Download as PDF, PPTX








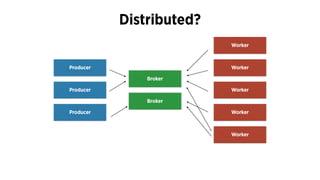
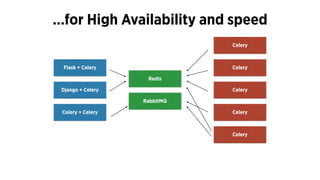




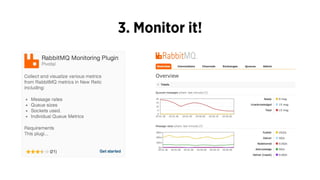


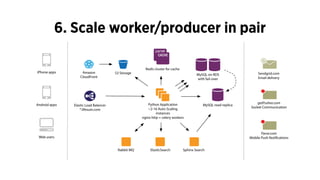






The document discusses the use of Celery, an asynchronous task queue, for managing task processing in Python applications. It outlines the benefits of using task queues, provides code examples for implementing tasks, and shares ten key lessons learned in scaling and optimizing Celery. Additionally, it covers best practices for task management, monitoring, and system architecture considerations.







![[수정본] 우아한 객체지향](https://cdn.slidesharecdn.com/ss_thumbnails/woowahan-oo-190624161343-thumbnail.jpg?width=640&height=640&fit=bounds)



























































