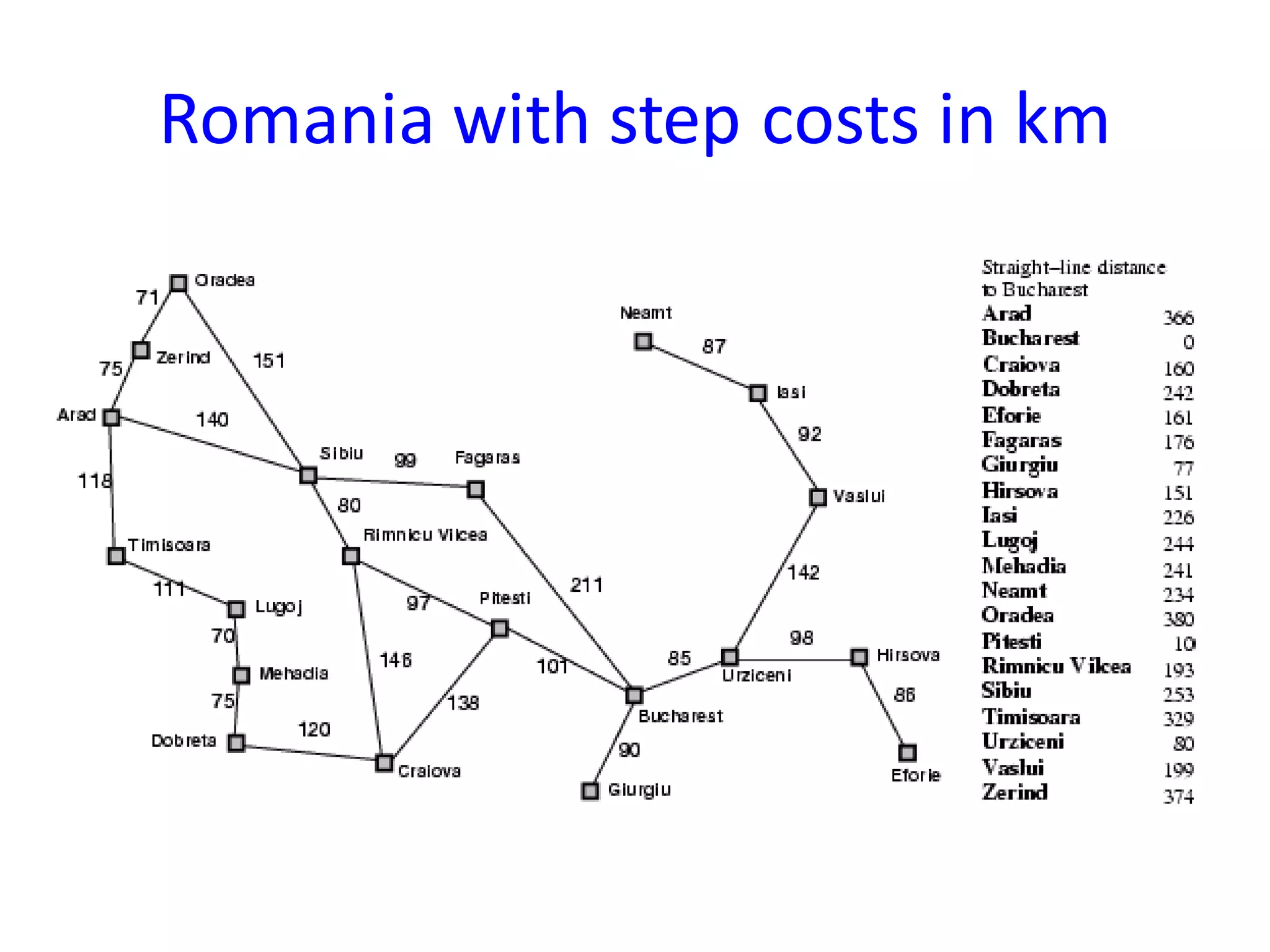
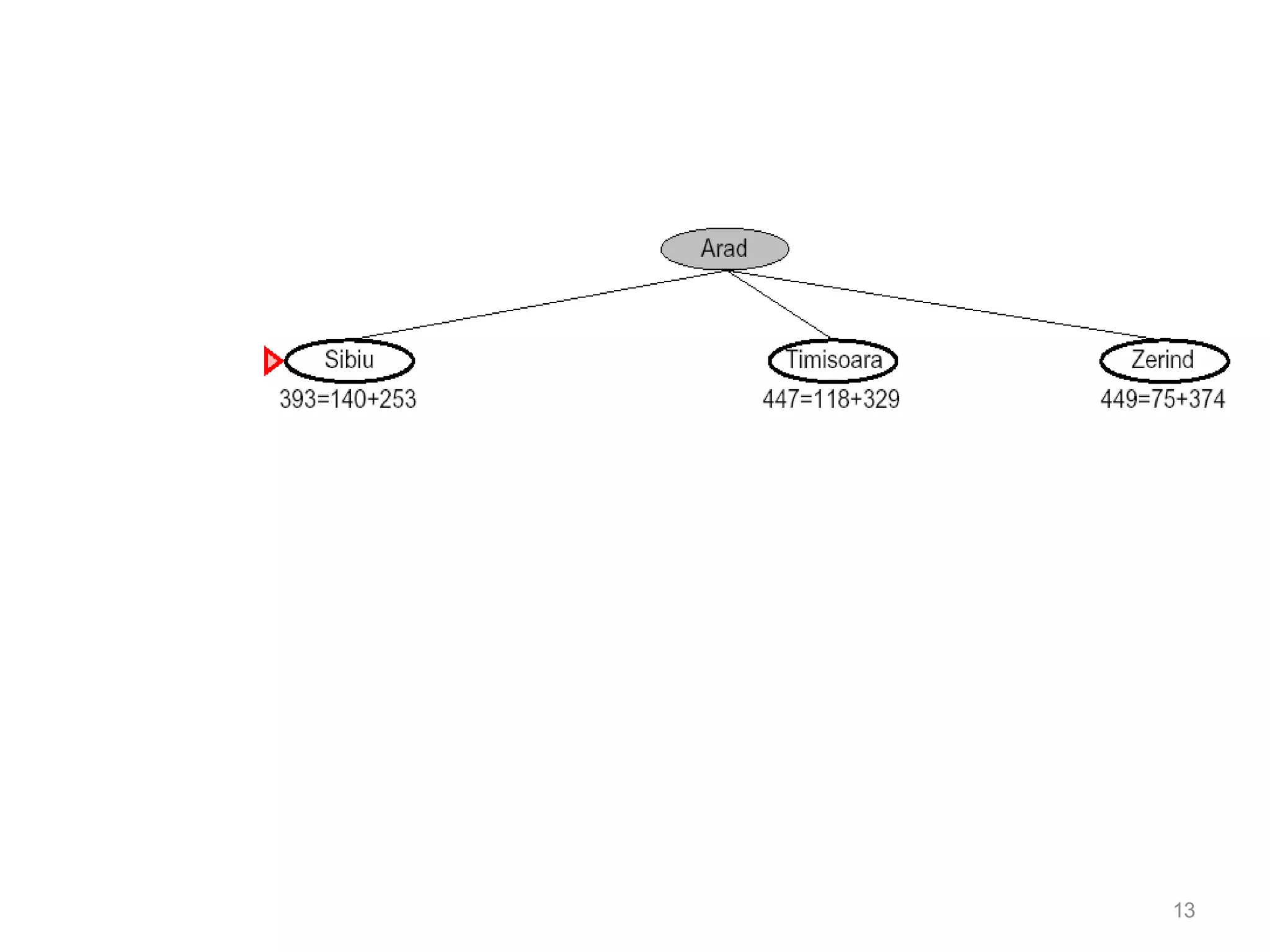
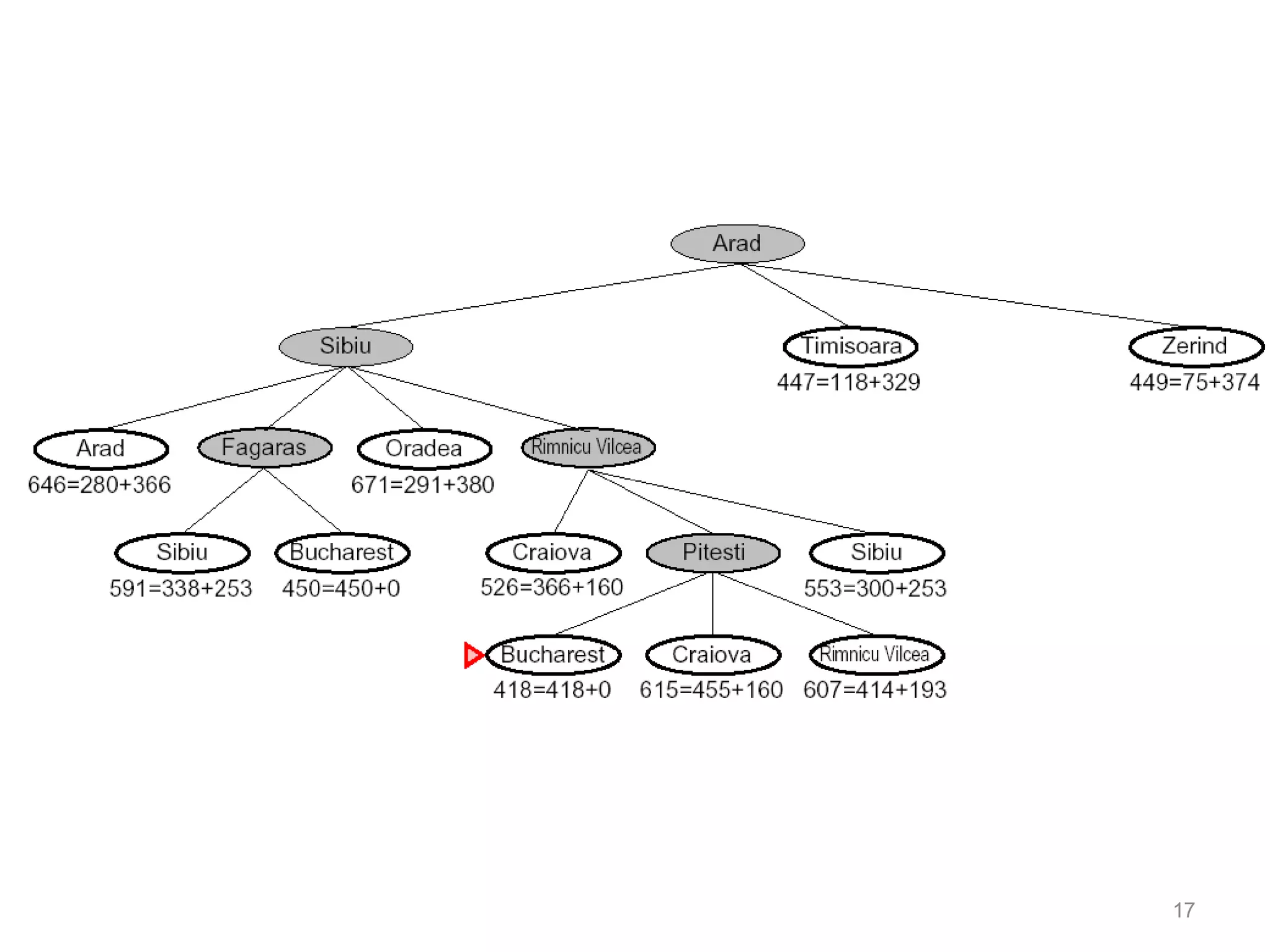
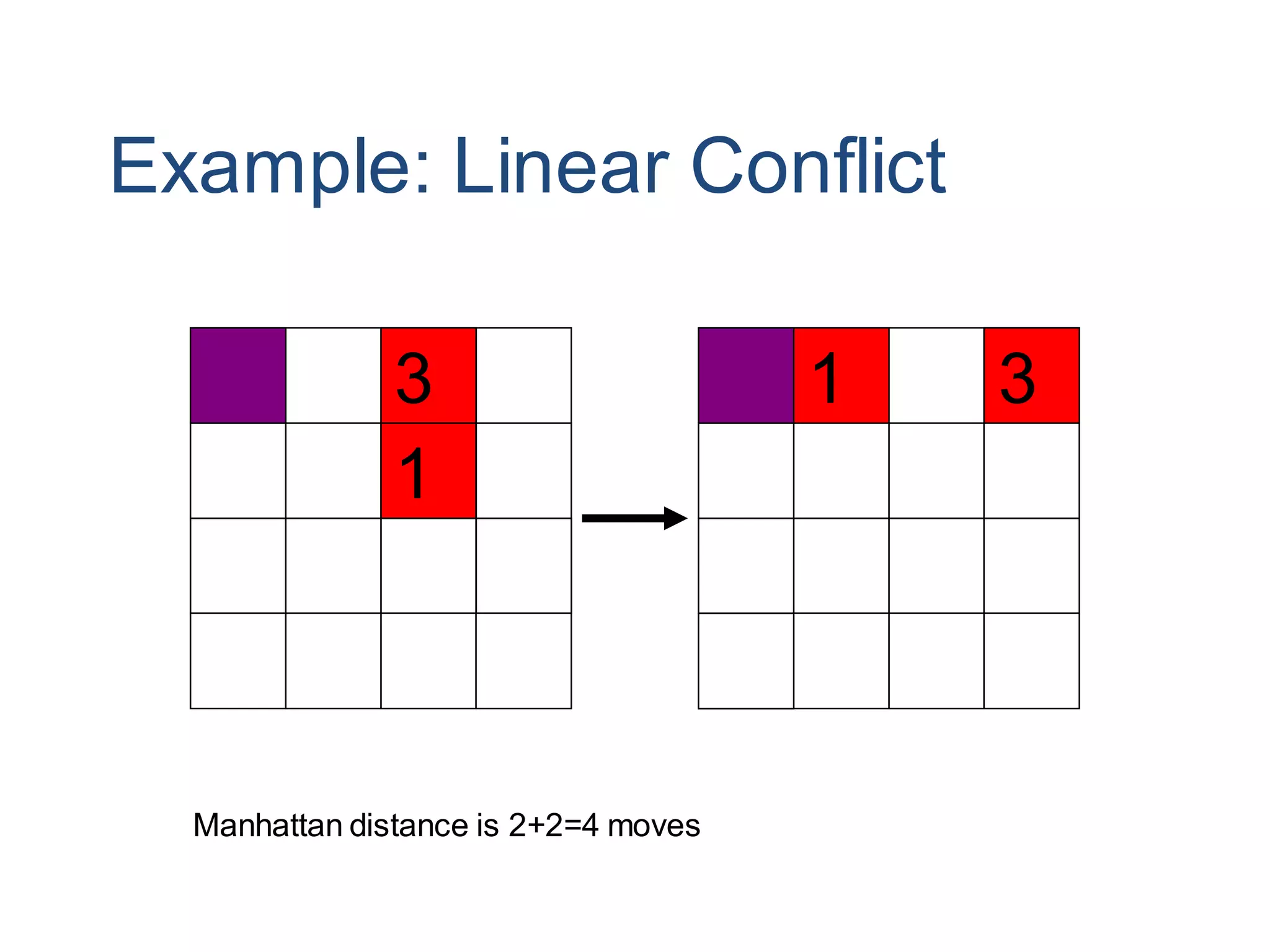
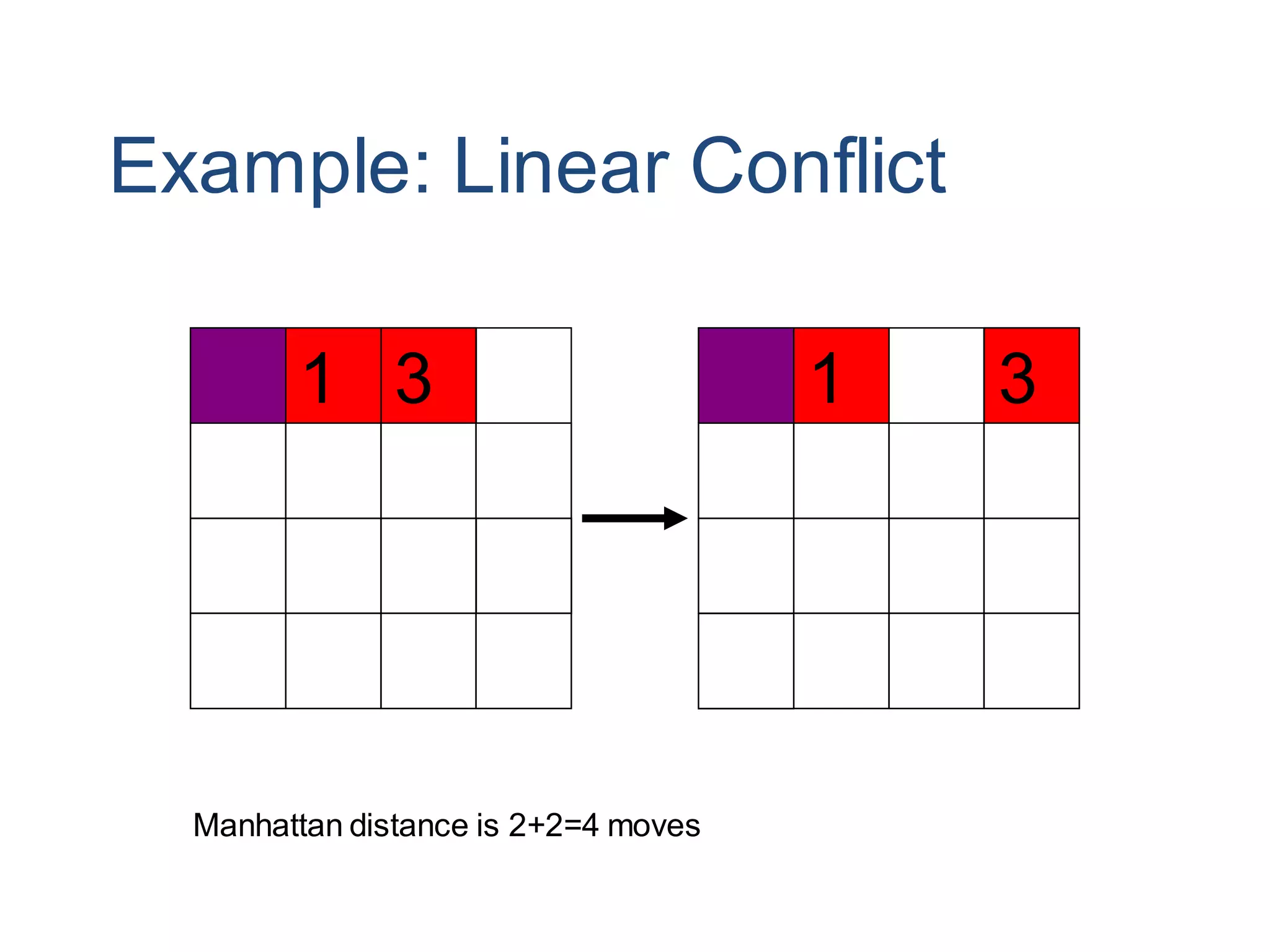
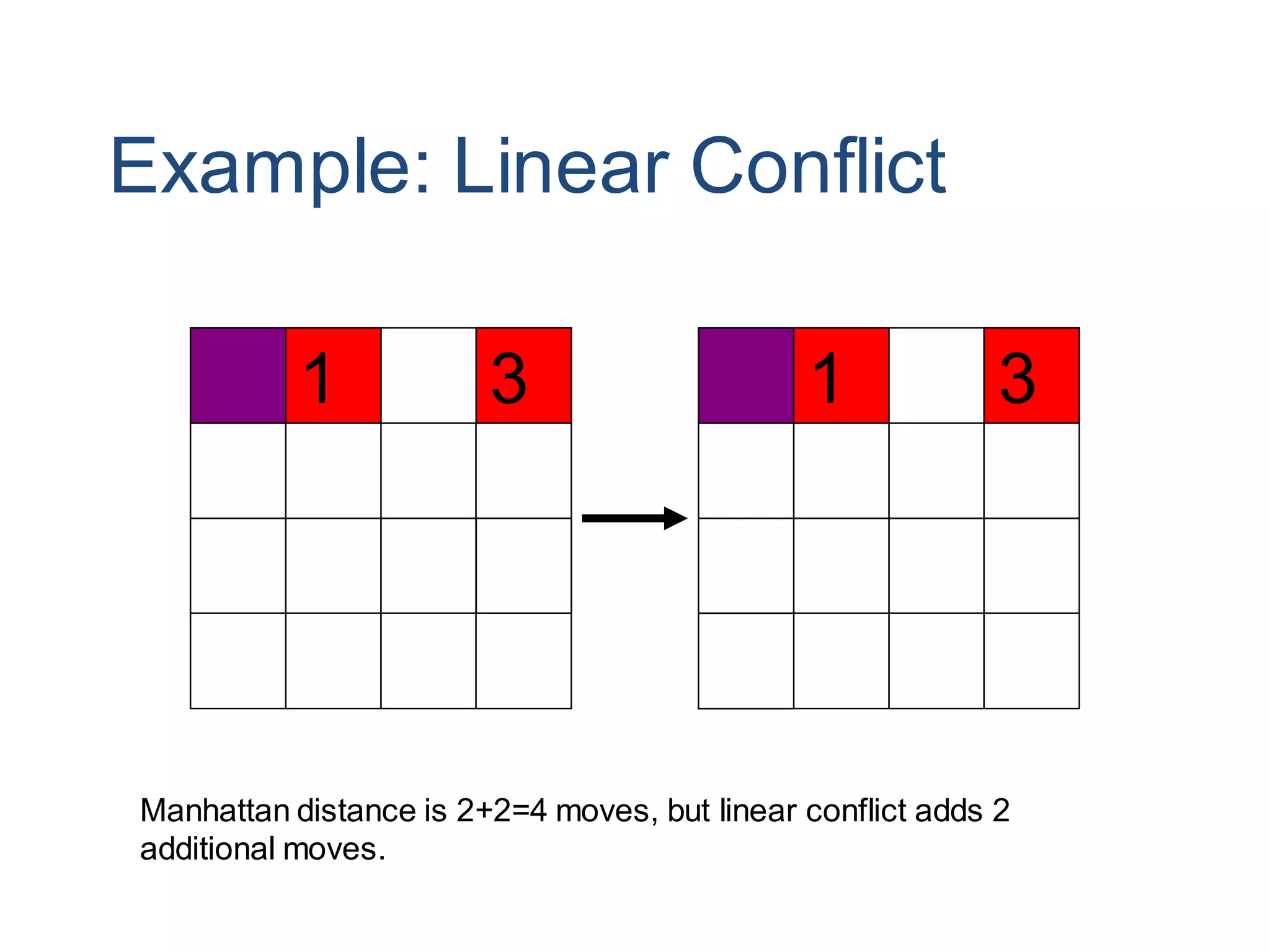
Informed search algorithms aim to be smarter than blind search about which paths to explore by using an evaluation function to estimate the cost to the goal for each node, with best-first search always expanding the node with the lowest estimated cost; A* search combines the cost so far and estimated remaining cost to provide an optimal search when the heuristic is admissible or consistent; pattern database heuristics derive more accurate estimates of moves required by solving subproblems exactly and combining the solutions.