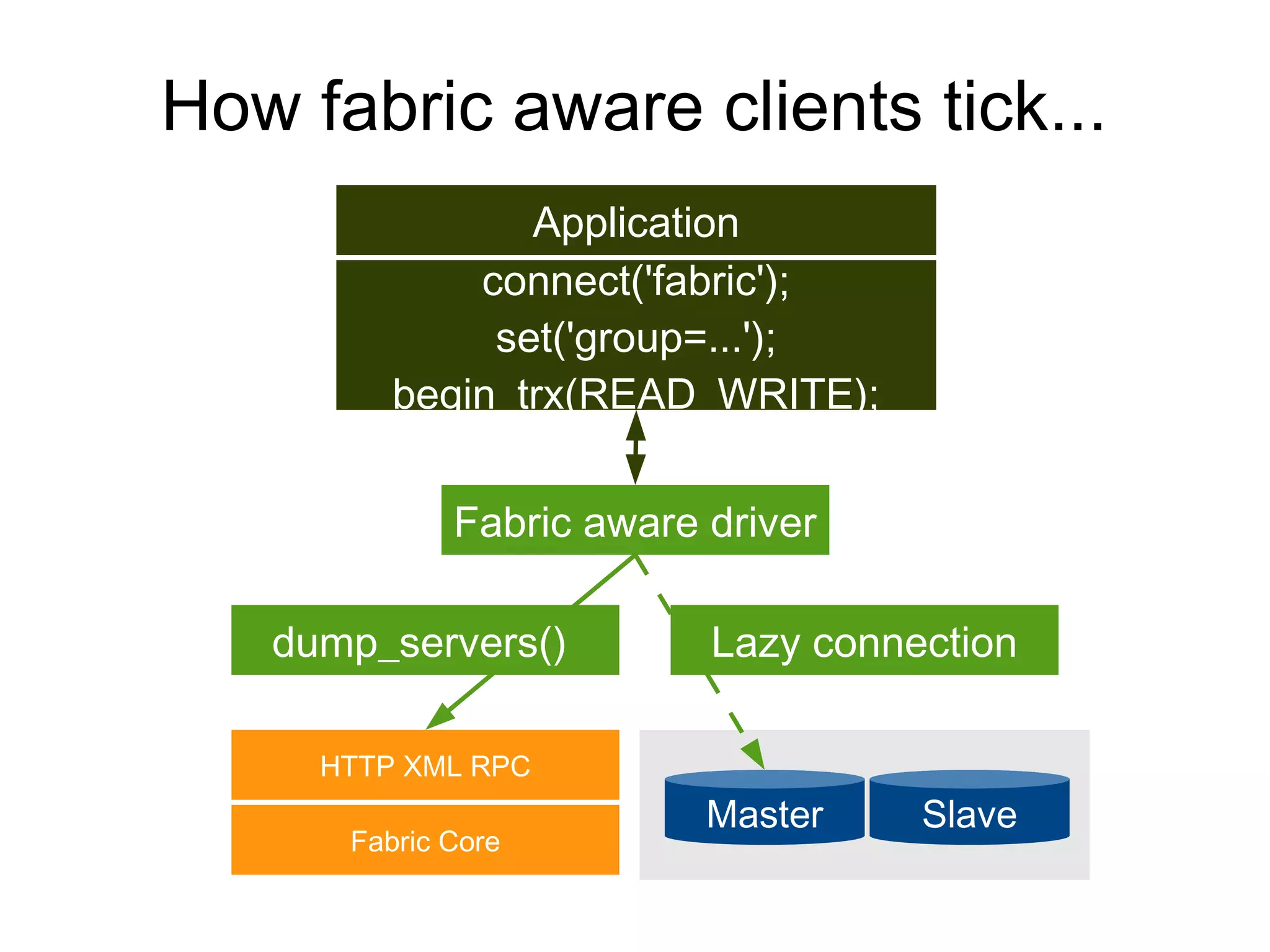




MySQL 5.6 Fabric provides tools for high availability and sharding of MySQL databases. It uses replication to create redundancy and increase availability. Sharding partitions data across multiple database servers to improve scalability. MySQL Fabric manages the replication and sharding configuration, monitoring the clusters and enabling automatic failover. It provides a command line tool and API for distributed database administration. However, sharding does require applications to specify a sharding key and cannot support transactions across shards.



![[db tech showcase Tokyo 2014] B15: Scalability with MariaDB and MaxScale by ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b15mariadbcorporationcolincharlesscalabilitywithmariadbandmaxscale-141208020836-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















