Downloaded 13 times








![soude.fazeli[at]ou[dot]nl
Pagina 19
@SoudeFazeli](https://image.slidesharecdn.com/sfaectel2014slides-140919045227-phpapp02/85/Presentation-on-Recommenders-in-Social-Learning-Platforms-at-iknow2014-ECTEL2014-in-Graz-Sep-2014-19-320.jpg)

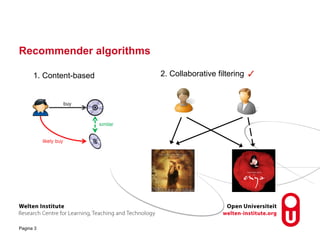
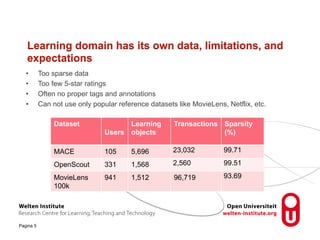
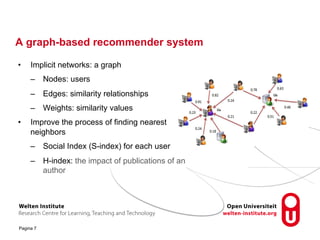
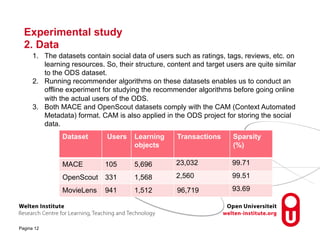
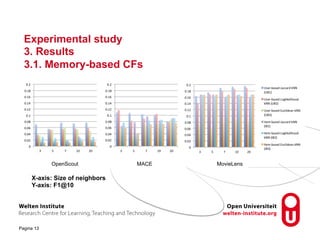
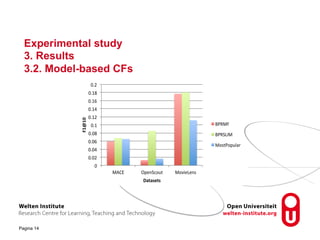
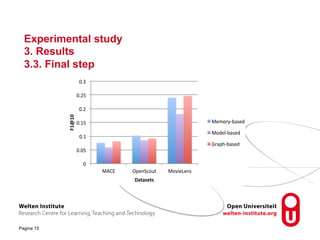
The document discusses research into recommender systems for social learning platforms. It evaluates content-based, collaborative filtering, memory-based, model-based, and graph-based recommender approaches using datasets from MACE, OpenScout, and MovieLens. Graph-based recommender systems performed best by addressing the sparsity problem in educational domains. The implemented graph-based recommender has been integrated into the Open Discovery Space platform and will undergo a user study to evaluate satisfaction metrics like novelty and serendipity.



























