Download to read offline






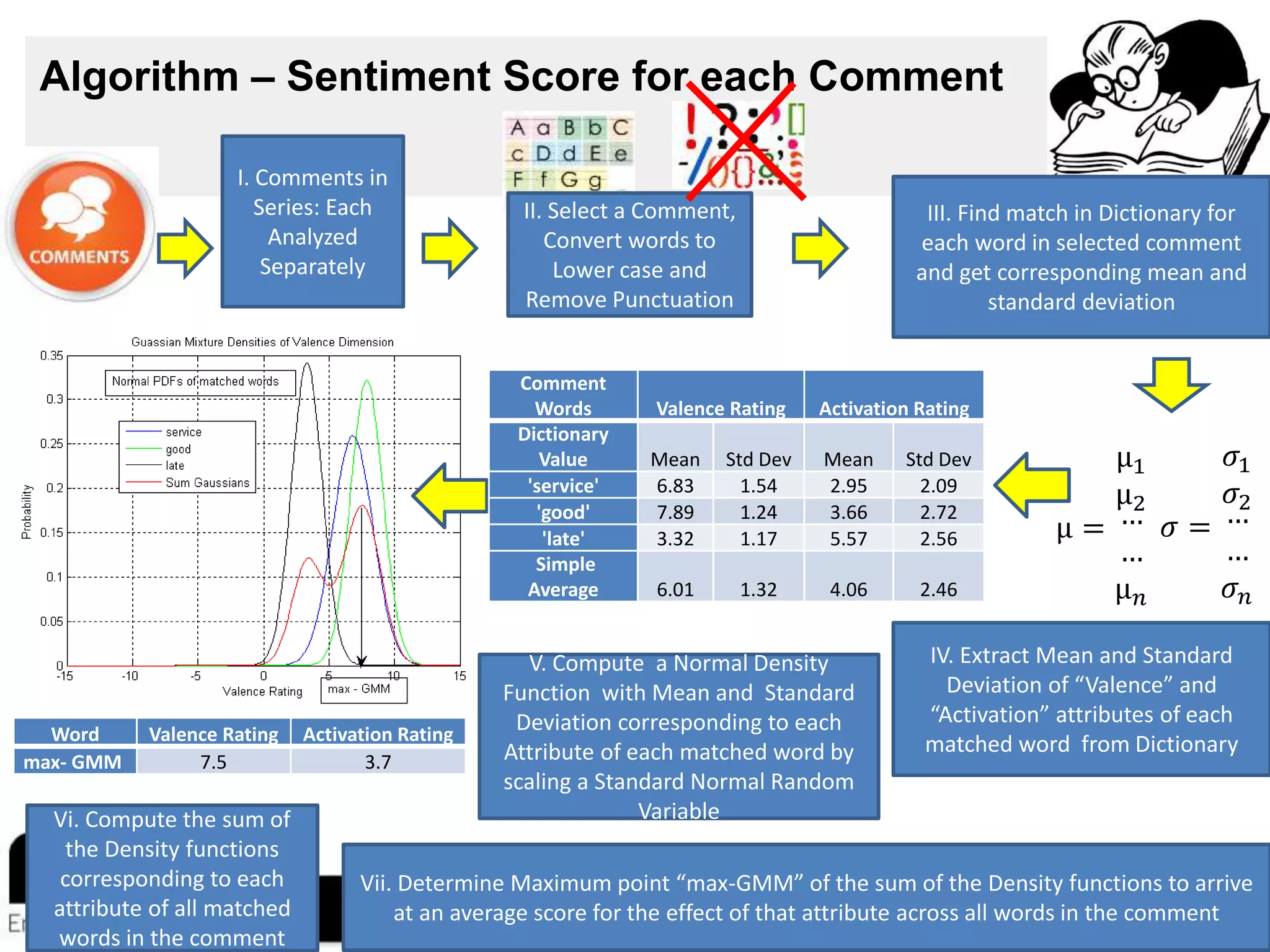

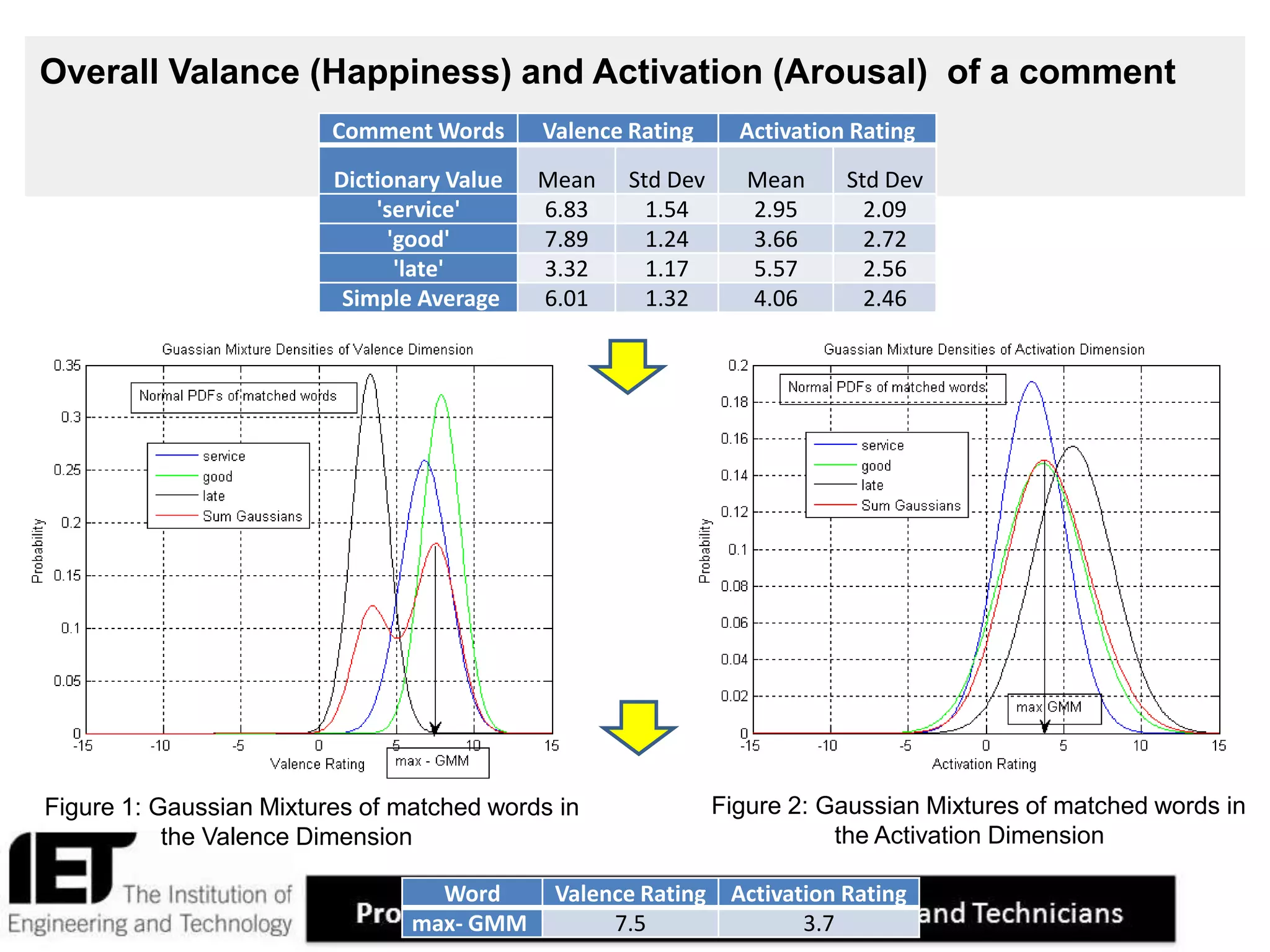
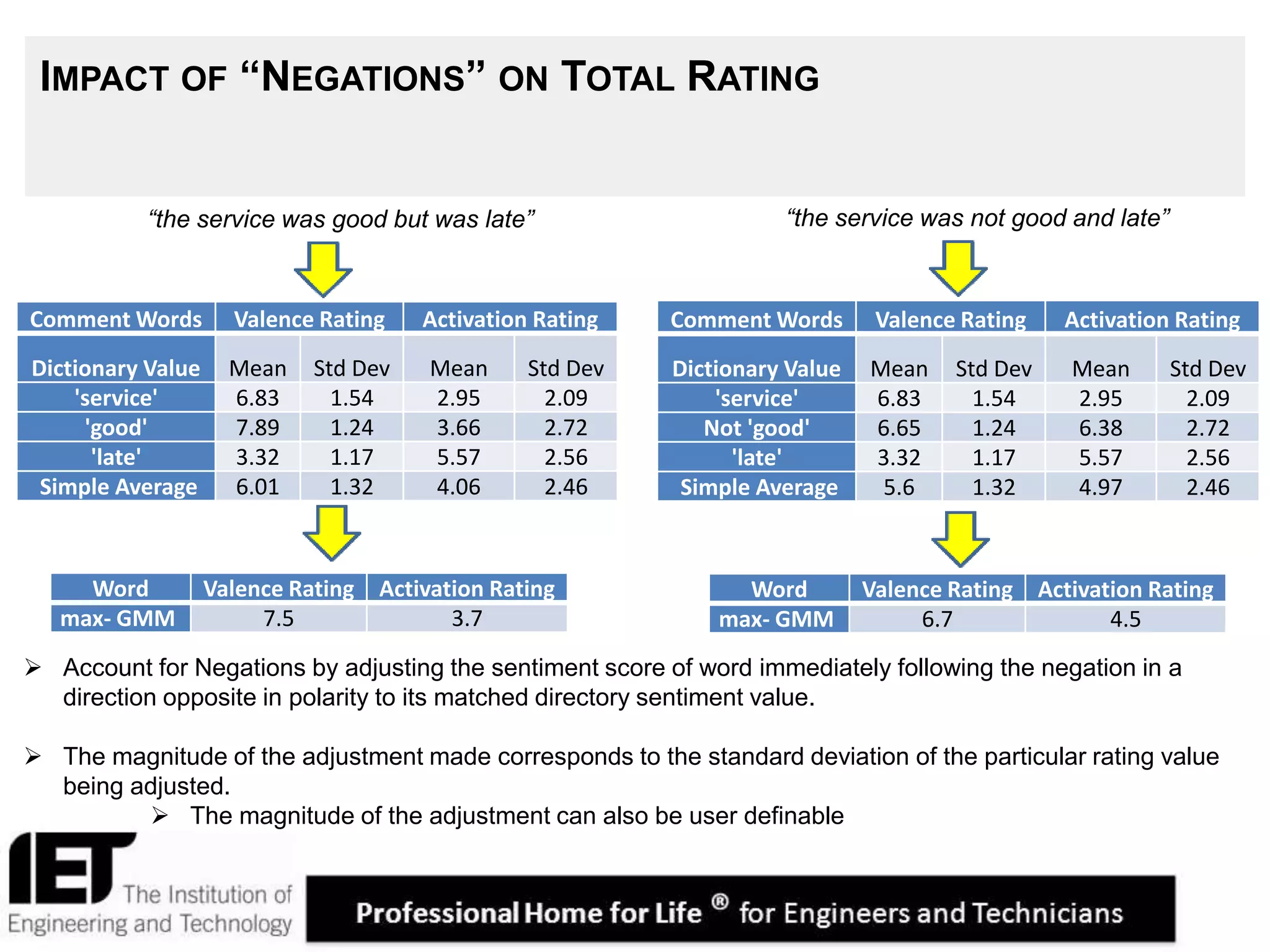
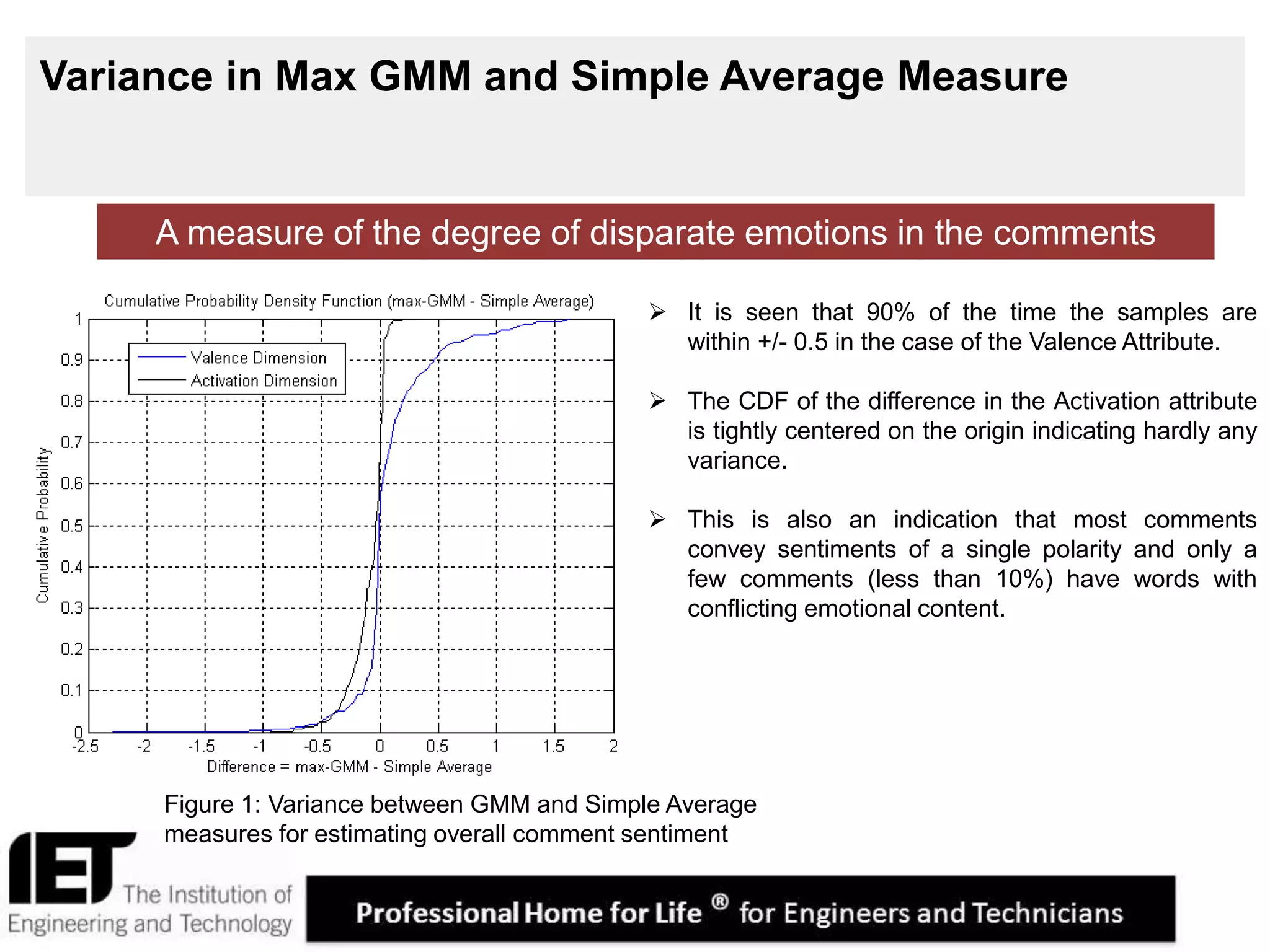
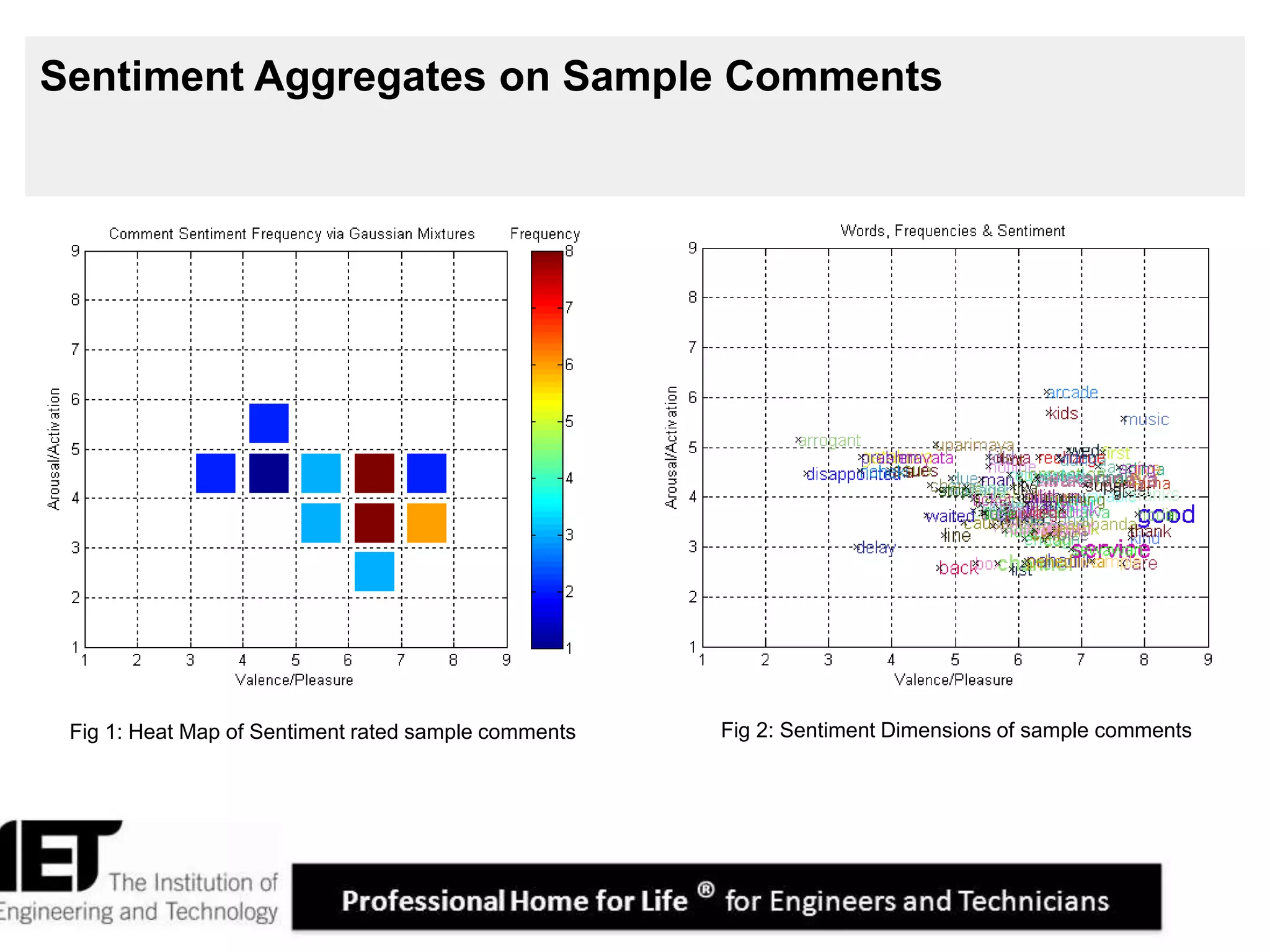








This document describes a sentiment analysis and classification algorithm that utilizes an independent term matching scheme sensitive to word count patterns. The algorithm calculates sentiment scores for comments by determining the Gaussian mixture of the sentiment ratings of matched words in the comment. It accounts for the impact of negations. Sample comments are then classified and rated for sentiment to evaluate the algorithm.

























































